DATADRIVEN MISDAADBESTRIJDING
EEN CASESTUDIE NAAR DE MEERWAARDE VAN CRISP-DM ALS
RAAMWERK VOOR DATADRIVEN MISDAADBESTRIJDING EN DE
ROL VAN BELEID IN DIT RAAMWERK
Aantal woorden: <24.295>
Bo Van Daele
Stamnummer: 01601883Promotor: Prof. Dr. Len Lemeire
Masterproef voorgelegd voor het behalen van de graad :
Master of Science in de Bestuurskunde en Publiek Management
II
VERTROUWELIJKHEIDSCLAUSULE
Ondergetekende verklaart dat de inhoud van deze masterproef mag geraadpleegd en/of
gereproduceerd worden, mits bronvermelding.
Naam student Bo Van Daele
III
ABSTRACT
Datadriven misdaadbestrijding maakt de laatste decennia steeds meer zijn intrede in de Vlaamse politiezones. Echter is er weinig geweten over de manier waarop elke zone dit aanpakt. Daarnaast is er niet veel bekend over de relatie tussen datagedreven werken en de invloed van beleid op de werking. Door middel van een literatuurstudie en case study wordt er een antwoord geboden op de onderzoeksvraag ‘In welke mate is CRISP-DM geschikt als
raamwerk voor datadriven misdaadbestrijding?’ en de subvraag ‘Welke rol speelt beleid in dit raamwerk?’.
Uit de literatuurstudie komt duidelijk naar voren dat CRISP-DM een goede basis is voor datamining processen. Verder kan er uit de literatuurstudie geconcludeerd worden dat er overeenstemmingen zijn tussen CRISP-DM en beleid. Dankzij de casestudie wordt het duidelijk dat het mogelijk is om het CRISP-DM raamwerk toe te passen bij datadriven misdaadbestrijding projecten. Maar dat het belang van beleid niet herkend wordt. Of het raamwerk ook geschikt is voor datadriven misdaadbestrijding hangt af van het probleem dat wordt aangepakt in het project. Wanneer er sprake is van een complex probleem zal het raamwerk doorgaans niet geschikt zijn.
IV
WOORD VOORAF
Deze masterproef wordt voorgedragen tot het behalen van het diploma Master Bestuurskunde en Publiek Management.
Het schrijven van deze masterproef heeft mij in eerste instantie zeer veel bijgeleerd. Het bestuderen van CRISP-DM en datamodellen was voor mij een nieuwe ervaring. Daarom zou ik eerst en vooral mijn promotor, Prof. Dr. Len Lemeire, willen bedanken om mij de kans te geven dit interessant onderwerp te mogen onderzoeken. Verder wil ik hem bedanken voor het ondersteunen en begeleiden van mijn masterproef. De feedbacksessies hebben ervoor gezorgd dat mijn masterproef elke keer weer de juiste richting in werd gestuurd.
Verder zou ik graag ook alle politiezones bedanken die ik heb mogen interviewen en zo meegewerkt hebben aan mijn masterproef. Zonder de interviews zou dit onderzoek niet mogelijk zijn geweest.
Als laatste zou ik graag mijn familie, vrienden en medestudenten bedanken om mij te steunen tijdens het schrijven van mijn masterproef en voor hun kritische mening. Ook mijn werkgroep bij de werksessie onderzoeksmethoden hebben mij opbouwende kritiek gegeven en mij goede aanbevelingen gegeven.
Gent, juni 2020 Bo Van Daele
V
PREAMBULE CORONAMAATREGELEN
Door de intrede van het COVID-19 virus in 2020 te België, werden over heel het land strenge coronamaatregelen getroffen. Vanaf 18 maart 2020 werden deze maatregelen verstrengd. Deze maatregelen hielden onder andere een verbod op samenkomst en niet-essentiële verplaatsingen in. Deze maatregelingen maakten mij het niet langer meer mogelijk om persoonlijk de interviews af te nemen.
Doordat het hele land in rep en roer was, werd er ook meer inspanning van de politie gevraagd. Voor het verzamelen van de data, werden er vanaf oktober 2019, politiezones gecontacteerd met de vraag of ze wilden bijdrage aan het onderzoek en bereid waren tot een interview. In totaal waren er acht politiezones bereid te helpen: Oostende, VLAS (Kortrijk), Brugge, Aalst, Gent, Turnhout, CARMA (Genk) en Sint-Niklaas.
Door de steeds meer verstrengde maatregelen haakten Oostende, VLAS, Brugge, Aalst en CARMA af, ook al hadden deze zones interesse om deel te nemen aan het onderzoek. De coronacrisis vergt 100% procent van de capaciteit van het politiekorps, daarom is het niet mogelijk om tijd vrij te maken voor een onderzoek. Hierdoor is het praktijkonderzoek van de masterproef enorm geslonken en werd er maar met een beperkt aantal cases gewerkt.
Deze preambule werd in overleg tussen de student en de promotor opgesteld en door beiden goedgekeurd.
VI
INHOUDSTAFEL
VERTROUWELIJKHEIDSCLAUSULE II ABSTRACT III WOORD VOORAF IV PREAMBULE CORONAMAATREGELEN V INHOUDSTAFEL VILIJST MET GEBRUIKTE AFKORTINGEN IX
LIJST VAN FIGUREN IX
LIJST MET TABELLEN IX
INLEIDING 1
1 LITERATUURSTUDIE 3
1.1 CRISP-DM 3
1.1.1 DATAMINING 3
1.1.2 CRISP-DM-PROCES 4
1.1.3 VOOR EN NADELEN VAN CRISP-DM 9
1.1.4 WAARDEN VAN DATA 10
1.1.5 PREDICTIVE POLICING 13
1.2 BELEID 21
1.2.1 BELEIDSPROCES 21
1.2.2 BELEIDSPROBLEMEN 32
1.2.3 MISDAADBESTRIJDING 33
1.3 COHERENTIE CRISP-DM EN BELEID 38
VII 1.3.2 AFSTEMMING CONFUSIONMATRIX 40 1.3.3 KENNIS UITWISSELING 41 2 METHODOLOGIE 43 2.1 LITERATUURSTUDIE 43 2.2 CASESTUDIE 43 2.2.1 CASESELECTIE 44 2.2.2 DATAVERZAMELING 45 2.3 DATA-ANALYSE 47 2.3.1 CODEBOOM 47 3 CASESTUDIE 49 3.1 POLITIEZONE GENT 49
3.1.1 PROJECT ANPR-CAMERA’S 49
3.2 POLITIEZONE TURNHOUT 55
3.2.1 PROJECT ANPR-CAMERA’S 55
3.3 POLITIEZONE SINT-NIKLAAS 61
3.3.1 PROJECT DRUGSDEALING 61
4 DISCUSSIE 70
4.1 LIMITATIES VAN HET ONDERZOEK 72
4.2 AANBEVELINGEN TOT VERDER ONDERZOEK 73
CONCLUSIE 74
REFERENTIES X
BIJLAGE XVIII
BIJLAGE 1.VRAGENLIJST XVIII
VIII
BIJLAGE 3.CIJFERS X
BIJLAGE 3.1.CIJFERS ONGEVALLEN OP HET GRONDGEBIED GENT X
BIJLAGE 3.2EVOLUTIE VEILIGHEID – VERKEER (TURNHOUT) X
BIJLAGE 3.3.RESULTATEN MODULE BLACKLISTCONTROLE (TURNHOUT) XI
BIJLAGE 4.TRANSCRIPTIES XII
BIJLAGE 4.1.POLITIEZONE GENT XII
BIJLAGE 4.2.POLITIEZONE TURNHOUT XVI
IX
LIJST MET GEBRUIKTE AFKORTINGEN
ANPR Automatic Number Plate Recognition
APO Ambtshalve Politionele Onderzoek
CAS Criminaliteit Anticipatie Systeem
CRISP-DM Cross Industry Standard Process for Data Mining
DDD Data-driven-decision making
GIS Geografische informatiesystemen
LIK Lokaal Informatie Kruispunt
PZ Politiezone
LIJST VAN FIGUREN
Figuur 1: Schematische voorstelling van het dataminingproces (KDD) (Fayyad, et.al., 1996). 4
Figuur 2: CRISP-DM (Chapman et al., 2000) 4
Figuur 3: Data Value Escalator (Gartner, 2016) 12
Figuur 4: De vier analytische mogelijkheden (Gartner, 2016) 13
Figuur 5: Het beleidsproces (Hoogerwerf, 1998) 21
Figuur 6: Probleemstappenplan (Dunn, 2004) 22
Figuur 7: Barrièremodel (Bachrach & Baratz, 1970) 25
Figuur 8: Stromenmodel (Kingdon, 1985) 26
Figuur 9: Soorten formulering (Howlett, Ramesh & Perl, 2009) 27 Figuur 10: Overzicht evaluatiecriteria wat, wanneer en waarom (Winter, 2014) 31
Figuur 11: Proces CRISP-DM en beleidsuitvoering 38
LIJST MET TABELLEN
Tabel 1: Verschillende tools voor het verzamelen en analyseren van data (Provost & Fawcett, 2013) 6 Tabel 2: Raamwerk van data (Lemeire, Maes & Clarysse, 2018; Pipino, Lee & Wang, 2002) 11
Tabel 3: Confusion matrix 17
1
INLEIDING
De ontwikkeling van data en technologie draagt op vele manieren bij aan de maatschappij, waaronder ook aan misdaadbestrijding. Dankzij het hanteren van verschillende technologieën zijn politiezones niet alleen in staat misdaad te bestrijden, maar ook te voorspellen. Het ontstaan van verschillende technieken, technologieën en de exponentiële groei van data, zorgen voor een overvloed aan mogelijkheden.
Vandaag de dag zijn er al verschillende politiezones bezig met het ontwikkelen van technologie op het vlak van datadriven misdaadbestrijding. Doch valt er op te merken dat politiezones in hun eigen silo’s werken en dat er weinig sprake is van inter-organisatorische samenwerkingen op het vlak van datadriven misdaadbestrijding.
Deze masterproef onderzoekt of CRISP-DM een goede basis is om datadriven te werken. Het is de bedoeling om een antwoord te bieden op de onderzoeksvraag ‘In welke mate is
CRISP-DM geschikt als raamwerk voor datadriven misdaadbestrijding?’.
Gedurende het onderzoek, is het de bedoeling om te onderzoeken of CRISP-DM kan dienen als een alomvattend raamwerk voor datadriven misdaadbestrijding. Het raamwerk zorgt voor een procedure die gevolgd kan worden door politiezones om datadriven projecten op te starten.
Daarenboven wordt in het onderzoek onderzocht of beleid een invloed heeft op het model. Aangezien de burgemeester aan het hoofd staat van de politie zal er een wisselwerking zijn tussen beleid en datadriven misdaadbestrijding. De subvraag voor dit onderzoek is ‘Welke rol
speelt beleid in dit raamwerk?’. Voor deze subvraag worden er bij verschillende aspecten
van beleid stil gestaan. Er wordt zowel gekeken naar de hoe beleid wordt uitgevoerd, het beleidsproces, de beleidsproblemen en de kenmerken van misdaadbestrijding. Zorgt beleid voor een bemoeilijking van het invoeren van datadriven te werken of ondersteunt het beleid de politiezone en kan er gesproken worden van een samenwerking tussen de zones en de verschillende beleidsinstanties?
2
Het onderzoek start met een literatuuronderzoek, een theoretische verdieping waar de verschillende concepten uitvoerig worden besproken. Dit eerste hoofdstuk bestaat uit drie delen: CRISP-DM, beleid en coherentie CRISP-DM en beleid. In elk deel wordt er een beeld gevormd wat deze concepten inhouden en worden relevante begrippen uitvoerig besproken. In hoofdstuk 2, de methodologie, wordt er geëxpliceerd hoe het onderzoek wordt aangepakt en welke methode er is gehanteerd. Er wordt uitgelegd hoe de selectie van cases is gebeurd, hoe de data is verzameld en op welke manier de data is verwerkt. Hoofdstuk 3 is de casestudie waarin de verschillende cases worden toegelicht. In dit hoofdstuk wordt elke politiezone voorgesteld, gevolgd door een uitvoerige analyse van de cases. In de discussie, hoofdstuk 4, wordt een antwoord geformuleerd op de onderzoeksvraag aan de hand van de bevindingen uit de casestudie. Daaropvolgend worden de limitaties van het onderzoek en de aanbevelingen tot verder onderzoek gegeven. Het onderzoek van deze masterproef wordt afgesloten met een conclusie.
3
1 LITERATUURSTUDIE
Het literatuuronderzoek bij dit onderzoek bestaat uit drie grote luiken: CRISP-DM, beleid en de coherentie tussen CRISP-DM en beleidsuitvoering. Elk luik wordt op zijn beurt uitvoerig besproken.
1.1
CRISP-DM
Het Cross Industry Standard Process for Data Mining, of kortweg CRISP-DM, is een toepassing van een datamining-proces. Het wordt gebruikt om een oplossing te vinden voor een bedrijfsprobleem. Deze oplossing wordt dikwijls gevonden onder de vorm van een model. Het model wordt gebruikt om te bestuderen hoe de dataset zich zal gedragen ten opzichte van het desbetreffende bedrijfsprobleem (Lemeire, Maes & Clarysse, 2018). CRISP-DM heeft een significante impact op het ordenen van data. Het voorziet een aanpak die gefocust is op de taak van de data (Saltz, 2015).
1.1.1
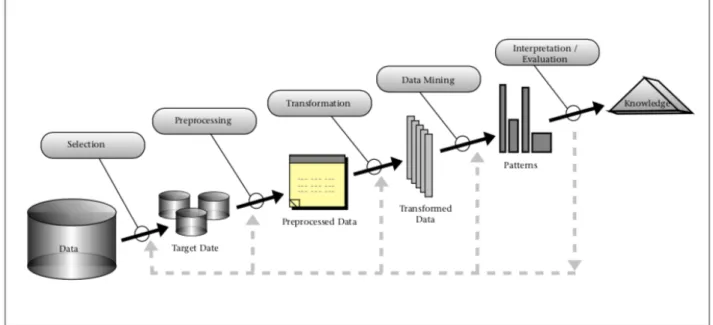
DataminingDatamining is een ambacht, het is het vakmanschap dat wordt gebruikt om data te analyseren. Door het analyseren via computermodellen, is het mogelijk om bepaalde verbanden bloot te leggen tussen data. Door deze verbanden in kaart te brengen kan men een model opbouwen dat kan leiden tot nieuwe bedrijfskennis. Met deze kennis kunnen bedrijven of organisaties op hun beurt data gedreven beslissingen maken. In figuur 1 wordt weergegeven hoe data wordt omgezet in patronen dankzij datamining om deze vervolgens dankzij interpretaties te ontwikkelen tot kennis. Deze kennis maakt het mogelijk om klantenrelaties te managen. Het gedrag van een klant kan geanalyseerd worden in een poging om de afslijting en de maximum verwachtte waarde van de klant te managen (Provost & Fawcett, 2013).
Datamining is het onttrekken van kennis uit data door gebruik te maken van technologie. Een belangrijke tool hierbij is “domain knowledge”. Door het hanteren van “domain knowledge” wordt er gebruikt gemaakt van de specifieke kennis omtrent het vakgebied. Hoe beter het analytisch denken, des te meer er intuïtie ontwikkeld zal worden om te weten hoe en wanneer creativiteit en “domain knowledge” te implementeren in het proces (Provost & Fawcett, 2013).
4
Figuur 1: Schematische voorstelling van het dataminingproces (KDD) (Fayyad, et.al., 1996).
1.1.2
CRISP-DM - ProcesHet CRISP-DM-proces bevat verschillende fasen die doorlopen worden gedurende het proces. Deze zes CRISP-DM-fasen zijn een iteratief cyclisch proces, wat betekent dat de volgorde van de fasen niet vaststaat. Wanneer het CRISP-DM-proces volledig doorlopen is, zonder dat er een bedrijfsprobleem is vastgesteld, betekent het niet dat er gefaald werd. Door de constante herhaling en het doorlopen in fasen, begrijpt de onderzoeker het bedrijfsprobleem en de beschikbare data beter. Door de extra informatie kan er bij fase drie
en vier, het transformeren en modelleren, beter op elkaar ingespeeld worden. Op deze manier wordt iedereen steeds beter geïnformeerd bij het opnieuw doorlopen van de fasen (Provost & Fawcett, 2013). De zes fasen van het CRISP-DM-proces zijn de volgende:
1. Begrijpen van het bedrijfsprobleem 2. Begrijpen van de beschikbare data
3. Transformeren van de data zodat men op zoek kan gaan naar een model
4. Het eigenlijke modelleren van de data 5. Het evalueren van het model
6. Het uitrollen van het model binnen de bedrijfsvoering
5
Bedrijfsprobleem begrijpen
In de eerste fase van CRISP-DM is het noodzakelijk om het probleem dat opgelost moet worden, te begrijpen. Het is de bedoeling om begrip te krijgen van het doel dat voor ogen is om het in een probleem te kunnen vertalen (Hoogstrate, Veenman, van Ypenburg, 2012). Zoals reeds aangehaald, moet dit niet vanaf de eerste keer dat het proces wordt doorlopen. Dankzij het cyclisch proces wordt er vaak teruggekoppeld naar het begrijpen van het bedrijfsprobleem. Het begrijpen van een bedrijfsprobleem lijkt eenvoudig maar is het niet. Een bedrijfsprobleem biedt zich zelden duidelijk en concreet aan, vaak is er een constante wisselwerking tussen het schetsen van een probleem en het bedenken van een oplossing (Provost & Fawcett, 2013). Er wordt gefocust op het begrijpen van de doelstellingen en noden vanuit het bedrijfsperspectief. Het is belangrijk om het juiste beeld voor ogen te krijgen zodat het bedrijfsprobleem kan worden geschetst. Met de kennis die uit deze fase wordt gehaald, kan er een beraamd plan opgesteld worden om de doelstellingen en noden te kunnen bereiken (Chapman, et al., 2000).
Beschikbare data begrijpen
Het doel van CRISP-DM is om tot een dataset te komen dat bijdraagt tot het oplossen van een bedrijfsprobleem. Hiervoor is het belangrijk dat er relevante data verzameld wordt. Vervolgens moet de verzamelde data verkend worden om te beslissen of de data al dan niet kan bijdragen om het bedrijfsprobleem aan te pakken (Hoogstrate, Veenman, van Ypenburg, 2012). Tijdens deze fase wordt er heel veel data verzameld alsook eerste inzichten verworven. Deze beschikbare data bestaat nu nog maar uit een ruwe gegevens (Provost & Fawcett, 2013). Daarom is het de bedoeling om met de datagegevens vertrouwd te geraken zodat de gebruiker in staat is om met de gegevens het probleem te identificeren. Aan het einde van deze fase wordt de kwaliteit van de verzamelde data gecontroleerd (Chapman, et al., 2000).
Het is ook belangrijk om de krachten en grenzen van de data te weten, omdat de data slechts zelden direct een antwoord zullen bieden op het bedrijfsprobleem. Verder moet er rekening worden gehouden met het feit dat elke soort databank een andere vorm heeft alsook een andere kostprijs. Data zijn niet altijd beschikbaar voor iedereen op dezelfde manier, sommige data zijn makkelijk en gratis online te verkrijgen terwijl andere data veel moeite kunnen kosten om te verkrijgen. Wanneer er een bedrijfsprobleem is waarover nog geen data bestaat, moet er een project worden opgezet om data rond het probleem te verzamelen. Bij zo’n projecten komt veel werk kijken. Enerzijds kost het veel om alle data te verzamelen. Anderzijds vereist
6
het veel moeite om alle verworven data in dezelfde vorm te transformeren. Het is belangrijk dat bij elke databron de voordelen tegenover de nadelen worden afgewogen en dat er gekeken wordt of het nuttig is om er verder in te investeren. Niet enkel het verwerven van databronnen kan veel moeite vergen, ook het vergelijken van de verschillende bronnen is niet efficiënt (Provost & Fawcett, 2013).
Gedurende deze fase kan het een voordeel zijn dat de creativiteit van een analist naar boven komt. Dit kan de sleutel naar succes zijn voor het vinden van een creatieve probleemformulering ten opzichte van wanneer het probleem wordt beschouwd als een dataprobleem. Vaak is het niet eenvoudig om data te vinden waarmee er kan gemeten worden of een probleem al dan niet wordt aangepakt. Door creatief om te gaan met de data en de formulering van het probleem, kunnen er innovatieve manieren gevonden worden om dat ene probleem aan te pakken. Creatieve manieren kunnen bijvoorbeeld het hanteren van verschillende tools zijn. Het is typisch dat in de vroege fasen van CRISP-DM, wanneer er een oplossing moet worden ontworpen, er veel tools worden gehanteerd. Andere mogelijkheden om creatief te werk te gaan met data zijn ook mogelijk. Zo ontwikkelen sommigen organisaties eigen beeldvormingen op basis van de data. Enkele voorbeelden van tools die kunnen helpen bij het zoeken naar data en het analyseren daarvan (Provost & Fawcett, 2013):
Tabel 1: Verschillende tools voor het verzamelen en analyseren van data (Provost & Fawcett, 2013)
Clusteren Poogt om individu’s samen te groeperen in een populatie op basis van hun gelijkenissen.
Classificatie Poogt voor een individu in een bevolking te voorspellen tot welke klasseset het individu behoort. Meestal is de klasse onderling exclusief.
Regressie Of met andere woorden waardeschatting poogt om voor ieder individu de numerieke waarde van een variabele te voorspellen of deze te benaderen voor dit individu.
Data reduction Poogt om een grote dataset te selecteren en deze te vervangen door een kleinere dataset die evenveel belangrijke informatie bevat dan de grote dataset.
Similarity matching
Poogt gelijke individu’s te identificeren aan de hand van reeds gekende data over hen.
7
Manieren om data te verwerven
Er bestaan verschillende manieren om aan data te komen. De manier waarop een politiezone data zal verwerven hangt af van de reden waarom ze de data nodig hebben. Er bestaan veel verschillende soorten manieren waarop politiezones aan data kunnen geraken. Zones kunnen data opvragen bij andere gemeenten of landen. Zones kunnen echter ook gebruik maken van andere bestaande methodes waarbij ze gegevens zelf moeten verwerken zoals satellietbeelden, GPS-signalen en verkeerscamera’s. Doordat data op verschillende manieren verworven wordt, betekent dit veelal dat de data niet in dezelfde vorm zal staan. Dit probleem wordt opgelost in de volgende fase.
Transformeren van data
Tijdens het transformeren van data wordt er een finale dataset gemaakt van alle ruwe data die reeds gevonden is. Voor de analytische technologieën die tijdens deze fase worden gehanteerd, zijn er verschillende voorwaarden. De data wordt opgeschoond, verrijkt en gekoppeld met elkaar (Hoogstrate, Veenman, van Ypenburg, 2012). Het is uitzonderlijk dat de data die in de tweede fase wordt verzameld, meteen in de juiste vorm wordt aangeleverd. Dit komt doordat de verzamelde data niet steeds afkomstig is van dezelfde bron. Er zullen verschillende transformaties moeten gebeuren om alle data in de correcte vorm te gieten zodat er betere resultaten verkregen kunnen worden (Provost & Fawcett, 2013). Voor het koppelen moeten de gegevens op elkaar worden afgestemd, vooral wanneer deze afkomstig zijn van verschillende bronnen (Hoogstrate, Veenman, van Ypenburg, 2012).
Hierdoor loopt het transformeren van data gelijk met de fase ‘data begrijpen’, omdat het transformeren meerdere keren en in verschillende volgordes uitgevoerd moet worden. De data wordt geselecteerd, opgeschoond, geconstrueerd, geïntegreerd en uiteindelijk geformatteerd (Chapman, et al., 2000).
Modelleren van data
Bij het modelleren van data wordt er op basis van de geïntegreerde dataset een model opgemaakt. Om data te modelleren is het belangrijk dat de juiste technieken gehanteerd worden. Er zijn echter verschillende technieken die gehanteerd kunnen worden. Elke techniek heeft zijn eigen vereisten over de vorm van de data. Hierdoor gebeurt het vaak dat er in deze fase wordt teruggekoppeld naar de data transformatie om een andere vorm te kunnen aanleveren voor een techniek (Marban, Mariscal & Segovia, 2009). Wanneer er een juiste datavorm voor de techniek is, kan er een testdesign tot stand worden gebracht, vanuit het
8
testdesign wordt er een model gebouwd. Het is belangrijk dat het model beoordeeld kan worden, daarvoor is het belangrijk dat het model in overeenstemming is met de evaluatiecriteria (Chapman, et al., 2000). Tijdens deze fase, worden de datamining technieken die geselecteerd werden, effectief uitgevoerd. In sommige gevallen is het mogelijk om verschillende datamining technieken met elkaar te combineren (De Tré, 20017).
Bij het modelleren van data wordt er gebruik gemaakt van analyses van de aanwezige data. Er bestaan twee belangrijke soorten analyses die toegepast worden bij datamining. Ten eerste is er de ‘supervised’ analyse. Hier wordt er met een dataset gestart waarbij er reeds een bepaalde variabele bekend is, de ‘target-variabele’. Bij deze methode wordt er gebruik gemaakt van een dataset uit het verleden. Er wordt een model opgesteld met de waarde van de target-variabele. Zo kunnen er nieuwe voorspellingen over een instantie gemaakt worden door overeenstemmingen te vinden met waarden die gekend zijn voor een instantie uit het verleden (Han, Kamber & Pei, 2011).
De tweede analyse is de ‘unsupervised’ analyse. Deze analysemethode kan worden beschouwd als clusteren. De input voorbeelden zijn niet op voorhand gelabeld. Door één of meerdere ‘split’ punten te vinden wordt het geheel daarin opgesplitst. Dit blijft zich herhalen tot er een finaal resultaat is (Han, Kamber & Pei, 2011).
Evalueren van model
Met de gegevens uit de vorige fasen, kan het bestaand model geëvalueerd worden. Het is de bedoeling om de datamining resultaten strikt te beoordelen en vertrouwen te winnen dat de data geschikt en betrouwbaar is, vooraleer er naar de volgende fase wordt doorgegaan. In elke dataset valt er een patroon te vinden, maar niet elke dataset voldoet aan een kritisch onderzoek. Het evalueren van data is nodig om tot een finaal model te kunnen komen. Op deze manier kan men er zeker van zijn dat het model wel degelijk de bedrijfsdoelstellingen realiseert (Marban, Mariscal & Segovia, 2009). Aan het einde van deze fase, moet er een beslissing worden genomen over hoe de resultaten van het model gebruikt zullen worden. Het wordt steeds aangeraden om de dataset eerst te testen in plaats van deze direct te hanteren. Het is goedkoper, makkelijker, sneller en veiliger om het verkregen model eerst te testen in een gecontroleerde omgeving dan het meteen toe te passen in de praktijk. Het testen van het model zorgt voor een extra zekerheid dat het model regelmatig is (Provost & Fawcett, 2013).
9
Het is de bedoeling dat er bij de evaluatie wordt gekeken of de dataset kan helpen om het bedrijfsprobleem op te lossen. Ook de stakeholders hebben inspraak omtrent het tot stand gekomen model, aangezien de bedrijfsbeslissingen worden gebaseerd op de resultaten van het model (Provost & Fawcett, 2013).
Uitrollen van het model
Het model ontwerpen en evalueren is niet voldoende. Het is ook de bedoeling dat de gebruiker de data doorheen de jaren kan blijven gebruiken. Het is belangrijk dat het model zich blijft ontwikkelen, hiervoor is er een monitoring- en onderhoudsplan nodig. In deze fase wordt de verkregen kennis georganiseerd en gepresenteerd, zodat het model zich met de bedrijfsdoelstellingen mee kan evolueren. Vervolgens moet er nog een laatste rapport worden opgesteld over het model en hoe dit mee is geëvolueerd. Het is belangrijk om in deze fase gebruik te maken van correcte visualisatie- en presentatietechnieken, zo kunnen beleidsmakers en beslissingsnemers de resultaten eenvoudig analyseren (De Tré, 2017). Aan het einde van de rit is het de bedoeling dat het volledige project wordt beoordeeld (Chapman, et al., 2000).
1.1.3
Voor en nadelen van CRISP-DMIn dit deel zullen de voor- en nadelen van CRISP-DM worden besproken. De voordelen geven weer waarom CRISP-DM een goed raamwerk is om data te ordenen. De nadelen daarentegen geven aan waar men best oplet wanneer CRISP-DM gehanteerd wordt.
CRISP-DM bevat sterke richtlijnen voor de meest geavanceerde problemen die betrekking hebben op data. Alle dataprojecten starten met het verstaan van het bedrijfsprobleem, de data moet verzameld worden en gefilterd worden en het moet mogelijk zijn dat de data in het algoritme worden geplaatst. Doorheen dit traject zorgt CRISP-DM voor een goede leidraad (Vorhies, 2016). Verder kan CRISP-DM geïmplementeerd worden zonder veel training, organisatorische veranderingen of organisatorische controverse. CRISP-DM is een common sense en een natuurlijk proces. Dit is vastgesteld uit twee onderzoeken van Saltz, Shamshuring & Crowston (2017). In het eerste onderzoek, bevroegen ze studenten die zonder begeleiding een dataproject moesten doen, de studenten hanteerden een aanpak zoals CRISP-DM beschrijft. In het tweede onderzoek, met groepen die wel getraind waren met projectmanagement richtlijnen, scoorde de groep die CRISP-DM moesten toepassen beter dan de groepen die opgedragen waren een andere aanpak te hanteren.
10
De initiële focus op de fase ‘bedrijfsprobleem begrijpen’ is nuttig om het technische werk van het project af te stemmen op de behoefte van het bedrijf. Verder zorgt het er voor dat de data-analisten niet zomaar een probleem aanpakken zonder dat ze de doelstellingen begrijpen. Dankzij de laatste stap ‘uitrollen van het model’ wordt er gefocust op de belangrijke overwegingen die gemaakt moet worden om het project te onderhouden.
Door het flexibel proces van CRISP-DM is het mogelijk dat de gebruiker kan terugkeren naar de vorige fasen. Dit zorgt ervoor dat wanneer het project start met een significante onbekende, het proces toch kan beginnen en in het verloop van het proces meer betekenis kan gegeven worden aan de data en het probleem.
Aan de andere kant moet er rekening worden gehouden met het feit dat het hanteren van DM ook nadelen met zich mee kan brengen. Sommigen beargumenteren dat CRISP-DM niet toepasbaar is voor big-data-projecten, maar eerder als een proces dat voorafgaat aan big data (Saltz & Shamshuring, 2016). Een ander nadeel van CRISP-DM is het feit dat het focust op kleinere teams en niet op een teamwork wat wel nodig is voor grote projecten. Daarom zou er een structuur toegevoegd moeten worden die helpt om teamwork te coördineren (Saltz, Shamshurin, Connors, 2017).
1.1.4
Waarden van dataData moeten een bepaalde waarden hebben vooraleer ze wordt toegevoegd aan een model of gehanteerd wordt in een project. Het is belangrijk dat data aan bepaalde criteria voldoet zodat het een meerwaarde kan hebben voor de doeleinden van het model of project.
Raamwerk van data
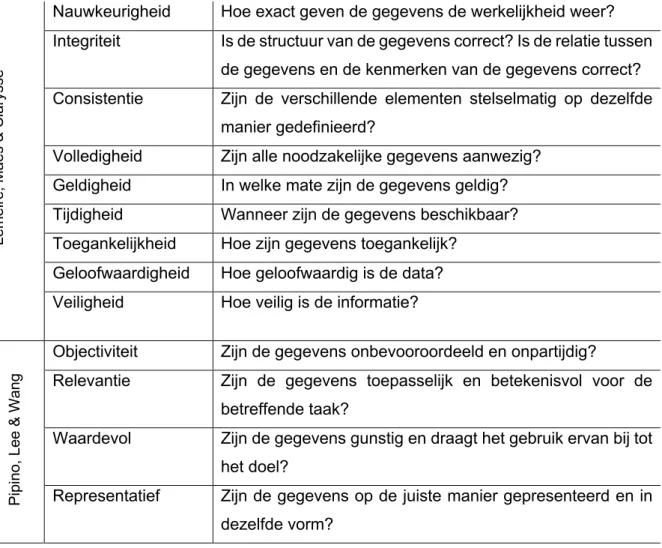
Bij het onderzoeken van data is het belangrijk om stil te staan bij de waarde die de data heeft. Wanneer er een beslissing wordt gemaakt op basis van data, zal de kwaliteit van deze beslissing afhangen van de kwaliteit van de informatie die uit de data is verkregen. Door het gebruik van kwaliteitscriteria kan er naar verschillende aspecten van data worden gekeken. Het volgende raamwerk van data is gebaseerd op data quality dimensions van Pipino, Lee & Wang (2002) en de kwaliteitscriteria voor informatie van Lemeire, Maes & Clarysse (2018).
11
Tabel 2: Raamwerk van data (Lemeire, Maes & Clarysse, 2018; Pipino, Lee & Wang, 2002)
Nauwkeurigheid Hoe exact geven de gegevens de werkelijkheid weer? Integriteit Is de structuur van de gegevens correct? Is de relatie tussen
de gegevens en de kenmerken van de gegevens correct? Consistentie Zijn de verschillende elementen stelselmatig op dezelfde
manier gedefinieerd?
Volledigheid Zijn alle noodzakelijke gegevens aanwezig? Geldigheid In welke mate zijn de gegevens geldig? Tijdigheid Wanneer zijn de gegevens beschikbaar? Toegankelijkheid Hoe zijn gegevens toegankelijk?
Geloofwaardigheid Hoe geloofwaardig is de data? Veiligheid Hoe veilig is de informatie?
Objectiviteit Zijn de gegevens onbevooroordeeld en onpartijdig?
Relevantie Zijn de gegevens toepasselijk en betekenisvol voor de betreffende taak?
Waardevol Zijn de gegevens gunstig en draagt het gebruik ervan bij tot het doel?
Representatief Zijn de gegevens op de juiste manier gepresenteerd en in dezelfde vorm?
De vier toegevoegde criteria zijn nodig bij het preventief bestrijden van criminaliteit. Het is belangrijk dat de data objectief zijn, zodat de voorspellingen die gemaakt worden geen vooroordelen bevatten. ‘Relevantie’ en ‘waardevol’ zijn toegevoegd zodat alle data die de logaritmes bevatten niet overbodig zijn maar bijdragen aan de output. ‘Representativiteit’ bevestigt het feit dat alle data in dezelfde vorm, dus op de juiste manier gepresenteerd, worden. Het is belangrijk bij de derde fase van CRISP-DM, het modelleren van de data, dat alle data dezelfde vorm aannemen. Het is belangrijk dat data ook aan deze vier extra voorwaarden voldoen zodat er aan datadriven misdaadbestrijding kan gedaan worden.
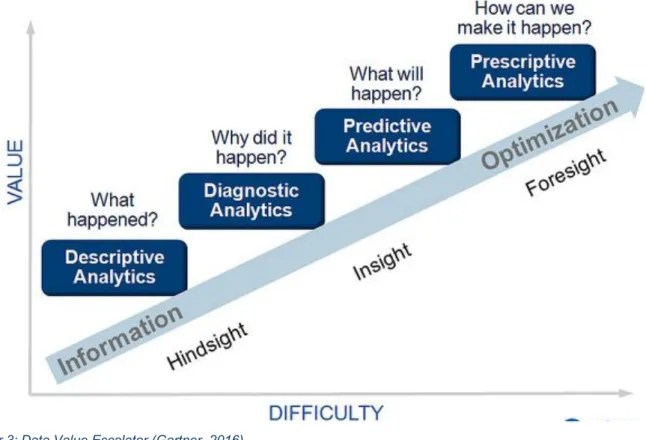
Data Value Escalator (Gartner, 2016)
Het Data Value Escalator model van Gartner geeft weer hoe ruwe data kunnen transformeren naar voorschrijvende analyse. Tijdens deze transformatie komen er verschillende vormen van analyses aan bod. Elke analyse heeft zijn eigen kenmerken.
Lem ei re, M aes & C lar ysse Pi pi no , L ee & W an g
12
Analytics is het analyseren van grote hoeveelheden data. Volgens Gartner zijn er vier soorten analytics: de beschrijvende, diagnostische, voorspellende en voorschrijvende analyses. De ruwe, grote hoeveelheden data worden in dit model omgezet in begrijpbare en nuttige data voor bedrijven. Het model toont dat de analytics worden onderscheiden van elkaar op basis van twee variabelen: waarde en moeilijkheid van de data. Hoe meer waarde de data bevat en hoe moeilijker de data te analyseren is, hoe meer informatie er uit de data vergaard kan worden (Gartner, 2016).
Figuur 3: Data Value Escalator (Gartner, 2016)
Beschrijvende analyse
De eerste soort analyse is ‘beschrijvende analyse’. Bij deze soort wordt het verleden en het heden geanalyseerd. Beschrijvende analyses geven vooral informatie over wat er gebeurd is en wat er momenteel gebeurt. Deze vorm stelt de belangrijkste metingen, resultaten en gegevens vast.
Diagnostische analyse
‘Diagnostische analyse’ is de tweede soort van analyse in het Gartner model. Bij deze vorm wordt er nog steeds naar het verleden gekeken maar wordt er dieper ingegaan op de oorzaak van bepaalde dingen. Er wordt op zoek gegaan naar oorzaken. Deze vorm legt afwijkende waarden of bepaalde patronen bloot. Verder kan irrelevante of onduidelijke data worden weggefilterd.
13
Voorspellende analyse
De derde soort analyse, ‘voorspellende analyse’, kijkt naar de toekomst. Op basis van de data van het verleden, probeert men een voorspelling te maken door middel van algoritmes. Zo kan men proberen te onderzoeken wat er in de toekomst kan gebeuren. Aan de hand van deze voorspellingen kunnen bedrijven betere beslissingen maken.
Voorschrijvende analyse
De laatste vorm van analyse is ‘voorschrijvende analyse’. In deze vorm wordt er nog een stap verder gegaan. Naast voorspellingen te maken, wordt er bij voorschrijvende analyse ook geanalyseerd welke beslissingen te nemen naar de toekomst toe. Op basis van deze analyses, kunnen bedrijven advies inwinnen om hun volgende acties of strategieën te plannen. De voorschrijvende analyse is de meest geoptimaliseerde vorm, dat de meeste waarde vrijgeeft maar ook het moeilijkste is om te analyseren.
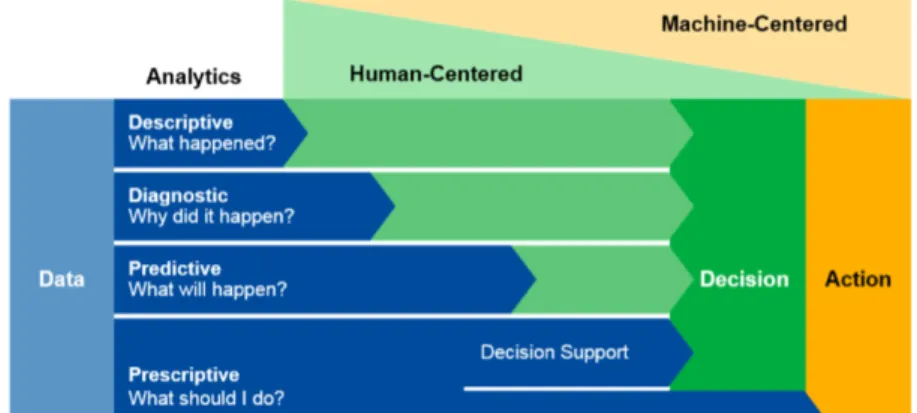
Machine gecentreerde model
De vernieuwde versie van de Data Value Escalator toont aan dat er bij de voorspellende en voorschrijvende analyse meer komt kijken dan bij meer traditionele data-analyses. Bij dit model speelt er bij de laatste twee analyses een nieuw element, namelijk dat niet de mens maar de machines centraal staan bij de analyse. De data die verkregen worden uit de voorschrijvende analyse kunnen twee
functies vervullen: ofwel beslissingsondersteuning ofwel beslissingsautomatisering. De eerste functie helpt bij het nemen van beslissingen of geeft inzichten in welke beslissingen te nemen. Bij de tweede functie wordt er meer gefocust op het nemen van acties (Gartner, 2016).
1.1.5
Predictive policingPredictive policing, ofwel politiewerk doen aan de hand van voorspellingen, is een vorm van datagedreven te werken. Aan de hand van datamodellen worden voorspellingen bekomen, die bijdragen tot het bestrijden van misdaad. Predictive policing vindt zijn oorsprong bij het politiedepartement van Los Angeles. Predictive policing is het gebruik van big data-analyses om voorspellingen te doen over menselijk gedrag. Het neemt een steeds prominentere rol in,
14
in onze samenleving. Het gebruiken van predictive policing is een beleidsstrategie of techniek die door de politie wordt gehanteerd om vooruitstrevende beslissingen te maken inzake misdaadpreventies (Ucida, 2009).
De voorspellingen worden gehanteerd om mogelijke doelwitten te identificeren, misdaad te voorkomen of om een onopgeloste zaak uit het verleden op te lossen. Het voorspellen van misdaad levert een bijdrage aan zowel de rechtspraktijk als aan het tactische en strategische perspectief (Perry, et al. 2013).
Predictive technieken
Het opmaken van de voorspellingen is mogelijk omdat er gebruik wordt gemaakt van predictive analytics voor deze technieken (Ratcliffe, 2015). De predictive analytics, of de voorspellende analyses, zijn een vorm van business intelligence die de laatste jaren steeds meer worden gehanteerd. De voorspellende analyse is reeds aan bod gekomen bij de Data Value Escalator van Gartner (zie 2.2.2).
Met de komst van deze analysetechnieken van menselijke gedrag op basis van big data, kan politiewerk efficiënter verricht worden. Verder leveren de analyses waardevolle informatie op (Graham, 2012; Mayer- Schönberger & Cukier, 2013).
De ontwikkeling van de analytische technieken kent een enorme groei de laatste jaren en heeft verschillende oorzaken. Ten eerste is het gebruik van voorspellend politiewerk, dus ook het gebruik van analytische technieken, gestegen omdat er de laatste jaren een intensievere samenwerking is tussen research en praktijk (Groff & La Vigne, 2002). Ten tweede is de ontwikkeling van analytische technieken te danken aan het feit dat ze meer worden toegepast dan vroeger. Doordat men telkens data moet verwerven om technieken toe te passen, zijn er steeds meer digitale data beschikbaar. Zo voegt elke (politie)organisatie op haar beurt eigen gegevens toe waardoor er steeds grotere databanken worden ontwikkeld. Deze gegevens bevatten informatie over misdaden uit het verleden. Met behulp van al deze gegevens kunnen er modellen worden gevormd, op basis van algoritmes en analyses, die criminaliteit kunnen voorspellen (de Vries & Smit, 2016). Tenslotte komt erbij kijken dat er steeds meer data geaggregeerd wordt. De hoeveelheid beschikbare data blijft exponentieel groeien als gevolg van databasekoppelingen van verschillende organisaties of bedrijven zoals veiligheidspartners en het ontstaan van het ‘Internet of Things’. Het ‘Internet of Things verwijst naar het feit dat alles en iedereen is gekoppeld aan het internet, met andere woorden Big Data (de Vries & Smit, 2016).
15
Door gebruik te maken van deze analytische voorspellende technieken, kan de politie meer preventiegericht werken. Om een techniek als effectief te beschouwen, moet deze techniek ook tastbaar resultaten kunnen leveren (Keuning & Eppink, 2004). Er kunnen twee verschillende soorten predictive policing technieken geïdentificeerd worden (van Brakel, 2016).
Machine learning
Machine learning is vandaag de dag een belangrijke methode voor wetenschappers, onderzoekers, ingenieurs en studenten op verschillende gebieden (Harrington, 2012). Machine learning kwam al eerder aan bod bij de voorschrijvende analyse omdat machine learning het mogelijk maakt om data te voorzien waarop toekomstige beslissingen steunen. Bij machine learning wordt onderzocht hoe computers kunnen leren of hun eigen prestaties kunnen verbeteren door middel van data. Deze computers worden gezien als zelflerende systemen. Bij machine learning wordt er gebruik gemaakt van training data. De training data is een eerste dataset dat een programma helpt te begrijpen hoe een neutraal netwerk een technologie moet toepassen en er verfijnde resultaten mee kan produceren.
Machine learning is een discipline die de laatste tijd enorm aan het groeien is. Het principe van een zelflerend systeem is een computer te programmeren zodat het automatische zaken kan herkennen na een voorbeeld te hebben gehad aan de hand van een set data. De machine herkent telkens autonoom een bepaald patroon en hanteert dit opnieuw, zo past het zich telkens aan een nieuwe situatie aan. Dit geeft aan dat datamachines zelfstandig kunnen bijleren van data. Bij machine learning wordt er vaak gefocust op de drie belangrijke taken; de efficiëntie en aanpasbaarheid van mining methodes van grote sets data, de manier waarop complexe soorten data behandeld worden en het ontdekken van nieuwe en alternatieve methodes voor zelflerende machines (Han, Pei & Kamber, 2011).
Machine learning kan helpen bij de technieken die worden toegepast bij predictive policing. Het is een ideale oplossing voor het opvragen van informatie en patroonherkenning. De intelligente algoritmes die in zo een machine bevat zijn in staat enorm grote hoeveelheden data te verwerken en om te zetten naar een output. In het geval van predictive policing, zal de output een voorspelling zijn of een beslissing die gebaseerd is op de verzamelde data. Machine learning kan helpen met het preventief bestrijden van misdaad door steeds terugkerende criminaliteit op te sporen. Machine learning wordt bijvoorbeeld gebruikt voor gezichts- en stemherkenning (Heida, 2017).
16
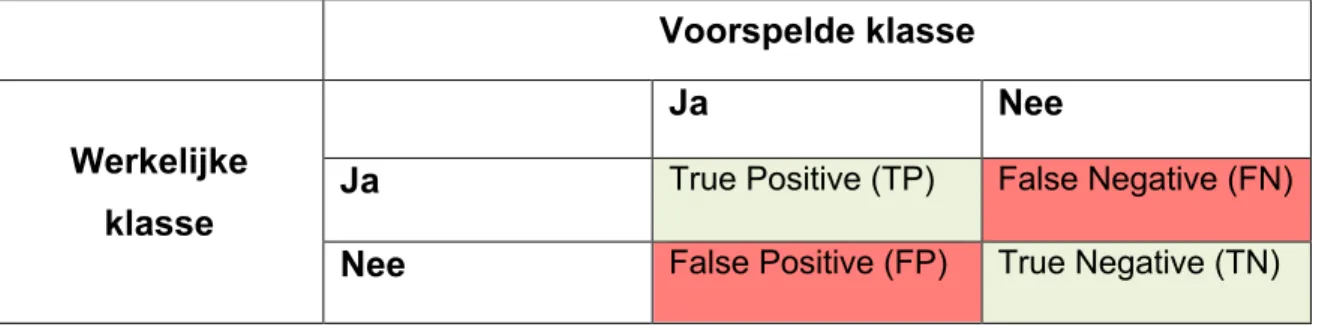
Confusion matrix
De confusion matrix is één van de meest klassieke beslissing-meetmethodes die gehanteerd wordt bij supervised machine learning. Om een correcte evaluatie te willen uitvoeren, is het belangrijk het begrip confusion matrix en het gebruik ervan goed te kennen. De confusion matrix is een supervised methode omdat de dataset aan het begin van de meeting reeds gekend is.
De confusion matrix is een visuele weergave van alle mogelijke uitkomsten van een voorspelling tegenover de werkelijke uitkomsten. De weergave van de matrix is afhankelijk van het aantal klassen. Wanneer er ‘n’ problemen zijn, zal de matrix zich weergeven als een ‘n x n’ raster. De kolommen van de confusion matrix tonen de voorspelling van de klassen, de rijen weerspiegelen de werkelijke klassen (Xu, Zhang & Miao, 2020). De confusion matrix ontstaat op basis van de beslissingen van de classificator. Een classificator gebruikt trainingsdata, data om te oefenen, om de input variabelen te kunnen begrijpen en in verband te brengen met de klasse. Het toont expliciet aan hoe een klasse met een andere klasse is verward. Door de verwarring, zijn er verschillende vergissingen, deze vergissingen worden door een confusion matrix weergegeven.
Aangezien de confusion matrix een supervised methode is, wordt de categorie waarop wordt ingedeeld op voorhand vastgelegd. De performantie van de classificatie wordt geëvalueerd op basis van het aantal correcte toegewezen objecten in de juiste klasse tegenover het aantal niet correcte toegewezen objecten (Witten et al., 2011). Deze vorm van interpretatie van de accuraatheid houdt echter geen rekening met de kost die kan ontstaan door het niet juist toekennen van een element in de juiste klasse. Bijvoorbeeld: de impact van het niet voorspellen van een orkaan is groter dan de impact van het voorspellen dat er een orkaan zou zijn. In het voorbeeld over de orkaan zijn er twee mogelijke uitkomsten: enerzijds de komst van een orkaan en anderzijds het niet bestaan van een orkaan. In een twee-klasse casus, zal een voorspelling leiden tot vier mogelijke uitkomsten, zoals gevisualiseerd in de confusion matrix. De True Positives (TP) en de True Negatives (NT), duiden op een juiste classificatie. Hieruit kan er geconcludeerd worden dat True wijst op een correcte voorspelling. Een False Positive (FP) komt voor wanneer de uitkomst is voorspeld als ‘ja’ maar het in werkelijkheid eigenlijk ‘nee’ is. Als laatste is er de False Negative (FN), deze wordt verkregen wanneer de uitkomst wordt voorspeld als negatief, maar het in werkelijkheid positief blijkt te zijn (Witten et al., 2011).
17
Tabel 3: Confusion matrix
Voorspelde klasse
Werkelijke
klasse
Ja
Nee
Ja
True Positive (TP) False Negative (FN)Nee
False Positive (FP) True Negative (TN)Soorten predictive policing
Bij predictive policing zijn er twee verschillende soorten te onderscheiden. Enerzijds is er predictive mapping, waarbij er wordt gekeken naar de locatie en tijd. Anderzijds is er Predictive identification focust zich op het menselijke variabele van de misdaad zoals bijvoorbeeld de dader en slachtoffers.
Predictive mapping
Predictive mapping heeft betrekking op het voorspellen van waar en wanneer een misdaad zou kunnen plaatsvinden. De analyses worden gemaakt op basis van het samenvoegen van informatie zodat ze op verschillende niveaus van de maatschappij gebruikt kunnen worden. Het proces van predictive mapping kan worden opgesplitst in twee stappen. De eerste stap is prospective crime mapping, deze houdt het gebruik van kwantitatieve analytische technieken in om te voorspellen waar de misdaad plaats zou kunnen vinden. De tweede stap is targeted prevention, hierbij worden de bronnen, activiteiten en interventies van de politie onderzocht in de voorspelde hotspot zodat toekomstige problemen en misdaden vermeden kunnen worden (Beak & Quinton, 2015). Een techniek die vaak gehanteerd wordt bij predictive mapping is het gebruik van geografische informatiesystemen.
Er is steeds meer data beschikbaar die informatie bevat over je eigen locatie, de locatie van je vrienden, etc.. Ook is een klassieke kaart niet meer van deze tijd aangezien alle nodige informatie ook te vinden is via GPS. Geografische informatiesystemen of kortweg GIS, zijn computerprogramma’s waarmee informatie in kaart kan worden gebracht. GIS zijn een sterke set van tools die ruimtelijke gegevens van de echte wereld verzamelen, opslagen, opvragen, transformeren en aanbieden voor bepaalde doelen (Burrough, 1986; Burrough & McDonnell, 1998). Deze informatie kan later geanalyseerd worden alsook visueel worden voorgesteld. De plaats waar iets "is" of "gebeurt" is dus heel belangrijk. Toch moeten niet alle gegevens
18
plaatsgebonden zijn. Ook andere informatie kan opgeslagen en gebruikt worden in GIS. Het is reeds voldoende dat minstens één gegeven verbonden is aan een locatie (UHasselt, z.d.).
Gegevens van verschillende bronnen kunnen via de computer gekoppeld worden aan een bepaalde locatie. Hierdoor heeft een locatie meerdere lagen. Op elke laag bevindt zich een andere soort informatie. Door al deze lagen bovenop elkaar te leggen, krijg je een volledig plaatje van hoe een situatie in elkaar zit of kan je een situatie voorstellen in de toekomst (Burrough, McDonnell, McDonnell, & Lloyd, 2015).
GIS kan in verschillende sectoren worden toegepast zoals verkeer en vervoer, milieu, economie enzovoort. Het voorstellen van een bepaalde situatie in de toekomst is een goede tool om preventief misdaad te bestrijden. Het schoolvoorbeeld is de stad Amsterdam.
Criminaliteit anticipatie systeem (CAS) – Amsterdam
Het CAS vindt zijn oorsprong bij de politie van Amsterdam. CAS is een geavanceerd plannings- en voorspellingssysteem. Verschillende politiekorpsen gebruiken CAS voor het voorspellen van woninginbraak, straatroven en overvallen. Het CAS-systeem verdeelt een bepaald gebied in verschillende vakjes. Voor elk vakje wordt de kans op een incident ingeschat. Vakjes met vooraf al een lage kans, zoals weilanden en open water, worden verwijderd. Voor de overblijvende vakjes worden grote hoeveelheden data verzameld. De inhoud van deze data is zeer uiteenlopend. Het kan gaan over de historie van het gebied tot de reeds veroordeelden die er wonen. Voor elk vakje wordt op verschillende peilmomenten geregistreerd welke gegevens er op dat moment bekend zijn. Vervolgens wordt bepaald welke incidenten de volgende twee weken kunnen voorkomen worden. Door gebruik te maken van kunstmatige neutrale netwerktechnologie, is het mogelijk om te bepalen welke combinatie van kenmerken een goede indicator zijn om criminaliteit in de nabije toekomst te bestrijden en te vermijden. Dit resulteert in een kaart waarop er verschillende “hotspots” zijn aangeduid. De kaart wordt een ‘heat map’ genoemd waarop elke hoge score, alsook groot gevaar op misdaad, een warmere kleur krijgt (de Vries & Smit, 2016).
Predictive identification
Predictive identification is de tweede techniek die bij predictive policing kan onderscheiden worden. Predictive identification gaat een stap verder dan het voorspellen van criminaliteit. Deze focust zich op het voorspellen van potentiële daders, daderprofielen, crimineel gedrag en mogelijke slachtoffers van een misdaad. Bij dit type wordt er gekeken naar personen en
19
technieken alsook worden gegevens over etniciteit gebruikt. Predictive indentification kan leiden tot privacy-schendingen omdat er persoonlijke gegevens over personen of groepen worden onthuld.
Risico’s bij predictive policing
Bij predictive policing moet er rekening gehouden worden met aantal risico’s. Er wordt al te vaak uitgegaan van een automatisme en men vergeet te vaak stil te staan bij het feit dat de voorspellingen door computers worden gemaakt. Wanneer er gebruik wordt gemaakt van predictive policing moeten onderstaande risico’s in acht worden genomen. Daardoor kan er immers wantrouwen en onrust bij de burgers worden veroorzaakt.
1. Foutief mensen oppakken en het op de technologie steken
Wanneer er foutief mensen worden opgepakt, wordt de schuld vaak direct op de technologie gestoken in plaats van eerst naar de eigen acties te kijken. Hierdoor maken agenten zich minder druk over het overtuigd zijn bij een arrestatie omdat ze de schuld niet zullen treffen wanneer er een fout wordt gemaakt.
2. Te complex waardoor mensen het niet gaan begrijpen
De analytische technieken die gebruikt worden bij predictive policing zijn vaak complex. Dit zorgt ervoor dat het merendeel van de burgers en agenten niet nadenken bij de voorspellingen die gemaakt worden maar deze altijd als correct aannemen. Er kan niet worden stilgestaan bij de analyses omdat ze niet altijd even verstaanbaar zijn.
3. Bias van de systemen
Wanneer de ontwerper van een algoritme reeds vooroordelen heeft, is de kans groot dat het algoritme ook die vooroordelen zal bevatten. In dit geval wordt er gesproken over algoritmische discriminatie (van Brakel, 2015). Er zijn drie verschillende soorten. Het eerste type van bias is de onbewust discriminatie die bij het labelen van de resultaten wordt opgenomen of in de regels die worden opgenomen in het algoritme. Het tweede type is gebaseerd op veronderstellingen die reeds een vooroordeel hebben. Deze veronderstellingen zijn in de data terecht gekomen door de manier waarop de data is verzameld. De laatste soort algoritmische discriminatie komt aan bod door technische defecten, fouten en bugs in het systeem. Dit leidt tot foute voorspellingen die overeenkomen met bepaalde criteria. Maar dit kan ook zorgen dat juiste voorspellingen als negatief worden beschouwd.
20
4. Tekort aan transparantie
Bij predictive policing wordt er geprobeerd een veilige maatschappij te creëren, toch kan er worden vastgesteld dat concurrentie ook hier een rol speelt. Iedereen wil dat zijn organisatie de beste scores heeft en hun algoritme het meest effectief en efficiënt is.
5. Geen menselijke benadering meer
Het feit dat de voorspellingen worden gemaakt op basis van algoritmes en door machines duidt erop dat er niet altijd sprake is van een menselijke benadering. Politieagenten moeten rekening houden met hun machtspositie. De resultaten van CAS zorgen niet altijd even goed voor een correcte afspiegeling van de realiteit (de Vries & Smit, 2016). Agenten moeten kritisch reflecteren over de uitkomsten vooraleer op te treden.
6. Ontstaan van oogkleppen
Door het voortdurend uitvoeren van voorspellingen en het optimaliseren hiervan kan men andere aspecten van de job vergeten. Er wordt minder gefocust op ander werk omdat men enkel nog de technologie wil blijven verbeteren.
21
1.2
Beleid
Beleid maken is het doelbewust handelen door een actor of meerdere actoren met als aanleiding een probleem of een zorgwekkende kwestie (Anderson, 2000). Tijdens het schetsen van beleid wordt er gepoogd om voor een politiek gedefinieerd probleem naar een oplossing te zoeken die gericht is op het wijzigen van het gedrag van de doelgroep ten voordele van beneficianten van het beleid (Knoepfel, 2007). Beleidmakers proberen problemen aan te pakken waar burgers negatieve ervaringen mee hebben. Dit doen ze door middel van beleid op te stellen. Beleid omvat het stellen van politieke doelstellingen en het gericht inzetten van instrumenten om een maatschappelijk probleem aan te pakken en om zo een ongewenste situatie te verbeteren of weg te werken.
1.2.1
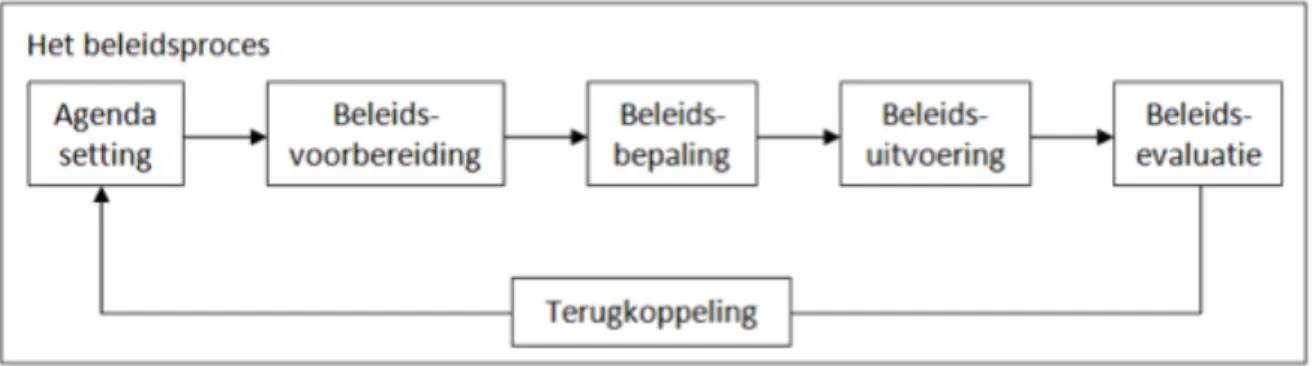
BeleidsprocesHet beleidsproces is een dynamisch verloop van verschillende handelingen en interacties met betrekking tot het beleid (Hoogerwerf, 1998, p.26). Het onderstaande fasenmodel is een dominant kader in de literatuur. Het feit dat het door verschillende auteurs wordt gehanteerd, is een goede indicator voor de kwaliteit van het model. Het beleidsproces bestaat uit zes verschillende fasen, zoals weergegeven in onderstaande figuur 5.
Figuur 5: Het beleidsproces (Hoogerwerf, 1998)
Beleidsmodellen die gehanteerd worden in de theorie van beleidsvoering, zijn meestal theoretisch en overzichtelijk model. Het probleem ligt bij de omzetting naar praktijk. Er is een enorme kloof tussen beleidsproces in ‘real life’ en het proces op papier. Dit heeft enkele oorzaken. Ten eerste is het beleidsproces niet lineair maar kunnen fasen overlappen. De doelen, problemen en opties komen vaak tegelijk aan de orde. Een tweede oorzaak is de invloed vanuit de omgeving. Wanneer er zich plotse gebeurtenissen voordoen, kan het zijn dat het beleid een volledige andere wending moet nemen. Het is ook mogelijk dat er een direct
22
optreden vereist wordt en dat beleidsmakers een beslissing niet kunnen uitstellen. Een laatste oorzaak voor de kloof is dat beleid wordt gevormd in een overheidscontext. Bij overheidsbeleid is er een sleutelrol, echter geen exclusieve, weggelegd voor de overheid. Het denken vanuit een beleidsproces gebeurt volgens een top-down-perspectief, doch moet er vandaag de dag rekening gehouden worden met de participatie van diverse actoren uit verschillende bestuursniveaus. Het beleidsproces wordt niet louter vanuit de superieure centrale overheidsinstituties opgesteld. Denk maar aan de participatie van burgers, actiegroepen, vakbonden en (non-)profit-actoren.
Agendasetting
De eerste fase ‘agendasetting’ wordt beschreven door de Vries (1998, p.42) als “het proces waardoor maatschappelijke problemen de aandacht van het publiek of de beleidsbepalers krijgen”. Politieke partijen gebruiken agendasetting vaak om kiezers aan te trekken met hun agenda. Problemen kunnen door de overheid worden aangegeven maar er kunnen ook problemen aangekaart worden door analisten zonder dat de overheid wist dat er een probleem was (Dunn, 2004).
Om aan agendasetting te doen, moet eerst begrepen worden wat de agenda is en wat een probleem is. Zoals de definitie van de Vries (1998) omschrijft, draait het hier niet om gelijk welk probleem maar enkel om maatschappelijke problemen. Daarom wordt er gekeken wanneer er sprake is van een probleem dat ook maatschappelijk is.
De stappen die hier overlopen worden, kunnen teruggekoppeld worden aan het probleemstappenplan van Dunn (2004). Dit stappenplan bevat vier fasen, die op verschillende vlakken stilstaan bij het probleem. Bij de eerste stap wordt het probleem zelf onderzocht. Daarna wordt er een definitie aan het probleem gegeven zodat het probleem besproken en benoemd kan worden. Vervolgens wordt er dieper op het probleem ingegaan en worden de specificaties van het probleem vastgelegd. De laatste stap is het herkennen van het probleem en het bevestigen dat er daadwerkelijk een probleem is. Wanneer deze stappen worden vergeleken met de agendasetting, stemt het definiëren van het probleem overeen met de
probleemanalyse. Het specifiëren van het probleem kan vergeleken worden met het maatschappelijk verklaren van het probleem, omdat hierbij het belang van de samenleving
23
wordt vastgesteld en de invloed op de samenleving wordt bekeken. Wanneer het probleem wordt herkend, kan het op de agenda worden geplaatst.
Agenda
De agenda is volgens Kingdon (1995) een lijst van onderwerpen en problemen waar openbare ambtsdragers en mensen van buiten de overheid belang aan hechten. Op deze lijst richten gezagsdragers op bepaalde tijdstippen hun aandacht. Volgens van de Graaf en Hoppe (2000) bestaan er drie verschillende agenda’s. Als eerste is er de publieke agenda, dit is een lijst met onderwerpen waarvan het publiek vindt dat ze de aandacht van politici en bestuurders behoren te hebben. Een tweede soort agenda is de politieke agenda, deze bevat een lijst van onderwerpen die reeds de aandacht van politici en bestuurders heeft. Als laatste is er de beleidsagenda, deze bevat een lijst van problemen die aandacht krijgen van overheidsactoren en waarvoor overheidsactoren al bezig zijn een maatregel te voorzien of in te voeren. Probleemanalyse
Vooraleer een probleem op de agenda gezet wordt, is het belangrijk om het probleem eerst te bestuderen en afdoende af te bakenen. Het is belangrijk om eerst alle aspecten van het vooropgestelde probleem te analyseren zodat beleidsmakers het probleem kunnen uitklaren. Zonder de afbakening is het niet mogelijk om treffende beleidsopties te vinden die specifiek het probleem aanpakken (Wayenberg, 2018). Volgens Kraft en Furlong (2012), kan dit aan de hand van het LASST-model worden gedaan. Het LASST-model staat voor level, actor, sector, state en time.
Level
Elk probleem bevindt zich op een andere schaal of niveau. Om te kunnen afbakenen is het belangrijk om het probleem op het juiste schaalniveau te kunnen situeren. Doch is het niet altijd even makkelijk om een probleem te situeren doordat het vaak meerdere schaalniveaus betreft. De erkende schaalniveaus zijn; lokaal, regionaal, nationaal, internationaal en globaal. Actor
Verder moet er gekeken worden naar wie de belanghebbenden zijn bij het probleem. De belanghebbenden zijn de actoren die invloed ondervinden of zelf invloed uit oefenen op het probleem. Deze invloed kan zowel positief als negatief zijn. De actoren hebben er baat bij dat er iets wordt gedaan met het probleem.
Sector
Een probleem kan zich in een bepaalde sector bevinden en enkel betrekking hebben tot deze sector. Wanneer dit het geval is, is het probleem sectorspecifiek. Echter is het ook mogelijk dat een probleem niet binnen een bepaalde sector valt, maar verschillende sectoren betreft. Dan kan er gesproken worden over een cross-sectoraal probleem.
24
State
State gaat over de grootte of de omvang van de probleemkloof. Zoals uitgelegd in het kloofmodel speelt de kloof een belangrijke rol voor de beleidsmakers. De kloof wordt veelal geduid met woorden, maar de voorkeur gaat naar het gebruik van cijfers om de kloof te beargumenteren.
Time
De laatste factor die gebruikt wordt om een probleem te situeren is tijd. Bij tijd wordt er gekeken of het gaat over een oud of nieuw probleem. Door te kijken naar de tijd, is het mogelijk om één van de soorten beleidsformuleringen toe te passen. Daarenboven is het ook belangrijk om rekening te houden met het feit of het probleem zich evolueert doorheen de tijd. Is het probleem een aanslepend probleem dat dringend moet aangepakt worden of is het een probleem dat al lang aansleept maar niet belangrijk genoeg is om over in actie te treden? Maatschappelijke relevantie
Opdat beleidsmakers aan agendasetting kunnen doen, moet er gekeken worden of een bepaalde kwestie ook een maatschappelijk probleem is of niet. Eerst wordt het soort probleem bekeken. Zaken waarover het publiek geen begrip heeft, zullen geen maatschappelijk probleem vormen en zullen dus niet snel op de agenda komen (Meraz, 2009). Verder speelt het “salience” van een maatschappelijk probleem een grote rol. Salience kan vertaald worden als het karakteristiek kenmerk van het probleem, wat is er opvallend aan? Hoe belangrijk vindt het publiek een bepaald maatschappelijk probleem? Als er geen aandacht aan een bepaald probleem wordt geschonken, is het dan nog maatschappelijk? (Takeshita, 2006). Ook al voldoet een kwestie aan het soort issue en de “salience”, dan nog wordt het maatschappelijk probleem automatisch op de agenda geplaatst. Er kan zich worden afgevraagd waarom een bepaald probleem op de agenda wordt gezet en ander niet. Er bestaan vier modellen die elk focussen op verschillende variabelen en verklaren waarom een probleem al dan niet op de agenda wordt geplaats (Akkerman et al., 2014). Tussen de vier modellen is er geen ‘beste’ model omdat er telkens op een ander aspect wordt gefocust.
Het kloofmodel
Bij dit eerste model, het kloofmodel van Hoogerwerf en Herweijer (2008), hangt de agendasetting af van de ernst of grootte van het probleem. Als eerste wordt er gekeken naar het probleem zelf: in welke mate is er een kloof tussen de maatstaf en de voorstelling van de situatie? Wanneer er over een groot verschil of een grote kloof wordt gesproken tussen de maatstaf en de werkelijke situatie, zal agendasetting optreden. Indien de kloof klein is, zal agendasetting niet optreden.
25
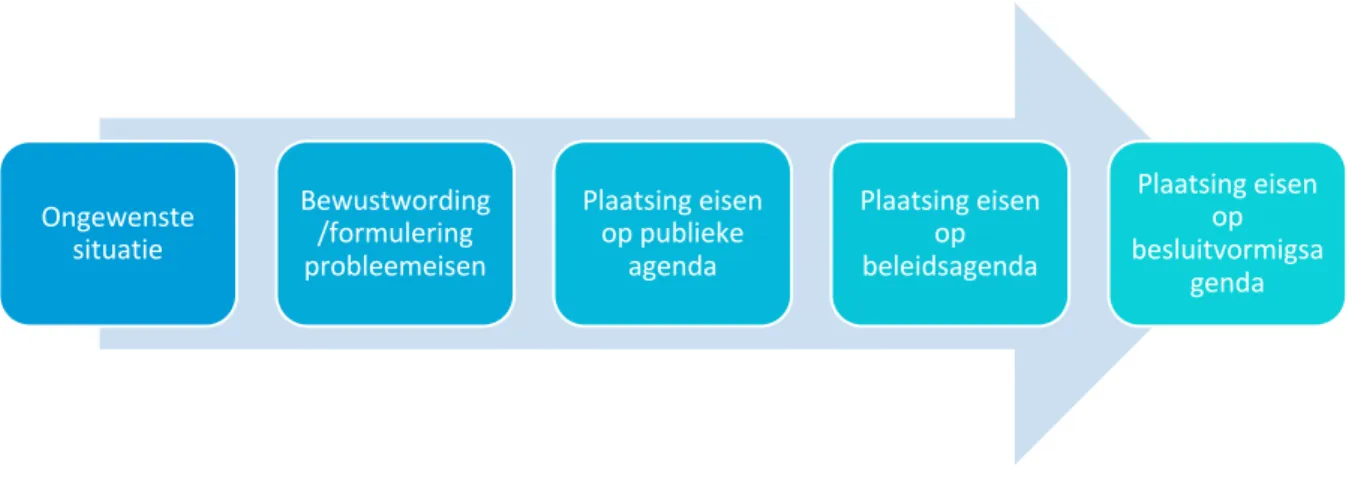
Het barrièremodel
Het barrièremodel van Bachrach en Baratz (1970) is het tweede model met betrekking tot agendasetting. Hier hangt de agendasetting af van de barrières bij de probleemevolutie. Het barrièremodel brengt in kaart waarom er niet altijd actief beleid volgt op een probleem. Volgens dit model moet een probleem vijf verschillende barrières doorlopen vooraleer het op de agenda kan worden geplaatst. De barrières volgen elkaar op: de eerste barrière is de ongewenste situatie, daarop volgt de bewustwording/formulering van probleemeisen, vervolgens de plaatsing op de publieke agenda, dan de plaatsing op de beleidsagenda, om tot slot te komen bij de plaatsing op de besluitvormingsagenda. Pas als het probleem alle fasen doorloopt kan er over agendasetting worden gesproken.
Figuur 7: Barrièremodel (Bachrach & Baratz, 1970)
Relatieve-aandachtsmodel
Het derde model, het relatieve-aandachtsmodel van Hoogerwerf en Herweijer (2008) gaat ervan uit dat er meerdere maatschappelijke problemen tegelijkertijd in de samenleving spelen. Dit model zegt dat de overheid slechts aan enkele problemen aandacht schenkt omdat het onmogelijk is om op alle problemen tegelijk te focussen. Een reden hiervoor is dat de middelen van de overheid schaars zijn. Agendasetting wordt gezien als een dynamisch en cyclisch proces ten gevolge van schaarste van overheidsmiddelen. De overheid zal zich in eerste instantie eerst focussen op een paar problemen en dan in tweede instantie op de andere problemen om vervolgens terug te focussen op de eerste problemen. Er is een constante wisselwerking van de aandacht dat de overheid besteedt aan problemen.
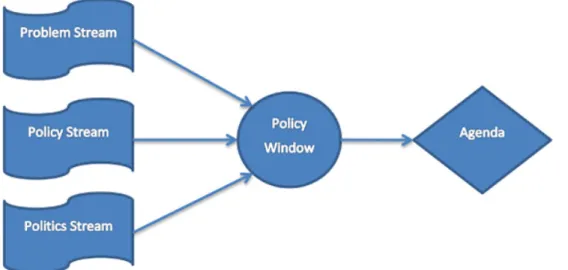
Stromenmodel
Het laatste model dat gehanteerd kan worden om te verklaren of een probleem al dan niet op de agenda wordt geplaatst, is het stromenmodel van Kingdon (1995). Het stromenmodel start vanuit drie verschillende stromingen, die zich afzonderlijk ontwikkelen. De eerste stroom is de
Ongewenste situatie Bewustwording /formulering probleemeisen Plaatsing eisen op publieke agenda Plaatsing eisen op beleidsagenda Plaatsing eisen op besluitvormigsa genda
26
probleemstroom, het gaat over het herkennen van de veranderlijke aandacht voor het probleem. Het zijn de stakeholders die verwachten van de overheid dat deze voor het maatschappelijke probleem met een oplossing komt. Problemen kunnen op verschillende manieren onder de aandacht worden gebracht. De tweede stroom zijn de ontwikkelingen binnen het politieke klimaat, dit klimaat is constant aan verandering onderhevig. Bepaalde gebeurtenissen in de samenleving kunnen alle beslissingen die gemaakt worden omtrent beleid beïnvloeden. De laatste stroom is de beleidsstroom, de manier waarop men omgaat met beleid. Sommige voorstellen worden serieus genomen en andere niet. Het idee van de tweede stroming is dat het probleem de selectie van beleidsoplossingen moet weten te overleven. De drie verschillende stromingen komen tezamen in de beleidsramen. Deze openen zich op een bepaald moment en blijven dan voor een bepaalde periode openstaan. Wanneer het beleidsraam open is, is het aan de actoren om te reageren voordat het raam zich terug sluit.
Figuur 8: Stromenmodel (Kingdon, 1985)
Beleidsformulering
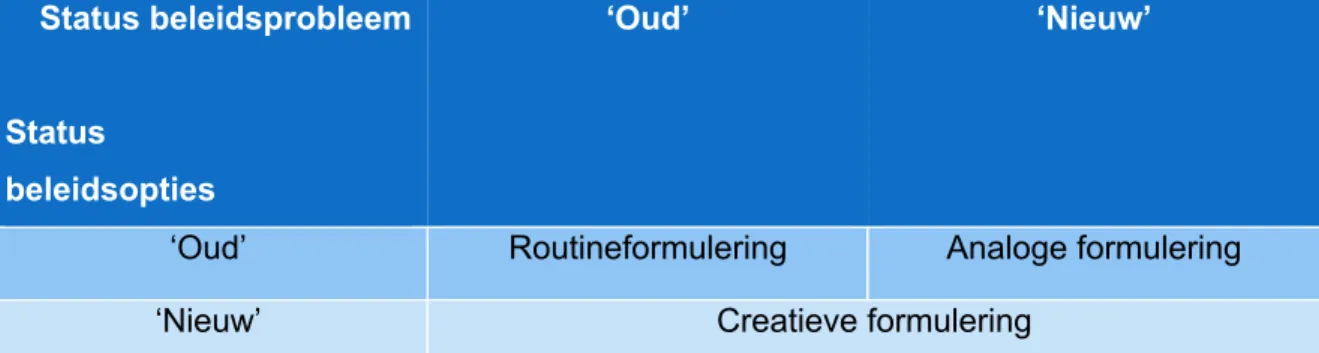
De tweede stap in het beleidsproces is ‘beleidsformulering’. Deze stap bestaat uit het uitwerken en overwegen van oplossingen voor een beleidsprobleem. Een beleidsoptie is een voorstel ter mogelijke aanpak van een probleem op de beleidsagenda. Een andere benaming voor een beleidsoptie is een beleidsalternatief. Veelal is er niet één beleidsoptie maar zijn er verschillende. De verschillende beleidsopties bevatten variatie op het vlak van in te zetten instrumenten en de operationele uitwerking. Er bestaan drie soorten beleidsformuleringen (Howlett, Ramesh & Perl, 2009). De eerste soort formulering is de routineformulering. Het is een beleidsformulering over een wederkerend probleem waarvoor aloude en typische
27
beleidsopties worden geformuleerd. De tweede soort beleidsformulering is de analoge formulering. Bij deze formulering worden oude beleidsopties gehanteerd voor een nieuw probleem. Er wordt naar analogie gehandeld met gekende problemen. De laatste soort formulering is de creatieve formulering, hier worden ongekende beleidsopties gelanceerd voor een nieuw probleem.
Status beleidsprobleem
Status
beleidsopties
‘Oud’ ‘Nieuw’
‘Oud’ Routineformulering Analoge formulering
‘Nieuw’ Creatieve formulering
Figuur 9: Soorten formulering (Howlett, Ramesh & Perl, 2009)
Soorten beleidsalternatieven
Zoals hierboven aangehaald, is het mogelijk om gebruik te maken van reeds bestaande alternatieven. Echter kunnen beleidmakers ook opteren voor nieuwe alternatieven. Deze alternatieven kunnen ontstaan op basis van tien factoren (Wayenberg, 2018a).
Tabel 4: Soorten beleidsalternatieven
Autoriteit De nieuwe beleidsalternatieven zijn opties aangegeven door de opdrachtgever, cliënt, (wettelijk) bevoegden en/of experten.
Participatie De opties van zowel de gewilde als ongewilde betrokkenen worden gehoord.
Methode De nieuwe beleidsalternatieven komen voort uit uitgevoerde onderzoeksmethoden.
Analogie De nieuwe beleidsalternatieven worden gebaseerd op oplossingen van een gelijkaardig probleem.
Parallellisme De nieuwe beleidsalternatieven gehanteerd door de beleidmakers zijn gebaseerd op de oplossingen van exact hetzelfde probleem, echter bevindt dit probleem zich niet in hetzelfde land.
Oorzaak De nieuwe beleidsalternatieven zijn gebaseerd op basis van een causaal veldmodel. Hierbij worden oplossingen gezocht door te kijken naar oorzaken van het probleem.
28
Teken De nieuwe beleidsalternatieven hangen samen met gespotte trends en ontwikkelingen in de samenleving of omgeving van de belanghebbenden.
Motivatie De nieuwe beleidsalternatieven worden ontwikkeld dankzij de erkenning van het maatschappelijk draagvlak voor de opties.
Ethiek De nieuwe beleidsalternatieven zijn gebaseerd op de normen en waarden. De oplossingen worden opgesteld vanuit de overtuiging wat goed en slecht is.
Classificatie De nieuwe beleidsalternatieven zijn tot stand gekomen door gebruik te maken van bestaande taxonomieën en typologieën van beleidsinstrumenten.
Beleidsbepaling
‘Beleidsbepaling’ is de derde stap in het beleidsproces. Deze stap bestaat uit het kiezen voor een beleidsoplossing en het overeenstemmen rond deze oplossing. Gupta (2004) beschrijft beleidsbepaling als het mobiliseren van politieke steun voor een oplossing teneinde die oplossing formeel te bekrachtigen. Bij het maken van een keuze zijn er drie verschillende opties. Actoren kunnen positieve, negatieve of geen beslissingen maken omtrent beleidsopties.
Beleidsoplossing kiezen
Bij ‘beleidsbepaling’ zijn er minder actoren betrokken dan bij beleidsformulering. Er bestaan twee verschillende soorten beleidsbepalers bij deze fase. Ten eerste zijn er de gezagsdragers, deze zijn formeel bevoegde actoren tot beleidsbepaling. Ten tweede zijn er de hoofdrolspelers, dit zijn alle andere actoren die bij de beleidsbepaling de doorslag kunnen geven. De laatstgenoemde kunnen invloed uitoefenen als ze voldoen aan vijf voorwaarden (Herweijer, 2014).
1. Een groot probleembesef
2. Bezit over betekenisvolle invloedsmiddelen 3. Grote bereidheid tot inzet van die middelen 4. Eenduidig standpunt