“DEMANDEZ-LE À SIRI”
LA VARIATION RÉGIONALE LINGUISTIQUE INFLUE-T-ELLE SUR LE
FONCTIONNEMENT DE LA VERSION FLAMANDE DE SIRI?
Aantal woorden: 16997
Tine Dhaene
Studentennummer: 01601818
Promotor(en): Dr. Orphée De Clercq
Masterproef voorgelegd voor het behalen van de graad master in de Meertalige Communicatie
© 2018 Tine Dhaene, Universiteit Gent
De auteur en de promotor(en) geven de toelating deze studie als geheel voor consultatie
beschikbaar te stellen voor persoonlijk gebruik. Elk ander gebruik valt onder de beperkingen van het auteursrecht, in het bijzonder met betrekking tot de verplichting de bron uitdrukkelijk te vermelden bij het aanhalen van gegevens uit deze studie.
I
ABSTRAIT
Ces dernières années, les gens se servent de plus en plus d’assistants vocaux. En même temps, l'intérêt des Flamands pour les dialectes augmente. Ce mémoire examine l'influence de la variation linguistique régionale sur la reconnaissance automatique de la parole de Siri, l’assistant vocal d’Apple. Afin d'examiner cela, nous avons composé un corpus de 37 enregistrements vocaux. Ils peuvent être subdivisés en fonction de l'origine des locuteurs, à savoir quatre villes (Courtrai, Gand, Puurs et Genk) : une par région dialectale flamande néerlandophone. Ils peuvent également être subdivisés en fonction de la variante parlée du néerlandais (le néerlandais standard parfait, l’effort de parler le néerlandais standard et la variante régionale du néerlandais standard). En faisant écouter ces enregistrements à Siri, nous avons vérifié la qualité du système de reconnaissance automatique de la parole. Les résultats des recherches indiquent que Siri comprend mieux le néerlandais standard parlé de manière parfaite. Des résultats, il ressort aussi qu'à mesure que le langage s'écarte du néerlandais standard, la compréhension de Siri baisse. En outre, nous constatons également que Siri comprend le mieux les dialectes brabançons et le moins bien les dialectes flamands orientaux.
III
REMERCIEMENTS
Tout d’abord, j’aimerais remercier quelques personnes qui m’ont aidée et encouragée à rédiger mon mémoire de fin d’études.
En premier lieu, je tiens à remercier sincèrement ma directrice de thèse dr. Orphée De Clercq pour me prendre sous son aile avec mon sujet librement choisi. Je voudrais également la remercier parce qu’elle m’a toujours aidée à réfléchir à des solutions aux problèmes liés à la crise de Corona et parce qu’elle a continué à me motiver malgré les nombreuses incertitudes pendant le semestre passé. J’aimerais en outre la remercier pour les séances de brainstorming fructueuses, pour ses réponses toujours rapides, pour ses corrections judicieuses et pertinentes, pour ses conseils précieux et pour son temps et sa patience pendant la réalisation de ce mémoire.
Je voudrais également remercier dr. Kathelijne Denturck pour ses conseils et corrections au sujet de la langue française.
En outre, j’aimerais exprimer toute ma gratitude à mes parents, et particulièrement à ma mère, Marie-Ange, pour ses conseils et explications en ce qui concerne le français tout au long de mes études. A part elle, je voudrais également remercier mon père, Lieven, mon frère, Pieter, et ma sœur, Annelies, pour leur patience et soutien infinis tout au long de mes études.
Comme un bon travail est le fruit d'un bon équilibre entre l'effort et la détente, j'aimerais aussi présenter mes remerciements à mes amis d'étude car ils ont contribué à créer une ambiance détendue pendant les quatre années universitaires.
En dernier lieu, je tiens à remercier toutes les personnes ayant fait des enregistrements et aussi celles qui m’ont aidée à trouver des participants appropriés. Sans elles, je n’aurais jamais pu mener ce mémoire à bonne fin.
V
PRÉAMBULE
Le but de ce mémoire était d'examiner si la variation linguistique régionale a une influence sur le fonctionnement de Siri. Pour cela, notre but était d’élaborer un questionnaire avec des caractéristiques sonores qui s'écartent du néerlandais standard dans différentes régions dialectales flamandes. Ce questionnaire serait lu à deux reprises par neuf participants ayant au moins cinquante ans et originaires de quatre villes flamandes : une fois en néerlandais standard et une fois dans la variante régionale du participant, sans remplacer certains mots par des variantes dialectales. Au total, nous aurions donc collectionné 72 enregistrements vocaux. Nous collectionnerions également cinq enregistrements vocaux de participants parlant de manière parfaite le néerlandais standard. Ensuite, nous ferions écouter ces enregistrements à Siri afin d’en mesurer le taux de reconnaissance.
La collecte des données était prévue pendant et après les vacances de Pâques. En raison de la crise de Corona, il n'était plus possible de l’exécuter, car il était interdit de rendre visite aux participants pour effectuer les enregistrements. Ainsi, au début de la crise de Corona, nous avions seulement des enregistrements de la région de Puurs et beaucoup d'incertitudes en ce qui concerne la suite de la réalisation du mémoire.
Pendant les vacances de Pâques, ma directrice de thèse, Madame De Clercq, et moi avons réfléchi à une méthode alternative pour collectionner les données. Nous avons d'abord testé s'il était possible de faire les enregistrements vocaux via Skype, ce qui n'a malheureusement pas fonctionné. Finalement, nous avons trouvé une méthode possible : nous avons élaboré une procédure et un plan par étapes (répertoriés dans les annexes II et III) donnant des explications aux participants de sorte qu'ils puissent faire les enregistrements nécessaires eux-mêmes et les nous envoyer par mail. Cela a causé de la variation en la qualité des enregistrements. De plus, cette méthode de collecte de données a ajouté un critère supplémentaire pour les participants, à savoir les compétences informatiques. Ce critère ne s'avère pas évident pour les personnes ayant un certain âge. Cette situation a entravé la recherche de participants appropriés. C'est pourquoi Madame De Clercq et moi avons décidé de réduire le nombre de participants par région dialectale à cinq. Le critère supplémentaire (les compétences informatiques) a joué des tours dans la recherche de participants, en particulier à Genk. Nous avons par exemple été en contact avec l'association dialectale de Genk, dont les membres étaient très gentils et prêts à nous aider, mais n'avaient malheureusement pas assez de compétences informatiques. Finalement, nous n’avons trouvé qu’un seul participant à Genk après une longue et laborieuse recherche de participants pendant la crise de Corona.
Ce préambule a été rédigé en concertation entre l'étudiant et la directrice de thèse et a été approuvé par les deux.
VII
TABLE DES MATIÈRES
Chapitre 1: Introduction ... 1
Chapitre 2 : Revue de la littérature ... 3
2.1 La variation linguistique en Flandre ... 3
2.1.1 L’origine du néerlandais standard ... 4
2.1.2 Les régions dialectales flamandes... 4
2.1.3 La variation linguistique dans les médias ... 6
2.1.4 Un aperçu des caractéristiques différentes dans les différentes régions ... 7
2.2 Les assistants vocaux ... 15
2.2.1 Qu’est-ce que les assistants vocaux ... 15
2.2.2 L’application des assistants vocaux dans la société contemporaine ... 15
2.2.3 Le fonctionnement des assistants vocaux ... 16
2.3 Les questions de recherche ... 27
Chapitre 3 : Méthodologie ... 29
3.1 Les données ... 29
3.1.1 Le questionnaire ... 30
3.1.2 Les participants ... 37
3.2 Le traitement des données ... 39
3.2.1 La vérification de la reconnaissance automatique de la parole de Siri ... 39
3.2.2 L’évaluation de la reconnaissance automatique de Siri ... 40
Chapitre 4: Résultats ... 43
4.1 L’analyse du corpus ... 43
4.1.1 L’analyse quantitative du corpus ... 46
4.1.2 L’analyse qualitative du corpus ... 51
4.2 La réflexion sur les questions de recherche à l’aide des taux ... 57
IX
LISTE DES FIGURES
Figure 1 : Les grandes régions dialectales en Flandre (Taeldeman, 2005, p.9) ... 4
Figure 2 : Les villes examinées dans ce mémoire ... 6
Figure 3 : La ligne noire montre les frontières de la région dans laquelle les Limbourgeois utilisent une langue à ton (Belemans et Keulen, 2004, p. 30) ... 13
Figure 4 : Le processus en cinq phases que l’assistant vocal parcourt avant de donner une réponse... 16
Figure 5 : Un exemple des valeurs importantes à remplir pour une réservation de vol ... 18
Figure 6 : le prétraitement en six phases ... 22
Figure 7 : Le processus de la reconnaissance automatique de la parole en six phases ... 23
Figure 8 : Le réglage de Siri ... 39
Figure 9 : L'output de Siri pour la question « Gaat het morgen regenen in Brugge? » ... 40
Figure 10 : La répartition des variantes du néerlandais standard ... 45
Figure 11 : Les taux d'erreur des mots pour les variantes régionales et pour l’effort de parler le néerlandais standard ... 46
Figure 12 : Les taux de réussite des commandes pour les variantes régionales et l'effort de parler le néerlandais standard ... 47
Figure 13 : Le taux d'erreur des mots des variantes du néerlandais standard ... 49
XI
LISTE DES TABLEAUX
Tableau 1 : La prononciation longue de la voyelle ‘a’ à Courtrai et à Puurs ... 7
Tableau 2 : La prononciation longue et courte de la voyelle ‘o’ à Gand, à Courtrai et à Puurs ... 8
Tableau 3 : La prononciation longue et courte de la voyelle ‘u’ à Courtrai, à Genk et à Puurs ... 9
Tableau 4 : La prononciation longue et courte de la voyelle ‘i’ à Courtrai et à Puurs ... 9
Tableau 5 : La prononciation du chva à Courtrai et à Puurs ... 10
Tableau 6 : La prononciation des diphtongues ‘ei’ et ‘ij’ à Gand, à Courtrai et à Puurs ... 10
Tableau 7 : La prononciation de la diphtongue ‘ui’ à Gand, à Courtrai, à Puurs et à Genk ... 11
Tableau 8 : La prononciation des consonnes g et h à Courtrai ... 12
Tableau 9 : La prononciation de la consonne ‘h’ à Gand ... 12
Tableau 10 : Un aperçu des caractéristiques audibles dans les questions du questionnaire ... 31
Tableau 11 : Le système d’attribution de valeurs aux questions ... 41
Tableau 12 : La répartition des participants ... 44
Tableau 13 : Le rapport possible entre la longueur d'une question et la compréhension du système ... 51
Tableau 14 : Un aperçu des taux d'erreur des mots en pourcentage par participant, par question pour le néerlandais standard ... 52
1
CHAPITRE 1: INTRODUCTION
Plus de la moitié des adultes américains utilisent un assistant vocal sur leur smartphone (Bera, 2019). Bera explique aussi qu'en 2018, les assistants vocaux étaient intégrés dans plus d'un milliard d'appareils. Il est principalement question des assistants vocaux célèbres comme Siri d'Apple, Google Assistant de Google, Alexa d'Amazon et Cortana de Microsoft. D'après Bera et Mens (2018), Siri a été activement utilisé sur plus de 500 millions d'appareils en 2018. Cela fait de
Siri l’assistant vocal le plus populaire et leader du marché.
Delarue et Lybaert (2018) signalent que non seulement l'utilisation de dialectes, mais aussi celle de la langue standard déclinent en Flandre. La variante mi-standardisée du néerlandais parlé en Flandre gagne ainsi en popularité. Cependant, malgré le déclin de l'utilisation des dialectes flamands, nous constatons que ces dernières années, les personnages dans les séries télévisées et les musiciens les utilisent davantage. L'accent brabançon a toujours été bien représenté à la télévision flamande dans des séries comme Thuis ou Familie. Le flamand occidental éprouve un succès grandissant dans les médias flamands avec des séries comme Eigen Kweek et Bevergem ou des musiciens tels que Brihang, Het Zesde Metaal et Ertebrekers. La série de la plus grande chaîne commerciale flamande, VTM, Amigos et le groupe de hip-hop Uberdope représentent le dialecte urbain de Gand. L'acteur limbourgeois Matteo Simoni représente sa région avec des rôles dans les séries Callboys et Safety First. Enfin, le rappeur anversois Tourist LeMC fait remarquer le dialecte d'Anvers et donc brabançon.
En Amérique, Fossat, Lee, Li, Palanica et Thommandram (2019) ont déjà démontré que les assistants vocaux éprouvent peu de difficultés à comprendre les dialectes. Dans leur étude, la compréhension moyenne des personnes sans accent se chiffre à 57%. Celle des personnes ayant un accent atteint 48,8%. La compréhension générale n’est donc pas si bonne et la variation linguistique n’influe pas si considérablement sur la reconnaissance automatique de la parole. Cependant, les versions flamandes des assistants vocaux n'en sont qu'à leurs débuts. Dans ce mémoire, nous voulons vérifier où ils en sont dans la reconnaissance générale et dans celle de la variation linguistique régionale. Plus concrètement, nous répondrons aux questions suivantes : La variation linguistique régionale influe-t-elle sur le fonctionnement de Siri ? Siri comprend-il mieux certaines variantes régionales du néerlandais que d’autres ? et Siri comprend-il mieux l’effort de parler la langue standard que le langage régional de la même personne ?
2
L’étude présente d’abord une revue de la littérature divisée en deux grandes parties. La première partie tente de donner un aperçu de la variation linguistique en Flandre en décrivant des caractéristiques divergentes de la langue standard du langage local d’une ville sélectionnée par région dialectale flamande. La deuxième partie éclaircit le fonctionnement des assistants vocaux et des technologies y intégrées ainsi que des méthodes à mesurer leur qualité et des éléments compliquant la reconnaissance automatique de la parole. Le troisième chapitre de ce mémoire vous explique la méthodologie de l’étude. Ce chapitre expose les différentes phases parcourues dans l’étude. Pour le corpus, nous avons collectionné 37 enregistrements vocaux, divisés en fonction de l’origine des locuteurs et en fonction de la variante du néerlandais standard qui est parlée. Le quatrième chapitre contient les résultats de l’étude. Nous y analysons le corpus principalement de manière quantitative. A ces résultats quantitatifs, nous ajoutons une analyse qualitative restreinte. Enfin, la conclusion tente de formuler de façon concise les principales constatations de l’étude. La discussion apporte des suggestions et des implications pour la recherche future dans ce domaine.
3
CHAPITRE 2 : REVUE DE LA LITTERATURE
2.1 La variation linguistique en Flandre
Au XVIIe siècle, le néerlandais standard, la variante standard du néerlandais est apparue (van der Sijs1, 2005). Ce néerlandais standard est décrit dans la dernière version du VRT-Taalcharter2 (2012) comme: « Nederlands dat taalbewuste sprekers in het publieke domein gebruiken wanneer zij hun taal verzorgen ». Van der Sijs caractérise le VRT comme le bon exemple et l'objectif à poursuivre en ce qui concerne le néerlandais standard en Belgique. L’entreprise est donc une autorité pour le néerlandais standard. Au XVIIe siècle, l'introduction de ce langage normalisé, uniforme dans l'ensemble de la région néerlandophone, avait pour but d'en assurer l'intelligibilité sur l'ensemble du territoire.
Depuis l’introduction du néerlandais standard, il y a donc une opposition entre le dialecte parlé et la langue standard écrite et normalisée. Cependant, cette opposition n'est pas formelle, car d'un point de vue linguistique, il n'y a pas de différence entre une langue standard et un dialecte. Les deux sont des systèmes linguistiques complets. La différence réside donc dans les questions extralinguistiques, à savoir l'orthographe, la grammaire et le choix des mots de la langue standard, qui sont uniformes, enregistrés et enseignés à l'école. En outre, la langue standard est élevée au statut de langue d'Etat (en Belgique en combinaison avec l'allemand et le français). Ces caractéristiques ne s'appliquent pas aux dialectes (van der Sijs, 2005).
Bien que la population belge s'intéresse de plus en plus aux dialectes, le langage évolue de plus en plus vers le néerlandais standard. Van der Sijs (2005) explique que c’est parce qu'il y a une différence dans le prestige accordé aux deux variantes car le néerlandais du VRT brille tout en haut de l'échelle et le dialecte se trouve tout en bas. Entre la langue standard et le dialecte se trouve un continuum rempli de versions linguistiques intermédiaires du néerlandais comme la variante mi-standardisée du néerlandais parlée en Flandre.
1 Van der Sijs est la rédactrice en chef de la série ‘Taal in stad en land’ et a écrit la préface, présente dans
tous les livres de la série.
2 Ruud Hendrickx. (11.09.2012). Taalcharter. 7 paragraphes. Consulté le 7.11.2019. par
4
2.1.1
L’origine du néerlandais standard
Selon Marynissen (2018), Anvers était la métropole commerciale de l’ouest entre 1495 et 1520 et influençait par conséquent aussi la culture des Pays-Bas du XVIe siècle. A partir d’environ 1500, les Anversois ont commencé à adapter consciemment la langue néerlandaise afin d’être plus compréhensible et ainsi agrandir leur débouché. Ce sont donc eux, appartenant à la région dialectale du brabançon, qui sont à l’origine d’une langue flamande écrite et uniforme. Ce phénomène s’appelle aussi l’expansion brabançonne. Après la chute de la ville d’Anvers en 1585, ce développement d’une langue standard est paralysé et le français et le latin sont devenus les langues importantes et influentes en Flandre. A la fin du XVIIIe siècle par contre, l’attention pour le néerlandais s’est de nouveau développée. Le Mouvement flamand, actif pendant les XIXe et XXe siècles, s’est efforcé à rendre le néerlandais de nouveau plus puissant en se joignant à la langue des Pays-Bas. Ainsi, le néerlandais pouvait se débattre contre la puissance du français et du latin en Flandre. Ce néerlandais des Pays-Bas a été influencé à travers les années par l’élite brabançonne qui a émigré aux Pays-Bas après la chute d’Anvers. On peut donc constater que les Brabançons sont les seuls Flamands qui se trouvent à la base du néerlandais standard.
2.1.2 Les régions dialectales flamandes
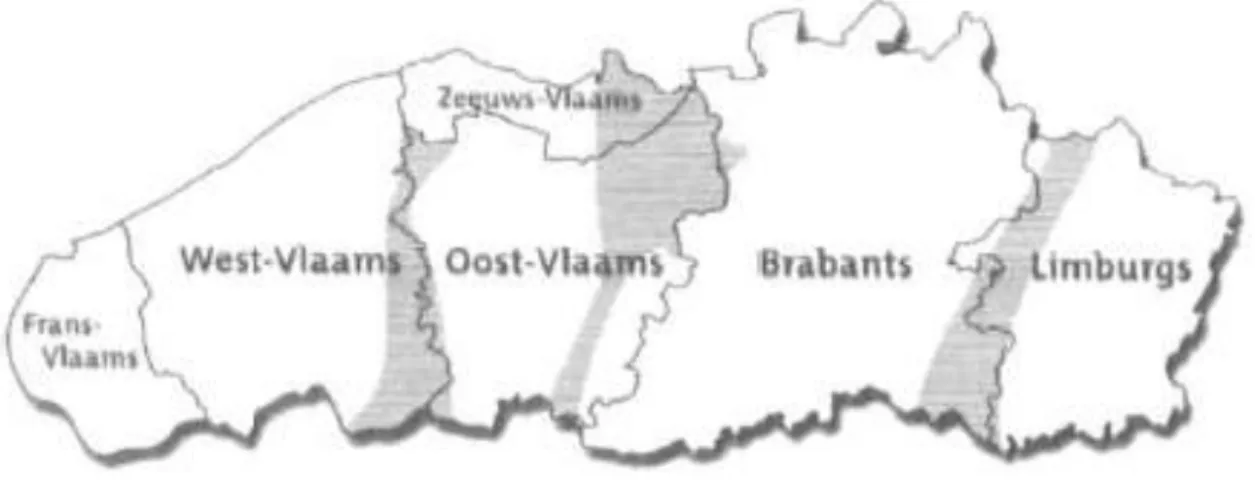
Van der Sijs (2005) divise le paysage linguistique flamand en cinq régions dialectales : le limbourgeois, le flamand oriental, le flamand occidental, le brabançon et le flamand français. La figure une montre que les frontières provinciales ne coïncident pas entièrement avec les zones de transition des différentes régions dialectales. Les habitants des zones de transition utilisent un mélange de différentes caractéristiques dialectales. Ils ne peuvent par conséquent pas être classés dans une seule région dialectale.
5
Ce mémoire se concentre sur quatre villes flamandes et plus spécifiquement une ville située dans les régions dialectales du flamand occidental, du flamand oriental, du brabançon et du limbourgeois. La figure deux montre la situation géographique des quatre villes en Flandre. Cette étude ne tient donc pas compte de la région dans laquelle les habitants parlent le flamand français et de la Flandre Zélandaise.
Pour le flamand occidental, cette étude se concentre sur la ville de Courtrai. Courtrai se situe dans le sud-est de la province de la Flandre-Occidentale, fait partie du ‘flamand occidental continental’ (Devos & Vandekerckhove, 2005, p. 29) et présente par conséquent les caractéristiques de cette région (Devos & Vandekerckhove). La ville possède encore d’autres éléments typiques qui ne sont pas applicables à la province entière.
Pour le flamand oriental, nous avons sélectionné la ville de Gand, la capitale de la province de la Flandre-Orientale qui y est située centralement. La ville de Gand présente un îlot linguistique dont le langage se parle à Gand et ses ‘banlieues attachées’ (Taeldeman, 2005, p. 49) : Ledeberg, Gentbrugge, Sint-Amandsberg, Wondelgem et Mariakerke. Taeldeman le décrit comme un îlot linguistique parce que le dialecte présente des caractéristiques que les villages ruraux de la région n’adoptent (presque) pas.
Puurs, une ville située dans Klein-Brabant et dans le sud-ouest de la province d’Anvers, représente la région du brabançon qui s’étend sur les provinces d’Anvers et du Brabant-Flamand. La région Klein-Brabant présente quelques éléments spécifiques et divergents du brabançon général (Ooms & Van Keymeulen, 2005). C’est pourquoi cette région est intéressante pour cette étude.
Pour la région dialectale du limbourgeois, nous avons sélectionné la ville de Genk, l’épicentre de la « Citétaal » limbourgeoise (Ugent Vakgroep Taalkunde – Nederlands, 2014)3. Koeman, Marzo & Schoofs (2016), Marzo (2018) et l’unité d’enseignement et de recherche déclarent que la «Citétaal» est une langue parlée basée sur le néerlandais et sur de nombreuses influences d'autres langues telles que l'italien, le turc, le marocain et l'arabe. Cette variante du néerlandais prend son origine pendant la vague de migration après la Seconde Guerre mondiale (1946-1960) dans sept sites miniers limbourgeois, dont trois à Genk (Waterschei, Winterslag & Zwartberg). Initialement,
3 UGent Vakgroep Taalkunde – Nederlands. (2014). Citétaal. Consulté le 7 mai 2020 par
https://www.dialectloket.be/tekst/etnolecten/citetaal/
6
la « Citétaal » était donc un ethnolecte, mais à travers les années, elle est passée à un sociolecte, à savoir la langue caractéristique des jeunes genkois. Cette langue présente quelques caractéristiques spécifiques. C’est pourquoi nous avons sélectionné cette ville pour cette étude.
Figure 2 : Les villes examinées dans ce mémoire
2.1.3 La variation linguistique dans les médias
Selon Delarue et Lybaert (2018), les médias servaient autrefois à promouvoir le néerlandais standard au moyen des ABN-acties (actions du néerlandais standard belge). Dans une phase ultérieure, seule la variante mi-standardisée brabançonne du néerlandais parlé en Flandre était présente dans les médias et dans des séries telles que Thuis et Familie. En outre, les médias sous-titrent de nos jours moins les énoncés de locuteurs de cette région que ceux de locuteurs d'autres régions. Toutefois, on observe depuis quelque temps un changement : les variantes mi-standardisées des régions dialectales non brabançonnes sont plus souvent représentées dans les médias flamands. Le flamand occidental, le gantois et le limbourgeois sont désormais également représentés par des personnages dans des séries telles que Eigen Kweek (flamand occidental),
Amigos (flamand oriental) et Callboys (limbourgeois).
Bien que le néerlandais standard soit une langue uniforme, formée sur la base du brabançon, il présente encore des variations quant au domaine de l'oral. Haeseryn (2018) affirme que la langue standard parlée présente de fortes variations et que l'origine des locuteurs ressort souvent de leur manière de parler.
7
2.1.4 Un aperçu des caractéristiques différentes dans les différentes régions
Ce mémoire donne une description contrastive des dialectes. L'accent est donc mis sur des éléments qui divergent de la langue standard. La prononciation de certains sons est discutée parce qu’elle constitue la différence la plus importante et la plus remarquable entre la langue standard et les dialectes (van der Sijs, 2005). C'est pourquoi les différences sonores entre les diverses régions sont soulignées dans ce mémoire. Elles sont suivies par des caractéristiques sonores de certaines régions.
Ce mémoire ne porte que sur les sons qui s’écartent de la langue standard dans au moins deux régions dialectales. En outre, un certain nombre de réalisations sonores très éminentes dans une région sont discutées.
2.1.4.1 La différence de prononciation de voyelles
La prononciation longue de la voyelle 'a' diffère dans les dialectes de Courtrai et de Puurs de celle du langage standard. Devos et Vandekerkchove (2005) expliquent que les Courtraisiens ont deux façons de prononcer la voyelle. Si elle se trouve devant les consonnes p, b, f, v, k, g, ou m, les Courtraisiens la prononcent comme 'oo' (exemples 1, 2 et 4). Si le 'a' long se trouve devant toutes les autres consonnes, ils articulent une sorte de diphtongue : 'ooë' (exemple 3). Ooms et Van Keymeulen (2005) attestent que les Brabançons ont aussi deux façons de réaliser le son, en fonction de la présence ou non d'une consonne dentale4 derrière le 'a' long. Si la voyelle se trouve devant une consonne dentale, ils prononcent une sorte de diphtongue 'ooë' (exemple 3), ce que font aussi les Courtraisiens. Si le 'a' se trouve devant une consonne non dentale, ils articulent un ‘oa’ (exemples 1, 2 4).
Langue standard Courtrai Puurs
Maken (1) Mooken Moake
Dragen (2) Droogen Droage
Water (3) Wooëter Wooëter
Avond (4) oovond Oaved
Tableau 1 : La prononciation longue de la voyelle ‘a’ à Courtrai et à Puurs
4 Les consonnes dentales sont les consonnes qui se prononcent par un contact entre la langue et les dents
8
A Gand, à Courtrai et au Brabant, la prononciation longue et courte de la voyelle ‘o’ diffère de celle du langage standard. Les Gantois prononcent la voyelle comme ‘ou‘ quand elle se trouve devant p, f, v, k et g (exemple 10) (Taeldeman, 2005). Selon Devos et Vandekerckhove (2006), les Courtraisiens ont deux façons de prononcer le 'o', en fonction de la réalisation courte ou longue de la voyelle. Ils palatalisent5 la variante longue vers 'eu' (exemples 5 et 8) et la courte vers 'u' (exemples 6, 7, 9 et 10). Les Brabançons ont également deux façons de prononcer le ‘o’, de nouveau en fonction de la réalisation courte ou longue (Ooms & Van Keymeulen, 2005). Ils prononcent le ‘o’ long comme une diphtongue 'oeë' (exemples 5 et 8). Pour la prononciation du ‘o’ court par contre, les Brabançons suivent les règles de la langue standard (exemples 6, 7, 9 et 10).
Langue standard Gand Courtrai Puurs
Zoon (5) Zoon Zeune Zoeën
Bos (6) Bos Bus Bos
Zon (7) Zon Zunne Zon
Brood (8) Brood Breud Broeëd
Dorp (9) Dorp Durp Dorp
Kop (10) Koup Kup Kop
Tableau 2 : La prononciation longue et courte de la voyelle ‘o’ à Gand, à Courtrai et à Puurs
A Courtrai, à Genk et à Puurs, la prononciation longue de la voyelle ‘u’ diffère de celle du langage standard. Les Courtraisiens ont deux façons pour articuler la prononciation longue (Devos & Vandekerckhove, 2006). Si le ‘u’ long se trouve devant un ‘r, (1) ils réalisent le son ‘eu’ au lieu de ‘u’ (exemples 12 et 13). Parfois, (2) ils prononcent le ‘u’ comme ‘ie’ (exemple 11). Cette forme est une sorte de délabialisation6et est aussi possible si le ‘u’ se trouve devant un ‘r’. En ce qui concerne la prononciation courte de la voyelle ‘u’, les Courtraisiens délabialisent de nouveau et la prononcent comme ‘i’ (exemples 14 et 15). Belemans et Keulen (2004) affirment que les Genkois désarrondissent aussi la voyelle ‘u’ et qu’ils réalisent par conséquent la prononciation courte comme ‘i’ (exemples 14 et 15) et la prononciation longue comme ‘ië/ eje’ (exemples 11-13). Les Brabançons ne s'écartent du langage standard qu'en prolongeant les formes (Ooms & Van Keymeulen, 2005). Dans ce langage régional, la prononciation courte de la voyelle ‘u’ correspond à la prononciation longue dans le langage standard (exemples 14 et 15). La prononciation longue de la voyelle est une version prolongée de celle dans le langage standard (exemples 11-13).
5 Dans le cas de palatalisation, l'articulation d'un son se déplace vers l'avant dans la cavité buccale. 6 Dans le cas de délabialisation, la forme des lèvres change : un son qui est normalement prononcé avec
9
Langue standard Courtrai Genk Puurs
Duur (11) Diere Dejer Duur (prononciation longue)
Buur (12) Gebeur Bejer Buur (prononciation longue)
Muur (13) Meur Mejer Muur (prononciation longue)
Dun (14) Dinne Din Duun
Put (15) Pit Pit Puut
Tableau 3 : La prononciation longue et courte de la voyelle ‘u’ à Courtrai, à Genk et à Puurs
La prononciation de la voyelle ‘i’ diffère à Courtrai et à Puurs de celle du langage standard. Devos et Vandekerckhove (2006) constatent que les Courtraisiens réalisent le ‘i’ long parfois comme une sorte de diphtongue, à savoir ‘ieë’ (exemples 16 et 17). En ce qui concerne la prononciation courte de la voyelle ‘i’, les Courtraisiens l’articulent comme ‘ie’ si la voyelle est suivie d’une combinaison de consonnes qui est introduite d’une nasale (exemple 19). Ooms et Van Keymeulen (2005) expliquent que les Brabançons prolongent la prononciation de la voyelle ‘i’, comme c’est le cas pour la voyelle ‘u’: la prononciation courte de la voyelle est réalisée comme la prononciation longue du langage standard (exemples 18-20) et la prononciation longue est articulée de manière prolongée (exemples 16 et 17).
Langue standard Courtrai Puurs
Brief (16) Brieëf Brief (prononciation longue)
Vies (17) Vieës Vies (prononciation longue)
Vis (18) Vis Vies
Kind (19) Kiend Kiend
Dik (20) Dik Diek
Tableau 4 : La prononciation longue et courte de la voyelle ‘i’ à Courtrai et à Puurs
La dernière voyelle qui s'écarte régulièrement du langage standard en ce qui concerne la prononciation est le chva. Sa prononciation diffère du language standard à Courtrai et à Puurs. Devos et Vandekerckhove (2006) affirment que les Courtraisiens ne prononcent pas le chva quand il se produit dans la combinaison de ‘-en’ en fin de mot (exemples 21, 22, 23 et 25). Les Brabançons laissent tomber ou insèrent le chva (Ooms & Van Keymeulen, 2005). Quand il est question d’une e-apocope, ils laissent tomber le chva en fin de mot comparé à la prononciation ancienne de la langue standard (exemple 24). En ayant supprimé le chva en fin de mot au singulier, le chva final suffit aux Brabançons pour faire une distinction entre le singulier et le pluriel des substantifs (auparavant, on avait besoin du son ‘en’ pour former le pluriel). Vu que le ‘e’ suffit, le son ‘en’ en fin d’un infinitif ou d’un substantif au pluriel est également devenu superflu (exemples 21, 22 et 25).
10
Quand il est question d’une voyelle Svarabhakti, les Brabançons insèrent le chva dans un mot. Le mot Svarabhakti est issu du sanskrit parce que des ajouts y ont été remarqués et décrits la première fois. Les Puursois s’écartent de la plupart des Brabançons car ils changent parfois la prononciation du chva quand il se trouve devant la consonne ‘m’ (exemple 26).
Langue standard Courtrai Puurs
Vragen (21) Vraagn Vrage
Kleine (22) Kleinn Kleine
Zeven (23) Zeevn Zeven
Kat (24) Katte Kat
Ogen (25) Ogn Oge
Adem (26) Adem Asom
Tableau 5 : La prononciation du chva à Courtrai et à Puurs
2.1.4.2 La différence de prononciation de diphtongues
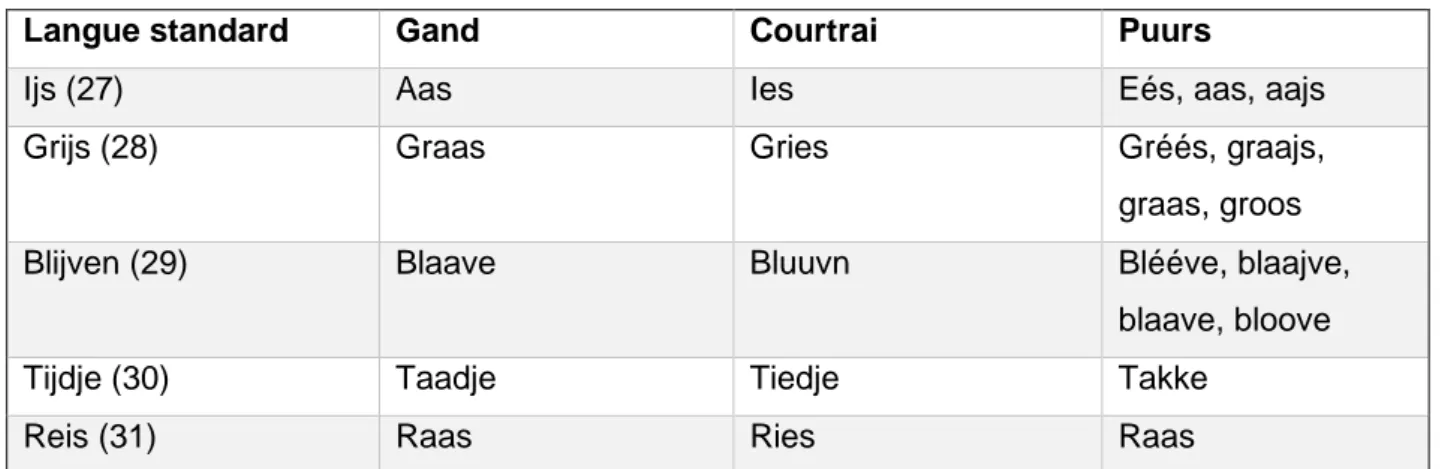
Dans les langages régionaux de Gand, de Courtrai et de Puurs, la prononciation des diphtongues ‘ei’ et ‘ij’ diffère de celle du langage standard. Taeldeman (2005) explique que les Gantois prononcent les diphtongues ‘ei’ et ‘ij’ comme ‘aa’ (exemples 27-31). Les Courtraisiens ont deux façons de réaliser la diphtongue ‘ij’ (Devos & Vandekerckhove, 2006). Quand la diphtongue se trouve devant une consonne labiale, (1) les Courtraisiens la labialisent en prononçant ‘uu’ (exemple 29). En d’autres cas, (2) ils transforment la diphtongue en une monophtongue et la prononcent comme ‘ie’ (exemples 27, 28, 30 et 31). Ooms et Van Keymeulen (2005) annoncent que dans la prononciation des Brabançons, la différence entre ‘ei’ et ‘ij’ n’est pas perceptible. Ils prononcent ces diphtongues de la même manière: comme ‘éé’, ‘aaj’, ‘aa’ ou ‘oo’ (exemples 27, 28, 29 et 31). Au Brabant, Ooms et Van Keymeulen remarquent quelques formes exceptionnelles, à savoir les mots ‘tijdje’ et ‘schijfje’ qui sont prononcés comme ‘takke’ et ‘schafke’ (exemple 30).
Langue standard Gand Courtrai Puurs
Ijs (27) Aas Ies Eés, aas, aajs
Grijs (28) Graas Gries Gréés, graajs,
graas, groos
Blijven (29) Blaave Bluuvn Blééve, blaajve,
blaave, bloove
Tijdje (30) Taadje Tiedje Takke
Reis (31) Raas Ries Raas
11
La prononciation de la diphtongue ‘ui’ diffère dans tous les langages régionaux. Taeldeman (2005) affirme que les Gantois prononcent la diphtongue ‘ui’ comme ‘aoë’ (exemples 32-36). Les Courtraisiens par contre la réalisent comme ‘uu’ (Devos & Vandekerckhove, 2006). Selon Ooms et Van Keymeulen (2005), les Brabançons ont différentes façons de réaliser la diphtongue ‘ui’, comme c’est aussi le cas pour les diphtongues ‘ei’ et ‘ij’. Ils la prononcent comme ‘oa’, ‘aaj’, ‘oeë’, ‘aa’ et ‘uu’ (exemples 32-36). Les Genkois délabialisent la diphtongue ‘ui’ de sorte qu’elle est réalisée comme ‘ê’ (exemples 32-36) (Belemans & Keulen, 2004).
Langue standard
Gand Courtrai Puurs Genk
Huis (32) Aoës Uus Aas, aajs, oeës,
oas
Hês
Kuip (33) Kaoëp Kuup Kaap, koeëp, koap Kêp
Muis (34) Maoës Muus Maas, moeës,
moas
Mês
Duivel (35) Daoëvel Duuvel Duuvel Dêvel
Luik (36) Laoëk Luuk Laak, loeëk, loak Lêk
Tableau 7 : La prononciation de la diphtongue ‘ui’ à Gand, à Courtrai, à Puurs et à Genk
2.1.4.3 Des caractéristiques sonores de certaines régions
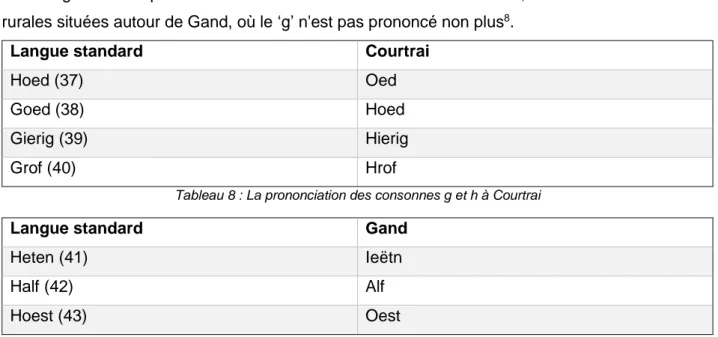
La prononciation caractéristique des consonnes ‘g’ et ‘h’ à Courtrai et à Gand
Devos et Vandekerckhove (2006) expliquent que les Courtraisiens ont une façon particulière de réaliser les consonnes ‘h’ et ‘g’. Dans leur langage régional, ils ne prononcent pas la consonne ‘h’ (exemple 37) et ils laryngalisent la consonne ‘g’ (exemples 38-40). Quand il est question de laryngalisation, le ‘g’ baisse dans le pharynx et est articulé comme ‘h’. Selon Taeldeman (2005), les Gantois ne prononcent pas la consonne ‘h’ non plus (exemples 41-43). En outre, Ghyselen (2018) affirme que le dialecte gantois est un dialecte rebelle qui refuse d'assumer des influences extérieures. Malgré son caractère obstiné, le dialecte gantois a néanmoins adopté une caractéristique remarquable d'autres régions, à savoir la substitution de la consonne 'g' par 'h'. Les jeunes femmes diplômées de l'enseignement supérieur ayant des parents gantois prononcent plus souvent la consonne ‘g’ comme ‘h’ que leurs concitoyens plus âgés. Cela confirme la constatation de l’unité d’enseignement et de recherche de linguistique néerlandaise de l’université de Gand
12
(2014)7 qui affirme que les femmes prennent l'initiative de la modernisation linguistique. La consonne ‘g’ disparaît donc dans le dialecte gantois. Selon Ghyselen, ce n'est pas un phénomène étrange car il s'agit d'un son difficile à prononcer qui n'existe pas dans beaucoup d'autres langues. Elle ajoute que, contrairement à ce que de nombreuses personnes pensent, cette adaptation au dialecte gantois indique non seulement l'influence du flamand occidental, mais aussi celle des villes rurales situées autour de Gand, où le ‘g’ n'est pas prononcé non plus8.
Langue standard Courtrai
Hoed (37) Oed
Goed (38) Hoed
Gierig (39) Hierig
Grof (40) Hrof
Tableau 8 : La prononciation des consonnes g et h à Courtrai
Langue standard Gand
Heten (41) Ieëtn
Half (42) Alf
Hoest (43) Oest
Tableau 9 : La prononciation de la consonne ‘h’ à Gand
La prononciation spécifique de la consonne ‘r’ à Gand
Taeldeman (2005) affirme que les Gantois utilisent le ‘r’ uvulaire au lieu du ‘r’ dental. Ce ‘r’ est réalisé en faisant trembler la luette et est une caractéristique de la langue française. Il est entré dans le langage régional gantois par l’infiltration de la bourgeoisie francisée à Gand.
La tonalité : une caractéristique du langage limbourgeois
De Belemans (2002) et Belemans et Keulen (2004), il ressort que la tonalité est l’une des caractéristiques les plus importantes du langage limbourgeois. Cette tonalité est la raison pour laquelle les personnes non limbourgeoises décrivent le langage limbourgeois comme mélodieux. Selon Belemans, le limbourgeois est la seule langue à ton belge. Ceux qui parlent une langue à ton peuvent différencier la signification des mots ayant une forme identique en variant la hauteur tonale. Le limbourgeois belge compte deux tons, à savoir le « stoottoon » et le ton traînant. Schmidt
7 UGent Vakgroep Taalkunde – Nederlands. (2014). Materiaal verzamelen. Consulté le 11 mars 2020 par
https://www.dialectloket.be/tekst/dialectologie/materiaal-verzamelen/
8 Cette caractéristique n’est pas audible chez les participants de cette étude car ils appartiennent au
13
(1986) (cité par Gussenhoven & Peters, 2008, p. 90) a nommé ces deux tons respectivement « accent 1 » et « accent 2 ». Belemans définit le « stoottoon » comme un ton court qui commence haut et baisse rapidement vers la fin et le ton traînant comme un ton un peu plus long qui monte d’abord et puis baisse progressivement. Belemans ajoute qu’il semble y avoir une différence en durée de prononciation, mais qu’elle est minime en réalité. En utilisant la tonalité, les locuteurs peuvent non seulement engendrer (1) une différence de signification entre des mots ayant une forme identique, mais aussi (2) une différence en nombre. Ainsi, le mot ‘bal’ prononcé en utilisant le « stoottoon » détermine une fête tandis que le même mot prononcé en utilisant le ton traînant détermine un ballon (1). Il y a également une différence entre la prononciation du mot ‘been’ dépendante de l’utilisation de la tonalité : en utilisant le « stoottoon », on parle d’une seule jambe (been) et en utilisant le ton traînant, on parle de plusieurs jambes (benen) (2). Pour des personnes qui n’habitent pas dans la région dialectale du limbourgeois, la différence entre les deux tons n’est pas perceptible. Ils entendent donc deux fois le même mot. Selon Belemans, les locuteurs de la langue standard en Belgique et de tous les langages non limbourgeois utilisent le « stoottoon ». Selon l’unité d’enseignement et de recherche de linguistique néerlandaise de l’Université de Gand (2014), la « Citétaal » genkoise présente la prosodie limbourgeoise, influencée par l’italien.
Figure 3 : La ligne noire montre les frontières de la région dans laquelle les Limbourgeois utilisent une langue à ton (Belemans et Keulen, 2004, p. 30)
14 La palatalisation du ‘s’ dans la « Citétaal » genkoise
L’unité d’enseignement et de recherche de linguistique néerlandaise de l’université de Gand (2014) et Marzo (2018) affirment que les locuteurs de la « Citétaal » palatalisent le 's' lorsqu'il se trouve en tête de mot. Au lieu du 's', il prononcent par conséquent le ton 'sj'. Ils prononcent donc le mot
'school' comme 'sjchool' et le mot 'stijl' comme 'sjtijl'. L'unité d'enseignement et Marzo expliquent le
phénomène à l'aide d'autres dialectes limbourgeois, où la palatalisation du ‘s’ se produit également. Les locuteurs de la « Citétaal » peuvent donc avoir adopté le phénomène de ces dialectes. Marzo propose une deuxième explication possible : la palatalisation du 's' se produit également dans le sud de l'Italie. Comme l'origine de la « Citétaal » se trouve chez les immigrés, c'est une explication possible.
15
2.2 Les assistants vocaux
2.2.1
Qu’est-ce que les assistants vocaux
Des assistants vocaux sont des « software agents that can interpret human speech and respond via synthesized voices » (Hoy, 2018, p. 81). Hoy explique que grâce à ces systèmes, les gens peuvent poser des questions ou passer des commandes aux machines dans leur langage naturel. Les assistants vocaux comprennent le langage naturel des gens et y répondent ou exécutent leurs commandes. Hirsch et Manning (2015) affirment que les assistants vocaux permettent ainsi la communication entre des machines et des êtres humains. Le domaine scientifique qui s’occupe des assistants vocaux fait par conséquent partie du domaine du traitement du langage naturel qui, à son tour, est un sous-domaine de la science informatique. Cette science se penche sur l’utilisation de techniques informatiques afin de comprendre, apprendre et produire du contenu dans le langage naturel des humains.
Les assistants vocaux comme nous les connaissons aujourd'hui sont apparus pour la première fois en 2010 sous la forme de Siri, l'assistant vocal d'Apple sur lequel ce mémoire porte essentiellement (Hoy, 2018). Il est intégré dans iOS, le système d'exploitation d'Apple, depuis 2011. Siri d'Apple a été suivi par Google en 2012 (Casanueva, Mrkšić, Su & Vulić, 2018), qui a lancé en cette année le
Google Now sur le marché. Peu de temps après l'introduction de Google Now, Microsoft a
également rejoint le marché des assistants vocaux. En 2013, l'entreprise a présenté Cortana. En 2014, le dernier acteur majeur dans le domaine des assistants vocaux, Amazon, a suivi les autres en lançant Alexa, l'assistant vocal intégré dans l’enceinte domestique Echo. En 2016, Google a lancé Google Assistant, le successeur de Google Now. Depuis lors, Google Assistant est intégré dans l’enceinte Google Home et depuis 2017, les propriétaires d'un smartphone ayant le système d'exploitation Android peuvent également en profiter via l'application Google Assistant.
2.2.2
L’application des assistants vocaux dans la société contemporaine
Selon Hoy (2018), chacun de ces assistants vocaux propose des fonctions spécifiques, exclusives et conçues par la marque relative. Cependant, il y a de nombreuses fonctions de base qu'ils partagent tous. Les assistants vocaux mentionnés ci-dessus sont par exemple tous capables:
− de lire et d’envoyer des messages ou des e-mails − d'appeler des gens
− de répondre à des questions de base. Il s’agit de questions comme : Quelle heure est-il ? et Quelle est la météo pour demain ?
16
− de régler des minuteurs, des alarmes et de fixer des rendez-vous − de créer des rappels ou des listes
− d'effectuer des calculs de base
− de manier des médias de services connectés
− de manier des appareils connectés via l’internet des objets. Il peut s'agir de thermostats, de lumières, d'alarmes, de serrures...
− de raconter des blagues et des histoires
2.2.3 Le fonctionnement des assistants vocaux
Lorsqu'une personne pose une question à un assistant vocal ou lui donne une commande, le système parcourt toujours cinq phases avant que l’utilisateur reçoive une réponse. Ces phases sont : la reconnaissance automatique de la parole (1), la compréhension linguistique (2), la gestion du dialogue (3), la génération de la réponse (4) et la synthèse vocale (5) (McTear, Callejas & Griol, 2016 ; Casanueva, Mrkšić, Su & Vulić, 2018).
Figure 4 : Le processus en cinq phases que l’assistant vocal parcourt avant de donner une réponse
Dans la première phase, à savoir celle de la reconnaissance automatique de la parole, le système convertit la langue parlée en un texte écrit afin que le système puisse l'analyser (Hirschberg & Manning, 2015 ; McTear, Callejas & Griol, 2016). Il s'agit donc, pour ainsi dire, d'une transcription automatique du texte parlé. Jain et Rastogi (2019, p.1) définissent la conversion comme « a
17
technology with the help of which a machine can acknowledge the spoken words and phrases. » La phase de la reconnaissance automatique de la parole sera examinée plus en détail, car c’est elle qui peut être influencée par la variation linguistique régionale (cf.2.2.3.1).
Dans la deuxième phase, celle de la compréhension linguistique, le système fait une représentation du sens de ce que l'utilisateur a dit. Ce processus se déroule à son tour en trois phases (Mctear, Callejas & Griol, 2016):
1. La classification du domaine. Lorsque le système classe l’élocution, il examine l'intention du locuteur. Il vérifie si l’élocution est une question, une demande d'action, une annonce, etc. Afin de faire cela, le système est doté d'un corpus constitué d'énoncés. Pour chaque décision, la classe (question, demande, annonce...) et les éléments qui la désignent sont indiqués. Les éléments utilisés sont (1) des mots et phrases sous forme de n-grammes. Par exemple, « alstublieft » fait référence à une demande et « bent u » à une question fermée. Des déclarations typiques sont aussi stockées dans la mémoire du système. (2) La prosodie est un deuxième élément utilisé. Ainsi, le mot « oké » peut, en fonction de la prosodie, signaler que quelqu'un a compris quelque chose ou que quelqu'un est d'accord. Le dernier élément examiné concerne (3) les informations syntaxiques et sémantiques que le système possède.
2. La classification du but de l’élocution. Afin de déterminer le but de l’élocution de l'utilisateur, le système en identifie d'abord le domaine. L’élocution peut par exemple concerner une réservation de vol, le cours de la bourse, la prévision météorologique, etc. Une fois que le système connaît le domaine de l'élocution, le système recherche certaines valeurs. Ce sont des mots importants qui indiquent la réponse voulue de l’utilisateur dans ce domaine spécifique. Pour une réservation de vol, le système doit savoir, par exemple, si l'utilisateur souhaite réserver, modifier ou annuler un vol, etc.
3. L’analyse du contenu de l’élocution. Dans cette phase, le système détermine le contenu de l’élocution afin de l’utiliser en remplissant les valeurs importantes relatives au domaine de l’élocution. Grâce à la détermination du domaine et des valeurs à remplir, cette phase est plus facile car le système peut effectuer des recherches ciblées afin de trouver les valeurs nécessaires. La figure cinq montre un exemple des valeurs importantes à remplir quand il est question d’une réservation de vol. Afin de comprendre le contenu de l’élocution,
18
toutes les techniques du traitement automatique du langage naturel sont combinées. Voici quelques exemples de ces techniques : la tokenisation, la représentation par sac de mots, l’analyse sémantique latente, l’étiquetage morpho-syntaxique, etc.
Figure 5 : Un exemple des valeurs importantes à remplir pour une réservation de vol
La troisième phase que le système parcourt est la gestion du dialogue. Cette phase comporte les stratégies d’interaction de l’assistant vocal. La gestion du dialogue consiste par exemple en les stratégies du tour de parole et la manière dont l’assistant manie des imprécisions. Le système utilise un seuil absolu pour identifier des incertitudes. Après les avoir identifiées, le système comporte deux stratégies de confirmation. Le système demande soit explicitement, soit implicitement une confirmation. Dans le premier cas, le système pose une question supplémentaire pour confirmer l'input de l'utilisateur. Dans le second cas, le système utilise l'élément incertain de l'input de l'utilisateur dans sa prochaine question. C'est alors l'utilisateur qui doit intercepter les erreurs éventuelles.
Dans la quatrième phase, à savoir la constitution de la réponse, le système détermine le contenu de la réponse (content determination) et la manière dont le système va l’exprimer (content realization). Le système cherche une réponse appropriée dans la banque de données et la place correctement dans le dialogue pour l’exprimer. Ces réponses se présentent sous forme de ‘canned text’ ou sous forme de modèles. La première option présente une réponse pré-créée et inadaptable que le système doit insérer dans le dialogue. La deuxième option est une réponse pré-créée à laquelle le système peut ajouter des informations issues du dialogue. La phrase "So you want to
go to * (Destination) on * (Day)? est un exemple de la deuxième option. Les astérisques dans cette
phrase représentent l’information issue du dialogue. L’output de la phase de la constitution de la réponse est un morceau de texte que le système transmet à la dernière phase, la synthèse vocale.
19
Dans la dernière phase, à savoir celle de la synthèse vocale, le système prononce la réponse de l’assistant vocal créée pour l’utilisateur. Pour la création de la réponse prononcée, le système combine des sons préenregistrés de sorte qu’ils présentent les mots nécessaires pour former la réponse créée dans la phase précédente. La voix flamande de Siri est celle de Libelia Desplenter. Sa voix a été enregistrée en prononçant des mots inexistants pour l’entreprise belge Lernout &
Hauspie et a été achetée par Apple plus tard (VIER, n.d. ; Feys & Dumon, 2015).
2.2.3.1 Le fonctionnement de la reconnaissance automatique de la parole plus en détail
Pour la reconnaissance automatique de la parole, les assistants vocaux utilisent la technologie de l'apprentissage automatique. C’est une forme d’intelligence artificielle qui signifie que des algorithmes sont développés avec lesquels les ordinateurs peuvent apprendre. Grâce à ces algorithmes, les assistants vocaux peuvent rechercher automatiquement des modèles dans de grandes quantités de données et prévoir l'output de nouveaux inputs (Ali, Hossain et Bhuiyan, 2013).
Dans le cas de la reconnaissance automatique de la parole, les algorithmes sont créés par l'apprentissage supervisé. Cela signifie que des experts traitent manuellement des exemples qui forment l’ensemble de données. Cet ensemble contient alors l’input et son output souhaité et forme la base de l’algorithme qui en est dérivé. Deux conditions importantes pour l'apprentissage supervisé sont que (1) les caractéristiques à extraire soient prédéfinies et (2) qu'il existe des exemples connus et élaborés. La création de l'algorithme se déroule en trois phases. Tout d'abord, un ou plusieurs experts traitent manuellement un ensemble de données. Cet ensemble de données contient un grand nombre d'inputs. L'expert extrait des caractéristiques importantes et prédéfinies de l'input et crée également l'output approprié et souhaité. Dans la deuxième phase, à savoir celle de l'apprentissage de l'algorithme, la machine dérive un algorithme basé sur les exemples traités manuellement de l’ensemble de données. Ensuite, dans le stade expérimental, l'ordinateur prédit l'output d'un nouvel input inconnu. Ainsi, il extrait les mêmes caractéristiques importantes de l'input comme l’expert a fait pour les exemples de l’ensemble de données et les utilise pour arriver à l'output correct. L'ordinateur le fait en utilisant les connaissances de la phase d'apprentissage. Pour déterminer ce résultat, le système peut se servir d’une relation un-à-un, mais aussi d’une approche probabiliste. Dans ce dernier cas, le nouvel input n'est pas associé à un seul output, mais à une chance probabiliste de représenter différents outputs.
20
Or, le système d'apprentissage utilisé pour la reconnaissance automatique de la parole n'apprend non seulement à l'aide de données prétraitées, mais aussi à l'aide de l'input des utilisateurs (Day, Turner & Drozdiak, 2019 ; Baert, Van Hee, Verheyden & Van Den Heuvel, 2019). Les systèmes le mettent à profit pour devenir plus intelligents. Day et al. déclarent qu'Amazon engage par exemple des employés pour écouter des enregistrements faits avec l'Amazon Echo. Ces personnes transcrivent et annotent les enregistrements et les stockent ensuite dans la base de données. Ainsi l'input des utilisateurs sert d'exemple pour le système d'apprentissage. Il en va plus ou moins de même pour Apple, où l'input des utilisateurs est stocké pendant six mois, lié à un code d'identification. Sous cette forme, des employés les écoutent et transcrivent. Après six mois, Apple supprime le code, mais garde l'enregistrement transcrit dans la base de données comme exemple pour le système d'apprentissage. Baert et al. déclarent que Google adopte également ce procédé. L'input du Google Assistant est d'abord transcrit automatiquement par le système. Ensuite, les employés de Google le transcrivent et y ajoutent des informations supplémentaires en ce qui concerne les locuteurs. Ils indiquent par exemple s'il est question d'un homme ou d'une femme, d'un adulte ou d'un enfant, etc.
Selon Day, Turner et Drozdiak (2019) et Baert, Van Hee, Verheyden et Van Den Heuvel (2019), des dénonciateurs des trois systèmes susmentionnés affirment que les employés ne traitent non seulement les informations destinées au système, mais aussi des prises de son que les appareils enregistrent sans que les utilisateurs n'aient consciemment allumé le système. Cela entraîne des problèmes en ce qui concerne la protection de la vie privée.
La reconnaissance automatique de la parole applique la technologie de l’apprentissage automatique (expliquée auparavant en trois phases). Comme il s’agit maintenant d’une application concrète, nous expliquons plus en détail cette technologie en six phases : la création de la base de données, l’apprentissage de l’algorithme, l’input, le prétraitement, l’extraction de caractéristiques et le processus de comparaison.
Étant donné que les systèmes de la reconnaissance automatique de la parole appliquent l'apprentissage automatique, Kanabur et Harakannanavar (2019) et Ali, Hossain et Bhuiyan (2013) affirment que la première phase de la reconnaissance automatique de la parole consiste à créer la base de données. Kanabur et Harakannanavar discutent de certains éléments que les créateurs de bases de données doivent prendre en compte. Premièrement, la base de données doit contenir tous les phonèmes, mots et expressions de la langue. En outre la population des locuteurs dans
21
la base de données doit être diversifiée. Ils parlent de « inter-speaker variability » (Kanabur & Harakannanavar, 2019, p.5) pour expliquer que la base de données doit représenter différents profils de locuteurs. Elle doit donc comprendre l’input de personnes originaires de différentes régions et parlant par conséquent les différentes variantes de la langue. Avec « intra-speaker variability » (Kanabur & Harakannanavar, 2019, p.5), ils expliquent que la base de données doit contenir des enregistrements des locuteurs dans différents états émotionnels. Enfin, ils expliquent que la base de données doit être mise en place en tenant compte de l’utilisation visée du système. Comme Siri peut être utilisé pour tant de choses différentes, la base de données doit contenir des exemples provenant de domaines différents.
Dans la deuxième phase, l’assistant vocal apprend un algorithme. Il le dérive sur la base des exemples (traités manuellement) de l’ensemble de données et l’utilise dans les phases ultérieures afin de trouver le match idéal pour l’input.
La troisième phase de la reconnaissance automatique de la parole implique l'input du locuteur (Kanabur & Harakannanavar, 2019 ; Ali, Hossain & Bhuiyan, 2013 ; Matarneh, Maksymova, Lyashenko & Belova, 2017). Matarneh et al. affirment que lorsqu'un locuteur pose une question, donne une commande, etc., son input est envoyé au centre de données d'Apple pour un traitement manuel, comme déjà expliqué dans ce mémoire. Kanabur et Harakannanavar et Ali et al. précisent que l’input du locuteur comporte des sons voisés et non voisés ainsi que des fragments de silence.
La quatrième phase de la reconnaissance automatique de la parole, à savoir le prétraitement, se compose à son tour de six phases (Kanabur & Harakannanavar, 2019 ; Ali, Hossain & Bhuiyan, 2013). Tout d'abord (1), le système numérise le signal vocal acoustique de l'input. Ensuite (2), Kanabur et Harakannanavar affirment que le système en supprime le bruit de fond. Après (3), la préaccentuation a lieu. Selon Kanabur et Harakannanavar et Ali et al., le système supprime dans cette phase les composants de l'input ayant une haute fréquence parce qu'ils ont généralement peu ou pas d'importance dans le traitement ultérieur. Ensuite (4), le système effectue une détection d'activation vocale. Cela signifie qu'il fait la distinction entre les sons voisés et non voisés et les silences dans l'input. Afin de le faire, le système utilise des paramètres tels que le zero crossing
rate ou l'énergie du signal. Ultérieurement (5), le système divise l'input en fragments durant vingt
à trente millisecondes. Les fragments se recouvrent de trente à cinquante pour cent pour éviter la perte d'informations essentielles. Dans la dernière phase (6), à savoir celle du windowing, les fragments sont multipliés par des windows de formes différentes dont un window bien connu est le
22
hamming window. Le but du windowing consiste à souligner les parties importantes et à supprimer
les parties sans importance. Après que l'input a parcouru ces six phases, il peut être soumis à l'extraction de caractéristiques, qui représente la cinquième phase de la reconnaissance automatique de la parole.
Figure 6 : le prétraitement en six phases
Selon Ali, Hossain et Bhuiyan (2013) et Kanabur et Harakannanavar (2019), pendant la cinquième phase, à savoir l'extraction de caractéristiques, le système convertit le signal vocal - qui a déjà subi plusieurs transformations - en un ensemble de vecteurs de caractéristiques. Ces vecteurs représentent la nature du signal vocal. Ali et al. détaillent quelques caractéristiques à extraire, à savoir l'amplitude du signal vocal, le débit du locuteur, l'accélération du signal vocal, la vitesse de vibration, la fréquence de base, l'énergie du signal et son intensité. Le mécanisme d'extraction de caractéristiques transforme l'input du locuteur en un point dans un espace multidimensionnel. Le nombre de dimensions dépend du nombre de caractéristiques extraites.
Ali, Hossain et Bhuiyan (2013) et Kanabur et Harakannanavar (2019) estiment que lors du processus de comparaison, la dernière phase, le système compare les vecteurs de caractéristiques avec ceux des exemples dans la base de données. Dans l'espace multidimensionnel, le système examine quels vecteurs d'exemple se trouvent les plus proches du vecteur de l'input. Avec le vecteur le plus proche, le système parcourt les prochaines phases.
23
Figure 7 : Le processus de la reconnaissance automatique de la parole en six phases
2.2.3.2 Mesurer la qualité de la reconnaissance automatique de la parole
Kanabur et Harakannanavar (2019) présentent deux méthodes permettant de mesurer la qualité des systèmes de reconnaissance automatique de la parole : (1) le taux d'erreur des mots et (2) le taux de réussite des commandes.
Le taux d'erreur des mots est une méthode qui permet de mesurer la qualité des systèmes au niveau des mots. La formule est la suivante : 𝑡𝑎𝑢𝑥 𝑑′𝑒𝑟𝑟𝑒𝑢𝑟 𝑑𝑒𝑠 𝑚𝑜𝑡𝑠 =S+I+DN . Les nombres de modifications apportées à l'input du locuteur, soit les remplacements (S), les additions (I) et les omissions (D), sont additionnés. Cette addition est ensuite divisée par le nombre total de mots de l'input (N). Plus le taux d'erreur des mots est bas, meilleure la qualité du système de reconnaissance automatique de la parole sera.
Nous illustrons la formule du taux d’erreur des mots à l’aide d’un exemple issu de nos données. L’input du locuteur était la phrase Wat is een collectief geheugen ? et le système de reconnaissance automatique de la parole en a fait Wat is een koe ∅ ?. Dans cet exemple, il est
24
et d’un remplacement, à savoir celui du mot collectief par le mot koe. L’input se compose de cinq mots. Si nous entrons ces chiffres dans la formule donnée au paragraphe précédent, nous obtenons le calcul suivant : 𝑡𝑎𝑢𝑥 𝑑′𝑒𝑟𝑟𝑒𝑢𝑟 𝑑𝑒𝑠 𝑚𝑜𝑡𝑠 =1+1
5 . Le taux d’erreur de cette phrase est donc de 2/5, soit 0,4, soit 40%.
Le taux de réussite des commandes mesure la qualité des systèmes au niveau des phrases. Pour le mesurer, il faut diviser le nombre de phrases correctement reconnues par le nombre total de phrases : 𝑡𝑎𝑢𝑥 𝑑𝑒 𝑟é𝑢𝑠𝑠𝑖𝑡𝑒 𝑑𝑒𝑠 𝑐𝑜𝑚𝑚𝑎𝑛𝑑𝑒𝑠 =phrases correctement reconnues
nombre total de phrases . Pour cette méthode, le contraire du taux d'erreur des mots vaut, donc plus le taux de réussite de la commande est élevé, meilleure la reconnaissance automatique de la parole sera.
2.2.3.3 Des éléments qui compliquent la reconnaissance automatique de la parole
Jain et Rastogi (2019), Kanabur et Harakannanavar (2019), Mctear, Callejas et Griol (2016) et Petkar (2016) décrivent dans leurs études certains éléments qui influencent la reconnaissance automatique de la parole ou la rendent plus difficile.
Une première difficulté que Jain et Rastogi (2019), Kanabur et Harakannanavar (2019), Mctear, Callejas et Griol (2016) et Petkar (2016) évoquent consiste en le bruit de fond. Si le signal vocal de l'input contient non seulement de la parole, mais aussi du bruit de fond, il est plus difficile pour le système de concevoir les signaux importants. Afin de surmonter cette difficulté, Kanabur et Harakannanavar, Mctear et al. et Petkar proposent l'utilisation d'un mécanisme de silencieux. Une fois qu'il est intégré dans les assistants vocaux, le bruit de fond ne pose plus de problèmes.
Deuxièmement, Jain et Rastogi (2019), Kanabur et Harakannanavar (2019), Mctear, Callejas et Griol (2016) et Petkar (2016) traitent la présence d'idiolectes9 qui peut également causer des problèmes au niveau de la reconnaissance automatique de la parole. Un idiolecte dépend de la personnalité des locuteurs, de leur situation sociale, etc. Kanabur et Harakannanavar, Mctear et
al. et Petkar soulignent l'importance du sexe des locuteurs dans la reconnaissance automatique
de la parole. Leur âge peut également exercer une influence. Ainsi, il y a une différence entre le ton d'un enfant et celui d'un adulte. Petkar affirme également qu'il est plus facile pour les systèmes
25
de comprendre les locuteurs natifs que les locuteurs étrangers. En effet, une langue non accentuée est plus facilement reconnaissable par les systèmes.
La troisième difficulté mentionnée par Jain et Rastogi (2019) et Petkar (2016) concerne les homophones. Les homophones sont des mots qui se prononcent de la même façon, mais qui ont un sens différent. Afin de pouvoir décider laquelle des variantes le locuteur exprime, les systèmes ont besoin du contexte dans lequel les homophones sont utilisés.
En outre, Kanabur et Harakannanavar (2019) et Petkar (2016) discutent du manque de multimodalité. En général, une langue est parlée en utilisant la multimodalité. Cela signifie que les locuteurs ne communiquent normalement non seulement avec leur voix, mais qu'ils se servent également de comportements non verbaux tels que les gestes de la main, le contact visuel, etc. En revanche, dans le cas de la reconnaissance automatique de la parole, seule la voix est utilisée pour comprendre le message, ce qui constitue une difficulté supplémentaire pour les systèmes.
Mctear, Callejas et Griol (2016) et Petkar (2016) évoquent un cinquième élément qui influe sur la qualité de la reconnaissance automatique de la parole, à savoir la qualité d'enregistrement. La qualité du micro avec lequel l'input est enregistré joue un rôle très important dans la reconnaissance automatique de la parole. Plus la qualité du microphone est bonne, meilleur le résultat de la reconnaissance automatique de la parole sera.
Ensuite, Petkar (2016) mentionne le débit des locuteurs, qui diffère selon la situation, le stress, etc. Il affirme que la variation du débit complique le lien entre les sons du locuteur et les phonèmes corrects. En fonction de son débit, le locuteur peut prononcer les mots plus ou moins vite que la norme prescrit. De plus, le débit du locuteur influence également son articulation. Certains phonèmes peuvent par exemple fusionner. Le débit peut donc engendrer de nombreuses conséquences négatives qui font en sorte que les gens parlent de manière plus ambiguë. Il en résulte que les résultats de la reconnaissance automatique de la parole sont plus mauvais.
26
Selon Petkar (2016), les régiolectes10 sont le dernier élément qui affecte la qualité de la
reconnaissance automatique de la parole. Dans les conversations normales, elles ne jouent pas un rôle aussi important car il y a une intelligibilité mutuelle entre les interlocuteurs. Dans le domaine de la reconnaissance automatique de la parole, en revanche, les régiolectes sont considérées comme des langues différentes. C’est pourquoi, le système doit être conçu par région. Comme aucun régiolecte ne peut être sélectionné dans le réglage de Siri, nous
présumons que Siri n'est pas développé à les reconnaître. Cependant, Siri distingue différents types d'anglais (américain, britannique, australien...), de français (belge, français, canadien, suisse), d'espagnol (mexicain, espagnol...), etc.
10 Un régiolecte, également appelé un parler régional, est une langue non standard utilisée dans une
certaine région, dans un certain département ou dans une certaine province. La différence avec un dialecte réside dans la zone d'utilisation des deux variantes. En effet, la zone d'utilisation des régiolectes est plus large que celle des dialectes. Un régiolecte est donc une variété de la langue standard dans une certaine région et se situe entre les dialectes et la langue standard.
27
2.3 Les questions de recherche
1. La variation linguistique régionale influe-t-elle sur le fonctionnement de Siri ?
Petkar (2016) mentionne que les systèmes de reconnaissance de la parole automatique considèrent les variantes linguistiques régionales comme des langues différentes. Delarue et Lybaert (2018) affirment en outre que les médias flamands sous-titrent les énoncés régionaux non brabançons. La nécessité de ces sous-titres indique les grandes différences linguistiques régionales en Flandre.
La variation linguistique ne pose pas de problèmes si le système est développé sur la base de chaque variante régionale. Comme la Flandre n'est pas très densément peuplée et ne présente donc pas un marché spectaculairement important pour Apple, nous supposons que ce n'est pas (encore) le cas. Sur la base de ce qui précède, nous supposons que la variation linguistique régionale en Flandre posera donc des problèmes à l'assistant vocal
Siri.
2. Siri comprend-il mieux certaines variantes régionales du néerlandais que d’autres ?
La région dialectale du brabançon se trouve à l'origine du néerlandais standard et l'a également influencé (Marynissen, 2018). En outre, Delarue et Lybaert (2018) mentionnent que les médias flamands sous-titrent moins les énoncés brabançons que ceux d'autres régions dans les séries non fictionnelles. Nous en déduisons que le brabançon est plus facile à comprendre parce qu'il se trouve plus proche du néerlandais standard. Nous supposons donc que Siri comprendra mieux la variante brabançonne du néerlandais que les autres.
3. Siri comprend-il mieux l’effort de parler la langue standard que le langage régional de la même personne ?
Nous présumons que Siri comprendra mieux l’effort de parler le néerlandais standard que le langage régional d’une seule personne. Mais, d’après Haeseryn (2018), même les efforts de différentes personnes présentent des variations. Ainsi, l’origine des locuteurs ressort souvent de leur manière de parler le néerlandais standard. Le taux de reconnaissance automatique de l’énoncé dépendra donc du niveau du néerlandais standard du locuteur.