opinions: a study with swarm robotics
Academic year 2019-2020
Master of Science in de informatica
Master's dissertation submitted in order to obtain the academic degree of
Counsellor: Dr. Yara Khaluf
Supervisors: Prof. dr. ir. Pieter Simoens, Dr. Yara Khaluf
Student number: 01206435
Mathias Annot
opinions: a study with swarm robotics
Academic year 2019-2020
Master of Science in de informatica
Master's dissertation submitted in order to obtain the academic degree of
Counsellor: Dr. Yara Khaluf
Supervisors: Prof. dr. ir. Pieter Simoens, Dr. Yara Khaluf
Student number: 01206435
Mathias Annot
I would like to thank prof. dr. ir. Pieter Simoens and dr. Yara Khaluf for promoting this thesis. They allowed me to work on a subject that I found to be tremendously interesting and exciting, as well as intellectually stimulating. The fields of swarm robotics and decision making are very exciting, and I am glad that I had the chance to contribute to these topics. Prof. dr. ir. Pieter Simoens stepped in when I was not able to fully define what my research exactly was going to be, and guided me into the right direction.
Dr. Yara Khaluf has been an excellent counsellor during my work on the thesis. Her ideas and guidance have been most helpful, and she has been a great source of advice throughout the entire year. If it were not for her, I would have never been able to write this thesis. For this I am very grateful.
On top of that I would like to thank my family and friends, who provided selfless support and help whenever I required it. They have been standing behind me during my entire studies. My gratitude goes, in particular, to Simon Scheerlynck, for proofreading the thesis, as well as for supporting me and showing me I could do this, even when I did not believe so myself.
My final thanks go to my girlfriend, Riet, who has pushed me to work hard when I was not able to motivate myself. For bringing out the best of me, for her patience and lastly, for her endless support and encouragement.
Permission for usage
The author gives permission to make this master dissertation available for consultation and to copy parts of this master dissertation for personal use. In all cases of other use, the copyright terms have to be respected, in particular with regard to the obligation to state explicitly the source when quoting results from this master dissertation.
13/01/2020 Mathias Annot
by Mathias Annot
Master’s dissertation submitted in order to obtain the academic degree of Master of Science in de informatica
Academic year 2018-2019
Supervisors: Prof. dr. ir. Pieter Simoens, Dr. Yara Khaluf Counsellor: Dr. Yara Khaluf
Faculty of Sciences Ghent University
Summary
In this thesis, we will study the effects of subjectivity on collective decision making in swarm robotics. To do this, we define two types of subjectivity that can be applied to robots. In the first part of this study, we look at agents with a biased opinion. These are the so-called underestimating (overestimating) robots, which will always have an underestimated (overestimated) opinion when making an estimation about a certain option. The second part of this study will cover specialisation, where subjectivity is not inherently part of a robot, but depends on the option that it is forming an opinion about.
For the first part of this thesis, we define a best-of-n problem, with n = 2. We investigate how subjectivity affects the consensus of the swarm. Then we design a decision making strategy that allows the swarm to make a better decision, by adding a weight to each robot’s opinion based on their type of subjectivity. For this, each robot needs to know its own type of subjectivity. We define three models, the distance based model, the k-means model, and the DBSCAN model, each with their own subjectivity classification algorithm.
In part two of the thesis, we try to solve the allocation problem for tasks with a limited robot capacity. We first look at a model without communication, and then design a communication model that allows the swarm to distribute itself according to the capacity of the options pretty good.
We conclude our study with our findings for each experiment and ways to improve the models.
subjective opinions: a study with swarm robotics
Mathias Annot
Supervisor(s): Prof. dr. ir. Pieter Simoens, Dr. Yara Khaluf
Abstract— In this thesis, we will study the effects of
sub-jectivity on collective decision making in swarm robotics. To do this, we define two types of subjectivity that can be applied to robots. In the first part of this study, we look at agents with a biased opinion. These are the so-called under-estimating (overunder-estimating) robots, which will always have an underestimated (overestimated) opinion when making an estimation about a certain option. The second part of this study will cover specialisation, where subjectivity is not in-herently part of a robot, but depends on the option that it is forming an opinion about.
For the first part of this thesis, we define a best-of-n prob-lem, with n = 2. We investigate how subjectivity affects the consensus of the swarm. Then we design a decision making strategy that allows the swarm to make a better decision, by adding a weight to each robot’s opinion based on their type of subjectivity. For this, each robot needs to know its own type of subjectivity. We define three models, the distance based model, the k-means model, and the DBSCAN model, each with their own subjectivity classification algorithm.
In part two of the thesis, we try to solve the allocation problem for tasks with a limited robot capacity. We first look at a model without communication, and then design a communication model that allows the swarm to distribute itself according to the capacity of the options pretty good.
We conclude our study with our findings for each experi-ment and ways to improve the models.
Keywords— Swarm robotics, decision making, subjectivity,
specialisation, task allocation
I. Introduction
W
HEN we make a decision, the outcome is often influ-enced by our personal perspectives, feelings or opin-ions. Rather than making decisions based on objective ob-servations or rational facts, our decision making process is mainly driven by our emotions. We call this subjectivity, and it is the main reason why we make judgment errors.In this thesis we want to study collective decision making by agents with subjective opinions in the context of swarm robotics. A swarm robotics system is a self-organised sys-tem of autonomous robots that has the ability to achieve coordinated behaviour with the entire swarm through the actions of its individual members. We would like to re-search how these robots with subjective opinions can have an impact on the collective decision making process.
Since robots do not possess the traits required to make subjective decisions, like personal opinions or emotions, we will first have to define how subjectivity can manifest in a robot agent. We will introduce two different definitions of subjectivity in robot agents. For both of these definitions we will then conduct a series of experiments and study the speed and accuracy of the decision making. We will also look for ways for the swarm to handle the subjectivity in a way that diminishes its effects on the swarm’s performance.
Finally, we will discuss how well our models are performing by looking at the results.
II. What is subjectivity?
Subjectivity is an error of judgment which occurs due to a mixture of personal experience, social influence, cultural background, etc. In psychology, we call this cognitive bias [1].
We would like to research two different approaches to subjectivity. In the first part of our study we will look at subjectivity as a trait linked to the individual. We will call these individuals ’biased agents’, because their opin-ions contain some kind of error. In this approach, a robot will either be underestimating, objective or overestimating. Since the subjectivity is linked to the individual, it will al-ways estimate everything with the error that is associated with its type of subjectivity.
In our next definition of subjectivity, the robots will pre-fer one option above all others. This time around, the sub-jectivity depends on what option is being evaluated. We will call this type of subjectivity specialisation. This will be the topic of the second part of our research.
III. Setup
We will conduct our experiments using an open source multi-robot simulator called the ARGoS Simulator [2]. We will be using C++ to write our robot controllers. The robot we will use is called the foot-bot [3], an autonomous robot specialised for ground movement. It is a great stan-dard choice for a wide variety of applications. We decided to deploy our experiments on the high performance com-puter of the University of Ghent. For every experiment we conduct, we will run 30 simulations to make sure that we get a good average view of the results. The graphs that display our results will be generated by a python library called plotly [4].
IV. Subjectivity in biased agents
A. Goal
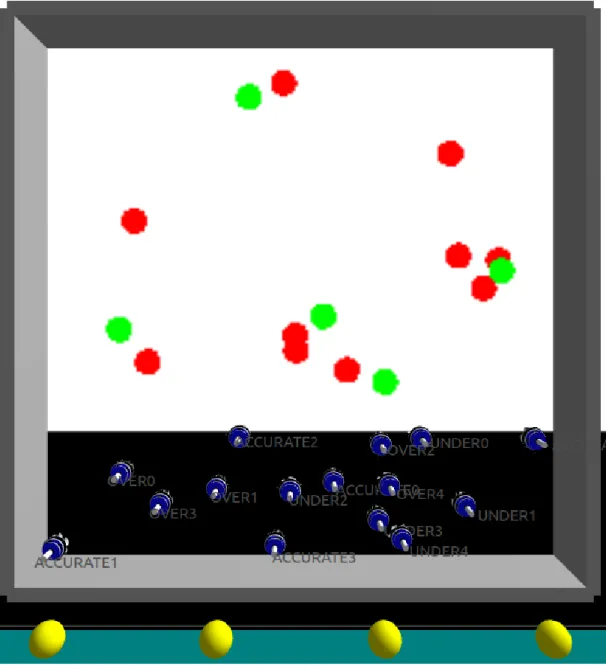
We want to see the effects of biased opinions in the de-cision making process of the swarm. We will look at the classic best-of-n problem [5], with n = 2. There will be two options, green and red, each with their own value. The robots will have to explore the arena and reach consensus about which option has the highest value. The layout of the arena is shown in figure 1. The two option sites are at the outer edges of the arena, and the nest is in the middle.
Each type has a different opinion bias. The goal of this experiment is to investigate how the subjective robots af-fect the global decision of the swarm, and to find a decision making strategy that allows the swarm to reach consensus about the best option more accurately.
We assume that the bias is symmetrical and that the objective value always lies in the middle. In other words, the size of the error caused by subjectivity is equally big for underestimating and overestimating robots, and there are no different levels of underestimation (overestimation). We will first take a look at the base model, in which the robots try to move their opinion towards the best option through communication. Then we will discuss a couple of models that we call the weighted models. In these weighted models, all robots try to figure out their own type of sub-jectivity by comparing their initial opinion with those of the other robots. They can then add a weight to the opin-ions of subjective robots in order to drive the consensus towards a better, more objective decision.
Fig. 1. Overview of the arena layout.
B. Base model
The base model will function as the basis that the weighted models will extend from. Its behaviour is defined as follows: first, each robot will explore the arena with a random walk until it has found an option. It will then make an estimation of this option’s value every 20 time steps. Once the robot has collected a predefined amount of estimate samples, it will store the average of all the es-timate samples it has taken as the eses-timated value of that option and return to the nest.
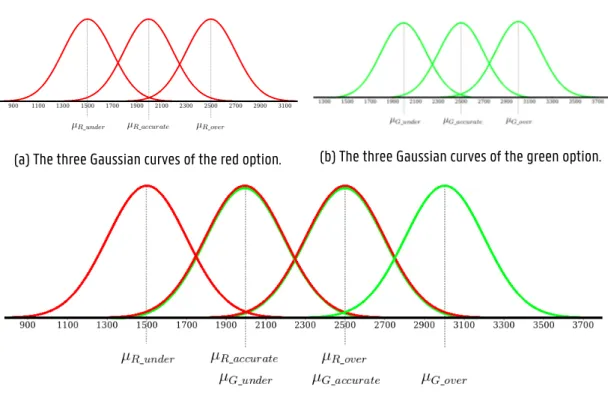
The estimate samples are generated by taking values from a certain Gaussian distribution, which depends on the subjectivity of the robot. The mean of this Gaussian distribution is defined as µ = V + δ, where V is the ac-tual value of the option, and δ ∈ {δaccurate, δunder, δover} is the subjectivity modifier. This modifier depends on the subjectivity type of the estimator. For an accurate robot
−500,
lead to the wrong decision about which option has the best value.
Fig. 2. Overview of the normal distributions that are sampled from when estimating an option, for both options.
Once a robot has returned to the nest it will first walk around in the nest for a predefined amount of steps, to en-sure that it has a well-mixed neighbourhood. After walking around for the required time, the robot will communicate its data to its neighbours, while still walking around ran-domly inside of the nest. The shared data contains the option that it currently thinks is best, and the value that it has currently estimated for that option. In the begin-ning, the robot will prefer the colour it has visited, but this might change during communication. The robot will listen to the opinions of its neighbourhood and will calcu-late the average green value G and the average red value R of all neighbours. A robot will then adapt its estimates of both the options’ values to G and R, if these averages are based on the opinions of at least Nmin robots, where Nmin is a parameter that can be chosen. This Nminis important to ensure that we base our decision on more than just one or two opinions. We hope that the opinions are averaged to objective values this way. If|G − R| ≤ ϵ, with ϵ a small
error margin, we consider the average values to be equal, and resolve the decision of the best option by using the majority rule [6]. In case|G−R| > ϵ, the robot will choose the best option by comparing both of its new estimates and choosing the option with the biggest value.
C. Weighted models
The weighted model is an extension of the base model, in which each robot will try to assign weight to the opinions of other robots, proportional to their type of subjectivity. In order to be able to do this, the robots will first have to know their own type of subjectivity. We will try to realise this by having the robots compare their own esti-mate to the estiesti-mates of other robots. After returning to the nest and starting communication, the robots will now spend some time to collect the initial estimate of robots that visited the same option as themselves, before making new decisions. They only listen to those robots, because it makes no sense to compare their own estimate to those of a different option. After this data collection phase has ended, the robot will try to classify itself to a type of
subjec-type of subjectivity. In case it has not yet classified itself, the robot will communicate subjectivity type ’unknown’, so that other robots can ignore this robot until it has man-aged to classify itself. Once a robot is making decisions, it will now weight each opinion as follows: if the accurate weight is Wa, then the robot will count each accurate opin-ion Wa times, as if Wadifferent neighbours have this same opinion. This is analogous for subjective opinions. By do-ing this, subjective opinions will have less weight in the decision that is being made, which should lead to a more accurate consensus. Even though we will count opinions multiple times, the average opinion must still be derived from Nminreal robot neighbours.
We have also added a parameter k, which is a treshold for the minimum amount of different robots that a robot needs to communicate with before it can change its type of subjectivity to objective. The idea behind this parameter is that the estimates of each robot will grow more and more towards a more objective opinion, due to the averaging of all neighbourhood estimates. We believe that, after com-municating with k different robots, its estimates will be close to the objective value of the options, and thus should be weighted as such.
We will propose three different models, each with their own implementation of a classification algorithm. In the distance based model, the robots will try to use the distance between their own estimate and those of the other robots to classify themselves. In the other two models, we try to reconstruct the Gaussian distributions that were used to generate the estimates. We will use two different clustering algorithms: k-means [7] and DBSCAN [8].
C.1 Distance based model
When a robot is in the data collection phase in this model, it will gather the distances between its own ini-tial opinion and the iniini-tial opinion of other robots who explored the same option. It will store these distances in a map of robot IDs, in order to make sure each robot’s opinion is taken into account exactly once. When the data collection phase ends, it will calculate the average distance between all other opinions, and compare that to a prede-fined lower- and upper bound. If its average distance is within these bounds, it is probably objective. If its aver-age distance is lower (higher) than the lowerbound (upper-bound), it is an underestimating (overestimating) robot. The downside to this approach is that we need to know how big the subjectivity modifier δsubjective is, since the ideal lower- and upperbounds will be the bounds of the range [−δsubjective
2 ,
δsubjective
2 ]. The classification accuracy
of this approach is also very sensitive to swarm size and swarm composition.
C.2 K-Means model
Instead of collecting distances in the data collection phase, this model will collect a map of estimates. It will
derestimating, objective, and overestimating). When the robot has found the clusters, it will know its type of sub-jectivity by matching its own estimate to a cluster. The downside to this approach is that we will always have to look for 3 clusters, even when our swarm composition lacks one type of robots.
C.3 DBSCAN model
Just like the k-means model, this model will use the esti-mates instead of the distances to classify the robots. This time we use a different clustering algorithm called DB-SCAN. The advantage of DBSCAN is that it is able to dynamically find the amount of clusters in our data. Now we can also end up with more than three clusters, but we have decided that all the middle clusters will depict an ob-jective robot. If less than three clusters were found, the robot will classify itself as objective, as there is no way of telling which types the two clusters belong to.
D. Results
D.1 Base model
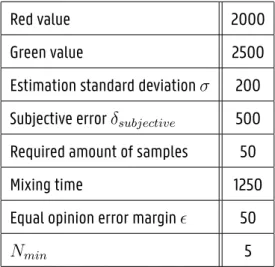
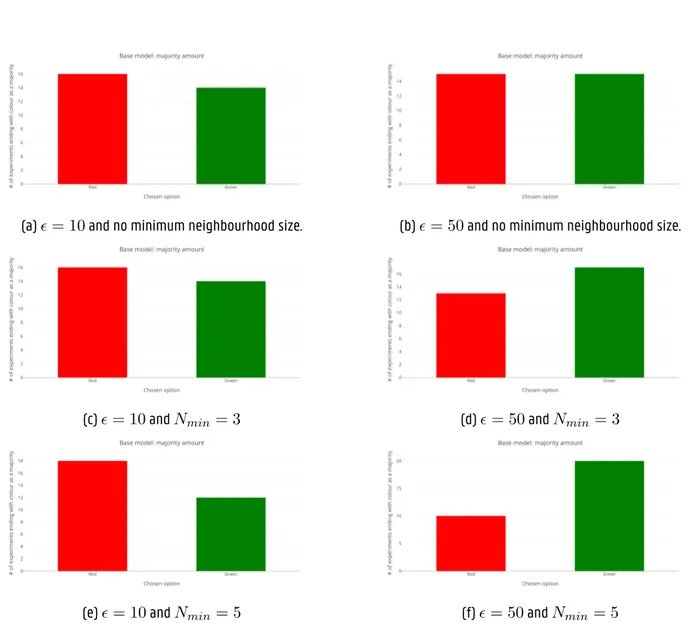
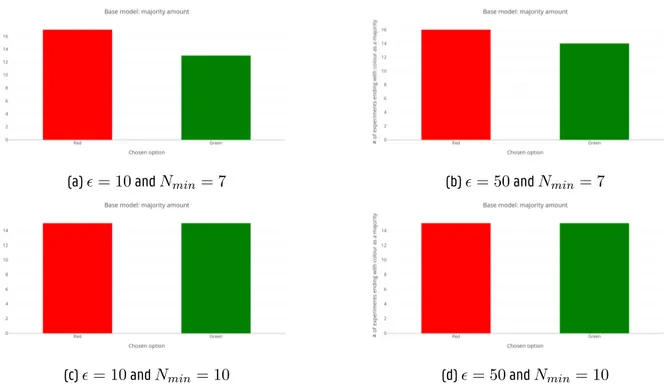
The parameter values that are used in the base model are shown in table I. In table II, the results are shown for running the experiment with different swarm compositions. We can tell that, for most swarm compositions, the base model already does a pretty good job at picking the green option more often than the red option.
Red value 2000 Green value 2500 Estimation standard deviation σ 200 Subjective error δsubjective 500 Required amount of samples 50 Mixing time 1250 Equal opinion error margin ϵ 50
Nmin 5
TABLE I Base parameter values.
D.2 Weighted model comparison
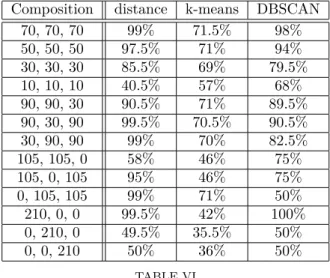
We will now look at the accuracy of the subjectivity clas-sification for all three models that we proposed. In addi-tion to the parameters from table I, each model will have its own specific parameters. Tables III, IV, and V show the specific paremeters used in the distance based model, the k-means model, and the DBSCAN model respectively. The results can be found in table VI. While having its down-sides, the distance based model performs the best for most swarm compositions. Since the only differences between the three weighted models is the subjectivity classification, we will solely compare the base model to the distance based model.
90, 30, 90 10 20 30, 60, 120 12 18 30, 120, 60 10 20 60, 30, 120 6 24 60, 120, 30 7 23 120, 30, 60 11 19 120, 60, 30 17 13 105, 105, 0 2 28 105, 0, 105 2 28 0, 105, 105 14 16 210, 0, 0 0 30 0, 210, 0 0 30 0, 0, 210 0 30 TABLE II
Accuracy of the decision making of the base model for different swarm compositions (objective, under, over). For each colour, the amount of times consensus was reached on
this colour is shown for 30 experiment runs.
Data collection time 1250 Objective lower bound -250 Objective upper bound 250 Accurate opinion treshold k 50
TABLE III
Model specific parameter values used to generate the experiments for the distance based model.
D.3 Distance based model
The results for the distance based model are shown in ta-ble VII. We can tell that some compositions perform better than the base model, but some of them do not. One thing we notice in all of our experiments is that the estimates that are stored by each robot at the end of the experi-ment are very close to each other for both colours (around 2500). This means that the outcome of our experiments will be very hard to predict, and could be the reason why the results are not that great in comparison to the base model. The fact is that low estimates will disappear from the opinion pool, since we are favouring higher values. By updating both estimates at all times, we effectively remove the lower estimates entirely, and all comparisons will be made against the higher values. We also noticed that the minimum amount of communications to become objective
k, could lead to a robot that thinks it is now objective,
while only one of its estimates has gotten accurate. When this robot happens to change colour preference, its opin-ion is no longer objective. Therefore we think it would be
Accurate opinion treshold k 50
TABLE IV
Model specific parameter values used to generate the experiments for the k-means model.
Data collection time 1250 Allowed distance ϵ 50
kmin 3
Accurate opinion treshold k 50
TABLE V
Model specific parameter values used to generate the experiments for the DBSCAN model.
V. Specialisation
A. Goal
We present a task allocation problem in which there are two different tasks, each with their own capacity. This capacity give us a maximum amount of robots that can perform this task at the same time. The robots’ type of subjectivity will now depend on the task that it is explor-ing. Each robot will prefer one task over the other, which can be seen as them ’liking’ that task more. We want the robots to allocate themselves to one task, in such a way that the capacity of both tasks is not exceeded. We will study how subjectivity can affect that decision. First, we will look at an aggregation model, in which robots simply try to aggregate on the task sites without subjectivity affecting their decisions. This model is used as a base for compar-ison. After this, we will take a look at our model that performs allocation with subjectivity. Finally, we will add a social component to this, by allowing robots to convince each other to switch their allocation to the other option.
The arena layout is shown in figure 3.
B. Specialisation model without communication
At the start of the experiment, the robots will explore the arena and try to commit to an option. This is done by getting their commitment for that option above a certain ’commitment treshold’. Every n time steps the robot is on a task site, with n a predefined parameter, it will roll a random number. The chance to gain commitment towards the option it prefers, is called Pcommit. The chance to gain commitment for the other option will be 1− Pcommit. Once it has reached the commitment treshold for one of the options, the robot will allocate itself to that option and return to the nest.
C. Specialisation model with communication
under-30, under-30, 30 85.5% 69% 79.5% 10, 10, 10 40.5% 57% 68% 90, 90, 30 90.5% 71% 89.5% 90, 30, 90 99.5% 70.5% 90.5% 30, 90, 90 99% 70% 82.5% 105, 105, 0 58% 46% 75% 105, 0, 105 95% 46% 75% 0, 105, 105 99% 71% 50% 210, 0, 0 99.5% 42% 100% 0, 210, 0 49.5% 35.5% 50% 0, 0, 210 50% 36% 50% TABLE VI
Comparison of the classification accuracy (rounded to the nearest half) between the different weighted models for
different swarm compositions (objective, under, over).
Fig. 3. Overview of the arena layout for circle radiuses: rred= 5
and rgreen= 5.
ration, the robots will try to estimate the capacity of each option by picking a random value from a normal distribu-tion, where the mean µ is equal to the true capacity of the option, and the standard deviation σ = 20. For each op-tion, the robot will collect all of its estimations in a vector, of which the average value will be the robot’s final estimate of the capacity.
When the robots are in the nest, they will now com-municate their allocation and estimated capacities, in the hopes that robots can derive whether the current distribu-tion of robots among the opdistribu-tions requires them to switch their allocation. In addition to this information, they will also communicate how many of its neighbours have chosen each task.
On the receiving end, a robot will count the number of
90, 30, 90 12 18 99.5% 30, 60, 120 10 20 99% 30, 120, 60 19 11 78% 60, 30, 120 9 21 95.5% 60, 120, 30 16 14 43% 120, 30, 60 11 19 100% 120, 60, 30 9 21 94.5% 105, 105, 0 5 25 13.5% 105, 0, 105 10 20 91.5% 0, 105, 105 18 12 98% 210, 0, 0 0 210 99.5% 0, 210, 0 0 210 0% 0, 0, 210 0 210 1% TABLE VII
Accuracy of the decision making of the distance based model for different swarm compositions (objective, under, over). For each colour, the amount of times consensus was
reached on this colour is shown for 30 experiment runs.
neighbours that are allocated to each task. It will also collect all non-zero capacity estimations for each option, and take the average of them. These average capacities will become its new estimations on the capacities of the corresponding tasks. Finally, it will store the amount of neighbours per option each of its own neighbours has in a map. Every m time steps, the robot will try to make a de-cision based on the collected data. The robot will calculate the average ratio:
R : G = 1 N N ∑ i=1 Ri+ 1 Gi+ 1 ,
with Riand Githe amount of robots in the neighbourhood of robot i allocated to red and green respectively, and N the size of the robot’s own neighbourhood. If R : G >
Cred: Cgreen, with Credand Cgreenthat robot’s estimated capacity of the red and green task respectively, the average red to green ratio is too high and the red option needs less robots. If R : G < Cred : Cgreen, green is overcrowded. We want the chance to switch allocation to be influenced by the subjectivity, so we will calculate the chance for a robot to switch to its preferred task as the sum of personal preference P P and a social component SC:
Pswitch= P
(t)
commit= P P± SC, with
P P = Pcommit(t−1) ,
and t the current time. The chance to switch to an option that is not preferred will be 1− Pcommit. If the option was preferred, we use P P +SC, otherwise we use P P−SC. By
SC = 1− 1
1 +|R : G − Cred: Cgreen|
α,
with a scaling factor α. The parameters that we will use in our specialisation experiments are shown in table VIII.
Estimation interval n 20 Initial Pcommit for OP 0.8 Commitment treshold 20 Capacity estimation stddev 20 Decision interval m 200 SC scaling factor α 0.2 Red capacity 1 3 of swarm size Green capacity 2 3 of swarm size TABLE VIII
Parameter values for the specialisation model.
D. Results
D.1 Aggregation model
For the aggregation model, we have looked at the dis-tribution of the swarm among the two tasks, for different task sizes. The results we gathered by running the experi-ment for different task radiuses rred and rgreen are shown in table IX. The capacities 1
3 and 2
3 that we will be using
for the red and green tasks in the specialisation experiment come closest in the aggregation experiment with rred= 2 and rgreen = 7, where 25 robots aggregated on red, and 55 on green. The high amount of unallocated robots could be explained by robots blocking the perimeter of the task sites.
rred rgreen Red Green Unallocated 5 5 43.5% 43% 13.5% 3 6 33.5% 49% 17.5% 2 7 25% 55% 20%
TABLE IX
Comparison of the average amount (rounded to the nearest half) of robots allocated to each colour for the aggregation model between different task site radiuses.
D.2 Specialisation model without communication
We will not be using different task radiuses with the specialisation model, as we noticed that it was too hard for robots to explore a small task site, which caused robots to pick the task that it does not prefer far too often. This is not what we want, since we can not study the subjectiv-ity this way. The capacsubjectiv-ity is now merely a number that the robots can measure. The results for running this
ex-the swarm correctly among ex-the options. 10%− 15% of the
robots will pick the option that they do not prefer. These robots have probably spent more time on the option site of the task they do not prefer, or have been unlucky when rolling for their commitment chance.
Composition Red Green P NP U 50%, 50% 50.5% 49% 85% 14.5% 0.5% 70%, 30% 67% 33% 86.5% 13.5% 0% 30%, 70% 34.5% 66.5% 85% 14.5% 0.5% 100%, 0% 92.5% 7.5% 92.5% 7.5% 0% 0%, 100% 9% 90.5% 90.5% 9% 0.5% TABLE X
Comparison of the average amount (rounded to the nearest half) of robots allocated to each colour for the specialisation model without communication between different swarm compositions (red, green). P, NP, and U are
abbreviations for the preferred task, the non-preferred task, and the number of unallocated robots respectively.
D.3 Specialisation model with communication
The results for the specialisation model with communi-cation are shown in table XI. We can see that our commu-nication model works pretty good. The distribution of the robots comes very close to the capacity of the tasks. There still seems to be a small bias towards the green task, which could possibly be explained by the fact that the robots have to base their information on a lot of approximations and local observations.
Composition Red Green P NP U 50%, 50% 30% 69.5% 58% 41.5% 0.5% 70%, 30% 27.5% 72% 46.5% 53% 0% 30%, 70% 30% 69.5% 65% 34.5% 0.5% 100%, 0% 28% 72% 28% 72% 0% 0%, 100% 29.5% 70% 70% 29.5% 0.5% TABLE XI
Comparison of the average amount (rounded to the nearest half) of robots allocated to each colour for the specialisation model with communication between different
swarm compositions (red, green). P, NP, and U are abbreviations for the preferred task, the non-preferred task, and the number of unallocated robots respectively.
VI. Conclusion
In the first part of our study we noticed that subjec-tivity can very badly affect the consensus that the swarm
and interactions between the robots.
We still have an issue where low estimates disappear and only competitive estimates survive, which makes it very hard for the robots to find the best option. We think this can be solved by not updating both values every time, or by integrating a history of previous values into the decision making process. Due to this problem, the weighted model did not always improve upon the base model. However, some swarm compositions already had promising results. We also learned that the parameter k can lead to errors and should not be used.
In the end we did manage to find a way to mitigate the errors introduced by the biased robots, by removing parameter k from the experiment and using weight 0 for subjective robots, proving that it is possible to have a per-fect decision making model with subjective robots.
In part two we discovered that allocation was mainly driven by the subjectivity of the robots. We created a communication model that proved to be very good at cop-ing with the subjectivity, effectively makcop-ing robots perform the task they ’like’ less more often in order to distribute the robots better between the tasks. There was still a little bias towards one option, however.
A. Future work
In addition to solving the known problems, we will pro-pose some other interesting avenues to further explore sub-jectivity in collective decision making.
We propose a model that tries to classify the subjectiv-ity of opinions instead of robots, leading to more precise weighting of each opinion.
Another weighting mechanism could be used, like the amount of time a robot spends communicating [9], or the range of its communication.
The robots could also try to become objective, by com-paring themselves to other opinions, and moving their
δsubjective towards δaccurate over time. This would make them better at estimating options in the future as well.
The specialisation experiment could be redefined to use expertise instead of affection as subjectivity. In this sce-nario, the robots will all be objective at the start, and become more skilled at an option as their commitment in-creases. Some robots could then become experts, whose opinion about that task becomes more valuable. This could also be used in leadership selection.
12 2016.
[2] Carlo Pinciroli, Vito Trianni, Rehan O’Grady, Giovanni Pini, Arne Brutschy, Manuele Brambilla, Nithin Mathews, Eliseo Fer-rante, Gianni Di Caro, Frederick Ducatelle, Timothy Stirling, Álvaro Gutiérrez, Luca Maria Gambardella, and Marco Dorigo, “ARGoS: a modular, multi-engine simulator for heterogeneous swarm robotics,” in Proceedings of the IEEE/RSJ International
Conference on Intelligent Robots and Systems (IROS 2011), pp.
5027–5034. IEEE Computer Society Press, Los Alamitos, CA, 9 2011.
[3] M. Bonani, V. Longchamp, S. Magnenat, P. Rétornaz, D. Burnier, G. Roulet, F. Vaussard, H. Bleuler, and F. Mondada, “The marxbot, a miniature mobile robot opening new perspectives for the collective-robotic research,” in 2010 IEEE/RSJ International
Conference on Intelligent Robots and Systems, 10 2010, pp. 4187–
4193.
[4] Plotly Technologies Inc., “Collaborative data science,” 2015. [5] Gabriele Valentini, Eliseo Ferrante, and Marco Dorigo, “The
best-of-n problem in robot swarms: Formalization, state of the art, and novel perspectives,” Frontiers in Robotics and AI, vol. 4, pp. 9, 2017.
[6] Serge Galam, “Majority rule, hierarchical structures, and demo-cratic totalitarianism: A statistical approach,” Journal of
Math-ematical Psychology, vol. 30, no. 4, pp. 426 – 434, 1986.
[7] J. A. Hartigan and M. A. Wong, “Algorithm as 136: A k-means clustering algorithm,” Journal of the Royal Statistical Society.
Series C (Applied Statistics), vol. 28, no. 1, pp. 100–108, 1979.
[8] Martin Ester, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu, “A based algorithm for discovering clusters a density-based algorithm for discovering clusters in large spatial databases with noise,” in Proceedings of the Second International
Confer-ence on Knowledge Discovery and Data Mining. 1996, KDD’96,
pp. 226–231, AAAI Press.
[9] Gabriele Valentini, Heiko Hamann, and Marco Dorigo, “Self-organized collective decision making: The weighted voter model,” 01 2014, vol. 1.
1 Introduction 1
1.1 Goal . . . 2
1.2 Thesis layout . . . 3
2 Subjectivity 5 2.1 What is subjectivity? . . . 5
2.2 Subjectivity in this work . . . 6
2.2.1 Biased agents . . . 6
2.2.2 Specialisation . . . 6
3 Preliminary experimentation 7 3.1 Working environment . . . 8
3.1.1 Simulator . . . 8
3.1.2 Robots & components . . . 8
3.1.3 Running the experiments . . . 11
3.2 Introductory challenge . . . 11 3.2.1 Problem . . . 12 3.2.2 Controller model . . . 12 3.2.3 Final remarks . . . 15 3.3 First attempt . . . 18 3.3.1 Setup . . . 18
3.3.2 Controller model . . . 20
3.3.3 Moving on . . . 25
4 Subjectivity in biased agents 26 4.1 Goal . . . 27
4.2 Simple base model . . . 29
4.2.1 Parameters . . . 30
4.3 Weighted models . . . 34
4.3.1 Distance based model . . . 35
4.3.2 Models based on reconstructing the Gaussian distribution . . . 37
4.4 Results . . . 42
4.4.1 Weighted models comparison . . . 42
4.4.2 Green option objective only . . . 43
4.4.3 Green option subjective . . . 46
4.4.4 Error-free solution . . . 54 4.4.5 Conclusion . . . 54 5 Specialisation 57 5.1 Setup . . . 58 5.1.1 Goal . . . 58 5.1.2 Arena layout . . . 59 5.2 Controller model . . . 61 5.2.1 Aggregation model . . . 61
5.2.2 Base specialisation model . . . 64
5.2.3 Model with communication . . . 65
5.2.4 Parameters . . . 68
5.3 Results . . . 71
5.3.1 Aggregation model . . . 71
5.3.3 Specialisation with social component . . . 74 5.3.4 Conclusion . . . 80 6 Conclusion 82 6.1 Biased agents . . . 82 6.2 Specialisation . . . 83 6.3 Future work . . . 84
3.1 Overview of the introductory challenge arena layout. . . 16
3.2 Robot behaviour described as a finite state machine. . . 17
3.3 Overview of the arena layout. . . 20
3.4 Robot behaviour described as a finite state machine. . . 21
3.5 Overview of the normal distributions that are sampled from when estimating an option. This is for the case when subjectivity is only activated for the red option. . . 23
4.1 Overview of the normal distributions that are sampled from when estimating an option. This is for the case when subjectivity is activated for both options. . . 28
4.2 Robot behaviour described as a finite state machine. . . 31
4.3 A comparison between different combinations of the equal opinion error margin ϵ and Nmin parameters. Each graph depicts the amount of experiments ending in consensus for each colour. These results have been gathered from the base model for swarm composition: objective = 70 robots, underestimating = 70 robots and overestimating = 70 robots. . . 32
4.4 A comparison between different combinations of the equal opinion error margin ϵ and Nmin parameters. Each graph depicts the amount of experiments ending in consensus for each colour. These results have been gathered from the base model for swarm composition: objective = 70 robots, underestimating = 70 robots and overestimating = 70 robots. . . 33
4.5 Speed and accuracy of the base model for swarm composition: objective = 70, underestimating = 70, overestimating = 70 with green objective. . . 45
4.6 Speed and accuracy of the distance based model for swarm composition: objective = 70,
underestimating = 70, overestimating = 70 with green objective. . . 47
4.7 Speed and accuracy of the base model for swarm composition: objective = 70, underestimating = 70, overestimating = 70 with green subjective. . . 49
4.8 Speed and accuracy of the distance based model for swarm composition: objective = 70, underestimating = 70, overestimating = 70 with green subjective. . . 52
4.9 Speed and accuracy of the distance based model for swarm composition: objective = 70, underestimating = 70, overestimating = 70 with green objective. . . 55
5.1 Overview of the arena layout for different option sizes. . . 60
5.2 Robot behaviour of the aggregation model described as a finite state machine. . . 62
5.3 Robot behaviour of the specialisation model described as a finite state machine. . . 65
5.4 Comparison of the same specialisation experiment with different circle radiuses. . . 70
5.5 Aggregation results for circle radiuses rred= 5& rgreen = 5and rred= 3& rgreen = 6. . 72
5.6 Average progress and standard deviation of the aggregation model with rred = 2 and rgreen = 7. . . 73
5.7 Specialisation without communication model results for swarm compositions: 50% preferring red, 50% preferring green and 70% preferring red, 30% preferring green. . . 75
5.8 Specialisation without communication model results for swarm compositions: 30% preferring red, 70% preferring green and 100% preferring red, 0% preferring green. . . 76
5.9 Average progress and standard deviation of the specialisation model without communication with swarm composition: 0% preferring red, 100% preferring green. . . 77
5.10 Specialisation with communication model results for swarm compositions: 50% preferring red, 50% preferring green and 70% preferring red, 30% preferring green. . . 78
5.11 Specialisation with communication model results for swarm compositions: 30% preferring red, 70% preferring green and 100% preferring red, 0% preferring green. . . 79
5.12 Average progress and standard deviation of the specialisation model with communication with swarm composition: 0% preferring red, 100% preferring green. . . 80
3.1 Parameter values for the introductory challenge. . . 14 4.1 Parameter values for the models used in the biased agents experiments. . . 31 4.2 Model specific parameter values used to generate the experiments for the distance based model. 37 4.3 Classification accuracy of the distance based model for different swarm compositions
(rounded to the nearest half). . . 38 4.4 Model specific parameter values used to generate the experiments for the k-means model. . 39 4.5 Classification accuracy of the k-means model for different swarm compositions (rounded to
the nearest half). . . 40 4.6 Model specific parameter values used to generate the experiments for the DBSCAN model. . . 41 4.7 Classification accuracy of the DBSCAN model for different swarm compositions (rounded to
the nearest half). . . 42 4.8 Comparison of the classification accuracy between the different weighted models for different
swarm compositions with green objective (rounded to the nearest half). . . 43 4.9 Accuracy of the decision making of the base model for different swarm compositions with
green objective. . . 44 4.10 Accuracy of the decision making of the distance based model for different swarm compositions
with green objective (rounded to the nearest half). . . 48 4.11 Accuracy of the decision making of the base model for different swarm compositions with
4.12 Accuracy of the decision making of the distance based model for different swarm compositions with green subjective (rounded to the nearest half). . . 53 5.1 Parameter values for the aggregation model. . . 63 5.2 Parameter values for the specialisation model. . . 69 5.3 Comparison of the average amount (rounded to the nearest half) of robots allocated to each
colour for the aggregation model between different task site radiuses. . . 71 5.4 Comparison of the average amount (rounded to the nearest half) of robots allocated to
each colour for the specialisation model without communication between different swarm compositions. . . 74 5.5 Comparison of the average amount (rounded to the nearest half) of robots allocated to each
colour for the specialisation model with communication between different swarm compositions. 81 5.6 Comparison of the average final values (rounded to the nearest half) between the
specialisation experiments without communication and the specialisation experiments with communication for different swarm compositions. . . 81
Introduction
The field of research known as swarm robotics studies how a large group of autonomous agents (robots) has the ability to achieve coordinated behaviour with the entire group (macroscopic level) through individual decisions made by the group’s members (microscopic level). We call a system with this characteristic self-organising [2]. The collective tasks accomplished by such a swarm of robots are usually performed more efficiently in group, or are outright impossible to be accomplished by an individual robot alone. These robots are usually small and simple, but can often achieve far greater things in group than a more complex robot by itself [3, 11].
A swarm robotics system is decentralised, which means that there is no central control unit or global state. Interaction and communication happens on a local level. This leads to a couple of characteristics that make swarm robotic systems such an attractive approach to collective robotics: (i) robustness: due to the redundancy of its units, the decentralised coordination of the swarm, and the simplicity of the individuals, the system will continue to operate when one or more robots fail, or when there are disturbances in the environment; (ii) scalability: since only the individual behaviour needs to be modeled, the control architecture remains the same regardless of the size of the swarm; (iii) flexibility: robots can dynamically be added or removed from the group without issue, they can reallocate and redistribute themselves when needed, and have the ability to generate modularised solutions to different tasks [19, 25].
In swarm robotics, the behaviour is inspired by the collective behaviour observed in nature. Examples include flocks of birds, schools of fish and social insects like ants, termites and bees [4]. A wide variety of tasks has been studied already, including:
• Aggregation: the task of gathering in a common place.
• Flocking: moving towards a common target location in group, a behaviour observed in many bird species. • Foraging: exploitation of food sources, inspired by ant colonies.
• Object manipulation: transportation of items, pulling items, etc.
• Collective decision making: unanimously choosing an option with the swarm.
A survey on the most common tasks, and their solutions, in swarm robotics can be found in [3].
One could argue that human society also displays traces of swarm intelligence, as humans make decisions out of self-interest and behave in a distributed manner, while still allowing civilisation to grow and thrive [26, 27]. Most decisions made by humans will in fact be influenced by their local neighbourhood [1] and people will often group together to achieve greater things. Obviously, there is plenty of differences as well. While agents in a swarm are mostly the same (even a heterogeneous swarm will usually consist of homogeneous subgroups), human society is very heterogeneous (no two humans are the same) and humans are very complex agents. Even though there are differences, it would still be interesting to investigate what happens when human characteristics are implemented in swarm robotics.
1.1 Goal
In this thesis we want to research subjectivity in swarm robotics. When estimating the value of a resource or when determining the time, cost or effort needed to perform a task, most humans will base their evaluation on a combination of personal experience, influencing factors in their neighbourhood and objective data. Very often, a human estimation is little more than an (un)educated guess. This results in a high level of subjectivity in the decision making process of humans.
We will try to investigate the effects that subjectivity can have on the decision making process of the swarm. We do this by adding robots with subjective opinions to the swarm. These robots will underestimate and overestimate the values of options they are exploring. These options are sites in the environment that represent some task or resource with a certain value. This value can be seen as the cost of the task (e.g., time) or the quality of the resource. We will monitor how choices made by the swarm are affected by the presence of subjective robots. It is important to note that we are not researching general errors in robot opinions. Instead, we are looking at a specific case of opinion error where there is no degree in the size of the errors, and the objective value (which is free of errors) is always the middle value. This means that all underestimating (overestimating) robots will have an error of the same magnitude, and that there is a presence of both an error lower and an error higher than the error-free objective value. Our research will be split into 2 parts. Part 1 deals with robots that have biased opinions. In part 2 we consider subjectivity as a form of specialisation.
1.2 Thesis layout
First, we will take a look at what subjectivity is. We will focus on this in chapter 2. We will start by discussing the concept of subjectivity in the psychological sense. This is subjectivity in nature, as it occurs in human decision making. Afterwards we will take a look at subjectivity in the context of this thesis. We will define two different approaches to subjectivity that we would like to explore.
In chapter 3 we will take a look at the preliminary experimentation that we have done before starting our work on the actual research. We begin with an overview of the environment setup and tools we used for our experimentation. Next, we discuss a first exercise experiment and what we learned from it. We finish the chapter with our preliminary attempt at our study on subjectivity in biased robot agents. This the first experimentation we conducted for that part of the thesis, but this was not very successful. For this reason we decided to change some things and redefine our experiment.
Chapter 4 is all about the first part of our study, in which we look at robots with biased opinions, as explained in subsection 2.2.1. We explore the effects of this on the consensus achievement abilities of the swarm and ultimately try to find ways for the swarm to cope with the subjectivity. We discuss the experiments we conducted, and the results we gathered from them.
After we have dealt with part one of our research, we will continue with the second part in chapter 5. In this part we investigate subjectivity as a form of specialisation, as explained in subsection 2.2.2. As with the first part of this research, we will go into detail about our experiments, and reflect on the results.
Subjectivity
In this chapter we will define what subjectivity is. We will start by looking at subjectivity in psychology. Afterwards we will define how we will utilise subjectivity in this thesis. We need to translate the psychological subjectivity we see in human decision making to a definition that can be used in swarm robotics. We will do this in two different ways.
2.1 What is subjectivity?
Human judgment is prone to errors, due to a mixture of personal experience, social influence, cultural background, poor estimation, and much more. Whenever a personal perspective, feeling or opinion is influencing the decision making process, we call the decision subjective. This is in contrast to an objective decision, which is free of subjective perspectives and is purely rational and based on facts.
Such an error of judgment is called a cognitive bias in psychology. They happen because humans tend to use cognitive short cuts when making decisions. A summary of the most common cognitive short cuts and the resulting biases can be found in [12].
2.2
Subjectivity in this work
Since robots do not base their decisions on beliefs or other personal attributes, we need to define subjectivity in a way that makes sense in this context. In this thesis, we will look at two different approaches for subjectivity.
2.2.1 Biased agents
In the first part of this thesis we will work with subjectivity as a function of the individual. In this context, subjectivity can be seen as some sort of error in the judgment of the robot. Since this bias is a function of the individual, it is independent of the option that is being estimated: an underestimating (overestimating) robot will always underestimate (overestimate) every option it evaluates. The robot itself is biased. As mentioned in section 1.1, we are not looking at estimation errors in general. In our case, there is no gradation to the bias, and objectivity is always the middle value, surrounded by underestimation and overestimation.
With this model of subjectivity, we want to look at the decision making process of the swarm. We want to see whether consensus can be achieved under the presence of these subjective robots, and most importantly how it affects the speed and accuracy of the decision making.
2.2.2
Specialisation
In general, humans have a tendency of preferring a certain option over another because they like it more. This emotional aspect of subjectivity in the decision making process is what we like to study in the second part of our research. In this case, the subjectivity is dependent of the option that is being evaluated. Each robot will ’like’ one option more than others, which it will more likely choose, regardless of the quality of the options. We will call this type of subjectivity specialisation.
We want to investigate how this type of subjectivity can affect the way each individual assigns itself to a task. This means we are not necessarily studying the ability to achieve consensus, or even decision making in itself. However, we will briefly investigate the impact a social component can have on convincing a robot to abandon their choice in order to make a more meaningful choice for the group.
Preliminary experimentation
In this chapter we will look into some of the preliminary experimentation that we have done before we moved on to the actual experiments, which will be discussed in the following chapters.
First, we will briefly discuss our working environment in section 3.1. This environment will stay the same for the remainder of this thesis. Afterwards, we will talk about the experiments themselves.
The first experiment was created with the aim of getting acquainted with the software environment and with swarm robotics itself. It started off with very simple features. These include basic swarm robotics tasks like movement and diffusion, but the experiment grew iteratively with more and more features. Ultimately, we wanted the swarm in this experiment to solve a little challenge exercise that is related to the thesis subject. We will go into detail about this first experiment and the challenge it tries to solve in section 3.2.
The next experiment was our first attempt at investigating subjectivity in biased robots, as previously discussed in subsection 2.2.1. In section 3.3, we will review the experiment setup and elaborate on why we chose to move on from this experiment to the final work discussed in chapter 4.
3.1
Working environment
In this section we will take a look at the choices that were made in regard to the working environment, and discuss why we made these choices. It is important to take things like programming languages, libraries, software tools, etc., into consideration before starting the research.
3.1.1 Simulator
Swarm robotics can be implemented using real robotics, or simulated using computer software. The latter is more useful for scientific research, because it is cheaper and easier to implement. We have chosen to work with the ARGoS Simulator, an open source multi-robot simulator. It is especially useful in large heterogeneous swarms of robots, and has a focus on both flexibility (the possibility to add new features like robot types) and efficiency (the ability to provide satisfactory run-time performance). Most other simulators fall short on one of these traits, so ARGoS is the best choice we can make [22]. Since the simulator is inherently multi-threaded, it is also very useful for faster experiment evaluation.
Another reason to choose a simulator above using real robots is the high amount of robots that are needed in order to get good results. We plan on using a couple hundreds of robots in our experiments, and it is cheaper if we do not need to buy that many physical robots. It is also a lot faster to run a simulation than it is to run the experiment in real time. Results reported in [21] show that ARGoS can simulate 10 000 simple robots 40% faster than real time. Finally, it would be much harder to collect results from the experiment when using physical robots.
The ARGoS Simulator was written in C++, and runs under Linux and Mac OS X. We developed all experiments on an Ubuntu distribution of Linux.
3.1.2
Robots & components
Robot typesThere is a plethora of robot types available, so it is important to choose the right one. Here is a non-exhaustive list of the most commonly used robot types and some of their most notable features:
• Kilobot [24]: a small, cheap robot that is widely used. It is capable of movement on flat surfaces, can communicate 9 bytes of information through IR communication, and is equipped with a RGB LED [23]. • E-puck [18]: a small wheeled robot developed for education and research purposes. The E-puck is
equipped with a great arsenal of actuators and sensors, making it a very versatile choice.
• Foot-bot [5]: an autonomous robot specialised for ground movement. Just like the E-puck, this robot is equipped with numerous sensors and actuators. Its communication device is capable of calculating the relative position of the sender from any message it receives. It also has grippers, allowing it to interact with its environment.
• Hand-bot [6]: This robot has no mobility on the ground, but is capable of climbing vertical structures instead. It has the same communication device as the foot-bot. Its dedicated arms also make it a great choice for manipulating objects.
• Eye-bot: The eye-bot is a flying robot, specialised in exploration. It is equipped with cameras that allow it to get an aerial overview of the environment. Its communication device is similar to the one used in the foot-bot and the hand-bot.
The foot-bot, hand-bot, and eye-bot were all created as part of the Swarmanoid project [10], for which the ARGoS simulator was developed as well. This means that these robots have the best integration in the ARGoS simulator, and have plenty of examples readily available. Especially the foot-bot is highly supported by reference material. Since we require ground movement in our experiments and are interested in the decision making process (the communication aspect), the foot-bot seems to be the ideal candidate. In addition, it is stated in [10] that it has enhanced autonomy, short and long range perception, robot-robot and robot-environment interaction, self-assembling abilities and a rich set of devices for sensing and communication, making it an excellent tool for swarm robotics experimentation. For these reasons we have chosen the foot-bot as the robot type we will use for all our experiments.
Footbot components
Now that we have established that we are using the foot-bot and why, we are going to summarise all the foot-bot actuators and sensors that we will be using.
Sensors:
• Range and bearing sensor: This sensor is used to receive messages from other robots. In contrast to most other communication devices, it is also capable of relative positioning, allowing it to pinpoint the position (distance and angle) of the sender of a message in relation to its own position [14].
• Proximity sensor: This is an infrared sensor, which allows the foot-bot to determine how close it is to another robot, an object, or a wall. This is mostly useful for diffusion.
• Light sensor: This sensor can be used to measure light intensity, and can pinpoint the direction towards higher light levels. This is used for phototaxis or anti-phototaxis.
• Motor ground sensor: To allow the robot to determine the ground colour underneath, this sensor can be used to read the light level of the ground. This sensor will be used to identify the nest and option sites. Actuators:
• Differential steering actuator: This can be used to adjust the speed and direction of both wheels. Steering is achieved by rotating both wheels in opposite directions or at different speeds.
• LEDs actuator: This actuator allows changing the colour of the LEDs on the foot-bot. In our experiment this will be used to visualise the robot’s commitment to an option.
• Range and bearing actuator: This is a communication actuator that allows the robot to send messages to its neighbourhood.
3.1.3
Running the experiments
HPC UGentWe developed and tested all of the experiments at home on our laptop. However, a laptop is not capable of fully exploiting the multi-threaded nature of the simulator. Running an experiment would prove to be too slow on such a device, and when collecting results we want to run a multitude of seeds for every experiment. Therefore we deployed our experiments on a node on the high performance computer of the University of Ghent. This way, we could make full use of the computational power of the HPC, and could parallelise the experiment runs using the cluster. Even then, each experiment would still require about 20 to 30 minutes to complete.
For every experiment we conducted, we ran 30 simulations, each using a different seed. From the results of those 30 simulations, we could get a decent understanding of how the swarm behaves on average. We used bash shellscripts to automatically deploy the 30 simulations.
Plotting the results
Once the results were available, we created plots displaying information about the experiment. We generated the plots with a Python script, using the Plotly graphing library [17].
3.2
Introductory challenge
In order to get acquainted to the simulator and to swarm robotics concepts in general, an introductory experiment was proposed. We will first explain the problem we are trying to solve with this experiment in subsection 3.2.1. In subsection 3.2.2, we will then explain how we modelled the robot controllers to solve this task. Finally we will conclude with some final remarks about this first experiment in subsection 3.2.3.
3.2.1 Problem
The problem we are trying to solve is as follows: Two different types of food are scattered around the arena. Each food item has its own value. We can view this value as the freshness of the food item. Every step of the experiment, the food value will drop by 1, until it reaches 0. Once the food value has reached 0, the food is spoiled and will be removed from the arena. Each food type has a different starting value. We colour each type differently, green and red, so it is easy for us to distinguish between both types when observing the simulation.
The swarm is heterogeneous and consists of three types of robot controllers: underestimating robots, overestimating robots, and accurate robots. These robots are supposed to explore the arena, and are able to estimate the value of every food item they come across. A subjective robot (either under- or overestimating) will make a less accurate estimation of the food item than an accurate robot. The underestimating robot will make an estimate lower than the actual value of the food, whilst the overestimating type will make an estimate that is higher than the actual value.
The goal is for the swarm to collect as many food items as possible. In order to do this, they have to collectively decide which food type they want to collect first. This decision can be made in the nest site, an area in the arena where the robots group to communicate. The layout of the arena for this experiment can be seen in figure 3.1. The bottom black area is the nest. The yellow spheres in the bottom are light sources. These can be used by the robots to perform phototaxis and anti-phototaxis, in order to find the nest site, or leave it, respectively. The coloured circles are food items.
3.2.2
Controller model
Now that we have a clear understanding of the problem we are trying to solve, we can proceed to explain the behavioural model of our robots. As this was our very first exercise, we started off with a simple model by adding movement and diffusion to our swarm. Once this was established, we proceeded by iteratively adding more and more features to the robot controller until it was able to solve the problem.
The behaviour of the robots is described in figure 3.2. At the start of the experiment, every robot will be in the ’forage’ state. They will perform anti-phototaxis to leave the nest and will then move around the arena through a random walk [9] in search of food. The experiment loop function has a list of coordinates for every food item. It will check for every robot whether it is standing on a food item. If this is the case, it will make the robot estimate the value of the corresponding food type. To do this, the robot will uniformly generate a value from a given range. We decided to use a range between 10% below and 10% above the actual value of the food type. After this base value is estimated, it will be multiplied by a subjectivity weight. For accurate robots, this subjectivity weight is simply 1. For subjective robots however, this is also a value uniformly picked from a certain range. In the case of underestimating robots, this range is between 0.5 and 1, thus lowering the base value after multiplication. For an overestimating robot, the range lies between 1 and 1.5, causing the base value to become higher.
Every robot will remember the lowest value (and associated food type colour) it has estimated, and will change its LED colours to the corresponding food colour. The tactic we apply here is to collect all the lower valued food first, which is why the robots only have to remember which colour they think has the lowest value. After a set amount of time steps (the exploration time) have expired, a robot will transition to the ’return to nest’ state. In this state, phototaxis will be performed until the robot is in the nest. It uses its ground sensors to identify the nest, which has been coloured black for this purpose. Once the nest has been reached, there are two options. Either communication still has to take place, and the robot will transition to the ’rest’ state, or communication has already taken place and the robot is currently bringing food to the nest. In this case the robot deposits the food to the nest and continues to forage, by transitioning to the ’foraging’ state.
A robot in the ’rest’ state will try to find an empty spot inside the nest and stay there. Once it has found a resting spot it will use its range and bearing actuator to transmit its opinion about which food type it thinks the swarm should collect first. A robot will then change its opinion based on the majority rule [15]: it changes its own opinion to whichever food type is occurring the most in its neighbourhood. Communication will go on for a set amount of steps, the rest time, after which the robots will transition to the ’foraging’ state.
In the ’foraging’ state, a robot will randomly walk around the arena and pick up any food that is of the type they currently prefer to take. Once it has found a food item, it will transition into the ’return to nest’ state to drop the food item off at the nest. Since there is no way of telling how many food items of a certain type are left, there is a chance for a robot to switch opinion. This chance is relative to the amount of time the robot has been foraging without finding its preferred food type. This leads to robots having a higher chance to change opinion when there are less food items of the preferred option left. After a certain treshold has been reached, the chance is 100%.
All chosen experiment parameters can be found in table 3.1. We chose these values by trial and error, but since this experiment was just an introduction to the matter, we did not go to great lengths to optimise these parameters any further.
Red food value 4000
Green food value 2000
Red estimation range 3600 - 4400
Green estimation range 1800 - 2200
Accurate estimation weight range 1.0 - 1.0 Underestimating estimation weight range 0.5 - 1.0 Overestimating estimation weight range 1.0 - 1.5
Exploration time 1000 steps
Resting time 200 steps
Time without food treshold 800 steps Table 3.1: Parameter values for the introductory challenge.
3.2.3 Final remarks
As mentioned in the previous subsection, this experiment only posed as a simple exercise to get acquainted with everything. For this reason we did not try to tweak the parameters and collect results from this. We, however, learned some valuable lessons from this challenge, which will prove to be very useful in the actual research that follows.
Firstly, we did get some good results from the experiment and the chosen parameters. Because we want the robots to collect the lowest valued food first, we would expect the swarm to reach consensus on the green colour, as this is the lowest valued food in our case. Full consensus for green was indeed almost always achieved, even with subjective robots. The biggest reason why this is the case, is that most robots will find both food types during their exploration. Since an underestimating robot will always underestimate every food type, and an overestimating robot will always overestimate every food type, there is a high chance that these subjective robots will still prefer green above red. On average, the swarm would collect about 70% of all the food.
One thing that is noteworthy is that we are interested in researching the collective decision making. This means that the foraging phase is actually redundant. In the subsequent experiments we will limit the behaviour to exploration and decision making, as we are only interested in examining the decision of the swarm.
The fact that the loop function has to check a robot’s coordinates to determine whether it is standing on a food item is also something that needs to be addressed. All robot functionality should be implemented in the robot controller class, and the robot could use their ground sensor to sense food instead.
We felt like the current system of picking a value from an interval, and then multiplying it with a subjectivity weight, was not very good. In subsequent experiments we will use a different system to estimate task values or costs.
Lastly, we learned how to work with the tools we were using, and thanks to this exercise we already had a good framework for our swarm to build upon in further experiments.
3.3
First attempt
After we had finished the introductory challenge, we started working on the first part of our research, where the type of subjectivity is independent of the task that is being evaluated, as explained in section 2.2.1. In this section we will talk about the first version we worked on. In the end, this version was getting too complex, and we were wasting time on minor details. This is why we decided to redefine our experiment, and started working on a simpler version that would prove to be much easier to work with.
Even though we did not end up using this version, we still gained valuable insights from it. We also ended up recycling most of the behaviour from it, so our work on this first version certainly proved to be useful. Because the experiments discussed in chapter 4 are very similar to this first version, we will go into detail on how this first experiment was set up, and how the behavioural model is implemented. Then in the next chapter, we will only discuss the differences between this version and the newer version.
3.3.1 Setup
In the previous section we learned that when a robot has seen all options, it will generally know which option is best. This is the case even when the robot is subjective, due to the fact that the type of subjectivity is independent of the option that is being evaluated. In order to prevent this from happening, we decided to split the arena into three regions. The middle region is the nest site, which is flanked by two option sites. The nest site is a dedicated area for communication, as it is the only place where a robot may communicate their opinions. The option sites represent some option with a set value. This option could represent a task, a resource, or a potential nesting site, but we deliberately do not specify this. All that matters is that it is some sort of option with a value, and we want the robots to decide which option is best. In fact we want the robots to solve a best-of-n problem [28], where n = 2. However, our work should also be applicable to other values of n. The layout of the arena can be seen in figure 3.3.