“RECOMMENDED FOR YOU(TUBE)?!”
EEN EXPLORATIEF ONDERZOEK NAAR DE PERCEPTIE EN
APPROPRIATIE VAN AANBEVELINGSALGORITMES OP YOUTUBE
EN DE ROL VAN MEDIA GELETTERDHEID
Wetenschappelijke verhandeling Aantal woorden: 21340
Koen Van Crombrugge
Stamnummer: 01612688
Promotor: dr. Peter Mechant
Commissaris: Marijn Martens
Masterproef voorgelegd voor het behalen van de graad master in de richting Communicatiewetenschappen afstudeerrichting Nieuwe Media en Maatschappij
Deze pagina is niet beschikbaar omdat ze persoonsgegevens bevat.
Universiteitsbibliotheek Gent, 2021.
This page is not available because it contains personal information.
Ghent University, Library, 2021.
3 Voorwoord
Deze masterproef omvat de laatste stappen in mijn opleiding aan Universiteit Gent. Ik heb een onderwerp kunnen kiezen dat mij erg interesseerde, waardoor mijn verwachtingen hoog waren voor dit eindwerk. Dit was niet altijd evident, maar ik heb hier alvast veel uit geleerd.
Graag bedank ik nog enkele personen die mij steunden in dit proces. Eerst en vooral wil ik mijn promotor, Peter Mechant, bedanken voor de feedback en begeleiding. Daarnaast bedank ik mijn ouders, broer en vriendin voor de waardevolle steun. Ten slotte, bedank ik de participanten van mijn onderzoek, zij die massaal deelnamen aan mijn survey, en zij die ook deelnamen aan de interviews.
4 Abstract
YouTube is alomtegenwoordig en aanbevelingsalgoritmes spelen een centrale rol in het gebruik van YouTube. Die algoritmes zijn niet neutraal - ze bezitten een vorm van macht - waardoor ze invloed kunnen uitoefenen op het gedrag van gebruikers. Uit literatuur blijkt dat sommige mensen strategieën ontwikkelen om deze algoritmes te beïnvloeden, anderen hebben minder kennis of gaan minder bewust om met algoritmes. Van YouTube, het grootste videoplatform, is hierover nog weinig bekend. Daarom wil deze studie inzicht bieden in de perceptie en appropriatie van aanbevelingsalgoritmes op YouTube, alsook de rol van media geletterdheid in beide. De centrale vraag gaat dan ook na hoe YouTube-gebruikers aanbevelingsalgoritmes percipiëren en appropriëren en wat de rol van media geletterdheid hierin is. In deze studie wordt een multimethodisch onderzoeksdesign gebruikt. Eerst werd een verkennende survey (n=338) uitgestuurd om gegevens te verzamelen over de perceptie en appropriatie van YouTube en de algoritmes, zodat de rol van media geletterdheid hierin kon worden bestudeerd. Daarna werd de survey gebruikt als rekruteringstool om participanten te bevragen via diepte-interviews (n=10), om de perceptie en appropriatie diepgaand te kunnen onderzoeken. Resultaten tonen aan dat de meeste participanten een zekere vorm van kennis hadden over de werking van algoritmes. De manieren die gekend waren om aanbevelingen te wijzigen, werden weinig gebruikt en lagen in dezelfde lijn met het niet kennen van strategieën. Participanten hadden geen ‘last’ of geen ‘drang’ om hun aanbevelingen te wijzigen. YouTube en de aanbevelingen worden het meest gebruikt op de smartphone, computer of laptop. De routines van het gebruik zijn divers en afhankelijk van de context. Hoewel de aanbevolen inhoud grotendeels wordt geapproprieerd, kunnen de aanbevelingen in sommige gevallen gededomesticeerd worden. Tot slot vonden we dat media geletterdheid zowel gerelateerd was aan de kennis over algoritmes op YouTube als het YouTube-gebruik.
5 Inhoud
1 Introductie ... 8
2 Literatuur ... 11
2.1 Algoritmes als onderzoeksobject ... 11
2.1.1 Algoritmes als technische, sociale en culturele systemen ... 11
2.1.2 Aanbevelingsalgoritmes op YouTube ... 12
2.1.3 Sociale aanbevelingen op YouTube ... 13
2.2 Media geletterdheid ... 14
2.3 De domesticatie van media technologieën ... 15
2.3.1 De drievoudige betekenisgeving van media technologieën ... 17
2.4 Gerelateerde studies over de perceptie van algoritmes ... 18
2.4.1 Het bewustzijn en kennis over algoritmes ... 18
2.4.2 Het gebruik van strategieën en factoren die hierop een invloed hebben ... 19
2.4.3 De invloed van bewustmaking en kennis over algoritmes ... 20
2.4.4 Weerstand tegenover de implementatie van algoritmes ... 20
2.4.5 Waardering en aversie voor algoritmes ... 21
3 Methodologie ... 23
3.1 Deel 1 – Kwantitatief exploratief onderzoek... 24
3.1.1 Pretest ... 24
3.1.2 Procedure en metingen ... 24
3.1.3 Rekrutering en participanten ... 26
3.1.4 Data-analyse ... 27
3.2 Deel 2 – Kwalitatief verdiepend onderzoek ... 28
3.2.1 Procedure ... 28
3.2.2 Vragenlijst ... 28
3.2.3 Rekrutering en participanten ... 30
3.2.4 Data-analyse ... 30
6
4.1 Beschrijving van de survey-steekproef ... 31
4.2 Exploratieve analyse van de survey-data ... 33
4.2.1 Samenhang tussen variabelen van YouTube-gebruik ... 33
4.2.2 Samenhang tussen YouTube-gebruik en geletterdheid variabelen ... 33
4.2.3 Samenhang tussen kennis over algoritmes en andere variabelen ... 34
4.2.4 Samenhang tussen de verschillende competenties van media geletterdheid ... 34
4.2.5 Rol van leeftijd en opleidingsniveau ... 35
4.2.6 Belangrijkste bevindingen ... 35
4.3 De media geletterdheid groepen ... 35
4.4 De perceptie van aanbevelingsalgoritmes op YouTube (RQ1) ... 36
4.4.1 Kennis en gebruik van manieren om aanbevelingen te wijzigen ... 37
4.4.2 Kennis over de werking van aanbevelingsalgoritmes op YouTube ... 39
4.4.3 Kritische attitude tegenover aanbevelingen op YouTube... 41
4.4.4 Belangrijkste bevindingen ... 42
4.5 De domesticatie van aanbevelingsalgoritmes op YouTube (RQ2) ... 42
4.5.1 Objectificatie ... 42
4.5.2 Incorperatie ... 46
4.5.3 De-domesticatie ... 51
4.5.4 Belangrijkste bevindingen ... 52
4.6 De invloed van media geletterdheid op de kennis over algoritmes op YouTube (RQ3) ... 53
4.6.1 Invloed van media geletterdheid op het gemiddeld kennisniveau ... 53
4.6.2 Invloed van media geletterdheid per kennisvraag ... 54
4.6.3 Belangrijkste bevindingen ... 56
4.7 De invloed van media geletterdheid op het YouTube-gebruik (RQ4) ... 56
4.7.1 Invloed van media geletterdheid op dagelijks YouTube-gebruik ... 56
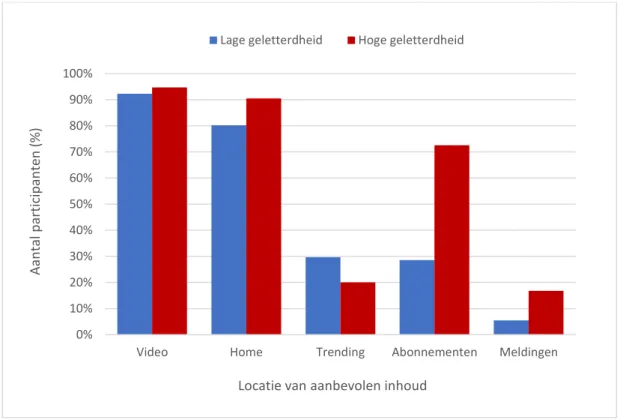
4.7.2 Invloed van media geletterdheid op het gebruik van aanbevelingen ... 56
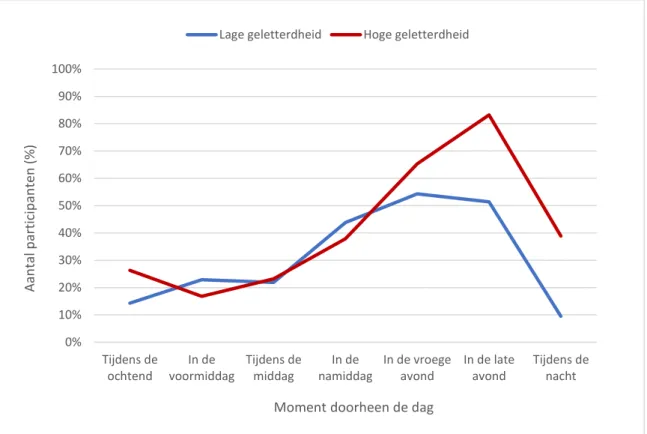
4.7.3 Invloed van media geletterdheid op gebruik per toestel ... 58
7
4.7.5 Invloed van media geletterdheid op ruimtelijk en sociaal gebruik ... 60
4.7.6 Belangrijkste bevindingen ... 60
5 Discussie... 61
6 Beperkingen en suggesties voor verder onderzoek ... 64
7 Conclusie ... 66
8 Notities ... 67
9 Referenties ... 68
8
1 Introductie
Vijftien jaar geleden verscheen de eerste video op YouTube. Sinds 2005 is het videoplatform uitgegroeid tot het grootste online user-generated content (UGC) videoplatform op het internet. De strategie van YouTube hierbij laat iedereen toe om video’s te uploaden en bij te dragen aan het platform. Volgens statistieken van YouTube kijken hun gebruikers dagelijks een biljoen uur aan YouTube-video’s (YouTube, 2020c). Ook in Vlaanderen wordt het platform vaak gebruikt. Ongeveer 66% van de Vlamingen gebruikt YouTube maandelijks. Bij 16-24-jarigen en 25-34-jarigen blijkt het platform het meest populair met een wekelijks gebruik van respectievelijk 87% en 73% (Vandendriessche & De Marez, 2019).
In het YouTube-gebruik spelen aanbevelingssystemen een centrale rol. Die systemen zijn algoritmes die op basis van personalisatie aanbevelingen tonen die voor gebruikers nuttig kunnen zijn, zoals het aanbevelen van een video (Burke, 2007). Volgens Neal Mohan, leidinggevende van de productafdeling van YouTube, wordt meer dan 70% van de tijd die besteed wordt op YouTube, gedreven door aanbevelingssystemen (Solsman, 2018). Onderzoek toont aan dat de aanbevelingen op de videopagina de belangrijkste bron zijn voor het bekijken van video’s op YouTube (Zhou, Khemmarat, & Gao, 2010). Bovendien vonden andere onderzoekers dat 60% van wat aangeklikt wordt op de startpagina, bestaat uit het selecteren van aanbevolen inhoud (Davidson, Liebald, Liu, Nandy, & Van Vleet, 2010).
Voorts wordt ons dagelijks leven gekenmerkt door algoritmes die inhoud selecteren voor feeds, gepersonaliseerde zoekresultaten geven en aanbevelingen tonen (Eslami et al., 2015) en dat vertaalt zich naar het academische debat omtrent de sociale macht van algoritmes. Het onderzoeksdomein van critical algorithm studies focust zich op de studie van algoritmes vanuit een complex ecosysteem van sociale, culturele en technische factoren (Beer, 2017; Willson, 2017). Het academisch debat omvat een reeks van empirische studies die de sociale perceptie tegenover algoritmes bestuderen, alsook studies die de omgang met algoritmes in het dagelijks leven onderzoeken.
Het is duidelijk dat YouTube een dominant platform is in het medialandschap en dat aanbevelingen een grote rol spelen in het YouTube-gebruik. Toch blijkt er nog weinig bekend over de perceptie en het gebruik van aanbevelingssystemen specifiek op YouTube. Dit onderzoek beoogt aan beide aspecten bij te dragen.
9
In een eerste plaats wordt gekeken naar de mate waarin mensen zich bewustzijn en bewust omgaan met algoritmes op YouTube. Bepaalde onderzoekers concludeerden voor diverse sociale mediaplatformen dat het merendeel van hun participanten niet bewust waren van de aanwezigheid van algoritmes in hun dagelijks leven (Eslami et al., 2015; Powers, 2017), terwijl participanten in andere studies wel bewust bleken (Bucher, 2017; Rader & Gray, 2015). Verder wordt in dit onderzoek nagegaan in welke mate participanten strategieën gebruiken (bv. pagina refreshen om andere inhoud te krijgen) om bewust om te gaan met algoritmes. Eerdere onderzoeken leverden ook hiervoor gevarieerde resultaten op (zie 2.4.2). Deze studie kan nieuwe inzichten bieden in het bewustzijn van, bewust omgaan met en gebruik van strategieën over aanbevelingssystemen.
Een tweede thema in dit onderzoek is de studie van hoe omgegaan wordt met algoritmes in het dagelijks leven. Bucher (2017) onderzocht de alledaagse en affectieve ervaringen van participanten op Facebook (bv. gevoelens bij gepersonaliseerde reclame). Andere onderzoekers (Leong, 2020; Siles, Espinoza-Rojas, Naranjo, & Tristán, 2019) deden onderzoek naar hoe algoritmes in het dagelijks leven werden ervaren aan de hand van de domesticatie theorie. In dit onderzoek wordt, voor de eerste keer, nagegaan hoe participanten de algoritmes op YouTube domesticeren in hun dagelijks leven.
Aanvullend wordt bij voorgaande concepten ook gekeken naar de rol van geletterdheid in de kennis over algoritmes en het YouTube-gebruik. Min (2019) vond dat internetvaardigheden een rol spelen in het bewust omgaan met algoritmes. Daarnaast geeft hij aan dat algoritmes in vergelijking met andere technologische concepten vaag en moeilijk te begrijpen zijn, waardoor onderzoek in de toekomst nood kan hebben aan meer geavanceerde digitale vaardigheden. In dit onderzoek wordt verondersteld dat media geletterdheid hierop een antwoord kan bieden. De meetschalen voor media geletterdheid die gebruikt worden in dit onderzoek, kunnen dan ook een belangrijke bijdrage leveren.
YouTube is alomtegenwoordig en een groot deel van dit gebruik blijkt via de aanbevelingen te gaan. Daarnaast bezitten algoritmes macht en zijn mensen zich niet altijd bewust van de algoritmes die hen beïnvloeden (deterministisch). Bovendien kunnen deze algoritmes leiden tot een filter bubbel, die een effect kan hebben op hoe mensen kijken naar de realiteit. Tot op heden is slechts één studie bekend over algoritmes op YouTube. Die studie focust zich op hoe influencers strategieën gebruiken om algoritmes te beïnvloeden.
10
In ons onderzoek kijken we naar minder zware gebruikers van YouTube. Tevens is de kennis over algoritmes en de appropriatie ervan nog niet bestudeerd voor YouTube.
Dit onderzoek heeft tot doel inzicht te verkrijgen in de perceptie en appropriatie van aanbevelingsalgoritmes op YouTube, alsook de rol van media geletterdheid in beide. Zo kan deze studie de huidige empirische studies aanvullen. De centrale vraag wordt hieronder voorgesteld, alsook de vier deelvragen die het beantwoorden van de centrale vraag ondersteunen.
RQ: Hoe percipiëren en appropriëren YouTube-gebruikers de aanbevelingsalgoritmes en wat is de rol van media geletterdheid hierin?
RQ1: Hoe percipiëren YouTube-gebruikers de aanbevelingsalgoritmes op YouTube? RQ2: Hoe appropriëren YouTube-gebruikers de aanbevelingsalgoritmes op YouTube? RQ3: Welke invloed heeft media geletterdheid op de kennis over algoritmes op YouTube? RQ4: Welke invloed heeft media geletterdheid op het YouTube-gebruik?
Voor dit exploratief onderzoek wordt een multimethodische aanpak gehanteerd. Daarbij neemt de onderzoeker eerst een verkennende survey af om kwantitatieve gegevens te bekomen die met behulp van statistische methodes verwerkt worden. Vervolgens worden verdiepende interviews uitgevoerd met kwalitatieve resultaten die via codering geanalyseerd worden. Om de nodige achtergrond mee te geven aan de lezer worden hierna de concepten algoritmes, media geletterdheid, domesticatie en de perceptie van algoritmes verder toegelicht.
11
2 Literatuur
2.1 Algoritmes als onderzoeksobject
2.1.1 Algoritmes als technische, sociale en culturele systemen
Om de perceptie en de appropriatie van aanbevelingsalgoritmes te begrijpen, is het noodzakelijk om te achterhalen wat er verstaan wordt onder algoritmes. Wat algoritmes zijn, valt echter moeilijk te conceptualiseren. Informeel kan een algoritme gezien worden als een gedefinieerde berekeningsprocedure die een bepaalde waarde, of reeks van waarden, als invoer neemt en een bepaalde waarde, of reeks van waarden, als uitvoer produceert. Een algoritme is dus een opeenvolging van rekenstappen die de invoer in de uitvoer omzetten (Seaver, 2013).
Algoritmes hebben echter een grote verantwoordelijkheid want ze bepalen wat er wanneer moet gebeuren in een bepaalde situatie (Bucher, 2018). Bovendien brengen algoritmes sociale en culturele implicaties met zich mee (Seaver, 2013). In tegenstelling tot het louter technisch benaderen van de term algoritme, roept Seaver (2013) op om algoritmes te benaderen als heterogene socio-technische systemen: ‘These algorithmic systems are not standalone little boxes, but massive, networked ones with hundreds of hands reaching into them, tweaking and tuning, swapping out parts and experimenting with new arrangements’ (Seaver, 2013). Hij geeft aan dat bij analyse van deze systemen geen onderscheid mag worden gemaakt tussen algoritmes als culturele en technische objecten. De bedoelingen die ontwikkelaars bijvoorbeeld hebben zijn minstens even belangrijk als de bedoelingen die sorteeralgoritmes hebben. In lijn hiermee geeft Kitchin (2017) aan om algoritmes te benaderen als ‘complex socio-technical assemblages’.
De sociale macht die algoritmes uitoefenen wordt vaak onderschat in studies over algoritmes, omdat algoritmes net bestudeerd worden als object op zich, zonder rekening te houden met risico’s van het gebruik van algoritmen of sociale complicaties. Op dit niveau worden algoritmes omschreven als abstracties met een autonoom bestaan. Ze worden onafhankelijk beschouwd van de infrastructuur waarin ze worden geïmplementeerd (Goffey, 2008). Daardoor blijven algoritmes meaningless machines (Gillespie, 2014) of mathematical fiction (Constantiou & Kallinikos, 2015). In deze paper wordt wel stilgestaan bij complicaties van algoritmes (e.g. filter bubbel) en worden participanten ook meer bewust gemaakt over de werking van algoritmes. Dit onderzoek situeert zich dan ook in het onderzoeksdomein van ‘critical algorithm studies’, een
12
transdisciplinair veld waarbij algoritmes en hun sociale implicaties kritisch worden benaderd (Gillespie & Seaver, 2015).
2.1.2 Aanbevelingsalgoritmes op YouTube
Om de algoritmes en de aanbevelingen die ze op YouTube produceren te kaderen, wordt het concept aanbevelingssystemen verder toegelicht. Aanbevelingssytemen worden omschreven als gepersonaliseerde informatie-agenten. Op basis van personalisatie worden aanbevelingen of suggesties gegeven van items die nuttig kunnen zijn voor een gebruiker (Burke, 2007). In de meeste gevallen stellen personalisatie systemen gebruikersprofielen op die de interesses en voorkeuren van gebruikers bevatten. Deze gebruikersprofielen kunnen impliciet via het systeem (bv. klikgedrag) of expliciet via de gebruiker (bv. vind-ik-leuk geven) opgesteld worden (Bozdag, 2013).
Aanbevelingssystemen kunnen verder onderscheiden worden van elkaar naargelang de bron waar ze hun kennis vandaan halen (Burke, 2007). In het algemeen kunnen twee type aanbevelingssytemen onderscheiden worden. Content-based filtering systemen stellen items voor die gerelateerd zijn aan de items die de gebruiker in het verleden interessant vond. Collaborative filtering systemen bieden items aan op basis van items die anderen met een gelijkaardige voorkeur interessant vonden. Daarnaast zijn er ook hybride aanbevelingssytemen. Tegenwoordig maken aanbevelingssystemen gebruik van geavanceerde technieken waarbij bovenstaande technieken worden gecombineerd (Ricci, Rokach, & Shapira, 2015).
In 2016 gaf Google via een technische paper aan dat de aanbevelingssystemen van YouTube gebruik maken van machine learning (Covington, Adams, & Sargin, 2016). Eerst worden op basis van de kijkgeschiedenis en collaborative filtering enkele honderden video’s geselecteerd uit het video-corpus op YouTube. Daarna worden deze video’s gerangschikt in een juiste volgorde door rekening te houden met de verwachtte kijktijd van video’s.
Doordat de algoritmes specifiek aanbevelingen voorstellen aan een gebruiker, definiëren we de algoritmes in deze paper als aanbevelingsalgoritmes. We veronderstellen dat deze aanbevelingsalgoritmes gebruik maken van hybride technieken, in combinatie met machine learning, om gepersonaliseerde aanbevelingen voor video’s te suggereren op YouTube.
13
2.1.3 Sociale aanbevelingen op YouTube
In het vorige onderdeel werden aanbevelingsalgoritmes gedefinieerd. Hieronder worden niet de algoritmes zelf, maar de uitkomst van deze algoritmes - namelijk de aanbevelingen die ze produceren op YouTube - bestudeerd. Deze aanbevelingen zijn terug te vinden op verschillende locaties op YouTube en kunnen gegroepeerd worden naargelang de pagina's of onderdelen waarop ze zich bevinden. De aanbevelingen die gebruikers onder of naast een video krijgen, zijn gebaseerd op video's die andere gebruikers samen met de huidige video bekeken of gerelateerd zijn aan het onderwerp van de huidige video. Daarnaast kunnen deze aanbevelingen ook video’s uit de abonnementen van gebruikers bevatten. Op de homepagina streeft YouTube naar de meest relevante en gepersonaliseerde aanbevelingen voor haar gebruikers. De aanbevelingen op de homepagina omvatten een mix van nieuwe video's, video's die gelijkaardige gebruikers bekeken, video's uit de abonnementen van gebruikers etc. De aanbevelingen die gebruikers krijgen op de trendingpagina, bestaan uit video's die nieuw en populair zijn in een bepaalde regio. De abonnementenpagina bestaat uit een verzameling van aanbevelingen die de meest recente uploads van video's bevatten waarop de gebruiker een abonnement heeft. Via meldingen stuurt YouTube standaard notificaties voor aanbevelingen van kanalen waar de gebruiker vaak naar kijkt of een abonnement op heeft (YouTube, 2020a).
In deze paper ligt de nadruk op het bestuderen van de aanbevelingen die gebruikers onder of naast een video en op hun homepagina krijgen. De andere aanbevelingen worden bestudeerd als aanvulling om de bredere context van de sociale perceptie in rekening te nemen.
Op YouTube hebben gebruikers mogelijkheden om de inhoud van hun aanbevelingen te beïnvloeden of wijzigen. Gebruikers hebben de optie om video’s of zoekopdrachten uit hun kijk- of zoekgeschiedenis te verwijderen. Dit verkleint de kans op het krijgen van gelijkaardige aanbevelingen. De kijk- of zoekgeschiedenis kan ook volledig verwijderd worden, indien de aanbevelingen niet relevant blijken. Daarnaast kunnen gebruikers hun kijk- of zoekgeschiedenis pauzeren of de incognito-modus inschakelen, indien ze niet willen dat hun activiteiten een invloed hebben op hun toekomstige aanbevelingen. Irrelevante aanbevolen inhoud kan verwijderd worden door de functie niet-aanbevelen of kanaal-niet-aanbevelen te selecteren. Deze verkregen feedback kan vervolgens ook verwijderd worden (YouTube, 2020b). De
14
bovenstaande mogelijkheden lijken nuttig. Toch moet er kritisch gekeken worden naar de mate waarin gebruikers zich bewust zijn van en deze mogelijkheden gebruiken. Daarnaast laten verschillende onderzoeken zien dat sommige gebruikers (creatieve) strategieën hanteren om hun aanbevelingen te beïnvloeden of wijzigen (Bucher, 2017; Min, 2019).
In het huidig hoofdstuk werden algoritmes, aanbevelingsalgoritmes en aanbevelingen in de context van YouTube behandeld. De volgende onderdelen van deze paper bespreken media geletterdheid, domesticatie van media en de sociale perceptie van algoritmes.
2.2 Media geletterdheid
Media geletterdheid gaat over het bewust omgaan met media technologieën in het dagelijks leven. Het begrip media geletterdheid heeft een lange geschiedenis met een aantal verschillende definities en complexe interpretaties (Livingstone, 2004b; Livingstone, Van Couvering, & Thumin, 2008). Het concept overlapt ook met andere vormen van geletterdheid zoals digitale en informatie geletterdheid (Koltay, 2011). In deze paper wordt media geletterdheid omschreven als de combinatie van technische en cognitieve competenties die noodzakelijk zijn om sociale media en meer bepaald YouTube te kunnen gebruiken op een effectieve en efficiënte manier (Vanwynsberghe, Boudry, & Verdegem, 2015). Om deze definitie te verduidelijken, wordt deze definitie afgewogen met die van andere relevante onderzoekers in het veld van media geletterdheid. De aanpak van Vanwynsberghe (2014) wordt gevolgd om de technische en cognitieve competenties verder te conceptualiseren.
De technische competenties worden gedefinieerd als de kennis en de omzetting van deze kennis naar vaardigheden om sociale media te gebruiken. Deze definitie werd gebaseerd op de ‘toegang’ component van Livingstone, Van Couvering, en Thumim (2005) en meer specifiek de basis navigatie of functionele competenties. Deze competenties zijn essentieel om sociale media te kunnen gebruiken. Als we dit op YouTube toepassen, zou dit bijvoorbeeld gaan over het openen van YouTube, en het opzoeken van een video. De functionele competenties overlappen met hoe van Deursen en van Dijk (2010) operationele vaardigheden beschrijven. In hun definiëring van technische competenties maken ze nog een onderscheid in operationele en formele (medium-specifieke) vaardigheden. In dit onderzoek worden deze twee vaardigheden samen beschouwd om de technische competenties na te gaan.
15
De cognitieve competenties worden gedefinieerd volgens Livingstone (2004a) als de analyse en de evaluatie van inhoud op sociale media. Deze competenties overlappen met de informatie en strategische vaardigheden van van Deursen en van Dijk (2010).
Hoewel media geletterdheid dus wordt opgedeeld in technische en cognitieve competenties, is het nuttig om te vermelden dat beide competenties nauw verwant zijn. Van Deursen, Helsper, en Eynon (2016) tonen bijvoorbeeld aan dat verbeterde technische competenties kunnen leiden tot een vooruitgang in cognitieve competenties.
In de huidige cultuur van sociale media, zijn de traditionele invullingen van media geletterdheid of andere geletterdheid vormen, slechts deels van toepassing op het gebruik van sociale media, dat gekenmerkt wordt door een toenemende graad van participatie (Vanwynsberghe et al., 2015). Om die reden werden naast technische en cognitieve competenties ook de vaardigheden om te communiceren en inhoud te creëren beschouwd bij sociale media geletterdheid. Voor YouTube valt op te merken dat deze participatieve vaardigheden vooral van toepassing zijn op actieve YouTube-gebruikers. Voor de vele passieve gebruikers zullen de technische en cognitieve competenties vaak volstaan.
2.3 De domesticatie van media technologieën
Domesticatie wordt gebruikt als metafoor en analytisch concept om te achterhalen hoe mens en technologie elkaar aanpassen om naast elkaar te kunnen bestaan. Het gaat voornamelijk over hoe een persoon een technologie inpast in zijn of haar dagelijks leven (Hynes & Richardson, 2009). De domesticatie theorie wordt gebruikt om de verwerving en weigering van media technologieën te bestuderen. Daarnaast word dit kader ook gebruikt om te bestuderen hoe betekenis wordt toegekend aan technologie, hoe een technologie ervaren wordt en welke rol technologieën spelen in het dagelijks leven van mensen (Haddon, 2006). Enkele kernconcepten van de domesticatie theorie worden hieronder toegelicht.
Dat het huishouden centraal staat in de domesticatie van technologieën, wordt benadrukt door de ‘moral economy of the household’ (Silverstone, Hirsch, & Morley, 1992). Het huishouden bestaat uit een systeem van sociale relaties waarin het publieke aan het private wordt gelinkt. Aan de ene kant is het huishouden een economische eenheid want de leden nemen deel aan de publieke economie (productie en
16
consumptie). Aan de andere kant is het een morele eenheid, doordat de betekenis van het consumeren van technologie afhankelijk is van de normen en waarden van dat huishouden.
Het domesticatieproces bestaat uit verschillende dimensies: commodificatie, appropriatie (objectificatie en incorporatie) en conversie (Silverstone, 1994; Silverstone et al., 1992). In de commodificatie dimensie worden technologieën via marketingcommunicatie voorgesteld aan consumenten. Media technologieën bevatten een dubbel leven. Enerzijds is er de betekenis die toegekend is door de ontwikkelaars via het design van de technologie. Anderzijds hebben consumenten de mogelijkheid om deze betekenis volledig of deels te aanvaarden of weigeren. In de appropriatie fase staat het bezit en eigendom van technologie centraal. De technologie wordt verworven en wordt van de publieke sfeer naar de private sfeer overgebracht. Het proces van appropriatie bestaat uit de objectificatie en incorporatie van technologieën. In de objectificatie fase ligt de nadruk op de locatie(s) waarmee een technologie wordt verbonden aan een bepaalde ruimte. Daarnaast gaat het ook over de betekenissen die worden toegekend aan de technologie. In de incorporatie fase wordt gekeken hoe de technologie gebruikt wordt en hoe deze technologie geïntegreerd wordt in de routines van het dagelijks leven. In de conversie fase, ten slotte, wordt het gebruik en de betekenis die aan technologie toegekend is, vertaald naar de buitenwereld, door technologie te delen, te bediscussiëren en te wijzigen.
Dat de fysieke dimensie van het mediagebruik aan de basis ligt van het domesticatieproces, wordt geïllustreerd door het sleutelconcept double articulation (Silverstone, 1994). In eerste plaats bevatten media technologieën betekenis als materiële objecten (technologie zelf) door hun specifieke esthetische en functionele eigenschappen. Ten tweede geven media technologieën betekenis aan media teksten als symbolische objecten. Media inhoud kan namelijk niet gearticuleerd worden zonder dat het object (technologie) gearticuleerd wordt (Morley & Silverstone, 1990; Silverstone et al., 1992). Door onderzoek en omwille van praktische redenen hebben onderzoekers het tweevoudige betekenisgevingproces uitgebreid met een derde dimensie, waarbij de materiële en symbolische betekenis van media kan variëren naargelang de context (Courtois, Mechant, Paulussen, & De Marez, 2012; Hartmann, 2006).
Een ander onderdeel van de domesticatie theorie werd ontwikkeld door Noorse onderzoekers. Deze onderzoekers legden de focus op de evolutie na de verwerving van technologie (Silverstone & Haddon,
17
1996). Ze benadrukten dat domesticatie geen eenmalige gebeurtenis was, maar een doorlopend proces. Hierdoor introduceerden de onderzoekers twee concepten. Enerzijds kan er een dedomestication plaatsvinden, waarbij een technologie of onderdelen van een technologie niet meer actief worden gebruikt. Anderzijds kan er een redomestication plaatsvinden. Een technologie of onderdeel van een technologie kan dan opnieuw gedomesticeerd worden (Haddon, 2017).
Om de domesticatie theorie toe te passen op het onderzoeksobject van algoritmes, geven we onze eigen interpretatie aan de bovenstaande kernconcepten. Ten eerste veronderstellen we dat algoritmes meestal individueel worden gebruikt in plaats van door huishoudens. In een vorige studie naar de domesticatie van Netflix-algoritmes, benadrukten de participanten hun account als iets persoonlijks (Siles et al., 2019). Ten tweede zijn algoritmes niet-tastbare objecten en zijn ze niet plaatsgebonden, waardoor de context een relevante rol kan spelen in de domesticatie (zie 2.3.1). Ten derde focussen we in dit onderzoek specifiek op het gebruik en de appropriatie van algoritmes. De objectificatie vertaalt zich naar de kenmerken van de toestellen en de sociale en ruimtelijk context van YouTube en de aanbevelingen. De incorporatie wordt vertaald naar hoe algoritmes worden gebruikt naargelang de inhoud, toestellen en context.
De relevantie van deze theorie in de context van studies rond de sociale perceptie van algoritmes, blijkt uit recente studies, die de theorie gebruiken als kader om het wederzijdse domesticatieproces te bestuderen tussen de Netflix algoritmes en hun gebruikers (Siles et al., 2019) en om de morele economie te begrijpen van het delen van informatie via het Facebook algoritme (Leong, 2020).
2.3.1 De drievoudige betekenisgeving van media technologieën
Het concept van meervoudige betekenisgeving werd reeds aangehaald en wordt hieronder verder toegelicht. Onderzoekers die de domesticatie van media technologieën bestuderen houden zich vaak vast aan een dubbele articulatie, waarbij de nadruk ligt op hoe de betekenisgeving van objecten en teksten worden vormgegeven in hun bredere context (Courtois et al., 2012; Courtois, Verdegem, & De Marez, 2013). Deze context blijkt problematisch te zijn in het bestuderen van de dubbele betekenisgeving van media technologieën. Onderzoekers focussen zich hoofdzakelijk op de context (en het object), waardoor minder aandacht wordt gegeven aan de relatie tussen de media tekst en het medium, de symbolische betekenis van technologie (Courtois et al., 2012; Courtois et al., 2013; Hartmann, 2006; Livingstone, 2007).
18
Om die reden werd het concept triple articulation naar voor geschoven. De drievoudige betekenisgeving van media technologieën legt de nadruk op de interactie tussen de media als objecten, als tekst en in hun symbolische context (Hartmann, 2006). De context wordt hier expliciet gescheiden van de twee andere dimensies. De waarde van de drievoudige betekenisgeving werd reeds in empirisch onderzoek gevalideerd (Courtois et al., 2012; Courtois et al., 2013). Courtois et al. (2012) vonden dat het object en de context individueel betekenisvol waren en beide bijdroegen aan de algemene betekenis van het gebruik. Daarnaast neemt het belang van triple articulation toe in een tijdperk van convergentie, waar de inhoud steeds meer los komt te staan van de technologie en de context (Courtois et al., 2012; Courtois et al., 2013).
In deze paper maken we de veronderstelling dat algoritmes anders ervaren worden naargelang de context. Zoals Willson (2017) aangeeft wordt het dagelijks leven gekenmerkt door algoritmes in allerlei software, en ervaren we deze ook op verschillende tijdstippen doorheen de dag. De context zal dus variëren en het concept van triple articulation biedt een kader dat kan worden toegepast op het huidig onderzoek.
2.4 Gerelateerde studies over de perceptie van algoritmes
2.4.1 Het bewustzijn en kennis over algoritmes
Een eerste groep van onderzoeken gaat over de kennis en het bewustzijn van de aanwezigheid van algoritmes in de dagelijkse omgeving. Eslami et al. (2015) vonden dat meer dan de helft van de participanten in hun studie niet op de hoogte waren van het feit dat algoritmes inhoud filteren op het nieuwsoverzicht van Facebook. Een gelijkaardig resultaat werd gevonden in de studie van Powers (2017), waarbij studenten zich grotendeels niet bewust waren van nieuwspersonalisatie en hoe algoritmes op Google en Facebook werken om gepersonaliseerd nieuws te tonen. In lijn met deze studies, veronderstelden French en Hancock (2017) dat participanten in hun studie sterk de overtuiging deelden dat er geen sprake zou zijn van een filterproces (door algoritmes) op het nieuwoverzicht van Facebook en Twitter. Studies die niet expliciet focussen op kennis over algoritmes komen tot gelijkaardige bevindingen (Siles et al., 2019).
In tegenstelling tot de bovenstaande studies, vonden andere onderzoekers dat de meeste participanten in hun studie zich wel bewust waren van de aanwezigheid van algoritmes (Bucher, 2017; Rader & Gray, 2015). Deze tegenstelde bevindingen zijn mogelijk beïnvloed door de rekrutering van de participanten in hun steekproef. In de studie van Rader en Gray (2015) werden bewust geletterde participanten gerekruteerd die
19
vertrouwd waren met het internet en sociale media, en zoals ze aangeven, mogelijk meer bewust konden zijn van algoritmes dan de algemene bevolking. In de studie van Bucher (2017) werden dan weer participanten gerekruteerd die expliciet op Twitter spraken over de algoritmes op Facebook.
Op basis van deze bevindingen suggereren we dat het merendeel van de mensen zich niet bewust zullen zijn van de rol van algoritmes in hun dagelijks leven.
2.4.2 Het gebruik van strategieën en factoren die hierop een invloed hebben
Een tweede groep focust zich op de strategieën die mensen gebruiken om algoritmes te beïnvloeden, wijzigen of manipuleren. Het uitgangspunt hierbij is dat algoritmes niet enkel dingen doen met mensen, maar tegelijkertijd mensen ook dingen doen met algoritmes (Bucher, 2017).
Eslami et al. (2015) vonden dat bepaalde participanten hun nieuwsoverzicht manipuleerden op Facebook. Deze participanten voerden bijvoorbeeld minder interactie met bepaalde connecties, om minder berichten van hen te zien. In dezelfde trend, vond Bucher (2017) dat meerdere participanten experimenteerden met de werking van de Facebook algoritmes. Eén participant trainde bijvoorbeeld de algoritmes door onbelangrijke berichten te verbergen, om zo meer interessante inhoud te krijgen. Cotter (2019) vond dat influencers op Instagram verschillende strategieën gebruikten om hun zichtbaarheid te vergroten. De participanten hadden veel interactie met hun volgers. Daarnaast simuleerden ze interacties door bijvoorbeeld strategische pagina’s te volgen. Gelijkaardig vond Bishop (2019) dat vloggers op YouTube strategisch omgingen met algoritmes. Ze deelden hun strategieën met andere YouTubers via gesloten Facebook groepen en mailinglijsten.
Deze bevindingen geven aan dat mensen in bepaalde gevallen kritisch en bewust omgaan met algoritmes. Toch is hier nuancering nodig. De participanten in de studie van Eslami et al. (2015) waren zich bewust van algoritmes, en gaven aan dat dit bewustzijn ertoe leidde dat ze hun nieuwsoverzicht op Facebook gingen manipuleren. Dit was ook zo bij participanten in het onderzoek van Bucher (2017). Daarnaast werden de participanten in de studie van Cotter (2019) en Bishop (2019) omschreven als zwaardere Instagram en YouTube gebruikers, waardoor ze mogelijk meer kennis over algoritmes konden bezitten. In contrast tot de bovenstaande studies, vonden Rader en Gray (2015) dat de participanten in hun studie grotendeels bewust waren van algoritmes, maar de attitude deelden van het minder kritisch omgaan met inhoud.
20
Verder geeft Bucher (2017) aan dat nadenken over wat algoritmes zijn en hoe ze functioneren niet enkel relevant is om te begrijpen welke ervaringen, gevoelens en gedachten algoritmes oproepen bij mensen. Deze denkbeelden brengen ook in kaart hoe de sociale perceptie een invloed kan hebben op de manier waarop mensen omgaan met deze algoritmes (Bucher, 2017). Deze theorieën of kennis die mensen opbouwen over de werking van de algoritmes, kunnen ook een invloed hebben op hoe mensen omgaan met algoritmes (Eslami et al., 2015).
2.4.3 De invloed van bewustmaking en kennis over algoritmes
Een belangrijk onderdeel bij studies die de kennis over algoritmes bestuderen, is de bewustmaking van de participanten en nagaan hoe ze in de toekomst zullen omgaan met deze algoritmes. In de studie van Eslami et al. (2015) werden participanten via een tool bewust gemaakt door een gefilterd nieuwsoverzicht te vergelijken met een niet gefilterd nieuwsoverzicht. Toen participanten bewust werden van algoritmes op hun nieuwsoverzicht van Facebook, reageerden de participanten enerzijds verrast en anderzijds ontevreden of boos. Na verloop van tijd rapporteerden de meerderheid van de participanten een verschil in hun gedrag. De participanten gebruikten strategieën en waren in het algemeen nog steeds tevreden over hun nieuwsoverzicht op Facebook
2.4.4 Weerstand tegenover de implementatie van algoritmes
Een vierde groep deed onderzoek naar hoe gebruikers weerstand bieden tegenover de aankondiging van de implementatie van algoritmes op Instagram en Twitter. Skrubbeltrang, Grunnet, en Tarp (2017) identificeerden tegenverhalen over de implementatie van algoritmes: (1) Gebruikers voelen zich onderdrukt door de hegemonie van algoritmes, (2) Gebruikers beweren dat algoritmes hun mogelijkheden tot handelen beperken, (3) Belangen van gebruikers zijn minder relevant dan commerciële belangen en (4) Algoritmes bevatten logica voor het bepalen van relevantie en populariteit. Complementair met deze bevindingen, vonden DeVito, Gergle, en Birnholtz (2017) dat de weerstand van gebruikers grotendeels het gevolg is van het schenden van de verwachtingen van de gebruikers. Er werd een verband gevonden tussen kennis over algoritmes en het type reactie. Meer gedetailleerde kennis over algoritmes ging samen met meer gedetailleerde uitdrukkingen van verzet tegen algoritmes.
21
Deze bevindingen geven argumenten weer over de sociale implicaties van algoritmes. Bovendien geven ze aan dat het schenden van de verwachtingen van gebruikers gerelateerd is aan het bieden van weerstand. Kennis kan een rol spelen in het kritisch zijn en het bieden van weerstand tegenover algoritmes.
2.4.5 Waardering en aversie voor algoritmes
Een vijfde groep deed onderzoek naar de waardering en aversie tegenover advies of aanbevelingen die afkomstig zijn van mensen versus algoritmes. Bepaalde onderzoekers gebruiken het perspectief van waardering om in te gaan tegen de dominante overtuiging van het wantrouwen tegenover algoritmes (Logg, Minson, & Moore, 2019).
Logg et al. (2019) toonden aan dat participanten zich meer aan advies hielden, wanneer dit kwam van algoritmes, dan wanneer advies kwam van mensen. In een paar situaties nam de waardering tegenover algoritmes af. Participanten die meer expertise bezaten over bepaald advies, lieten minder waardering zien tegenover advies van algoritmes, dan anderen. In de studie van Thurman, Moeller, Helberger, en Trilling (2019) ervaarden participanten in het algemeen meer waardering voor nieuwsaanbevelingen van algoritmes op Facebook, dan wanneer ze afkomstig waren van nieuwsredacties. In tegenstelling tot de bovenstaande studie, vonden ze dat de waardering voor algoritmes bleef bestaan, zelfs wanneer de menselijke aanbevelingen afkomstig waren van experts (nieuwsredacties, journalisten). Hun studie laat zien dat de waardering van algoritmes afhankelijk is van de context.
In contrast met bovenstaande studies, bestuderen andere onderzoekers de aversie van mensen tegenover algoritmes. Dietvorst, Simmons, en Massey (2015) concludeerden dat participanten aversie ervaarden tegenover algoritmes, nadat ze ontdekten dat algoritmes imperfect waren. De participanten lieten een grotere tolerantie zien voor hun eigen fouten, dan voor die van algoritmes. Daardoor verkozen ze advies van mensen boven advies van algoritmes, zelfs indien deze algoritmes beter presteerden. Prahl en Van Swol (2017) vonden een gelijkaardig resultaat. Nadat participanten slecht advies ontvingen van mensen en algoritmes, daalde het gebruik van advies van algoritmes meer dan wanneer dat afkomstig was van mensen. Dietvorst, Simmons, en Massey (2018) suggereerden dat de aversie tegenover algoritmes verminderd kon worden door participanten (enige vorm van) controle te geven over de uitkomst van algoritmes. Doordat
22
participanten algoritmes konden wijzigen, voelden ze zich meer tevreden over de uitkomst en waren ze meer geneigd om deze algoritmes te gebruiken in de toekomst.
Deze bevindingen tonen aan dat de waardering van algoritmes afhankelijk is van de context en dat mensen bereid zijn om algoritmes te waarderen vooraleer ze zien dat algoritmes imperfect zijn. Daarnaast kan de aversie tegenover algoritmes verminderd worden door meer controle te geven over de uitkomst van algoritmes.
23
3 Methodologie
In dit onderzoek worden de perceptie en appropriatie van aanbevelingsalgoritmes en de invloed van media geletterdheid hierop bestudeerd. Om de centrale onderzoeksvraag te beantwoorden worden vier onderzoeksvragen voorgesteld. Bij de eerste twee onderzoeksvragen worden de perceptie (RQ1) en de appropriatie (RQ2) van aanbevelingsalgoritmes op YouTube bestudeerd. De laatste twee onderzoeksvragen behandelen de invloed van media geletterdheid op de kennis over algoritmes op YouTube (RQ3) en het YouTube-gebruik (RQ4).
Tabel 1: Overzicht van de onderzoeksmethodologie
Deel Methode Doel Onderzoeksvraag
Deel 1 Online survey Verkennend (RQ1, RQ2,) RQ3, RQ4
Deel 2 Online diepte-interviews Verdiepend RQ1, RQ2
Er werd een multimethodisch onderzoeksdesign uitgevoerd dat opgedeeld was in twee delen. In het eerste deel werd een verkennende online survey uitgestuurd om het YouTube-gebruik en de kennis van de participanten over algoritmes op YouTube na te gaan. Deze gegevens werden gebruikt om de twee laatste kwantitatieve onderzoeksvragen (RQ3, RQ4) te beantwoorden. Hiervoor werden de participanten opgedeeld in drie groepen naargelang hun geletterdheid niveau (zie sectie 3.1.4). Daarnaast werden ze als inleidend materiaal gebruikt voor de twee eerste kwalitatieve onderzoeksvragen (RQ1, RQ2). In het tweede deel werden online diepte-interviews uitgevoerd om de eerste twee onderzoeksvragen (RQ1, RQ2) te bestuderen. De beschrijvende resultaten van de survey werden daarbij enerzijds gebruikt om participanten te rekruteren en anderzijds als input om tijdens de interviews op terug te koppelen. De nadruk van dit onderzoek lag op de eerste twee onderzoeksvragen.
In het algemeen vertrekken we in dit onderzoek vanuit een constructivistisch onderzoeksparadigma. Dit paradigma stelt dat elke persoon zijn eigen betekenis geeft aan de werkelijkheid (Mortelmans, 2013). De appropriatie, het toe-eigenen van algoritmes is een uniek en persoonlijk proces. De perceptie, de kennis en het begrijpen van algoritmes ook. Daarom worden diepte-interviews gebruikt. Deze onderzoeksmethode laat
24
ons toe om dieper in te gaan op de ervaringen en beleving van bepaalde fenomenen in de persoonlijke leefwereld van de participanten. Daarnaast gebruikten voorgaande studies naar de perceptie (Eslami et al., 2015; Powers, 2017) en domesticatie (Leong, 2020; Siles et al., 2019) van algoritmes ook diepte-interviews. Het gebruik van een survey is geschikt om een eerste en snel beeld te krijgen van het YouTube-gebruik en de kennis over algoritmes (Evans & Mathur, 2005). In de twee laatste onderzoeksvragen wordt er gezocht naar een verschil tussen de geletterdheid groepen. Door middel van statistische toetsen van kwantitatieve gegevens kan dit nagegaan worden.
3.1 Deel 1 – Kwantitatief exploratief onderzoek
3.1.1 Pretest
Begin maart 2020 werd een kleine pretest (n=18) uitgevoerd, bij participanten uit het netwerk van de onderzoeker. De participanten kregen via sociale media (of mail) de uitnodiging om deel te nemen. De onderzoeker vroeg expliciet aan de participanten om onduidelijkheden na het invullen van de survey te melden. Enkele gerapporteerde vragen en antwoorden werden aangepast, opnieuw opgenomen en verwerkt door de volgende participanten. Hierdoor kon de onderzoeker controleren of de ingevoerde aanpassingen duidelijk waren voor de volgende participanten.
3.1.2 Procedure en metingen
De survey bestond uit verschillende onderdelen. Eerst werden twee selectievragen gesteld. Om toegang te krijgen tot de volgende onderdelen, moesten participanten een Belg of Nederlander zijn en een YouTube-account hebben. De vereiste voor een Belgische of Nederlandse nationaliteit kwam er omdat de survey werd verspreid in het Nederlands. Het hebben van een YouTube-account was noodzakelijk doordat de aanbevelingen van gebruikers gelinkt zijn aan hun account. Niet-ingelogde gebruikers krijgen aanbevelingen die gebaseerd zijn op andere criteria (bv. populariteit van video’s in regio) (YouTube, 2020b). Daarnaast zouden de kennisvragen over algoritmes verschillende interpretaties kunnen teweegbrengen tussen participanten met of zonder YouTube-account.
Na enkele selectievragen kregen participanten vragen over hun YouTube-gebruik. Deze vragen waren gebaseerd op het triple articulation kader en de objectificatie en incorporatie dimensies van het domesticatieproces, toegepast in de context van algoritmes op YouTube. We vroegen welke aanbevelingen
25
participanten gebruiken op YouTube (inhoud), of en hoe vaak ze YouTube gebruiken op een bepaald toestel (object), of en met wie ze YouTube gebruiken (sociale context) en waar en wanneer ze YouTube gebruiken (ruimtelijke en temporele context). De vragen werden opgesteld op basis van voorgaande studies (Courtois et al., 2012; Courtois et al., 2013). Daarnaast werden het dagelijks gemiddeld gebruik, het aantal abonnementen en of gebruikers een YouTuber zijn, ook bevraagd.
De kennis over algoritmes op YouTube werd bevraagd aan de hand van vier kennisvragen. Deze vragen waren van toepassing op de aanbevelingen die gebruikers op de homepagina of onder of naast een video krijgen. Participanten kregen eerst de vraag of elke video uit hun abonnementen, weergegeven zou worden in hun aanbevelingen. Hierna vroegen we of ze dezelfde aanbevelingen zouden krijgen als anderen, indien ze dezelfde video’s zouden opzoeken en bekijken. Verder kregen participanten de vraag of ze de mogelijkheid hebben om de inhoud van hun aanbevelingen te wijzigen en of ze manieren kenden om deze inhoud te wijzigen. Deze kennisvragen werden opgesteld op basis van voorgaande studies, die de kennis bestudeerden door participanten zo minimaal mogelijk te primen over de rol van algoritmes (Eslami et al., 2015; Powers, 2017; Rader & Gray, 2015). Daarnaast werden deze vragen bewust gesteld voorafgaand aan het media geletterdheid gedeelte omdat dat gedeelte mogelijke antwoorden bevat op de huidige kennisvragen. Om de technische en cognitieve competenties van YouTube te meten, werd de (sociale) media geletterdheid toolkit van Vanwynsberghe en Haspeslagh (2014) gebruikt als richtlijn. De technische competenties daarbij werden gemeten op basis van een frequentie en bekendheid schaal. Onderzoekers gebruiken doorgaans indirecte manieren zoals de gebruiksfrequentie om de technische competenties te meten (Vanwynsberghe & Haspeslagh, 2014).
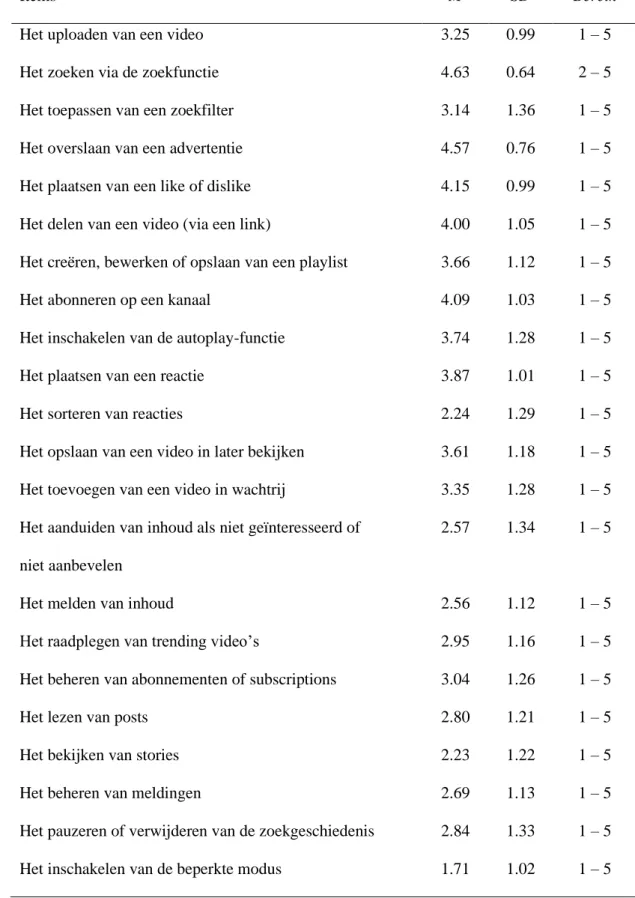
Op basis van deze inzichten werd een nieuwe schaal ontwikkeld die de frequentie van acht YouTube-gerelateerde activiteiten meet (TC1, Tabel 9). De items van de schaal variëren van (1) “Zelden of nooit” tot (5) “Meermaals per dag” en werden gebaseerd op het onderzoek van Khan (2017). Hierdoor meet deze schaal ook de mate van participatie op YouTube. De items van de frequentie schaal hingen goed samen met elkaar (Cronbach’s α = .70).
Technische competenties kunnen ook gemeten worden door de bekendheid met terminologie te bevragen (Vanwynsberghe & Haspeslagh, 2014). Hargittai (2005) vond dat de bekendheid met begrippen
26
een sterkere voorspeller was dan metingen van de frequentie van gebruik. Op basis hiervan werd een tweede schaal ontworpen die de bekendheid van 22 YouTube-gerelateerde activiteiten meet (TC2, Tabel 10). De items van de schaal variëren van (1) “Ik heb er nog nooit van gehoord” tot (5) “Ik ken het heel goed”. Om de items van de schaal voldoende begrijpbaar te maken, werden de begrippen vermeld als een activiteit (bv. het uploaden van een video). De items van de bekendheid schaal hingen sterk samen met elkaar (Cronbach’s α = .93).
De cognitieve competenties werden gemeten op basis van een attitude schaal. In een studie van Hargittai, Fullerton, Menchen-Trevino, en Thomas (2010) werd het vertrouwen bevraagd bij het bezoeken van een website. Deze meting is echter niet relevant doordat er geen rekening wordt gehouden met het kritisch omgaan met inhoud bij de participatie op sociale media. Daarnaast lag de focus van de meting niet op het vertrouwen in andere gebruikers, wat belangrijk is op sociale media (Vanwynsberghe & Haspeslagh, 2014). Hierdoor werd beslist om cognitieve competenties (CC) te meten via de attitude. De attitude is afhankelijk van het kennisniveau van participanten over het sociale media platform en zijn gebruikers (McKnight & Chervany, 2006). Op basis van deze inzichten werd een 7-punt semantisch differentiaal attitude schaal ontwikkeld. De items werden overgenomen uit de studie van Yang en Yoo (2004), waarbij de attitude tegenover technologie werd gemeten op basis van drie affectieve items (Geërgerd - Blij, Negatief - Positief, Slecht - Goed) en drie cognitieve items (Dwaas - Wijs, Schadelijk - Gunstig, Waardeloos - Waardevol). De items van de attitude schaal hingen sterk samen met elkaar (Cronbach’s α = .90).
In het laatste onderdeel van de survey werden demografische kenmerken gemeten (geslacht, geboortejaar, hoofdstatuut en hoogst behaalde diploma). Participanten kregen de vrijblijvende optie om deel te nemen aan het vervolgonderzoek.
3.1.3 Rekrutering en participanten
Halverwege maart 2020 werd de survey gedurende een maand beschikbaar gesteld via Qualtrics. De participanten werden gerekruteerd via een gelegenheidssteekproef. Op verschillende sociale media kanalen van de onderzoeker (Facebook, Twitter, LinkedIn) werd een publiek bericht geplaatst. Na het krijgen van een lage respons, werden participanten persoonlijk gecontacteerd op Facebook. Deze rekruteringsstrategie bleek meer succesvol te zijn.
27
De survey werd in de helft van april 2020 afgesloten. In totaal werden 555 antwoorden geregistreerd op Qualtrics. Participanten die geen Belg waren, geen YouTube-account hadden en de vragen niet volledig invulden werden niet opgenomen in de finale steekproef van 338 participanten. Geen participanten werden gevonden die de survey invulden in minder dan 3 minuten. De gemiddelde duurtijd van de survey zonder uitschieters (n=15) bedroeg 9 minuten. Verder omvat de steekproef meer vrouwelijke participanten (54%) dan mannelijke participanten (46%). De gemiddelde leeftijd van de participanten bedraagt 25 jaar (SD = 6.5), met een minimum leeftijd van 15 jaar en een maximum leeftijd van 87 jaar. De steekproef bestaat grotendeels uit enerzijds werkenden (52%) en anderzijds studenten (45%). Over het algemeen zijn de participanten hoogopgeleid. Het merendeel van de participanten beschikt over een bachelor diploma (39%), gevolgd door een master diploma (32%), een diploma van secundair onderwijs (26%), en andere (3%). Een groot aantal participanten (24%) vulden hun contactgegevens in om deel te nemen aan het vervolgonderzoek. Deze variabelen worden weergegeven in Tabel 8.
3.1.4 Data-analyse
Het analyseproces bestond uit drie delen. In het eerste deel werd een exploratieve data-analyse uitgevoerd om de variabelen te verkennen. Beschrijvende analyses werden uitgevoerd en gekoppeld aan de resultaten van de eerste twee onderzoeksvragen (RQ1, RQ2). Daarna werd een correlatiematrix opgevraagd om de samenhang te analyseren tussen de ordinale en metrische variabelen van de survey. Zo kon de onderzoeker een eerste zicht krijgen op de samenhang tussen variabelen van geletterdheid en gebruik. De Pearson correlatietest werd gebruikt om de samenhang te berekenen tussen metrische variabelen. Wanneer één variabele ordinaal van type was, werd de Spearman correlatietest gebruikt.
In het tweede deel werden participanten in groepen opgedeeld op basis van hun media geletterdheid. Na de exploratieve analyses, werd beslist om de participanten in te delen in groepen naargelang hun bekendheid met activiteiten op YouTube (TC2). Deze variabele hing het sterkst samen met de kennis over algoritmes. De variabele werd eerst omgezet naar haar corresponderende gestandaardiseerde waarde. Daarna experimenteerde de onderzoeker met gestandaardiseerde waarden om een goede indeling te krijgen voor de verschillende groepen. De variabele werd finaal opgedeeld in een laag niveau (z-score < -0.6), middelmatig niveau (z-score > -0.6 en z-score < 0.6) en hoog niveau van media geletterdheid (z-score > 0. 6). Deze
28
indeling werd gebruikt om twee redenen. Ten eerste vertoonde de nieuwe variabele (media geletterdheid niveau) een gelijkaardige samenhang tussen de kennis over algoritmes in vergelijking tot de originele variabele (TC2). Ten tweede weerspiegelde de nieuwe variabele een realistische weergave van de originele data. De nieuwe variabele hing namelijk zeer sterk samen met de originele variabele.
In het derde deel werden de laatste twee onderzoeksvragen beantwoord (RQ3, RQ4). Verschillen tussen ordinale en metrische variabelen werden gecontroleerd door middel van een One-Way-Anova test. Als er geen gelijke spreiding werd vastgesteld, dan werd een Kruskal-Wallis test uitgevoerd. Een Chi-Square test werd gebruikt om verschillen tussen ordinale en nominale variabelen na te gaan.
3.2 Deel 2 – Kwalitatief verdiepend onderzoek
3.2.1 Procedure
Van begin mei tot begin juli 2020 werden online diepte-interviews afgenomen. De procedure van deze methodologie bestond uit twee fasen. Eerst werd de participant via de opgegeven contactgegevens van de survey uitgenodigd voor een inleidend gesprek. Het doel van dit gesprek was vierledig. De onderzoeker kon allereerst kennismaken met de participant. Daarnaast ontving de participant informatie over de soort vragen. De onderzoeker vroeg aansluitend om na te denken over het YouTube-gebruik van de participant. Verder werd het document van de geïnformeerde toestemming overlopen en werd onderling een moment gekozen om het interview in te plannen.
In de tweede fase werd het interview afgenomen. Hiervoor werd Zoom gebruikt. Beide softwarepakketten maken het mogelijk om zowel geluid als beeld op te nemen en schermen te delen tijdens videogesprekken. De participant kreeg via een link de uitnodiging naar de software. De duurtijd van de interviews varieerde tussen 55 minuten en een uur en 27 minuten. De opnames, transcripties en andere documenten van de interviews werden gelinkt aan elkaar via de datum van het afgenomen interview. Op deze manier kon de anonimiteit en privacy van de participanten gerespecteerd worden.
3.2.2 Vragenlijst
De vragenlijst van de semigestructureerde interviews bestaat uit vragen rond de domesticatie van algoritmes en uit vragen over de geletterdheid van algoritmes op YouTube. Voorgaande studies werden
29
geraadpleegd om vragen te ontwikkelen voor zowel het geletterdheid als domesticatie gedeelte. De resultaten van de survey werden gebruikt als input om terug te koppelen op de antwoorden van de participanten.
In het eerste gedeelte lag de nadruk op domesticatie en het triple articulation kader. We vroegen eerst waarvoor participanten YouTube gebruiken. Hierna vroegen we welke en hoe aanbevelingen gebruikt worden naargelang de inhoud. Het scherm van de participant werd gedeeld, zodat de onderzoeker vragen kon stellen tijdens de demonstratie van het gebruik. Daarna werd een overzicht van de verschillende dimensies (inhoud, object en context) van het YouTube-gebruik van de participant gedeeld. De participant kreeg de mogelijkheid om het eerder gedemonstreerde gebruik te koppelen aan de verschillende dimensies. Ondertussen kon de onderzoeker vragen stellen om de context van het gebruik van de aanbevelingen te begrijpen.
In het tweede gedeelte werd gefocust op de geletterdheid. We stelden vragen die peilden naar de attitude tegenover aanbevelingen op YouTube. De onderzoeker vroeg of participanten ooit gezocht hebben naar manieren om hun aanbevelingen te wijzigen, of ze manieren kennen en welke manieren ze bewust of onbewust gebruiken om hun aanbevolen inhoud te wijzigen op YouTube. Na de terugkoppeling op de kennisvragen, bevroegen we de algorithmic imaginary, mentale modellen van participanten over hoe algoritmes werken, en welke factoren volgens de participanten bijvoorbeeld een invloed hebben op hun aanbevelingen. Het geletterdheid gedeelte omvatte ook een proces van bewustmaking. Twee video's werden ontwikkeld door de onderzoeker1 om enerzijds participanten bewust te maken over 1) aangereikte strategieën
van YouTube om aanbevelingen te wijzigen en 2) de rol van algoritmes in het dagelijks leven. Door videomateriaal te gebruiken tijdens de interviews, kon de onderzoeker de kennis en attitude van de participanten verder bestuderen.
De vragenlijst werd regelmatig aangepast om diepgang te krijgen in de data. Na enkele interviews vonden we bijvoorbeeld dat vragen naar de commodificatie en conversie van YouTube in de context van algoritmes weinig interessante antwoorden opleverden2. Deze vragen werden niet opgenomen in de volgende
30
3.2.3 Rekrutering en participanten
De participanten werden gerekruteerd via de survey. Participanten die akkoord gingen om deel te nemen aan het vervolgonderzoek en hun contactgegevens invulden, kwamen in aanmerking voor de rekrutering. De controlevragen van de survey, de nationaliteit van Belg bezitten en een YouTube-account hebben, werden automatisch opgenomen als criteria voor deze rekrutering.
Om de rol van de perceptie (RQ1) en appropriatie (RQ2) van aanbevelingsalgoritmes te begrijpen, werd gekozen voor een doelgerichte steekproef. Participanten worden daarbij geselecteerd op basis van specifieke kenmerken. Deze kenmerken waren afhankelijk van de resultaten van de verkennende survey. De volgende variabelen werden in rekening genomen bij de selectie van de participanten: het gebruik van verschillende type aanbevelingen, de gebruikte toestellen, het gebruik met anderen en de geletterdheid van YouTube en de algoritmes.
In totaal werden 10 diepte-interviews afgenomen. De steekproef bestaat uit 6 vrouwelijke en 4 mannelijke participanten. De gemiddelde leeftijd van de participanten bedraagt 24 jaar. De specifieke kenmerken omtrent het gebruik en de geletterdheid van participanten worden weergegeven in Tabel 13.
3.2.4 Data-analyse
Na controle op data saturatie, werden de interviews getranscribeerd. De onderzoeker controleerde vervolgens de transcripties door de opnames opnieuw te beluisteren. Hierna werden de interviews gecodeerd via Nvivo, in verschillende fasen. Eerst werden open codes gecodeerd waarbij zo dicht mogelijk bij de data gebleven werd. Daarna werden deze codes gegroepeerd en geplaatst binnen ruimere thema's. Bij elke dataverwerking werd het proces opnieuw doorlopen en werden de ruimere thema's aangepast in functie van de onderzoeksvraag. In dit proces ging de onderzoeker hoofdzakelijk inductief te werk. Afgezien van het appropriatie gedeelte, waarbij de concepten van objectificatie en incorporatie als initiële thema’s werden opgesteld. Hierna werd er gezocht naar processen van objectificatie en incorporatie in de context van aanbevelingsalgoritmes op YouTube.
31
4 Resultaten
4.1 Beschrijving van de survey-steekproef
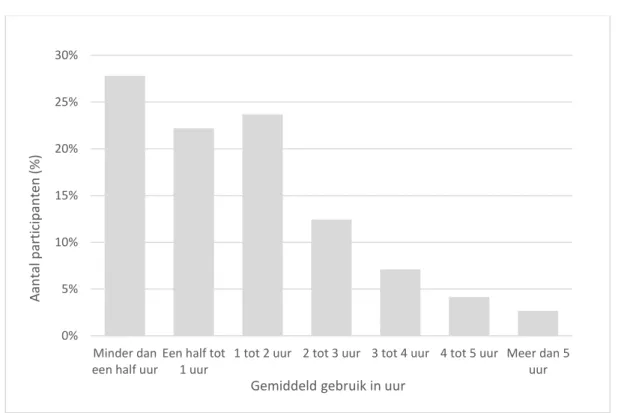
Enkele relevante kenmerken van de survey-steekproef worden beschreven in Tabel 8. De participanten zijn voornamelijk passieve YouTube-gebruikers die dagelijks video's bekijken en maandelijks tot wekelijks reacties lezen op YouTube (Tabel 9). Participanten gebruiken YouTube gemiddeld één tot twee uur per dag. Figuur 1 geeft de verdeling weer van het gemiddeld YouTube-gebruik per dag. Zowel de frequentie van activiteiten op YouTube als het gemiddeld YouTube-gebruik per dag vertonen een rechts-scheve verdeling. Een klein aandeel van de participanten omschrijft zichzelf als YouTuber en uploadt minstens maandelijks video’s op zijn kanaal (2.7%). Gemiddeld hebben de participanten 54 abonnementen (SD=137), met een minimum van 0 en een maximum van 2000 abonnementen.
Figuur 1: Gemiddeld YouTube-gebruik per dag
0% 5% 10% 15% 20% 25% 30% Minder dan een half uur
Een half tot 1 uur
1 tot 2 uur 2 tot 3 uur 3 tot 4 uur 4 tot 5 uur Meer dan 5 uur Aan ta l p ar ticip an ten (% )
32
In lijn met de omschrijving van eerder passieve YouTube-gebruikers, bleken de participanten vertrouwd met activiteiten zoals het gebruik van de zoekfunctie, het overslaan van advertenties, het plaatsen van (dis)likes, het abonneren op een kanaal en het delen van video's (via een link). In het algemeen vertoonden de participanten ook een positieve attitude tegenover YouTube.
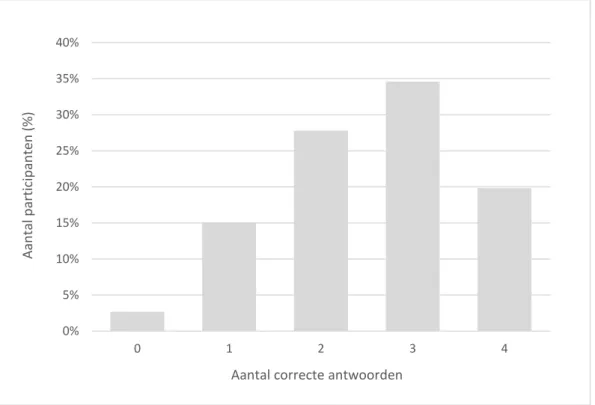
De participanten hebben een hoog kennisniveau over algoritmes op YouTube. Ze beantwoordden gemiddeld twee en een half vragen op de vier kennisvragen correct (M=2.54, SD=1.05). In Figuur 2 wordt de verdeling van het aantal correcte antwoorden op de kennisvragen over algoritmes op YouTube weergegeven. Het kennisniveau van de participanten vertoont een matige links-scheve verdeling. De hoge score op het gemiddelde kan mogelijk te wijten zijn aan enerzijds de rekrutering en anderzijds de exploratieve aard van de vragen in de survey.
Figuur 2: Aantal correcte kennisvragen over algoritmes op YouTube
0% 5% 10% 15% 20% 25% 30% 35% 40% 0 1 2 3 4 Aan ta l p ar ticip an ten (% )
33
4.2 Exploratieve analyse van de survey-data
Om een eerste beeld te krijgen van de (mogelijke) samenhang tussen de variabelen uit de survey, werd een correlatiematrix opgevraagd. De resultaten hiervan worden weergegeven in de bijlage (Tabel 11). De meest relevante correlaties in functie tot de onderzoeksvragen van deze paper worden hieronder besproken.
4.2.1 Samenhang tussen variabelen van YouTube-gebruik
Eerst controleerden we de samenhang tussen variabelen over het gebruik van YouTube. Er is een matige positieve samenhang tussen het gemiddeld YouTube-gebruik en respectievelijk het gemiddeld gebruik van de computer of laptop (r = 0.41**) en de smartphone (r = 0.29**). Met het gebruik van de tablet en de televisie werd geen samenhang gevonden. Tussen de toestellen onderling is er een zwakke positieve samenhang tussen het smartphone-gebruik van participanten en enerzijds hun televisie-gebruik (r = 0.24**) en anderzijds hun computer- of laptop-gebruik (r = 0.15**).
Het aantal toestellen dat participanten gebruiken, werd positief en duidelijk geassocieerd met het gemiddeld gebruik van televisie (r = 0.57**), gevolgd door het tablet-gebruik (r = 0.54**) en het smartphone-gebruik (r = 0.39**). Het aantal toestellen hing eerder zwak samen met het computer- of laptop-smartphone-gebruik (r = 0.25**). Verder is er een duidelijke positieve samenhang tussen het aantal momenten doorheen de dag waarop participanten YouTube gebruiken en hun gemiddeld YouTube-gebruik (r=0.42**). Daarnaast werd het aantal momenten positief en matig geassocieerd met het aantal locaties waar participanten YouTube gebruiken (r = 0.34**) en bleek het aantal gebruikte locaties het sterkst samen te hangen met het aantal personen waarmee participanten YouTube gebruiken (r = 0.20**). Bovendien werd er een zwakke positieve associatie vastgesteld tussen het aantal abonnementen van de participanten en hun gemiddeld YouTube-gebruik (r = 0.18**) en computer- of laptop-YouTube-gebruik (r = 0.18**).
4.2.2 Samenhang tussen YouTube-gebruik en geletterdheid variabelen
Hierna werd de samenhang tussen het gebruik van YouTube en de verschillende geletterdheid variabelen geanalyseerd. Een positieve samenhang werd vastgesteld tussen de technische en cognitieve competenties en het YouTube-gebruik. Die samenhang is het sterkst aanwezig bij de frequentie van activiteiten, gevolgd door de bekendheid met activiteiten, en de attitude tegenover YouTube. Er is een
34
duidelijke positieve samenhang tussen de frequentie van activiteiten op YouTube en het gemiddeld YouTube-gebruik (r=0.53**), het gebruik per smartphone (r=0.37**) en het gebruik per laptop of computer (r=0.43**). Verder is er een matige tot duidelijke positieve samenhang tussen de bekendheid met activiteiten op YouTube en het gemiddeld YouTube-gebruik (r=0.39**), het gebruik per smartphone (r=0.31**) en het gebruik per laptop of computer (r=0.27**). Vervolgens bleek er een zwakke positieve samenhang tussen de attitude tegenover YouTube en het gemiddeld YouTube-gebruik (r=0.26**), het gebruik per smartphone (r=0.20**) en het gebruik per laptop of computer (r=0.15**). Overigens vonden we een matige positieve samenhang tussen de frequentie van activiteiten op YouTube en het aantal gebruikte aanbevelingen (r=0.37**) en het aantal momenten (r=0.35**) waarop YouTube doorheen de dag wordt gebruikt. Aansluitend hierop vonden we een matige positieve samenhang tussen de bekendheid met activiteiten op YouTube en het aantal gebruikte aanbevelingen (r=0.36**)
4.2.3 Samenhang tussen kennis over algoritmes en andere variabelen
Vervolgens werd de samenhang tussen de kennis over algoritmes en andere variabelen gecontroleerd. Er werd een positieve zwakke samenhang gevonden tussen de technische competenties van de participanten en hun niveau van kennis over algoritmes. Deze samenhang is sterker met de bekendheid met activiteiten (r = 0.29**), dan met de frequentie van activiteiten (r= 0.23**) op YouTube. In tegenstelling tot de technische competenties, werd er geen verband gevonden tussen de cognitieve competenties van participanten en hun kennis over algoritmes (r= 0.01) op YouTube. Verder vonden we ook een zwakke positieve samenhang tussen het niveau van kennis over algoritmes en het gemiddeld YouTube-gebruik (r = 0.19**), het opleidingsniveau (r= 0.18**), het smartphone gebruik (r= 0.17**) en het aantal gebruikte aanbevelingen (r = 0.17**).
4.2.4 Samenhang tussen de verschillende competenties van media geletterdheid
Aansluitend gingen we na in welke mate de verschillende competenties van media geletterdheid samenhangen met elkaar. Er is een duidelijke positieve samenhang tussen de technische competenties onderling (r= 0.48**). Tussen de cognitieve competenties en de technische competenties werd een zwakke positieve samenhang vastgesteld. Die samenhang is sterker aanwezig tussen de attitude tegenover YouTube
35
en de bekendheid met activiteiten (r= 0.28**), in contrast tot de frequentie van activiteiten (r= 0.23**) op YouTube.
4.2.5 Rol van leeftijd en opleidingsniveau
Ten slotte controleerden we ook de rol van de leeftijd en het opleidingsniveau in de correlatiematrix. We stelden een lage negatieve samenhang vast tussen het opleidingsniveau en het gemiddeld YouTube-gebruik (r = -0.18**). Daarnaast vonden we een duidelijke positieve samenhang tussen de leeftijd en het opleidingsniveau (r = 0.47**).
4.2.6 Belangrijkste bevindingen
In deze exploratieve fase ontdekten we een eerste trend waarbij het gebruik en de context van het gebruik een rol speelt in de geletterdheid van participanten, en omgekeerd. Het gaat over een positieve samenhang waarbij de sterkte varieert van zwakke tot matige en duidelijke verbanden. Daarnaast vonden we dat de technische competenties het sterkst samenhingen met enerzijds de kennis over algoritmes en anderzijds het gebruik en de context van het gebruik. Deze inzichten werden gebruikt om de participanten later in te delen in geletterdheid groepen. De resultaten geven echter geen concrete oorzaak-gevolg verbanden aan. We kunnen dus niet concluderen dat variabelen van geletterdheid of eerder het gebruik voorspellende variabelen zouden zijn.
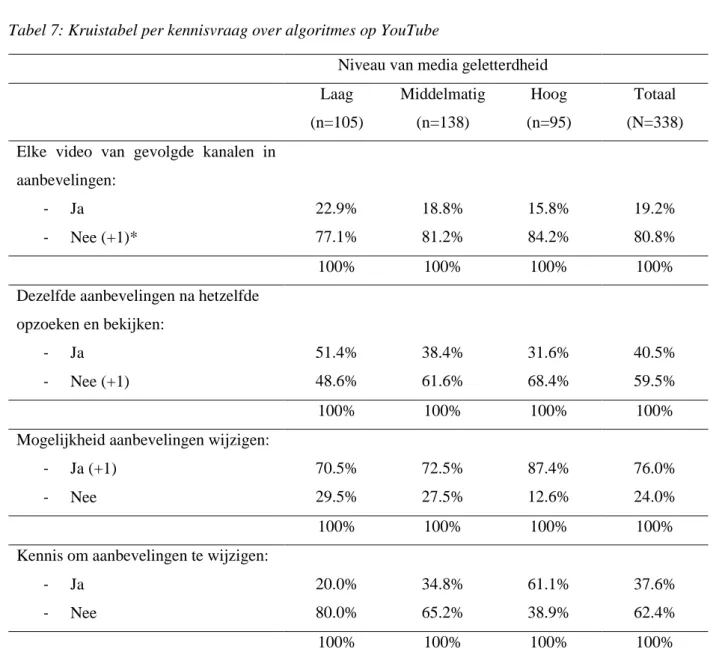
4.3 De media geletterdheid groepen
Om de rol van media geletterdheid te onderzoeken, werden de participanten opgedeeld in drie niveaus van media geletterdheid (laag, middelmatig en hoog) naargelang hun technische competenties, de bekendheid met activiteiten, op YouTube (zie sectie 3.1.4).
De geletterdheid groepen verschillen significant op vlak van hun bekendheid met activiteiten op YouTube (F(2, 335) = 789.361, p < 0.001), en verschillen onderling ook significant van elkaar (p’s < 0.001). De hoog geletterde participanten (M=4.14) zijn over het algemeen goed bekend met de verscheidenheid van activiteiten op YouTube. In contrast, zijn de laag geletterde participanten (M=2.43) eerder weinig tot matig bekend met de diversiteit van activiteiten op YouTube. Daarnaast sluit de bekendheid tegenover activiteiten op YouTube van de middelmatige geletterde participanten (M=3.28) aan bij die van de gemiddelde steekproef. Bovendien werd er een significant verband gevonden tussen de geletterdheid groepen en de