DE ACCEPTABILITEIT VAN BELGISCH
TAALGEBRUIK EN DE IMPACT VAN
PERSOONLIJKHEID
Aantal woorden: 26.287 inclusief voetnoten en bibliografie, exclusief appendices
Zenon Andries
Studentennummer: 01506769
Promotoren: Dr. Anne-Sophie Ghyselen, Prof. dr. Timothy Colleman
Masterproef voorgelegd voor het behalen van de graad master in de Taal- en Letterkunde: Nederlands-Engels
Inhoudsopgave
1. Inleiding ... 6
2. De positie van Belgisch Nederlands ... 8
2.1 Het Nederlands als pluricentrische taal ... 8
2.2 De relatie tussen BN en NN ... 10
2.3 De acceptatie van Belgisch Nederlands ... 12
3 Taal- en persoonlijkheid ... 15
3.1 Persoonlijkheid als taalvariabele ... 15
3.2 Persoonlijkheid meten ... 15
3.3 De validiteit van de Big Five ... 19
3.4 De relatie tussen de Big Five en gedrag ... 21
4. Methodologie ... 24
4.1 Selectie van de taalvariabelen ... 24
4.1.1 Selectiecriteria ... 24
4.1.2 Beschrijving van de taalvariabelen ... 27
4.2 Enquête ... 30 4.2.1 Biografische informatie ... 30 4.2.2 Acceptabiliteitsoordelen ... 31 4.2.3 Persoonlijkheidsvragenlijst ... 34 4.3 Respondentenbeschrijving ... 35 4.3.1 Regio... 35 4.3.2 Geslacht ... 36 4.3.3 Geboortejaar ... 37 4.3.4 Opleidingsniveau ... 38 4.4 Data-analyse ... 40
4.4.1 Acceptabiliteit van de variabelen ... 40
4.4.2 Relatie tussen persoonlijkheid en acceptabiliteit ... 42
5. Resultaten ... 44
5.1 Acceptabiliteitsscores ... 44
5.1.1 Algemeen beeld ... 44
5.1.2 Per subtype ... 45
5.1.3 Per testzin ... 46
5.2 Relatie tussen persoonlijkheid en acceptabiliteit ... 48
6. Bespreking ... 54
6.1 Een endogene norm? ... 54
6.2 Ongelijke afkeuring ... 57
6.3 Ruimdenkendheid als factor bij de acceptabiliteitsscores ... 63
7. Conclusie ... 66
Bibliografie ... 69
Appendix 1 - Online enquête ... 73
Appendix 3 - Variantenvoorkeur bij de testzinnen (Mann-Whitney U) ... 77 Appendix 4 - Correlaties tussen persoonlijkheid en acceptabiliteit ... 80
Lijst van tabellen
Tabel 1 - De Big Five persoonlijkheidsdimensies met conceptuele definities en voorbeelden
... 16
Tabel 2 - De vijftien facetten, verdeeld per domein ... 19
Tabel 3 - De zes categorieën van belgicismen ... 26
Tabel 4 - De geselecteerde taalvariabelen, gesorteerd per categorie. ... 27
Tabel 5 - De testzinnen van de twaalf taalvariabelen ... 33
Tabel 6 - De positieve controlezinnen ... 34
Tabel 7 - De negatieve controlezinnen ... 34
Tabel 8 - Regionale spreiding van de Belgische deelnemers ... 36
Tabel 9 - Geslacht van de Belgische deelnemers per provincie ... 37
Tabel 10 - Hoogst behaalde diploma van de Belgische deelnemers ... 39
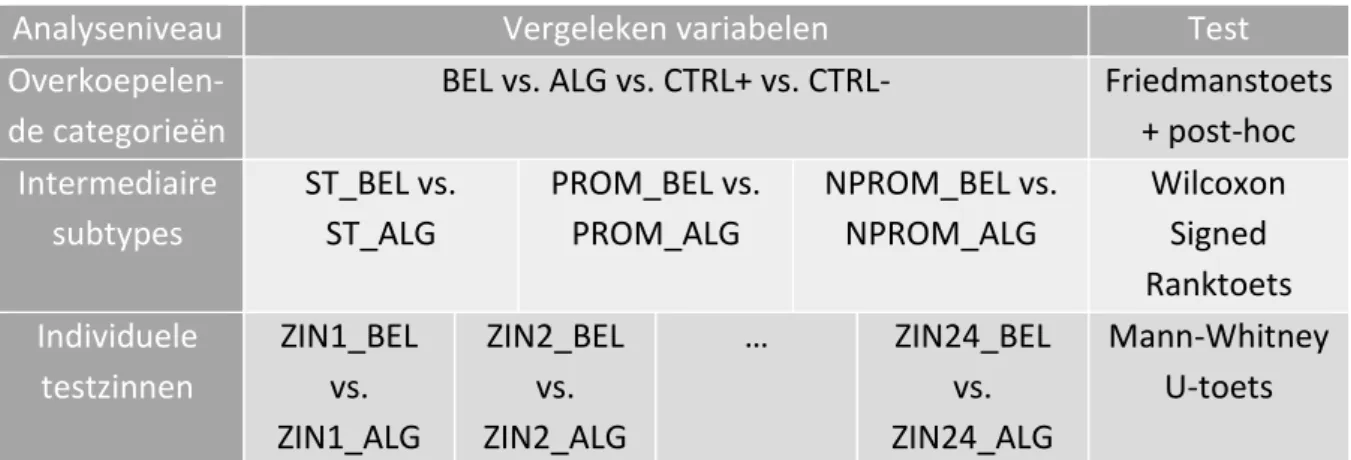
Tabel 11 - De drie analyseniveaus bij de kwantitatieve analyse van de acceptabiliteitsoordelen ... 42
Tabel 12 - Paarsgewijze verschillen tussen de overkoepelende categorieën ... 45
Tabel 13 - Wilcoxon Signed Ranktoets: paarsgewijze verschillen binnen elk intermediair subtype ... 46
Tabel 14 - Variantenvoorkeur bij de ST-variabelen... 47
Tabel 15 - Variantenvoorkeur bij de PROM-variabelen ... 47
Tabel 16 - Variantenvoorkeur bij de NPROM-variabelen ... 48
Tabel 17 - Correlatie tussen de vijf domeinen en de acceptabiliteitsscores ... 49
Tabel 18 - Correlatie tussen de facetten van Extraversie en de acceptabiliteitsscores ... 51
Tabel 19 - Correlatie tussen de facetten van Vriendelijkheid en de acceptabiliteitsscores .... 51
Tabel 20 - Correlatie tussen de facetten van Consciëntieusheid en de acceptabiliteitsscores 51 Tabel 21 - Correlatie tussen de facetten van Negatieve emotionaliteit en de acceptabiliteitsscores ... 52
Tabel 22 - Correlatie tussen de facetten van Ruimdenkendheid en de acceptabiliteitsscores 52 Tabel 23 - Variantenvoorkeur bij de ST-variabelen (samengevat) ... 54
Tabel 24 - Variantenvoorkeur bij de PROM-variabelen (samengevat) ... 57
Tabel 25 - Variantenvoorkeur bij de NPROM-variabelen (samengevat) ... 57
Tabel 26 - Significante correlaties tussen de acceptabiliteitsscores en de facetten die niet onder Ruimdenkendheid vallen ... 64
Tabel 27 - Significante correlaties tussen de acceptabiliteitsscores en (de facetten van) Ruimdenkendheid ... 64
Lijst van figuren
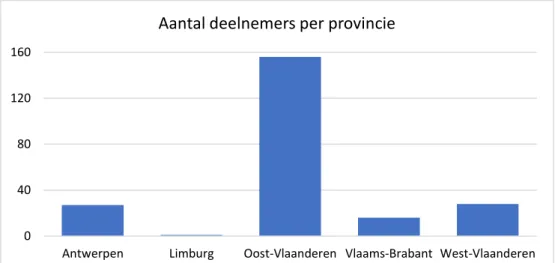
Figuur 1 - Regionale spreiding van de Belgische deelnemers ... 36
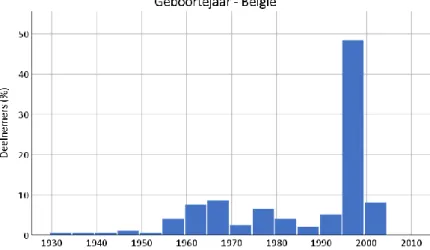
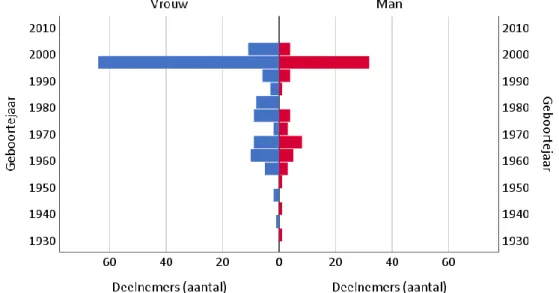
Figuur 2 - Geboortejaar van de Belgische deelnemers ... 37
Figuur 3 - Geboortejaar van de Antwerpse deelnemers ... 38
Figuur 4 - Geboortejaar van de Oost-Vlaamse deelnemers ... 38
Figuur 5 - Geboortejaar van de Vlaams-Brabantse deelnemers ... 38
Figuur 6 - Geboortejaar van de West-Vlaamse deelnemers ... 38
Figuur 7 - Geboortejaar van de Belgische deelnemers per geslacht ... 38
Figuur 8 - Leeftijd per categorie van hoogst behaalde diploma ... 39
Figuur 9 - De gemiddelde acceptabiliteitsscores van de vier overkoepelende categorieën ... 44
Figuur 10 - De gemiddelde acceptabiliteitsscores van de intermediaire subtypes ... 45
Figuur 11 - Acceptabiliteit van ijskast: testzin 1 ... 56
Figuur 12 - Acceptabiliteit van frigo: testzin 1 ... 58
Figuur 13 - Acceptabiliteit van ijskast: testzin 2 ... 57
1. Inleiding
In november 2014 publiceerde De Standaard de resultaten van de internetenquête Hoe
Vlaams is uw Nederlands. Meer dan 3.000 Vlaamse taalprofessionals kregen een aantal zinnen
te zien die typisch Belgische woorden of constructies bevatten. Vervolgens moesten de deelnemers oordelen of ze die zinnen aanvaardbaar vinden voor gebruik in een standaardtalige context. Gemiddeld werden 58% van zinnetjes goedgekeurd: de taalprofessionals gaven dat ze geen probleem te hebben met die Belgisch gekleurde zinnen (De Schryver 2014:6). In de publicatie benadrukt De Standaard vooral de mildheid waarmee de taalprofessionals belgicismen beoordelen: “‘Vlaamser’ Nederlands is geen taboe meer” (De Standaard 2014a). Hoewel 58% inderdaad een aanzienlijk aandeel is, impliceert de resterende 42% natuurlijk ook een relatief grote verdeeldheid (Debrabandere 2015:50). Ook op sociale media lokte de publicatie uiteenlopende reacties uit. Eén Facebookgebruiker signaleert bijvoorbeeld dat de enquête beter “hoe boers is uw Nederlands” geheten had, waarop een andere gebruiker in de bres springt voor het Belgisch Nederlands: “het Vlaams is een verrijking, verdorie!” (reacties op De Standaard 2014b).
Bovendien is de gerapporteerde 58% slechts een gemiddelde. Een uitgebreidere analyse toont aanzienlijke verschillen, meer bepaald op twee vlakken. Ten eerste is de acceptabiliteit sterk afhankelijk van welk belgicisme precies bestudeerd wordt. De Belgische uitdrukking op vraag
van (versus op verzoek van) wordt bijvoorbeeld door 87,5% van de deelnemers geaccepteerd,
maar tien na zes (versus tien over zes) slechts door 36,9% (De Schryver 2014:5). Ten tweede houden verschillende sprekers er verschillende oordelen op na. Zo keuren vertalers gemiddeld maar 49,2% van de testitems goed, terwijl dat bij advocaten 66,4% is (De Schryver 2014:7). Hoe kunnen we die verschillen in acceptabiliteit verklaren? Het huidige taalattitudeonderzoek biedt weinig: de acceptabiliteit van verschillende belgicismen bij verschillende sprekers is weinig onderzocht. Daarom probeert dit onderzoek die acceptabiliteitsverschillen verder uit te diepen, en vertrekt dus vanuit de twee volgende vragen:
1. Waarom keuren taalgebruikers sommige belgicismen goed, maar andere niet? 2. Waarom keuren sommige taalgebruikers belgicismen goed, maar anderen niet? Om de eerste vraag te beantwoorden werd er een enquête opgesteld waarbij sprekers testzinnen te zien krijgen die typisch Belgische constructies en woorden bevatten. Vervolgens moeten ze een oordeel vellen over de geschiktheid van het taalgebruik in een formele geschreven context, meer bepaald een krantenartikel. Het ene belgicisme is echter het andere niet: sommige zijn lexicaal, andere grammaticaal. Sommige belgicismen worden doorgaans tot de standaardtaal gerekend, terwijl andere dan weer gekend staan als beruchte Vlaamse ‘fouten’. Daarom worden er meerdere categorieën onderscheiden tijdens de analyse. Door de acceptabiliteitsoordelen van verschillende belgicismen te vergelijken met elkaar én met algemeen Nederlandse tegenhangers, kan er een preliminaire schets opgemaakt worden van welke (soorten) belgicismen meer aanvaard worden en welke minder.
Om de tweede vraag te beantwoorden wordt de persoonlijkheid van de deelnemers in kaart gebracht. Aangezien ons doen en denken onlosmakelijk verbonden is met wat voor persoon we zijn, rijst de vraag of ons talig denken ook gestuurd wordt door ons persoonlijkheid. Het is dus goed mogelijk dat persoonlijkheid correleert met de intersprekerverschillen in taalattitudes: de reden waarom één persoon een belgicisme goedkeurt en de andere niet, hangt mogelijk samen met verschillen in persoonlijkheid. Persoonlijkheid is een weinig gebruikte variabele in taalkundig onderzoek, vergeleken met klassieke variationele variabelen zoals leeftijd, geografie, sekse, socio-economische status, opleidingsniveau of geografie. Dit onderzoek probeert dus niet enkel te beschrijven welke persoonlijkheidstrekken samenhangen met welke taalattitudes, maar verkent tegelijk de validiteit van een psychologisch-variationele insteek in een kwantitatief attitudeonderzoek. De operationalisering van de persoonlijkheidscomponent gebeurde aan de hand van de zogenaamde Big Five, een model binnen de differentiële psychologie dat persoonlijkheid beschrijft aan de hand van vijf scalaire persoonlijkheidsdomeinen. Vervolgens wordt er
gekeken of de persoonlijkheidsscores correleren met verschillen in de
acceptabiliteitsoordelen, om zo een beeld te krijgen van de relatie tussen persoonlijkheid en Belgische taalattitudes.
Hoofdstuk 2 behandelt de status van Belgisch Nederlands, en het bestaande onderzoek naar sprekerattitudes tegenover belgicismen. Hoofdstuk 3 schetst vervolgens het theoretisch kader voor de persoonlijkheidscomponent van dit onderzoek, en motiveert de keuze voor de Big
Five als persoonlijkheidsmodel. Vervolgens komt de methodologie aan bod: hoofdstuk 4
beschrijft de keuze van de taalvariabelen, de enquête zelf, de deelnemers en de werkwijze bij de data-analyse. Hoofdstuk 5 rapporteert de resultaten in ruwweg twee luiken: eerst de acceptabiliteitsoordelen van de belgicismen, en vervolgens de correlaties met de persoonlijkheidsvariabelen. De resultaten worden daarna geïnterpreteerd in hoofdstuk 6, en ten slotte geeft hoofdstuk 7 een overzicht van het onderzoek, samen met een algemene conclusie.
2. De positie van Belgisch Nederlands
Taalattitudes komen nooit in isolatie voor. Om acceptabiliteitsoordelen van belgicismen te begrijpen, moeten die geanalyseerd worden in het licht van een bredere ideologische, politieke en sociohistorische context. Daarom bespreekt dit hoofdstuk eerst en vooral de positie van Belgisch Nederlands in het bredere Nederlandse taallandschap, met bijzondere aandacht voor de relatie tussen verschillende vormen van het Nederlands. Vervolgens wordt er ook kort besproken hoe Vlamingen zich verhouden tegenover hun regio-eigen taalvariëteit(en).
2.1 Het Nederlands als pluricentrische taal
Het Nederlands telt maar liefst 24 miljoen sprekers wereldwijd, waarvan 17 miljoen in Nederland wonen, 6,5 miljoen in België en 0,5 miljoen in Suriname. In die landen is het Nederlands naast een officiële taal dan ook een levendige taal, met unieke ontwikkelingen en eigen karakteristieken (StaatNed 2019:8). Daarom wordt het Nederlands tegenwoordig meestal beschouwd als een pluricentrische taal (Geerts 2012). Kort uitgelegd heeft een pluricentrische taal meerdere centra die taalontwikkeling aansturen, elk met hun eigen (gecodificeerde) norm (Clyne 2012:1). Volgens een pluricentrische visie bestaat ‘het Nederlands’ dus uit verschillende ‘Nederlandsen’: zowel Surinaams Nederlands (SN) als
Belgisch Nederlands (BN) en Nederlands Nederlands (NN) bestaan naast elkaar als
evenwaardige, deels overlappende vormen van het Nederlands. Essentieel voor het pluricentrisme is dat de verschillende centra deels onafhankelijk zijn, hoewel ze allicht ook interactie vertonen met elkaar (Clyne 2012:1). België als normatief centrum wordt ongetwijfeld beïnvloed door Nederland, maar de standaard in België is niet enkel en alleen parasitair afhankelijk van de Nederlands Nederlandse norm (Lybaert & Delarue 2017:178). Het idee dat centra slechts deels autonoom zijn impliceert echter dat de relatie tussen twee centra niet noodzakelijk symmetrisch is. Doorgaans zorgen extralinguïstische factoren zoals ongelijke politieke of economische macht ervoor dat er een dominant centrum ontstaat (Clyne 2012:454). Een dominante variëteit heeft dan bijvoorbeeld meer impact op de taalontwikkeling in andere centra dan omgekeerd, of geniet een groter prestige op het wereldtoneel. Een voorbeeld is het Duits: het Duits uit Duitsland oefent een sterke invloed uit op de standaard in Oostenrijk, Zwitserland, Luxemburg en België, maar omgekeerd hebben andere variëteiten weinig of geen impact op de Duits Duitse standaard. In de Italiaans- en Franssprekende delen van Zwitserland leert men op school zelfs eerder de Duitse dan de Zwitserse standaard (Auer 2013:20). Volgens de meeste taalkundigen is Nederland het dominante centrum, terwijl België een voorbeeld is van een niet-dominant centrum (Geerts 2012:86). Zo wordt er in een internationale context nagenoeg alleen NN aangeleerd aan studenten van het Nederlands, of introduceren Nederlanders een pak meer neologismen in het Nederlands dan Belgen (De Caluwe 2013:46). Ook neemt NN slechts zeer zelden woorden of constructies over uit BN (uitzonderingen bestaan, bijvoorbeeld “prietpraat” of “uitbaten”); iets wat omgekeerd veel vaker het geval is (Geerts 2012:87).
Hoe kan de niet-dominante positie van BN verklaard worden? De literatuur noemt een aantal redenen. Ten eerste is de asymmetrische relatie tussen BN en NN een natuurlijk gevolg van een verschillend demografisch gewicht (De Caluwe 2013:46; Geerts 2012:86): er wonen in Nederland nu eenmaal bijna tweeëneenhalf keer zoveel Nederlandstaligen als in België, namelijk 17 miljoen versus 6,5 miljoen sprekers (cf. supra). Het hoeft op zich niet te verwonderen dat het centrum met de grootste populatie ook het dominante centrum is. Bovendien merkt Geerts (2012) op dat ook de politieke situatie in België meespeelt. België als land is namelijk tweetalig; er is geen één-op-één relatie tussen BN en het nationale niveau, zoals dat wel het geval is met NN in Nederland. Het centrum van ‘Belgisch’ Nederlands is in realiteit beperkt tot Vlaanderen en Brussel. Was België als politieke eenheid uitsluitend Nederlandstalig, dan zou het land misschien een dominantere rol spelen op het internationaal toneel en bij zijn noorderburen (Geerts 2012:88).
Ten slotte is de taalgeschiedenis van het Nederlands ongetwijfeld een belangrijke factor (De Caluwe 2013:46; Geerts 2012:80). Tot recent was er namelijk geen sprake van pluricentrisme maar eerder van monocentrisme, met het Nederlands Nederlands als de taalnorm bij uitstek (Lybaert & Delarue 2017:178). De reden daarvoor begint bij de scheiding van de Nederlanden, die na 1585 een breuk veroorzaakte in het Nederlandse taallandschap. Het Nederlands onderging al snel een gestaag standaardiseringsproces in het onafhankelijke noorden, terwijl dat proces nauwelijks van de grond kwam in het zuiden, dat tot in 1815 onder buitenlands bewind bleef (De Louw 2016:117-118; Lybaert & Delarue 2017:176). Tijdens de Habsburgse, Oostenrijkse en Franse overheersing overleefde het Nederlands in het zuiden voornamelijk als een verzameling dialecten (De Caluwe 2004:53). Vosters et al. (2010) nuanceren dat idee enigzins: volgens hun onderzoek was de (geschreven) standaard in het zuiden minder fragmentarisch dan traditioneel verondersteld wordt – alleszins in de 19e eeuw. Wat wel
vaststaat, is dat de maatschappelijke positie van het Nederlands moest onderdoen voor het prestigieuzere Frans. Pas na een lange taalstrijd in de 19e en 20e eeuw, geleverd door de
Vlaamse Beweging, werd het Nederlands geaccepteerd als officiële en volwaardige taal in Vlaanderen (De Louw 2016:118; Lybaert & Delarue 2017:176-177).
De emancipatie van het Nederlands ten koste van het Frans introduceerde echter een nieuw probleem: welke variëteit van het Nederlands moest de nieuwe standaard worden? Er kunnen ruwweg twee ideologische kampen onderscheiden worden, elk met hun eigen antwoord:
particularisten en integrationisten. Particularisten benadrukten het belang van een autonoom
Vlaams standaardiseringsproces, terwijl integrationisten de adoptie van de Nederlands Nederlandse standaard promootten. Alles bijeengenomen heeft de integrationistische agenda het gehaald: in 1989 werd NN erkend als officiële taal van België naast het Frans met de zogenaamde Gelijkheidswet (Lybaert & Delarue 2017:177). De Nederlands Nederlandse standaard was namelijk een moderne en gecodificeerde taal, met genoeg prestige om te concurreren met het Frans. Bovendien geloofden de integrationisten niet dat de wirwar aan
dialecten in Vlaanderen geschikt was als basis voor een standaardtaal (Van Hoof 2013:40). Het gevolg was dat Nederlands Nederlands tot in de jaren ‘70 model stond voor de Belgische standaard: hoewel België al vanaf het begin een relatief autonome uitspraaknorm had, was Nederland hét autoritaire normatieve centrum voor Nederlandse woordenschat en morfosyntaxis (Van Hoof & Jaspers 2012:104-105)1. Eigenschappen van BN die verschilden van
NN werden in die tijd dus beschouwd als afwijkingen van de (enige) norm, zoals typisch is voor monocentrische taalsituaties (Clyne 2012:1). Bijgevolg maakte Vlaanderen tussen 1950 en 1980 een periode door van wat Van Hoof & Jaspers (2012) hyperstandaardisering noemen: een sterk propagandistische en grootschalige poging om de Vlaming de Nederlandse taalnorm aan te leren, aan de hand van media, onderwijs en andere initiatieven zoals de ABN-kernen, verenigingen van schoolgaande jongeren opgericht om “de speelplaats voor het ABN te veroveren” (Van Hoof & Jaspers 2012:100).
Pas in de jaren ’70 begon de situatie te veranderen voor BN, wanneer taalkundigen en beleidsmakers België meer begonnen te erkennen als een deels autonoom centrum. In de tweede helft van de 20e eeuw werd Vlaanderen namelijk de dominante politieke en
economische regio in België. Het zelfbewustzijn van de Vlaamse (talige) identiteit groeide, en het normatieve zwaartepunt begon te verschuiven van NN naar een eigen Belgisch Standaardnederlands; het zogenaamde VRT-Nederlands nam langzaam de positie in van de standaardnorm (Lybaert 2017:178). Kortom, door een complexe geschiedenis van emancipatiestrijd, onderdrukking en taalbeleid heeft het belang van België als normatief centrum lang op zich laten wachten. De evolutie van het Nederlands van een monocentrische naar pluricentrische taal is een recente ontwikkeling, en het proces is waarschijnlijk nog steeds aan de gang.
2.2 De relatie tussen BN en NN
Het feit dat sommige taalvariëteiten dominanter zijn dan andere, zoals Duits Duits bijvoorbeeld dominanter is dan Oostenrijks Duits, wijst erop dat pluricentrisme geen categoriale eigenschap voorstelt, maar eerder een spectrum. Normatieve centra kunnen namelijk meer of minder afhankelijk zijn van een ander (dominant) centrum. Zo stelt Ammon (1989) bijvoorbeeld een scalair model voor, gebaseerd op de codificatie van een bepaalde variëteit: die variëteit krijgt soort ‘codificatiescore’ aan de hand van de hoeveelheid modelsprekers, modelschrijvers, spellingsregels, woordenboeken en naslagwerken die bestaan voor die bepaalde variëteit (Ammon 1989:89). Afhankelijk van de score wordt een variëteit op een schaal geplaatst van volledige exonormativiteit tot volledige
endonormativiteit. Zo kan er een onderscheid worden gemaakt tussen volledige centra versus semi-centra en rudimentaire centra (Ammon 1989:90).
1 Ook in Suriname was de standaard tot in de jaren ’70 uitsluitend gericht op een Nederlands Nederlandse norm (Geerts 2012:73). Sindsdien wordt SN ook erkend als variëteit naast BN en NN, maar er is nog veel discussie over wat de Surinaamse norm precies inhoudt en wat haar nu precies onderscheidt van het Nederlands in Europa (StaatNed 2019:20).
Waar bevindt het BN zich op die schaal? Het zou ongetwijfeld leerrijk zijn om de codificatie van BN op een soortgelijke kwantitatieve manier te analyseren, maar een dergelijke studie is naar mijn weten niet voorhanden. Wel merken Lybaert & Delarue (2017) op dat BN steeds meer erkend wordt in naslagwerken als volwaardige variëteit. Het Prisma handwoordenboek
Nederlands en de Dikke Van Dale hebben allebei pogingen ondernomen om woorden die
enkel in België voorkomen minder snel als niet-standaardtalig te bestempelen. In de plaats classificeren ze een groot aantal Belgische woorden nu als Belgische standaardtaal. Bovendien – en minstens even belangrijk – wordt dezelfde procedure toegepast op woorden die beperkt zijn tot Nederlands Nederlands: die krijgen het label van (Noord-)Nederlandse Standaardtaal, terwijl ze vroeger zonder meer als standaardtalig beschouwd werden (Lybaert & Delarue 2017:179). In een typologie van niet-dominante taalvariëteiten classificeert Muhr (2012) de taalstatus van verschillende variëteiten, voornamelijk op basis van hun erkenning in naslagwerken en andere taalcodices. BN wordt daarbij geplaatst op het niveau met de hoogste status vergeleken met andere niet-dominante variëteiten in de wereld (Muhr 2012:43). Met andere woorden, wie kijkt naar de codificatie van het (Belgisch) Nederlands zou – in Ammons’ termen – denken dat België een relatief volledig centrum is met een relatief hoge endonormativiteit.
De Caluwe (2013) waarschuwt echter dat de focus op codificatie te beperkt is. Enkel onderzoeken hoe naslagwerken BN en NN taalvariëteiten honoreren is “te eng om de reële relatie tussen dominante en niet-dominante variëteiten te vatten” (47). Zelfs al waren alle grammatica’s en woordenboeken van het Nederlands perfect symmetrisch in hun behandeling van NN en BN, dan capteert dat niet noodzakelijk de werkelijke relatie tussen de twee centra. Er moet ook gekeken worden naar andere factoren, zoals bijvoorbeeld de organisatie van de media- en cultuurmarkt (De Caluwe 2013:47). Wat de media betreft is er vooral sprake van twee parallelle markten: België en Nederland hebben allebei hun eigen kranten, magazines, radio, televisie, muziek, reclame en films, waar telkens gebruik wordt gemaakt van de regio-eigen taalvariëteit. Kruisbestuiving bestaat, vooral bij een handvol overheidsinitiatieven zoals het Cultureel Verdrag Vlaanderen-Nederland of het Vlaams-Nederlands cultuurhuis deBuren, maar het blijft toch de uitzondering op de regel wanneer de twee markten zich vermengen, zeker bij commerciële initiatieven (De Caluwe 2013:47-49). Het is op zich al veelzeggend dat de Lage Landen uit financieel gewin opgedeeld worden in twee ‘taalcoconnen’; het is dus niet zo dat België, het niet-dominante centrum, overspoeld wordt met Nederlands Nederlandse media. Integendeel, in veel gevallen krijgen mediaproducten uit één centrum een remake in het andere, wat de Belgische autonomie onderstreept. Zo kreeg de Vlaamse film Loft uit 2008 twee jaar later ook een Nederlandse remake, en werd het Nederlandse Alles is Liefde (2007) omgewerkt tot Zot van A (2010) in België.
Wanneer producten of ondernemingen zich wel op de hele markt richten, dan gebeurt dat meestal symmetrisch of tenminste in proportie met het demografisch gewicht van België en Nederland. Enkele voorbeelden: de jury van de Prijs der Nederlandse Letteren is steevast samengesteld uit drie Nederlanders, drie Belgen en een Surinamer. Het Corpus Gesproken
Nederlands bestaat ongeveer voor twee derde uit Nederlands Nederlands en voor een derde
uit Belgisch Nederlands, wat ruwweg overeenkomt met de bevolkingsgrootte van de twee taalcentra. Ook het zogenaamde STEVIN-programma, een onderzoeksprogramma naar Nederlandstalige spraaktechnologie, werd respectievelijk voor twee derde en een derde gefinancierd door de Nederlandse en Vlaamse overheid (De Caluwe 2013:53). Een bron van asymmetrie die wel aanwezig is, is de geografie van die gedeelde projecten. Hoewel de verdeling tussen Vlaanderen en Nederland doorgaans proportioneel is wanneer het gaat om personeel of financiering, zijn de belangrijke instituten zoals het INL, de grote woordenboeken, de Nederlandse Taalunie of de redacties van het BNTL en het DBNL allemaal in Nederland gevestigd, meer bepaald in de Randstad (De Caluwe 2013:54). Ondanks dat BN vandaag de dag op allerlei vlakken dezelfde status geniet als NN, zijn er dus toch enkele asymmetrieën; het gevaar bestaat dat die ongelijkheden de historische perceptie bevestigen dat Nederland (en meer bepaald de Randstad) hét normatieve centrum is van het Nederlandse taalgebied.
2.3 De acceptatie van Belgisch Nederlands
In de vorige paragrafen werd er tot op zekere hoogte abstractie gemaakt van de taalgebruikers van het Nederlands. Het ging vooral over de officiële status van BN en NN, over de sociohistorische, politieke en economische context die impact heeft op de positie van BN binnen het taallandschap. Minstens even belangrijk bij de studie van taalvariëteiten is echter de mentale realiteit van de taalgebruikers: de vraag is welke status Vlamingen (en Nederlanders) zelf aan het BN toekennen. In welke situaties wordt BN geaccepteerd, en door wie?
Om die vraag te beantwoorden moeten we eerst weten wat BN precies inhoudt. Internationaal onderzoek naar pluricentrische talen heeft het doorgaans over ‘de’ variëteit van een bepaald centrum, waarmee in essentie een soort regio-eigen standaardnorm wordt bedoeld (Clyne 2012:3). De variëteit van het Nederlands die het best aan de beschrijving van ‘Belgische Standaardtaal’ voldoet, wordt wel eens het VRT-Nederlands genoemd, het Algemeen Nederlands van de Vlaamse openbare omroep (De Louw 2016:116; Lybaert & Delarue 2017:178). Uit attitudeonderzoek blijkt dan ook dat van alle gesproken variëteiten (inclusief de NN standaard) het VRT-Nederlands in België het hoogst scoort op statusgerelateerde eigenschappen (Van Hoof & Jaspers 2012:113). Sprekers associëren het met ‘mooi’, ‘correct’, ‘nuttig’, ‘beschaafd’, ‘deftig’, ‘net’, ‘formeel’ en ‘intelligent’ (Grondelaerts et al. 2020:56; Impe & Speelman 2007:119-120; Van Bezooijen 2004:784). Ze vinden het VRT-Nederlands geschikt voor formele en officiële situaties, professionele contexten, onderwijs en geschreven taalgebruik (Lybaert 2015:114-115; Vandekerckhove
2000:264). Voor een overzicht van attitudeonderzoek naar de Belgische Standaardtaal, zie Lybaert (2015:108) en Van Hoof & Jaspers (2012:112-113). Wie kijkt naar het attitudeonderzoek, kan concluderen dat de Vlaming een endogene norm (het VRT-Nederlands) heeft geïnternaliseerd als dé taalnorm voor het Nederlands.
De normatieve hegemonie van de VRT-standaard is echter niet vrij van controverse; sommige auteurs schuiven immers een andere visie op de Belgische standaard naar voren. Het probleem is namelijk dat de standaard een ‘virtuele’ variëteit is. Dat wil zeggen: de VRT-norm is misschien wel maatschappijbreed bekend, maar wordt slechts door een minieme kern van sprekers beheerst en gebruikt (Grondelaers et al. 2020:50). Hoewel Vlamingen de VRT-standaard als de meest prestigieuze variëteit zien – dat is althans hun overte houding – ervaren ze het als een oncomfortabele taalvariëteit, niet geschikt om zelf te gebruiken (cf. het idee van de VRT-norm als zondagspak, Geeraerts 2001). Tussentaal groeit daarentegen wel gestaag aan populariteit. Tussentaal is een soort intermediair taalgebruik dat ergens tussen de VRT-standaard en de dialecten in ligt. Tussentaal is de ‘alledaagse’ functie van dialecten aan het overnemen, maar daarnaast wordt het ook steeds meer gebruikt in domeinen die traditioneel voor de standaardtaal gereserveerd waren, zeker bij jongere sprekers (De Caluwe 2009:9). Lybaert (2015) nam bijvoorbeeld spontane interviews af bij Vlamingen nadat ze stimulusfragmenten beluisterden met verschillende variëteiten van het Nederlands. Een significant deel van de respondenten vond bij de tussentalige fragmentjes dat het taalgebruik het best paste bij formele situaties (116-117). De opmars van tussentaal en het feit dat de VRT-standaard een virtuele variëteit is, zien sommige auteurs als bewijs dat de VRT-norm net niet meer de standaard is (Van Hoof & Jaspers 2012:118). Grondelaers et al. (2011) hebben het zelfs over een “standaardtaalvacuüm”: momenteel is er volgens hen geen echte standaard voorhanden, hoewel tussentaal potentieel vertoont om gestandaardiseerd te worden in de toekomst (217). Volgens het idee van het standaardtaalvacuüm zou er een destandaardisering van het Nederlands hebben plaatsgevonden, waardoor noch tussentaal noch het VRT-Nederlands erin slaagt om de positie van de standaard te veroveren.
Ten slotte is er een opvallend hiaat in de literatuur over taalattitudes in Vlaanderen. De attitudeonderzoeken die tot nu toe vermeld werden, richten zich uitsluitend op gesproken taal. Attitudes tegenover geschreven BN, wat het studieobject is van dit onderzoek, worden daarbij buiten beschouwing gelaten. Een eerste reden daarvoor is waarschijnlijk het feit dat attitudeonderzoek vaak gebaseerd is op uitspraak, wat wegvalt bij de studie van geschreven taal. Belangrijker is wellicht de assumptie dat Nederland en België een vaste, gedeelde schrijftaal hebben. De verschillen tussen BN en NN zijn inderdaad doorgaans veel kleiner in geschreven Nederlands. Veel typisch Belgische kenmerken behoren enkel tot het niveau van de tussentaal (of de dialecten), zoals bijvoorbeeld het ge-voornaamwoord. Hoewel ge overheerst in de spreektaal van heel wat Vlamingen, hebben ze er geen moeite mee om je te gebruiken tijdens het schrijven (Grondelaers & Van Hout 2011:207-208). De niveaus van tussentaal en dialect zijn echter simpelweg minder relevant in het geschreven BN, wat
waarschijnlijk de reden is waarom onderzoek naar geschreven belgicismen uitblijft. Bovendien merken Grondelaers & Van Hout (2011) op dat er wel enkele verschillen bestaan tussen geschreven (Standaard) BN en (Standaard) NN, maar dat die verschillen miniem zijn in vergelijking met de verschillen in gesproken taalgebruik (208-209).
Toch zijn attitudes tegenover geschreven Belgisch Nederlands een interessant studieobject. De vraag rijst bijvoorbeeld in welke mate kenmerken die typisch zijn voor BN, aanvaard worden in formeel geschreven taalgebruik. Oordelen sprekers verschillend over kenmerken die tot de VRT-norm behoren dan wel over kenmerken die substandaardtalig zijn? De officiële status van een woord of constructie hoeft namelijk niet samen te vallen met de mentale realiteit van sprekers: aangezien tussentaal steeds meer taaldomeinen verovert ten koste van het VRT-Nederlands, is het allicht ook mogelijk dat substandaardtalige belgicismen in zekere mate geaccepteerd worden in een formele schrijfsetting. In welke mate zijn Vlamingen (of Nederlanders) bewust van de ‘Belgisch-heid’ van Belgisch Nederlands taalgebruik? Zoja, welke kenmerken vallen hen op, en welke niet? Deze vragen dienen als leidraad bij dit onderzoek.
3 Taal- en persoonlijkheid
Net zoals er geen twee personen zijn die op exact dezelfde manier spreken, zijn er ook geen twee individuen met exact dezelfde persoonlijkheid. Sinds de jaren ’60 wordt het belang van variatie in talig gedrag systematisch bestudeerd in de taalkunde, maar een historisch onderbelichte factor is die van persoonlijkheid. Hoe een persoon spreekt, is echter onlosmakelijk verbonden met wat voor persoon hij of zij is. Dit hoofdstuk bespreekt de effecten van persoonlijkheid op talig gedrag en hoe persoonlijkheidskenmerken geoperationaliseerd kunnen worden als variabelen in (attitude)onderzoek.
3.1 Persoonlijkheid als taalvariabele
Een van de meest gangbare visies op persoonlijkheid in de differentiële psychologie is die van Larsen & Buss (2009). Zij definiëren persoonlijkheid als een set van relatief langdurige psychologische kenmerken die invloed uitoefenen op hoe een persoon omgaat met zijn of omgeving. Persoonlijkheid bestaat dus uit vrij vaste eigenschappen die het psychologische, fysieke en sociale gedrag van een bepaalde persoon beïnvloeden (Larsen & Buss 2009:4). Taalgebruik en -attitudes vormen op zich ook een soort gedrag, en worden dus ongetwijfeld ook beïnvloed door persoonlijkheid. Daarom heeft de relatie tussen persoonlijkheid en taal dan ook de interesse gewekt van zowel psychologen als taalkundigen. Onderzoek naar tweedetaalverwerving heeft bijvoorbeeld uitgewezen dat de persoonlijkheid van een tweedetaalverwerver een impact kan hebben op zijn of haar leerstijl en taalvaardigheid (bijvoorbeeld Erton 2010:124; Ghapanchi et al. 2011:152-153). Een ander voorbeeld is het onderzoek van Tausczik & Pennebaker (2010), die aan de hand van het computerprogramma LIWC (Linguistic Inquiry and Word Count) teksten analyseerden en zo de persoonlijkheid van de schrijver/spreker trachtten te reconstrueren.
Hoewel het evident lijkt dat de persoonlijkheid van taalgebruikers hun taalgedrag en -attitudes beïnvloedt, is er verbazend weinig kruisbestuiving tussen persoonlijkheidsonderzoek en de variationele linguïstiek. Nochtans hechten variationele taalkundigen belang aan intersprekerverschillen bij het bestuderen van taalproductie, taalperceptie en (zoals in dit onderzoek) taalattitudes. Zo onderzoeken ‘Laboviaanse’ sociolinguïsten in welke mate variabelen als leeftijd, etniciteit, socio-economische status, gender en sekse het taalgedrag beïnvloeden. Persoonlijkheid blijft als variabele echter grotendeels onder de radar.
3.2 Persoonlijkheid meten
Persoonlijkheid is moeilijk om te ‘meten’ in vergelijking met iets als leeftijd, wat kan verklaren waarom persoonlijkheid onderbelicht is in de variationele taalkunde. Binnen de sociale psychologie werden er echter verschillende methoden ontwikkeld om persoonlijkheid in kaart te brengen. Een populaire aanpak in de differentiële psychologie is de trait approach of
trekbenadering. Die trekbenadering probeert persoonlijkheid in kaart te brengen aan de hand
van taxonomieën van meetbare traits of persoonlijkheidskenmerken. Er zijn binnen die benadernig al lang verschillende invloedrijke modellen voorhanden met elk hun eigen
taxonomie, zoals het driefactorenmodel van Eysenck of de zestien persoonlijkheids-factoren van Cattell. Het model waarover er echter momenteel veruit de meeste consensus bestaat, is het zogenaamde Big Five-model, ook wel gekend als het Five Factor Model (FFM) of het
OCEAN-model (John et al. 2008:120). De basisprincipes en de origine van het Big Five-model
worden in de rest van deze paragraaf besproken.
Zoals de naam suggereert, bestaat de taxonomie van de Big Five uit vijf scalaire persoonlijkheidsdimensies, op te vatten als clusters van persoonlijkheidstrekken: Extraversie,
Vriendelijkheid, Consciëntieusheid, Negatieve emotionaliteit en Ruimdenkendheid (Engels Extraversie, Agreeableness, Conscientiousness, Negative Emotionality en Open-mindedness).
Tabel 1 geeft voor elke persoonlijkheidsdimensie een definitie en voorbeelden van gedrag die typisch zijn voor beide extremen van elke schaal.
Dimensie
HOGE SCORE t.o.v. LAGE SCORE
Conceptuele definitie Voorbeelden van gedrag
‘+’: typisch voor hoge scores ‘-‘: typisch voor lage scores
EXTRAVERSIE
t.o.v. INTROVERSIE
Een energetische benadering tegenover de sociale en materiele wereld. Omvat kenmerken zoals activiteit, assertiviteit en positieve emotionaliteit.
+: Vreemden benaderen op een feestje en mijzelf introduceren -: Stil blijven wanneer ik niet akkoord ben met anderen
VRIENDELIJKHEID
t.o.v. ANTAGONISME
Een pro-sociale oriëntatie tegenover anderen. Omvat kenmerken zoals altruïsme, tederheid van geest, vertrouwen en bescheidenheid.
+: De nadruk leggen op de
positieve kwaliteiten van anderen wanneer ik met hen praat
-: Onvriendelijk zijn tegen anderen
CONSCIËNTIEUS-HEID
t.o.v. LAKSHEID
Het controleren van impulsen in situaties waar dat sociaal voorgeschreven is. Brengt gedrag voort zoals nadenken vooraleer iets te doen, niet toegeven aan onmiddellijke bevrediging en regels en normen volgen.
+: Op tijd of te vroeg komen bij afspraken
-: De vieze vaat langer dan een dag laten staan
NEGATIEVE EMOTIONALITEIT
t.o.v. STABILITEIT
Een negatieve emotionaliteit, zoals zich angstig, nerveus, verdrietig of
gespannen voelen, in contrast met emotionele stabiliteit en een evenwichtig humeur.
+: Snel van streek geraken wanneer iemand boos is op mij -: Het goede en slechte in mijn leven accepteren zonder te klagen of op te scheppen
RUIMDENKEND-HEID
t.o.v. GESLOTENHEID
De breedte, diepte, originaliteit en complexiteit van iemands mentale en experimenteel-creatieve leven.
+: De tijd nemen om iets te leren, simpelweg voor het plezier van het leren
-: Intellectuele en filosofische discussies uit de weg gaan
Tabel 1 - De Big Five persoonlijkheidsdimensies met conceptuele definities en voorbeelden van typerend gedrag voor beide extremen van de schaal. Aangepast en vertaald uit John et al. (2008:120). De namen van de persoonlijkheidsdimensies zijn
De 5-dimensionele structuur van de Big Five is gegroeid uit de lexical trait approach, een benadering die vertrekt van lekenbeschrijvingen van persoonlijkheid om een persoonlijkheidstaxonomie op te stellen. De keuze voor lekentaal als startpunt gaat uit van de
hypothese dat het leeuwendeel van de sociaal relevante en saillante
persoonlijkheidskenmerken gecodeerd is in natuurlijke talen (Saucier & Srivastava 2015:287-288). Met andere woorden, omdat persoonlijkheid een sociaal en observeerbaar gegeven is, zullen natuurlijke talen ook woorden en uitdrukkingen uitgevonden hebben om de belangrijkste persoonlijkheidskenmerken te beschrijven. Daarom vormen die woorden en uitdrukkingen een tamelijk betrouwbaar startpunt om een wetenschappelijke persoonlijkheidstaxonomie op te stellen. De vroegste pogingen om een taxonomie op te bouwen binnen de lexical trait approach gebeurden in de jaren ’30, en verzamelden alle mogelijke woorden om persoonlijkheid te beschrijven in woordenboeken. Zo kwamen Allport & Odbert (1937) in hun woordenboekenonderzoek tot maar liefst 17.953 lexicale items om persoonlijkheid te beschrijven in het Engels (24).
Een taxonomie die uit duizenden persoonlijkheidskenmerken bestaat is echter moeilijk om te operationaliseren in wetenschappelijk onderzoek. Daarom werden er in de tweede helft van de 20e eeuw nieuwe modellen ontwikkeld die het aantal kenmerken van de oorspronkelijke
taxonomieën sterk reduceren aan de hand van semantische clustervorming en factoranalyses. De redenering gaat als volgt: als uit testen blijkt dat de scores op een specifiek persoonlijkheidskenmerk altijd sterk correleren met de scores op een ander, dan vormen de twee waarschijnlijk een overkoepelend persoonlijkheidskenmerk (Soto & John 2008:118). Een voorbeeld: stel dat er aan de deelnemers van een onderzoek wordt gevraagd om een vriend scores toe te kennen op een aantal persoonlijkheidsadjectieven. Hoge scores op ‘artistiek’ blijken altijd overeen te komen met hoge scores op ‘vindingrijk’ en vice versa, maar die scores correleren veel minder met ‘attent’. Dan kan er waarschijnlijk gesproken worden van een soort overkoepelende persoonlijkheidsdimensie die ‘artistiek’ en ‘vindingrijk’ omvat. Die overkoepelende dimensie kan dan bijvoorbeeld de naam ‘creatief’ krijgen. Op die manier kunnen wetenschappers op zoek gaan naar een structuur die zo weinig mogelijk dimensies telt, maar tegelijkertijd zo veel mogelijk ‘specifieke’ persoonlijkheidskenmerken kan verklaren.
In de zoektocht naar de meest robuuste factorstructuur zijn er verschillende taxonomieën voorgesteld, maar vanaf de jaren ’90 stak de Big Five de andere modellen voorbij in populariteit; vandaag is er een relatief grote consensus dat een vijffactorenmodel de meest consistente persoonlijkheidstaxonomie biedt (John et al. 2008:116). Enkele auteurs pleiten voor een zesfactorenmodel met de toevoeging van een zesde dimensie Honesty-Humility (het
HEXACO-model, Lee & Ashton 2004), maar dat model wordt hier buiten beschouwing gelaten.
Belangrijk is dat de vijf dimensies van de Big Five geen nauwe, specifieke persoonseigenschappen zijn maar zeer brede en sterk abstracte ‘persoonlijkheidsdomeinen’
die clusters van specifiekere persoonlijkheidskenmerken impliceren. De ‘big’ in Big Five verwijst dan ook naar die breedheid en abstractie. De Big Five wil namelijk de menselijke persoonlijkheid zo volledig mogelijk beschrijven. Het feit dat de vijf dimensies ondergespecifieerd en overkoepelend zijn, is precies de reden waarom de oneindige variatie aan mogelijke persoonlijkheden vertegenwoordigd kan worden door een taxonomie met slechts vijf elementen (John et al. 2008:119). Om verwarring te vermijden worden de Big Five persoonlijkheidsdimensies in dit onderzoek vanaf nu geen persoonlijkheidskenmerken genoemd maar (persoonlijkheids)domeinen, naar analogie met Soto & John (2017).
Doordat de Big Five abstracte clusters van specifiekere persoonlijkheidskenmerken zijn, gebeurt de naamgeving van de dimensies post-hoc. Onderzoekers proberen de dimensies namen te geven die alle onderliggende trekken zo goed mogelijk weerspiegelen, maar er ontstaat vaak discussie omdat de namen altijd enigszins subjectief zijn. Vooral over de naamgeving van de vierde en de vijfde dimensie is er discussie: Negatieve emotionaliteit wordt soms wordt vaak Neuroticisme genoemd (Engels Neuroticism), en Ruimdenkendheid heet soms Intellect, Openheid of Openheid voor ervaringen (Engels Intellect, Openness of Openness
to experience) (Soto & John 2017:119-120).
Bovendien vormt de abstractheid van domeinen soms een probleem wanneer ze met (talig) gedrag gecorreleerd worden. Omdat de Big Five uit slechts vijf domeinen bestaat, hebben de domeinen een brede inhoud maar zijn ze tegelijk ook minder informatief. Vergelijk het met de naamgeving van dieren: wanneer een eend het label ‘eend’ toegekend krijgt, vertelt dat ons meer dan wanneer de eend als een ‘vogel’ geclassificeerd wordt. De naam ‘Salvadorina waigiuensis’ is nog informatiever, omdat het aanduidt tot welk biologisch geslacht de eend behoort. Het zou echter sisyfusarbeid zijn om een persoonlijkheid kwantitatief te beschrijven in de meest informatieve termen – de 17.953 items van Allport & Odbert (1937), bijvoorbeeld. Bij taxonomieën als de Big Five gaat reikwijdte dus ten koste van informativiteit of betrouwbaarheid en vice versa, wat in de literatuur de bandwith-fidelity tradeoff genoemd wordt (Salgado 2017:1-2).
Er zijn verschillende modellen die compenseren voor de effecten van de bandwith-fidelity
tradeoff, door persoonlijkheid op verschillende hiërarchische niveaus tegelijk te analyseren.
Dat wil zeggen: binnen elk domein van de Big Five kan er ook een factorstructuur afgebakend worden. Die lagere niveaus van kenmerkenclusters die dan onderscheiden worden, heten
facetten (Salgado 2017:2). Hoewel de factorstructuren van facetten minder robuust zijn dan
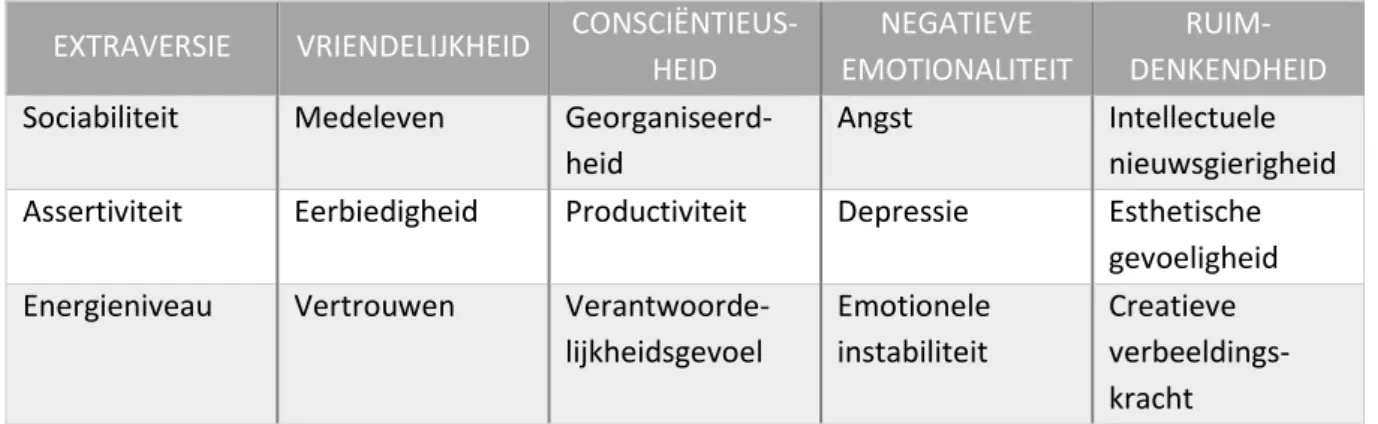
die van de vijf domeinen, vormen facetten een mooie aanvulling op de vijf domeinen, omdat ze preciezere informatie geven over persoonlijkheid dan de Big Five. Er bestaat geen consensus over welke facettentaxonomie de meest bruikbare is, maar dit onderzoek kiest voor het model van Soto & John (2017), dat ontwikkeld werd voor de Big Five Inventory-2 (cf. 4.2.2). Zij onderscheiden vijftien facetten, meer bepaald drie per domein (cf. Tabel 2). Het domein Vriendelijkheid heeft bijvoorbeeld Medeleven, Eerbiedigheid en Vertrouwen (Engels
Compassion, Respectfulness en Trust) als facetten2. Met de facetten en de domeinen als
aanvullende tools is er een completere en informatievere analyse mogelijk van de relaties tussen taalgedrag en persoonlijkheid.
EXTRAVERSIE VRIENDELIJKHEID CONSCIËNTIEUS-HEID
NEGATIEVE EMOTIONALITEIT
RUIM-DENKENDHEID
Sociabiliteit Medeleven
Georganiseerd-heid
Angst Intellectuele
nieuwsgierigheid Assertiviteit Eerbiedigheid Productiviteit Depressie Esthetische
gevoeligheid
Energieniveau Vertrouwen
Verantwoorde-lijkheidsgevoel Emotionele instabiliteit Creatieve verbeeldings-kracht Tabel 2 - De vijftien facetten, verdeeld per domein. Aangepast en vertaald uit Soto & John (2017:121). 3.3 De validiteit van de Big Five
Het grootste voordeel van de Big Five is de uitgebreide hoeveelheid empirisch onderzoek dat de validiteit van het model aantoont. Factoranalyses van persoonlijkheidskenmerken hebben herhaaldelijk dezelfde vijf-dimensionaliteit blootgelegd, zelfs wanneer er oorspronkelijk verschillende sets van specifiekere persoonlijkheidskenmerken bevraagd werden. Dat was bovendien zowel het geval bij peerevaluatie als bij zelfevaluatie (John et al. 2008:119). De ‘inhoud’ van de responsen kan verschillen wanneer een persoon zichzelf beoordeelt dan wel een beoordeling krijgt van anderen, maar de ‘structuur’ van de taxonomie niet. Anders gezegd, tests tonen aan dat iemand zijn eigen persoonlijkheid soms anders beoordeelt dan anderen hem of haar beoordelen (hoewel er ook vooral sprake is van convergentie), maar de manier waarop persoonlijkheid beoordeeld wordt in het algemeen is gelijk: de bevraagde persoonlijkheidskenmerken correleren steeds op dezelfde manier, waarbij de vijffactorenstructuur telkens geschikt blijft (Saucier & Srivastava 2015:295).
Bovendien blijkt de Big Five geschikt voor proefpersonen van diverse leeftijden: vanaf de kindertijd is de Big Five al een adequate taxonomie en vanaf de late adolescentie verandert de factorstructuur helemaal niet meer (Marsh et al. 2010:483). Longitudinale studies tonen bovendien aan dat domeinscores stabiel blijven met veroudering, althans onder volwassenen (Cobb-Clark & Schurer 2012:14).
De taxonomische structuur van de Big Five blijft dus intact ongeacht verschillende leeftijden en verschillende testtypes (bijvoorbeeld peer- versus zelfevaluatie), maar een goed model van menselijke persoonlijkheid moet ook crosscultureel en crosslinguïstisch generaliseerbaar zijn.
2 Naast facetten en domeinen worden er ook soms andere hiërarchische niveaus gebruikt: zo stellen DeYoung et al. (2007) aspecten voor, een intermediair niveau van tien factoren tussen de facetten en domeinen in (891). Een andere mogelijkheid is één of twee overkoepelende hyperfactoren bóven de vijf domeinen, de zogenaamde
Aangezien de lexical trait approach vertrekt vanuit het idee dat (bijna) alle belangrijke persoonlijkheidskenmerken voldoende gecodeerd zijn in natuurlijke taal, zouden analyses van verschillende talen in verschillende culturele omgevingen gelijkaardige resultaten moeten opleveren. Indien niet, dan moet de taxonomie worden aangepast worden om crosscultureel generaliseerbaar te zijn (Saucier & Srivastava 2015:288). Wat dat betreft, duiken er moeilijkheden op: over het algemeen is er voorlopig geen bewijs dat elke cultuur en taal unieke eigen persoonlijkheidsdimensies zou hebben (John et al. 2008:123-124), maar bij sommige analyses wijken de factorstructuren licht af van de Big Five. Het probleem in die gevallen is vaak het vijfde domein, Ruimdenkendheid. Meer bepaald kon Ruimdenkendheid niet altijd duidelijk geïdentificeerd worden als factor in Italië (De Raad et al. 1998), Hongarije (Szirmak & De Raad 1994) en Griekenland (Saucier et al. 2005).
Het feit dat studies buiten de Angelsaksische wereld niet altijd de Big Five-taxonomie ondersteunen, vormt niet noodzakelijk theoretisch probleem. De meeste crossculturele replicaties gebeurden namelijk aan de hand van tests die vertaald zijn uit het Engels; die tests gebruiken een kleine hoeveelheid lexicale items zoals persoonlijkheidsadjectieven of beschrijvende zinnetjes waarvan bewezen is dat de scores goede predictoren zijn voor de vijf domeinen in het Engels. Het probleem is dat die items nooit één-op-één vertaald kunnen worden. Wanneer de scores van vertaalde items onderworpen worden aan een factoranalyse, en de factorstructuur verschilt van de Big Five, dan zijn er twee verklaringen: het is inderdaad mogelijk dat de Big Five persoonlijkheidstaxonomie niet geldt in die cultuur, maar even plausibel is dat de vertalingen de predictieve kracht van de items hebben beïnvloed (DeYoung et al. 2007:892). Anders gezegd lijkt het misschien alsof dezelfde persoonlijkheidskenmerken verschillend met elkaar correleren in twee talen, maar een mogelijke verklaring is dat het helemaal niet om dezelfde persoonlijkheidskenmerken gaat. Een vertaald testitem toetst namelijk altijd naar een lichtjes anders persoonlijkheidskenmerk.
Een voorbeeld: in vroege Big Five-tests in Duitsland werd het Engelse item temperamental bijvoorbeeld vertaald als temperamentvoll. Hoewel temperamental een (negatieve) predictor is voor Consciëntieusheid, correleerde het temperamentvoll eerder (positief) met Extraversie. De conclusie lijkt te zijn dat hetzelfde persoonlijkheidskenmerk onder verschillende domeinen valt in Duitsland versus de Angelsaksische wereld, waardoor er sprake is van twee cultureel verschillende persoonlijkheidstaxonomieën. Die conclusie is problematisch: in realiteit hebben de twee lexicale items simpelweg een verschillende semantische lading.
Temperamentvoll wil namelijk vaker ‘vurig’, ‘gepassioneerd’ of ‘hartstochtelijk’ zeggen, terwijl
het Engelse temperamental sneller de negatieve connotatie oproept van een heethoofd, iemand die opvliegend is (John et al. 2008:122). De juiste conclusie is dus dat de Engelse en de Duitse vorm een (licht) verschillend persoonlijkheidskenmerk representeren.
Om werkelijk tot de conclusie te komen dat er een verschillende persoonlijkheidstaxonomie heerst in een ander land of een andere cultuur, zou er onafhankelijk van de Engelse
predictoren een grote hoeveelheid lexicale items moeten getest worden. Vervolgens moet er gekeken worden of factoranalyses een structuur opleveren die lijkt op de Big Five (Saucier & Srivastava 2015:288). In ieder geval is er nog meer empirisch onderzoek nodig. Bovendien zijn de studies naar de Big Five in non-Westerse settingen op dit moment te beperkt om algemeen-menselijke uitspraken te doen (Saucier & Srivastava 2015:291).
Er kan dus voorlopig niet gezegd worden of de Big Five in zijn huidige vorm een adequaat crosscultureel model is, een persoonlijkheidstaxonomie die de algemeen-menselijke natuur weerspiegelt. Wat wel vaststaat, is dat er onafhankelijk Big Five-achtige structuren zijn gevonden met lexicale tests in Germaanse en Slavische talen zoals het Engels, Duits, Kroatisch, Tsjechisch, Pools en het Nederlands (Saucier & Srivastava 2015:291). Bovendien is de structurele validiteit van de domeinen én de vijftien facetten in een Nederlandse context bevestigd, en zijn er gestandaardiseerde tests ontworpen met testitems die goede predictoren blijken te zijn voor de Big Five (Denissen et al. 2019:15). Op die manier is een factoranalyse van een grote hoeveelheid testitems niet nodig. Hoewel de Big Five misschien niet helemaal crosscultureel generaliseerbaar zijn, is de taxonomie dus wel ‘lokaal’ bruikbaar in een Nederlandstalige context, zoals bij deze studie (zie ook hoofdstuk 4.2.2).
3.4 De relatie tussen de Big Five en gedrag
Hoe moeten correlaties tussen domeinscores en gedrag geïnterpreteerd worden? Een zwaktepunt van de Big Five is de atheoretische aard van het model. De Big Five biedt in essentie geen verklarende theorie voor de psychologische mechanismen die aan de basis liggen van gedrag, maar voornamelijk een beschrijving van dat gedrag (Boyle et al. 2008:14). Het concept ‘persoonlijkheid’ is in die opvatting slechts een regelmatigheid van een bepaald soort gedrag in een bepaalde soort situatie. Neem het volgende voorbeeld: uit onderzoek blijkt dat iemand die hoog scoort op Extraversie meer kans maakt om vreemden te benaderen op een feestje (zie Tabel 1). Wie vaker vreemden benadert op feestjes zal gemiddeld positiever antwoorden op de vraag “ben jij iemand die snel vreemden benadert op feestjes?”, en bovendien zullen kennissen ook positiever antwoorden op de vraag “is [de persoon in kwestie] iemand die snel vreemden benadert op feestjes?” (John et al. 2008:120). Zowel peer als- en zelfevaluaties zullen dus uitwijzen dat die persoon hoog scoort op het (fictieve) persoonlijkheidskenmerk Vreemden benaderen op feestjes. Dat kenmerk is echter slechts een beschrijving van observeerbaar gedrag; het beschrijft geen psychologische, neurologische of genetische factor die causaal verklaart waarom iemand vreemden benadert op feestjes. Voor de persoonlijkheidsdomeinen geldt hetzelfde principe. Elk domein is immers een soort geabstraheerde cluster van specifiekere persoonlijkheidstrekken zoals Vreemden benaderen
op feestjes. Zo is een hoge score voor Extraversie geen verklaring voor typisch extravert
gedrag, maar wijst het slechts op een algemene neiging om vaker extravert gedrag te vertonen, zoals vreemden benaderen op feestjes of bijvoorbeeld sneller voortouw nemen bij een project (Soto & John 2008:120). Het impliceert dus een zekere circulariteit om de Big Five
te interpreteren als een verklaring voor (talig) gedrag, eerder dan een beschrijving (John et al. 2008:145-146). Als uit dit onderzoek blijkt dat wie hoogt scoort op Vriendelijkheid bepaalde belgicismen vaker goedkeurt, wijst dat dus enkel op een correlatie. Over andere verbanden of verklarende mechanismen kan er op basis van die correlatie er natuurlijk gespeculeerd worden, maar tot er verder onderzoek is blijft het dus bij (geïnformeerd) giswerk.
Enkele auteurs hebben voorgesteld dat de vijf domeinen net wel een in een causaal verband staan met gedrag: hun voornaamste argument is dat de persoonlijkheidsdomeinen een biologische component zouden hebben, meer bepaald een genetische basis. DeYoung et al. (2007) beschrijven bijvoorbeeld twee genetische factoren die significant correleren met scores op de domeinen en andere hiërarchische niveaus (894). Bovendien ontdekte een meta-analyse dat erfelijkheid tot 40% van de intersprekervariatie verklaart met betrekking tot persoonlijkheidsscores (Vucasović & Bradko 2015:780). Als biologie – alleszins gedeeltelijk – gedrag verklaart, en de Big Five hebben een biologische basis, zijn ze dan niet ook verklarend in plaats van beschrijvend? Saucier & Srivastava (2015) waarschuwen tegen die conclusie: de
Big Five-taxonomie is gegroeid uit een lexicaal-sociaal model van persoonlijkheid, niet als
louter biologisch model noch als biosociaal model. De vijf-factorenstructuur capteert de structuur van observeerbaar gedrag, maar niet noodzakelijk de structuur van de genetische kernen die gedrag en persoonlijkheid beïnvloeden. De exacte relatie tussen genetische factoren, de Big Five en gedrag is nog niet goed genoeg begrepen (298-299). Voorlopig lijkt het dus veiliger om de Big Five te gebruiken op een beschrijvende manier eerder dan op een verklarende manier.
Het ‘beschrijvende’ karakter van de Big Five heeft onderzoekers er echter niet van weerhouden om op zoek te gaan naar allerlei gedragsvariabelen die correleren met de persoonlijkheidsdomeinen. Consciëntieusheid is bijvoorbeeld een predictor voor sterkere prestaties in een onderwijscontext, terwijl lage scores voor die dimensie dan weer overeenkomen met een kortere levensduur, omdat Consciëntieusheid een negatieve predictor is voor roken, slechte eet- en beweeggewoontes en druggebruik (John et al. 2008:120). Ook op taalvlak zijn er al heel wat studies verricht met behulp van de Big Five. Zo onderzochten Fabbro et al. (2019) de intersprekerverschillen bij het vertellen van verhalen. Ze vonden allerlei correlaties met persoonlijkheidsdomeinen: individuen met hogere scores op
Vriendelijkheid en Extraversie, gebruiken gemiddeld een kleinere verscheidenheid aan
woorden (i.e. een lager type/token-ratio) in hun verhalen. Onafgewerkte zinnen, afgebroken woorden en herhalingen correleren ook met Vriendelijkheid maar negatief met Extraversie (Fabbro et al. 2019:293-294). De persoonlijkheidsdomeinen kunnen dus in verband worden gebracht met vertelstijl.
Een andere belangrijke interesse in het onderzoeksveld is het voorspellen van persoonlijkheidsscores aan de hand van taalgebruik. Mairesse & Walker (2006) trainden bijvoorbeeld een computerprogramma om persoonlijkheidskenmerken voorspellen op basis
van zowel geschreven tekst als (getranscribeerde) gesproken tekst. Hun experiment was succesvol: met behulp van de semantische klassen van woorden (bijvoorbeeld woorden van woede), zinstypes, zinslengte of het totaal aantal woorden kon hun programma de Big Five van een spreker of schrijver relatief accuraat in kaart brengen. Vooral de positieve relatie tussen Extraversie en het totaal woordenaantal viel op (Mairesse & Walker 2006:546-547). Een studie van Facebookberichten vond gelijkaardige resultaten, waarbij Extraversie opnieuw de belangrijkste variabele was en bijvoorbeeld correleerde met enthousiaste woorden zoals
best, stoked of pumped en met sociale woorden zoals party, hanging of dinner. Introvertere
deelnemers gebruikten vaker voorzichtigere woorden, bijvoorbeeld probably, suppose of
apparently (Park et al. 2015:942). In het Nederlandse taalgebied is de situatie gelijkaardig:
Vandenhoven en De Clercq (2016) ontdekten een vergelijkbare correlatie in hun onderzoek van Nederlandstalige tweets. Nederlandstaligen die laag scoren op Extraversie praten bijvoorbeeld meer over de dood, verdriet en negatieve emoties in het algemeen (40-41). De rode draad doorheen deze studies is dat Extraversie het persoonlijkheidsdomein lijkt te zijn dat het sterkst correleert met taalkenmerken.
Het onderzoeksveld dat talig gedrag bestudeert in het licht van de Big Five is de laatste decennia in opmars, en is te uitgebreid om hier volledig te bespreken. Wat echter opvalt aan de hierboven genoemde onderzoeken en aan de literatuur in het algemeen, is dat tot nu toe enkel taalproductie bestudeerd werd. Naar mijn weten bestaat er geen enkele studie die taalattitudes of acceptabiliteitsoordelen in verband brengt met de persoonlijkheidsdomeinen. Het doel van deze studie is dan ook om dat gat enigszins op te vullen; we gaan na of de Big
Five of de onderliggende facetten correleren met de taalattitudes van Nederlandstaligen ten
4. Methodologie
De vorige hoofdstukken bespraken de positie van Belgisch Nederlands en het theoretische kader van dit onderzoek. De vraag rijst nu hoe er kan worden nagegaan in welke mate Vlamingen (en Nederlanders) verschillende belgicismen accepteren, op een manier die ons toelaat om acceptabiliteit kwantitatief in verband te brengen met de persoonlijkheid van de deelnemers. Met dat doel voor ogen werd er een online enquête opgesteld. Die brengt niet alleen de domein- en facetscores van de deelnemers in kaart, maar bevat ook testzinnen met ofwel een belgicisme ofwel de ‘algemene’ tegenhanger van een belgicisme. De respondenten moeten vervolgens oordelen hoe geschikt ze de zinnen vinden voor een formele, geschreven gebruikscontext (een krant). De rest van dit hoofdstuk beschrijft de selectie van de taalvariabelen, de verschillende onderdelen van de enquête, de deelnemersprofielen en de werkwijze bij de data-analyse.
4.1 Selectie van de taalvariabelen
Natuurlijk kan dit onderzoek slechts een kleine steekproef van het totale aantal belgicismen bestuderen. In wat volgt wordt er toegelicht welke selectiecriteria gehanteerd werden om tot een werkbaar aantal belgicismen te komen, en vervolgens worden de gekozen variabelen beschreven.
4.1.1 Selectiecriteria
De variabelenselectie gebeurde op basis van drie criteria. Ten eerste worden er zo veel mogelijk enkel belgicismen geselecteerd die een algemeen Nederlandse tegenhanger hebben, een tegenhanger die dus gangbaar is in het hele taalgebied. Zo kunnen de acceptabiliteitsscores van een Belgische variant dus vergeleken worden met de acceptabiliteitsscores van een algemenere variant, wat de interpretatie van de resultaten vergemakkelijkt. De acceptabiliteitsscore van een belgicisme als ajuin is bijvoorbeeld informatiever wanneer de score van ui ook gekend is. Sommige Belgische woorden zoals
vieruurtje hebben geen duidelijke algemene tegenhanger, en worden daarom uitgesloten.
Ten tweede wordt er zo veel mogelijk gezocht naar taalkenmerken met een brede geografische spreiding binnen (Nederlandstalig) België, maar niet daarbuiten. Dit onderzoek richt zich immers op belgicismen in de strikte, pan-Belgische zin; het niveau van dialecten en regiolecten is hier minder relevant. Het doel is dus om de acceptabiliteit te testen van kenmerken die in principe endogeen zijn voor alle Belgische deelnemers, maar exogeen voor Nederlandse deelnemers. Het woord tengel (‘brandnetel’) komt bijvoorbeeld niet voor in Nederland, maar echt pan-Belgisch is het ook niet: er zijn heel wat plaatsen in België waar
tengel niet gezegd wordt, bijvoorbeeld in een groot deel van West-Vlaanderen (Lefebvre &
Triest: 2012:122).
Ten slotte wordt er gekozen voor taalkenmerken die verschillende subtypes van belgicismen vertegenwoordigen. Het ene belgicisme is namelijk het andere niet: het onderzoek van De
Standaard heeft uitgewezen dat er sterke verschillen zijn in de acceptabiliteit van Belgische taalfenomenen, afhankelijk van welk fenomeen precies bestudeerd wordt (De Schryver 2014:5). In een poging om die variatie beter te begrijpen, onderscheiden we verschillende categorieën die de acceptabiliteit van de belgicismen kunnen helpen verklaren. We kijken niet enkel naar lexicale, maar ook naar syntactische fenomenen, en maken binnen daarnaast nog eens onderverdelingen op basis van de status van het belgicisme: is het standaardtalig, en zo nee, hoe sterk wordt het belgicisme afgekeurd in de literatuur?
De eerste onderverdeling die dit onderzoek maakt, is dus op basis van taaldomein: BN heeft niet enkel een unieke woordenschat, maar ook eigen fonologische, morfologische en syntactische kenmerken. Uit onderzoek naar gesproken taalgebruik blijkt dat de saillantie (i.e. de ‘opvallendheid’) van niet-standaardtalige taalkenmerken verschilt per taaldomein. Grammaticale taalkenmerken blijken namelijk gemiddeld minder saillant te zijn dan lexicale kenmerken. Taalgebruikers zouden sneller een niet-standaardtalige woordenschat opmerken dan niet-standaardtalige morfo-syntactische kenmerken (Lybaert 2014:11; van Bree 2000:42). Het is goed mogelijk dat dit verschil in saillantie zich ook voordoet bij geschreven taalgebruik, wat een impact kan hebben op de acceptabiliteitsscores. Daarom worden in dit onderzoek grammaticale belgicismen onderscheiden van lexicale belgicismen. Om de mogelijke invloed van het taaldomein verder te beperken, kiezen we in de praktijk enkel voor syntactische belgicismen als grammaticale variabelen. Morfologische belgicismen komen dus niet aan bod. De belgicismen worden op de tweede plaats onderverdeeld op basis van standaardtaligheid. Sommige belgicismen worden doorgaans tot de (Belgische) standaardtaal gerekend, zoals
vliegenraam of lintmeter. Voor veel Belgische taalkenmerken is dat echter niet het geval
(bomma of congé), waardoor die vormen al minder geschikt zijn voor een formele, geschreven gebruikscontext. Standaardtalige en niet-standaardtalige varianten moeten dus uit elkaar gehouden worden. Bovendien is er binnen het niet-standaardtalige type ook nog eens een onderscheid te maken, als gevolg van het taalzorgbeleid in Vlaanderen: heel wat belgicismen zijn jarenlang expliciet afgekeurd en zo het collectieve bewustzijn ingegaan als fouten (een prototypisch voorbeeld is noemen in plaats van het standaardtalige heten), maar dat is zeker niet het geval voor alle niet-standaardtalige belgicismen. Een onderscheid op basis van prominentie in taalzorg- en taalhulpliteratuur kan dus nuttig zijn: het is goed mogelijk dat belgicismen die bekend staan als ‘Vlaamse fouten’ minder geaccepteerd worden dan belgicismen die ook niet-standaardtalig zijn, maar minder bekend zijn in de taalzorg.
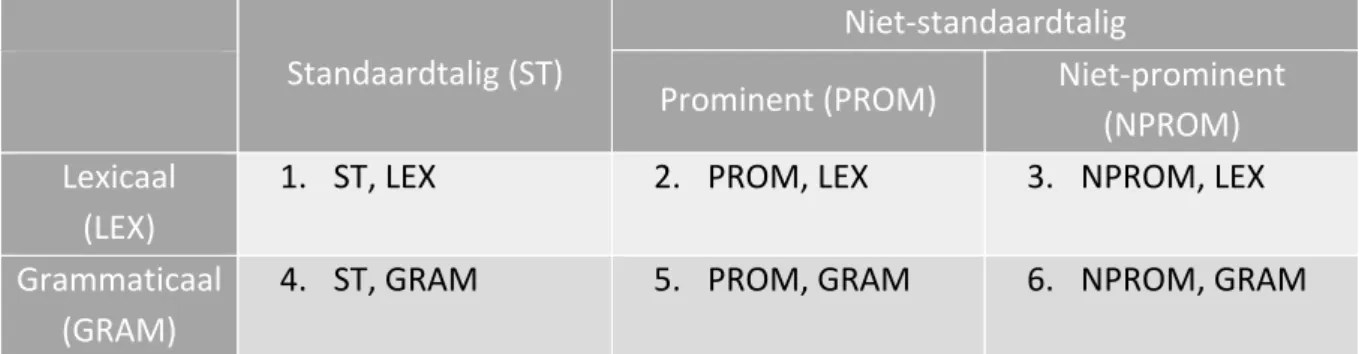
De belgicismen zijn dus verdeeld in zes ‘subtypes’ (cf. Tabel 3) aan de hand van de volgende criteria. Elke groep moet door een gelijk aantal variabelen vertegenwoordigd worden.
1. Lexicaal (LEX) versus grammaticaal (GRAM)
2. Standaardtalig (ST) versus niet-standaardtalig (NST)
a. Niet-standaardtalig en prominent in taalzorgliteratuur (PROM) versus niet-standaardtalig en niet prominent in taalzorgliteratuur (NPROM)
Standaardtalig (ST)
Niet-standaardtalig
Prominent (PROM) Niet-prominent (NPROM) Lexicaal
(LEX)
1. ST, LEX 2. PROM, LEX 3. NPROM, LEX
Grammaticaal (GRAM)
4. ST, GRAM 5. PROM, GRAM 6. NPROM, GRAM
Tabel 3 - De zes subtypes van belgicismen
Hoe kunnen de cellen in Tabel 3 ingevuld worden? Het standaardtaligheidscriterium biedt een eerste uitdaging. Objectief bepalen wat wel en niet behoort tot de standaardtaal, is onmogelijk. Het Nederlandse taalgebied heeft namelijk geen normatief orgaan dat een standaard voorschrijft. Was dit wel zo, dan is dat nog geen garantie dat de officiële standaardtaal een mentale realiteit weerspiegelt bij de taalgebruikers. De dichotomie ST-NST is dus slechts een rudimentaire opdeling die op zijn best die mentale realiteit kan benaderen, en alle mogelijke criteria voor die opdeling zijn dus enigszins arbitrair. Om de subjectiviteit zo veel mogelijk te beperken wordt er gekozen voor twee autoritaire werken om te definiëren wat standaardtalig is: de 15e editie van de Dikke van Dale (2015) en versie 1.3 van de e-ANS (2012), die gebaseerd is op de 2e herziene editie van de Algemene Nederlandse Spraakkunst (1997).
Niet-standaardtalige lexicale items krijgen in de Dikke van Dale het label BE; niet algemeen, en standaardtalige lexicale items enkel het label BE. Van Dale geeft het label spreektalig aan woorden die niet standaardtalig zijn maar enkel typisch zijn voor gesproken taal. Spreektalige woorden worden uitgesloten bij de selectie. De standaardtaligheid van grammaticale items wordt bepaald aan de hand van de e-ANS: zij hanteren het label regionaal voor niet-standaardtalige belgicismen en neerlandismen. Enkel wat geen label krijgt, dus ook niet de labels formeel of uitgesloten, beschouwen zij als deel van de (Belgische) standaardtaal. Belangrijk is dat beide werken zichzelf zien als descriptief, niet prescriptief. Met andere woorden, de van Dale en de e-ANS proberen slechts de taal te beschrijven, niet voor te schrijven. Volgens die filosofie is iets standaardtaal wanneer de taalgebruikers het zelf standaardtalig vinden, en het is slechts de taak van de van Dale en de e-ANS om die standaardtaal te beschrijven. Toch erkennen de twee werken dat er natuurlijk altijd een normatief aspect vasthangt aan zulke naslagwerken. De van Dale ziet het als een cirkel: door te documenteren wat gangbaar is, worden er een bepaalde normatieve status van taalkenmerken (onbedoeld) bevestigd (van Dale 2015). Er is dus een deels circulaire relatie tussen wat de twee werken zien als standaardtaal, en wat taalgebruikers zelf correct vinden in een standaardtaalcontext (zoals in dit onderzoek, 4.2.2). Het is belangrijk dat die circulariteit in rekening gebracht wordt tijdens de analyse.