DUAL ACTIVITY OF PROTEINS WITH A
LECTIN AND A GLYCOSYL
HYDROLASE DOMAIN FROM
ARABIDOPSIS THALIANA
Koen Gistelinck
Student number: 01505464Promotor(s): Prof. dr. Els J.M. Van Damme, Prof. dr. Tom Desmet
Tutor: dr. Koen Beerens
Master’s Dissertation submitted to Ghent University in partial fulfilment of the requirements for the degree of Master of Science in Bioscience Engineering: Cell and Gene Biotechnology
Deze pagina is niet beschikbaar omdat ze persoonsgegevens bevat.
Universiteitsbibliotheek Gent, 2020.
This page is not available because it contains personal information.
Ghent University, Library, 2020.
ACKNOWLEDGEMENTS
First of all, I would like to express my deep gratitude to my promotors Prof. dr. Els Van Damme and Prof. dr. Tom Desmet. They gave me the opportunity to work on a very interesting subject and to experience research work from different perspectives.
I would like to offer my special thanks to my tutors Prof. dr. Els Van Damme and dr. Koen Beerens for their patient guidance, encouragement and useful feedback. They teached me to work independently and gave me advice concerning the topic.
Advice and assistance provided by both research teams inside and outside the meetings was greatly appreciated. I am particularly grateful for the assistance given by dr. ir. Pieter Wytynck, dr. Jeroen Lambin, Simin Chen and Isabel Verbeke. I would also like to thank the other students for contributing to a pleasant working environment.
Finally, I wish to thank my parents, family and friends for their support and encouragement throughout my studies. The five-year study program of the bio-engineers was a rollercoaster with ups- and downs. It was a challenge to get at this stage. I would not have made it this far without the aforementioned people. Therefore I really want to express to them my appreciation and gratitude.
PREAMBLE
During the last months of 2019, a viral epidemic emerged in Wuhan, China. In the first stages the cause was not known. At last the causative agent was identified as a new coronavirus. The acronym of the disease is COVID-19. The infection spread very fast globally (Cascella et al., 2020). In the early stages, Belgium and other European countries did not have any cases of COVID-19. However, in the beginning of February 2020 the first corona infections were confirmed. In March, the Belgian government moved into a federal phase of lockdown. In the setting of my thesis research, all experiments were stopped on the 19th of March, following to a decision taken by the University of
Ghent.
The initial objective of the thesis was to clone the sequences of AT1G13130 and AT3G26140 and to express the recombinant proteins in E. coli. Afterwards the specificity of the proteins encoded by AT1G13130 and AT3G26140 could be tested using different types of carbohydrate binding assays. In parallel overexpression lines for AT1G13130 and AT3G26140 were to be created in Arabidopsis
thaliana and their overexpression level should be determined. These transgenic lines could have
been the starting point for some stress experiments.
Due to the corona pandemic, most experiments were ceased, suddenly. Because of these drastic but necessary changes, our initial goals could not be met. Constructs for expression of proteins encoded by AT1G13130 and AT3G26140 in E. coli were successfully cloned. A few initial attempts were made to produce the recombinant proteins. Due to the lockdown, no further experiments could be performed. Overexpression lines for AT3G26140 in A. thaliana were made and transgenic lines were selected. Unfortunately, the transgenic overexpression lines for AT1G13130 were not obtained yet. Thanks to Isabel Verbeke, a new floral dip experiment was finished.
Once the wet lab experiments were no longer possible, alternatives were searched to replace the experimental work in the master thesis. In consultation with the supervisors it was decided that the data from the initial research experiments could be complemented with some in silico analysis and a more elaborate discussion. A detailed analysis was made for the available information related to gene and protein sequences for AT1G13130 and AT3G26140 in different databases. In addition a more extended discussion including ample ideas for future research is written.
It saddens me that our initial goals for the experimental part of the thesis could not be met. But I am confident that these preliminary data can be the starting point for future research.
This preamble was drawn in consultation between the student and the supervisors, and was approved by all parties.
TABLE OF CONTENTS
Acknowledgements Preamble Table of contents List of abbreviations 1 Abstract 2 Samenvatting 4 1 Introduction 6 2 Literature study 8 2.1 Carbohydrates 8 2.2 Lectins 8 2.3 Glycoside hydrolases 11 2.4 Multi-domain proteins 162.5 Heterologous protein expression 19
2.6 Research objectives 20
3 Materials and methods 21
3.1 In silico analysis 21 3.2 Plant section 21 3.3 E. coli section 26 4 Results 30 4.1 In silico analysis 30 4.2 Plant section 37 4.3 E. coli section 42 5 Discussion 46 5.1 In silico analysis 46 5.2 Plant section 47 5.3 E. coli section 48
6 Future perspectives 50
6.1 Plant section 50
6.2 Heterologous protein expression 52
7 Conclusion 54
References 55
Appendix 63
LIST OF ABBREVIATIONS
ABA abscisic acid
BAR Bio-Analytic for Plant Biology
CAZymes carbohydrate active enzymes
CBM carbohydrate-binding module
cDNA copy DNA
CDS coding DNA sequence
CE carbohydrate esterase
ColonyPCR colony polymerase chain reaction
DAMP damage-associated molecular pattern
DDS drug delivery system
DNA deoxyribonucleic acid
EC enzyme commission
EDTA ethylenediaminetetraacetic acid
ERT enzyme replacement therapy
EtBr ethidium bromide
ETSs expressed sequence tags
gDNA genomic DNA
GH glycosyl hydrolase
GH5-11 GH family 5 subfamily 11
GRAS generally recognized as safe
IPTG isopropyl-ß-D -thiogalactopyranoside
LB lysogeny broth
LSD lysosomal storage disorders
mRNA messenger RNA
MS Murashige and Skoog medium
OD optical density
PAMP pathogen-associated molecular pattern
pI iso-electric point
PL polysaccharide lyase
PMSF phenylmethylsulfonyl fluoride
PR pathogenesis-related
PVDF polyvinylidene fluoride
RIP ribosome inactivating protein
RNA ribonucleic acid
SDS-PAGE sodium dodecyl sulphate polyacrylamide gel electrophoresis TAIR The Arabidopsis Information Resource
TEMED N,N,N',N'-tetramethylethylenediamine
TIM triosephosphate isomerase
UTR untranslated region
YEB yeast extract beef
ABSTRACT
Previous research has focussed on the glycosyl hydrolase and lectin activity of individual proteins. In this thesis we aimed to elucidate the activity and the biological role of two-domain proteins from
Arabidopsis, encoded by AT1G13130 and AT3G26140. These proteins are composed of a glycosyl
hydrolase as well as a lectin domain and are hypothesized to have both glycosyl hydrolase activity and carbohydrate binding properties. The goal of this thesis was (a) to perform an in silico analysis of the gene and the protein sequences of interest, (b) to create overexpression lines for AT1G13130 and AT3G26140 in A. thaliana and (c) to examine the heterologous expression of these proteins in
Escherichia coli.
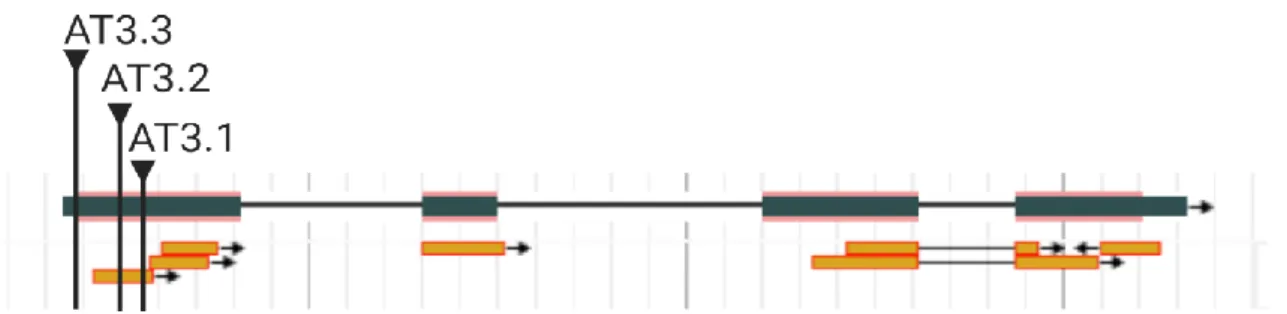
In the in silico analysis, genome, transcriptome and proteome databases were consulted for information related to the sequences AT1G13130 and AT3G26140. The genomic design, expression patterns at cell and tissue level, changes in expression after treating plants with biotic and abiotic stresses and possible protein modifications were acquired from these databases and online tools. The in silico analysis predicted three possible transcripts for AT3G26140. The occurrence of the different transcripts in abscisic acid induced seedlings was analysed by performing polymerase chain reaction (PCR). To determine the biological function of the proteins, overexpression lines were made in Arabidopsis thaliana. The transformation of the A. thaliana plants was done by floral dip using
Agrobacterium tumefaciens C58C1 pMP90.
To elucidate the activity and specificity of the two two-domain proteins, these proteins have to be purified in order to perform activity assays. Heterologous expression of the proteins encoded by AT1G13130 and AT3G26140.1 in E. coli BL21-AI was performed and protein patterns were analysed under multiple growth and induction conditions.
This thesis forms the basis for the elucidation of the biological role of the proteins encoded by AT1G13130 and AT3G26140 in A. thaliana.
SAMENVATTING
Eiwitten met glycosyl hydrolase- of lectine-activiteit werden in voorgaand onderzoek in detail bestudeerd. Deze studie stelt tot doel de activiteit en biologische rol te onderzoeken van twee-domein eiwitten Arabidopsis thaliana, gecodeerd door AT1G13130 en AT3G26140. Deze eiwitten bevatten zowel een glycosyl hydrolase als een lectine domein, en worden verondersteld zowel glycosyl hydrolase als suikerbindende eigenschappen te bezitten. Deze masterproef wordt onderverdeeld in (a) een in silico analyse omtrent de gen- en eiwitsequenties, (b) experimenten met als doel overexpressielijnen voor AT1G13130 en AT3G26140 te creëren in Arabidopsis thaliana en (c) de heterologe expressie van deze proteïnen uit te voeren in Escherichia coli.
In de in silico studie worden verschillende genoom, transcriptoom en eiwit-databanken geraadpleegd om meer informatie te verkrijgen over de sequenties AT1G13130 en AT3G26140. Meer specifiek, worden de opbouw van de genen, de expressieprofielen in de cel en in verschillende weefsels, genexpressie-veranderingen na behandeling van planten met verschillende biotische en abiotische stressoren en mogelijke eiwitmodificaties besproken.
In deze analyse werden drie verschillende transcripten voor AT3G26140 aangetoond. Aan de hand van ‘polymerase chain reaction’ (PCR), werd het voorkomen van de transcripten van AT3G26140 nagegaan in abscisinezuur-behandelde Arabidopsis-planten. De aanmaak van A. thaliana overexpressielijnen kan bijdragen tot het bepalen van de biologische functie van de eiwitten. Voor het transformeren van de A. thaliana planten werd ‘floral dip’ met Agrobacterium tumefaciens C58C1 pMP90 uitgevoerd, waarna transgene lijnen werden geselecteerd.
De multi-domein eiwitten, gecodeerd door AT1G13130 en AT3G26140, dienen onderworpen te worden aan activiteitanalyses om de activiteit en specificiteit van de twee eiwitdomeinen te bepalen. Daarom werd heterologe expressie van de eiwitten, gecodeerd door AT1G13130 en AT3G26140.1, uitgevoerd in E. coli BL21-AI en werd de eiwitproductie bij verschillende groei- en inductie- omstandigheden bestudeerd.
Deze thesis vormt de basis voor het onderzoek naar de biologische functie van de eiwitten gecodeerd door AT1G13130 en AT3G26140 in A. thaliana.
1 INTRODUCTION
The availability of completely sequenced genomes provides researchers the possibility to explore new aspects of genome biology and evolution through comparative analysis. In the search of new lectins in 38 plant genomes, researchers retrieved a vast majority of lectin sequences that encoded multiple protein modules. (Van Holle and Van Damme, 2019). This feature is not unique due to the fact that over 70% of all eukaryotic proteins have multiple modules (Han et al., 2007). Protein domains are the units of protein structure, function and even evolution. Domain rearrangement provides an enormous degree of diversity in proteins (Kersting et al., 2012). Multi-domain proteins often have improved features compared to their single-domain counter parts. These features due to inter-domain interactions can be structural stability, new functions, activities, etc. (Vishwanath et al., 2018). In the case of lectin sequences very little is known about the cooperativity of protein domains that compose one lectin.
One of the building blocks of life are carbohydrates and these molecules are crucial for every organism. Carbohydrates play an important role in different biological processes (Aspeborg et al., 2012). Interactions with other biomolecules such as proteins also prove to be important in a variety of mechanisms. Protein-carbohydrate interactions are crucial for a variety of biological mechanisms. Different proteins can interact with carbohydrates such as lectins and Carbohydrate Active enZymes (CAZymes). Lectins are proteins that selectively recognize and bind to specific carbohydrate structures. The interaction of lectins and their ligands is reversible and does not change the structure of the carbohydrate (Lannoo et al., 2014). The latter is often the case for CAZymes, such as glycosyl hydrolases, which perform enzymatic reactions. In the case of glycosyl hydrolases, carbohydrates are degraded by enzymatic catalysis (Gloster, 2012). Both lectins and glycosyl hydrolases (GHs) are involved in biological processes in plants such as development, defence and symbiosis (Cosgrove, 2005; Komath et al., 2006; Minic, 2008). Besides their biological importance, the lectins and glycosyl hydrolases prove to be suitable for applying in medicine. Especially lectins show to be promising as therapeutics.
The multi-domain lectins found during the bioinformatic study of Van Holle and Van Damme (2019) were comprised of unrelated domains including F-box, protein kinase, NB-ARC or glycoside hydrolase domains. The combination of a glycosyl hydrolase and a plant lectin domain was observed in different plant species such as Arabidopsis thaliana and rice. Within the vast majority of A. thaliana genes encoding multi-domain proteins consisting of a GH-domain and a lectin domain, AT1G13130 and AT3G26140 were selected for further study.
2 LITERATURE STUDY
2.1
Carbohydrates
Carbohydrates play an important role in the daily life of every living creature. These biomolecules have several biological functions in organisms whether it is for energy storage, host-pathogen interactions, signal transduction, intracellular trafficking or development (Aspeborg et al., 2012). In general, carbohydrates can be divided into 3 different categories: monosaccharides, oligosaccharides and polysaccharides. Monosaccharides are the simplest form of a carbohydrate. Oligosaccharides and polysaccharides can be hydrolysed into simpler carbohydrate structures. Polysaccharides are in fact repeats of oligosaccharide motifs (Varki and Sharon, 2009). The main characteristics of carbohydrates are the rich diversity of monosaccharides, their structural complexity and the possibility to link carbohydrates through different linkages. Due to these facts carbohydrates occur in different forms ranging from simple linear structures to complex highly branched formations (Aspeborg et al., 2012). Carbohydrates can also be linked with other biomolecules such as proteins and lipids. These glycosylated biomolecules are called glycoconjugates (Bhagavan and Ha, 2011). Organic molecules can also be glycosylated e.g. glucosinolates (Gloster, 2012).
Due to the large diversity of carbohydrate structures and glycoconjugates, a whole collection of proteins is required for the processing and/or recognition of this class of biomolecules. Examples of such proteins are carbohydrate active enzymes (CAZymes) and lectins. CAZymes are enzymes that help in the assembly or the degradation of the glycosides and glycosylated molecules (Lombard et al., 2014). Carbohydrate active enzymes are present in all kingdoms of life but particularly in plants (Ekstrom et al., 2014). CAZymes are composed of different groups of enzymes such as glycosyl transferases, carbohydrate esterases, polysaccharide lyases and glycosyl hydrolases. The glycosyl transferases are very important for the formation of glycosidic linkages, whilst the carbohydrate esterases (CEs), polysaccharide lyases (PLs) and the glycosyl hydrolases (GHs) are mediating the degradation of the carbohydrate structures (Aspeborg et al., 2012; Lombard et al., 2014). Besides the metabolism of carbohydrates, the recognition of carbohydrates is also crucial. This process is mainly mediated by lectins (Vijayan and Chandra, 1999).
2.2
Lectins
Lectins are carbohydrate binding proteins which are ubiquitously distributed in the tree-of-life (Gabius, 1997; Van Holle and Van Damme, 2019). The name ‘lectin’ originates from the Latin word ‘legere’ that means ‘to select’ (Berg et al., 2002). Lectins recognize and bind reversibly to selective carbohydrates (Santos et al., 2014), but they do not show any enzymatic activity as is the case for glycosyl hydrolases. Additionally, immunoglobulins cannot be considered as lectins (Barondes, 1988). The definition of lectins in the article of Barondes (1988) is very restrictive. According to Peumans and Van Damme (1995) plant lectins can be defined as “all plant proteins that possess at least one noncatalytic domain that binds reversibly to a specific mono- or oligosaccharide” (Peumans and Van Damme, 1995). This definition of plant lectins can be generalized for all lectins. Due to this broadened definition, the group of lectins is very heterogeneous. The heterogenicity occurs in the biological activity but also in the function and structure of lectins (Van Holle and Van Damme, 2019).
2.2.1
Classification of plant lectins
Lectins play a role in several processes in plants. The plant lectin families can be classified based on the presence of conserved carbohydrate binding modules. Based on this classification system, there are 12 different plant lectin families: Agaricus bisporus agglutinin homologs, Amaranthins, Class V chitinase homologs, Cyanovirins, Euonymus-related lectins, Galanthus nivalis agglutinin-related lectins, Jacalin-related lectins, Hevein-domain lectins, Legume lectins, lysin motif domain proteins, Nictaba-like lectins and RicinB lectins (Van Damme et al., 2008).
Next to the structural classification, expression patterns can also be used as a criterion to divide the plant lectins giving rise to two classes. The first class contains lectins that are produced constitutively. This kind of lectins are mainly found at high concentrations in specific storage organs, such as seeds and tubers. The other class consists of lectins which are highly expressed during certain biotic or abiotic stresses (De Schutter et al., 2017). In normal conditions these inducible lectins are hard to detect in plants. After applying a certain stress like drought, heat or pathogen attacks, the gene expression increases but the amount of transcripts is still very low. Most of these inducible lectins are located in the nucleus or the cytoplasm where they perform a specific role to cope with the abiotic and biotic stresses (Lannoo and Van Damme, 2010).
2.2.2
Biological importance of lectins
The importance of carbohydrate recognition in biological processes is enormous. Cell-cell adhesion, cell-matrix interaction, enzymatic activity, parasitic infection and immune defence are a few of these crucial recognition events. In most of these events lectins have been implicated to play a role (Komath
et al., 2006). Research is still proceeding to elucidate the biological function of plant lectins and their
potential uses in biotechnology, medical applications, agriculture and more. The function of lectins in plants can be very diverse. As already mentioned, certain plant lectins can be found at high concentrations in specific tissues. These abundant lectins can function as a source of nitrogen after degradation, which is normally the case for storage proteins. It is suggested that these proteins also have a role in protection against pathogen invasion (Peumans and Van Damme, 1995; Komath et al., 2006).
Plant immunity is also attributed to lectins through the perception, recognition and/or destruction of the pathogens. Lectins can detect endogenous and/or exogenous signal molecules, such as damage-associated molecular patterns (DAMPs) and pathogen-damage-associated molecular patterns (PAMPs), respectively (Van Holle and Van Damme, 2018). Additionally, some lectins can destroy the threat due to their toxicity (Peumans and Van Damme, 1995). Plant lectins can inhibit the growth and the development of fungi (Dias et al., 2015). In the case of herbivorous insects, lectins can alter the digestive enzyme machinery, cause a drop in fecundity, reduce the growth and the development and even have insecticidal activity (Caccia et al., 2012).
Plant lectins also play a role in symbiosis between microorganisms and their host plant. The recognition of micro-organism-specific carbohydrates by the host plant and vice versa is very important in the early stages of symbiosis and symbiosis itself. Membrane-associated lectins, such as lysin motif receptor-like kinases and lectin receptor-like kinases have been associated with mycorrhizal and root-nodule symbiosis (De Hoff et al., 2009; Van Holle and Van Damme, 2018).
2.2.3
Applications in medicine
Lectins, in general, have the property to recognize and bind sugar complexes with very high specificity. This feature makes them very useful in drug targeting due to their specificity and their resistance to enzymatic degradation. Different cell types express a different plethora of carbohydrates. This can be used in Drug Delivery Systems (DDSs). Drugs decorated with lectins could target specific cells/tissues (Bies et al., 2004). Moreover, the use of lectins in drug targeting could enhance the absorption and bioavailability of poorly absorbable drugs and therapeutic DNA. The use of lectins in glycotargetting DDSs depends on the carbohydrate specificity and the structure of the lectin (Lavín de Juan et al., 2017). There are two different approaches for drug targeting through lectins: direct lectin targeting and reverse lectin targeting (Figure 1). The former utilizes an oligosaccharide moiety bound to the drug which is recognized by the endogenous lectins. Reverse lectin targeting uses exogenous lectins which bind to carbohydrate moieties present on the cell surface (Minko, 2004; Lavín de Juan et al., 2017). Lectins are already applied in the field of drug targeting e.g. for vaccines and for cancer therapy (Bies et al., 2004; Lavín de Juan et al., 2017).
Figure 1: Overview of the different approaches for drug delivery systems based on lectins: A reverse lectin targeting and B direct lectin targeting. (Taken from Lavín de Juan et al. )
Besides the use of lectins to target drugs to specific cells, these proteins have already been used in naturally occurring immune responses. Certain lectins possess antimicrobial, antifungal, antiparasitic and even antiviral properties (Dias et al., 2015; Iordache et al., 2015). A major issue in medicine is antibiotic resistance. The re-emergence of old pathogens due to their newly acquired antibiotic resistance poses a huge threat towards human health. The discovery of lectins with antimicrobial activity and antiparasitic activity can be used in the never-ending war against antibiotic resistance. (Iordache et al., 2015). Mannose-binding lectins, for example, are able to activate proteins which are utilized for the lysis of the micro-organism. In addition, they can increase phagocytosis and can modify the microbial targets (Jack and Turner, 2003).
Many enveloped viruses are decorated with glycoproteins. Antiviral lectins can disturb the interactions between host cells and viral proteins, reducing the viral attachment to the host cells (Ziółkowska and Wlodawer, 2006; Iordache et al., 2015). Several lectins such as cyanovirin and griffithsin are reported to have an inhibitory effect on different viruses e.g. HIV, coronavirus (which causes SARS) and Ebola virus (Ziółkowska and Wlodawer, 2006).
Due to the carbohydrate binding properties of lectins, these proteins prove to be a promising tool for medical use, either for their biocidal effects on pathogens, viruses and parasites or as a drug delivery system.
In the previous sections the use of lectins is mainly discussed but lectins can also be a target in medicine. This is due to the fact that micro-organisms also produce carbohydrate binding proteins. These microbial lectins exploit the cell surface glycans. The carbohydrate-protein interaction is very important for infection and is part of their pathogenicity. The use of derivatives which can be bound by the microbial can prevent infection (Nizet et al., 2017).
2.3
Glycoside hydrolases
The selective degradation of carbohydrates is an important process for energy and cell wall metabolism, and signalling. As a consequence the glycosyl hydrolases (GHs) are a very important group of enzymes because they mediate the selective degradation of carbohydrate structures (Davies and Henrissat, 1995). GHs are enzymes that perform the hydrolysis of glycosidic bonds. The substrate for these enzymes can be either oligosaccharides, polysaccharides, glycoconjugates or glycosylated molecules (Gloster, 2012).
The activity of glycosyl hydrolases is crucial for a lot of organisms, as reflected by the fact that glycosyl transferases and glycoside hydrolases represent 1-3% of an organism’s genome (Davies et
al., 2005). In humans, impaired activity of GHs or the deficiency of certain glycosidases are often
related to diseases like Sandhoff's and Tay-Sachs diseases (Ohtsubo and Marth, 2006). Glycosyl hydrolases are also used in several industrial applications. Cell wall degrading enzymes are applied in biorefining sectors and bioenergy industries (Gilbert et al., 2013).
All enzymes are classified in six classes based on their enzyme activity. Each class is indicated by an enzyme commission (EC) number. Hydrolases get the EC number of 3. Each EC number can be appended by extra digits giving a more detailed description of the enzymatic reaction (Roskoski, 2007). Specifically the EC number of glycosyl hydrolases is EC 3.2.1.x . The first three numbers indicate that the enzymes hydrolyse O-glycosyl linkages whereas the last number indicates the substrate-specificity (Henrissat, 1991).
The organisation of glycosyl hydrolases into families is based on the sequence similarity. This classification resulted in 167 families reported in the CAZY database (Lombard et al., 2014). The members of the same GH family can bind different ligands and/or have different specificities. Members of different GH families can have the same ligand/specificity e.g. cellulases can be found in 11 different GH families (Henrissat et al., 2001). Consequently it is hard to make predictions about the specificity of members from the same GH family.
Enzyme families that share a fold and catalytic machinery are grouped into clans (Aspeborg et al., 2012). There are 18 different clans within the glycosyl hydrolases from GH-A to GH-R (Lombard et al., 2014) These clans are grouped based on a common but very distant ancestor (Aspeborg et al., 2012). Certain GH families can be subdivided into subfamilies, as is the case for GH5, GH13, GH16, GH30 and GH43 (Lombard et al., 2014). This organisation into subfamilies is based on phylogenetic analysis. Clans were grouped based on a distant common ancestor; the subfamilies are divided based on a more recent common ancestor. Similar as in the families, the subfamilies are polyspecific (Aspeborg et al., 2012). This means that subfamilies often have members which have different substrates/specificities and therefore it is very difficult to predict the specificity of the members from the same subfamily (Aspeborg et al., 2012).
2.3.1
Mechanisms of glycosidic hydrolysis
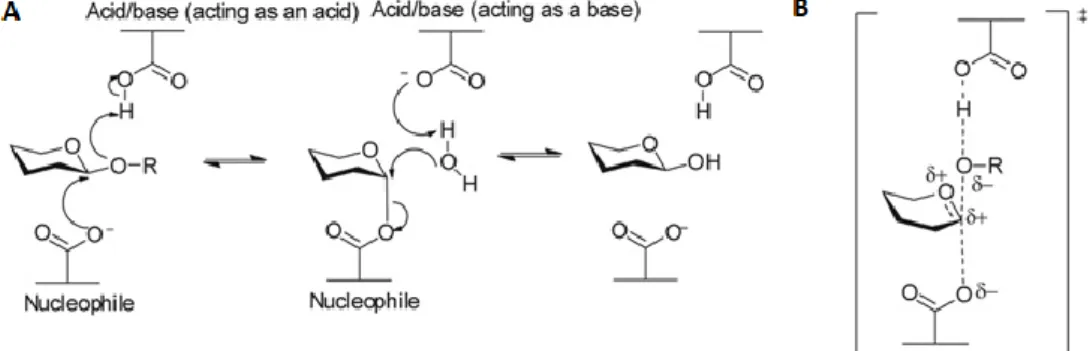
The catalysis of glycosylated molecules and carbohydrate structures containing at least two saccharides is mainly mediated through two mechanisms. These mechanisms were first suggested in 1953 by Koshland: the inverting mechanism and the retaining mechanism (Koshland, 1953). The difference between the two mechanisms is whether or not the anomeric configuration of the carbohydrate is retained or inverted (Davies and Henrissat, 1995). Both mechanisms require the presence of two carboxylate residues such as aspartate or glutamate (Gloster, 2012).
The inversion of the stereochemical anomeric centre is a one-step mechanism (Figure 2). One of the residues will function as a proton donor (acid), while the other acts as a proton acceptor (base). During the enzymatic reaction, the proton donor will help with the departure of the leaving group by supplying it with a proton. In the meantime, a water molecule attacks the anomeric centre. To prevent the production of highly nucleophilic molecules, the proton acceptor deprotonates the water molecule. The previous steps all happen simultaneously (Gloster, 2012).
Figure 2: Enzymatic reaction of glycosyl hydrolases using the inversion mechanism. Adapted from Gloster (2012).
The mechanism of retaining the anomeric configuration is a two-step process (Figure 3). It consists of consecutive steps of inversion and has a covalently bound carbohydrate-enzyme intermediate. One of the carboxylate residues will act both as acid and base depending on the step in the process, while the other carboxylate functions as the nucleophile. During the first step of the retaining mechanism, the acid/base residue acts as an acid and protonates the leaving group. Concomitantly, the nucleophile attacks the carbon at the anomeric centre. The latter step gives rise to the glycosyl-enzyme intermediate. In the second step, the acid/base residue functions as a proton acceptor and it deprotonates a water molecule. The deprotonated water molecule attacks the glycosyl-enzyme intermediate and results in the release of the carbohydrate.
Figure 3: Glycosidic hydrolysis using the retaining mechanism (A). Glycosyl-enzyme intermediate (B). Adapted from Gloster (2012).
2.3.2
Glycosyl hydrolase family 5
Members of the glycosyl hydrolase family 5 (GH5) occur in Eubacteria, Archaea and Eukaryota such as fungi, plants and metazoans (Aspeborg et al., 2012). The GH5 family is polyspecific and has members such as cellulases, chitosanases, glucanases, xylanases, β-mannanases, and endoglycoceramidase. Despite the variation in the specificity of the GH5 members, they all carry eight conserved residues in the active site of which two are glutamate residues (Opassiri et al., 2007). According to the CAZY database the GH5 members show a retaining mechanism.
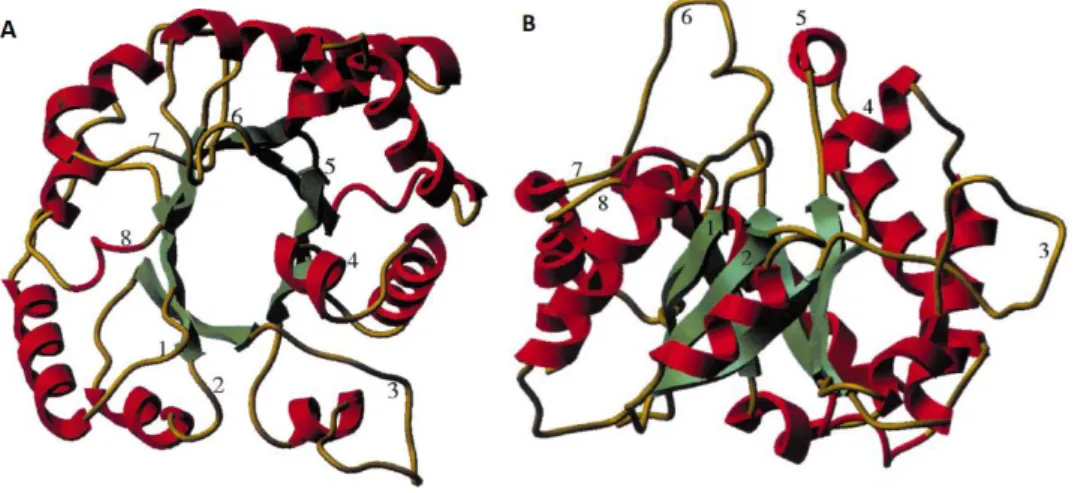
The GH5 family is part of the GH-A clan, having a core (β/α)8-barrel in common (Opassiri et al., 2007). This fold is formed by eight strand-loop-helix-turn chains (Silverman et al., 2001). This structure was observed for the first time in triosephospate isomerase (TIM), hence this type of fold is known as TIM-barrel (Wertz et al., 2017) (Figure 4). The TIM-barrel fold is the most common enzyme fold in the Protein Data Bank and besides glycosyl hydrolases the fold can be found in a lot of different enzymes (Wierenga, 2001). The α-helices surround the β-strands. The active sites are found in the β->α loops (Silverman et al., 2001).
Figure 4: TIM-barrel fold, illustrated using trypanosomal TIM. A: Top view of the TIM-barrel. The active site of the TIM-barrel is shown, due to the fact that the β->α loops are visible. B: Side view of the TIM-barrel. Adapted from Wierenga (2001).
2.3.3
Biological importance of GH in plants
Glycosyl hydrolases are ubiquitous in Arabidopsis and rice, and 29 GH families are present in these model plants (Minic, 2008). The occurrence of glycosyl hydrolase and glycosyl transferase genes in the plant genome is estimated to account for 1-2%. Arabidopsis contains 379 open reading frames of glycosyl hydrolases (Henrissat et al., 2001). The numerous glycosyl hydrolase genes present in the genome of plants display the importance of these enzymes in the plant.
The cell wall gives the plant cell its rigidity and structure (Lannoo et al., 2014). A lot of the GHs are employed to maintain the cell wall polysaccharides in plants. The cell wall is composed of several polysaccharide fractions: cellulose, pectin and hemicellulose. Whereas cellulose gives rise to the framework, pectin and hemicellulose are embedded in the cellulose frame (Fry, 2004). Pectin and hemicellulose consist of polysaccharides built by numerous different monosaccharides such as arabinose, galactose, rhamnose and glucose. Cellulose is made up of β-(1,4)-D-glucose linked chains (Fry, 2004). Due to the diversity and complexity of carbohydrates in the cell wall, there are a lot of GHs associated with the metabolism of the cell wall. Cell wall metabolism is important for growth, but
also for abscission and fruit softening (Cosgrove, 2005). It can also be induced by abiotic stresses such as water deficiency (Le Gall et al., 2015).
Next to cell wall modification, GHs play a role in energy storage and carbon metabolism. The release of carbohydrates from storage molecules (e.g. starch) is mediated by glycosyl hydrolases. The released saccharides (e.g. glucose) can serve as an energy source in the plant (Minic, 2008).
The glycoside hydrolases are also very important in plant defence and symbiosis. Plants produce pathogenesis-related proteins (PR-proteins) as a response to infections (Eckardt, 2008). Certain proteins originate from the GH group. In this category chitinases and β-1,3-glucanases are very important. Both proteins play a role in the plant defence against fungal pathogens (Mauch et al., 1988; Ferreira et al., 2007; Minic, 2008; Pusztahelyi, 2018). Chitin is a major component of the cell wall of certain fungi. Next to chitin, β-1,3-glucans are also present in the cell wall as a structural component. Chitinases and β-1,3-glucanases degrade the fungal cell wall and inhibit the growth of the pathogenic fungus (Ferreira et al., 2007; Pusztahelyi, 2018). There are hypotheses, that apart from the role in plant defence, these enzymes serve in other physiological processes (Minic, 2008). Next to the chitinases and glucanases, other GHs can help in the defence response by activating metabolites as is the case for myrosinases that hydrolyse glucosinolates. This results in the production of isothiocyanates, which have a role in the immune response against infections by micro-organisms (Tierens et al., 2001; Pastorczyk and Bednarek, 2016). The abovementioned information about the involvement of GHs in plant defence is just a scratch on the surface. In the process of symbiosis, the presence of GHs is not yet completely elucidated but several hypotheses assume that GHs are important for the Rhizobium–legume interactions (Minic, 2008).
The process of glycosylation and deglycosylation by glycosyl transferases and GHs, respectively, is very important in plant hormone signalling. Glycosylation of plant hormones which have huge effects on the plant’s processes has the potential to inactivate the hormones (Jones and Vogt, 2001). The levels of active phytohormones can be kept in balance by conjugating hormones with sugars. This is the case for several phytohormones such as auxin (Jin et al., 2013), cytokinin (Hou et al., 2004), brassinosteroids, ABA, gibberellic acid and jasmonic acid (Bajguz and Piotrowska, 2009). There are indications that β-glucosidases are important for the release of the active hormone and the carbohydrate moiety (Minic, 2008; Bajguz and Piotrowska, 2009).
Glycosyl hydrolases also contribute to other processes, including glycolipid metabolism, secondary plant metabolism, biosynthesis and remodulation of glycans, signalling and physiological processes such as pollen development, flowering and germination (Minic, 2008).
2.3.4
Applications in medicine
Mutations in specific glycosidase genes can lead to lysosomal storage disorders (LSD) such as Tay-Sachs disease and Gaucher disease (Desnick et al., 2013; Solovyeva et al., 2018). One of the possible approaches for the treatment of LSD is to use enzyme replacement therapy (ERT). The treatment consists of the intravenous infusion of the respective enzyme. For example in the case of type 1 Gaucher disease, human β-glucocerebrosidase was injected in the patient. This strategy was successfully applied for type 1 Gaucher disease. This was an incentive to utilize this therapy for the treatment of other LSD (Desnick et al., 2013). Unfortunately, ERT cannot be applied for all manifestations of LSDs.
Lactose intolerance is estimated to be present in 65-70% of the global adult population. This is due to lower levels of lactase in the intestinal tract (Bayless et al., 2017). There are different strategies to cope with lactose intolerance e.g. the consumption of lactose-reduced products, prebiotics, probiotics and exogenous uptake of lactase. The strategy of the exogenous uptake of lactase is not yet fine-tuned (Szilagyi and Ishayek, 2018).
The direct application of glycosyl hydrolases against pathogenic infections is also possible. Chitinases can be used in the therapy for fungal diseases (Dahiya et al., 2006; Le and Yang, 2019). Polysaccharide depolymerases originating from bacteriophages show antimicrobial activities and these glycosyl hydrolases can even inhibit biofilm formation (Wu et al., 2019).
In the previous sections glycosyl hydrolases serve as the solution for diseases, intolerances and infections, but glycosyl hydrolase activity can also be the problem. In this case the use of inhibitors is required to inhibit the glycosidase activity. In a medical setting, these inhibitors can be used in viral infections, cancer therapy and genetic disorders (Asano, 2003). In the following sections some examples of applications of glycosyl hydrolase inhibitors are demonstrated.
Inhibitor molecules of the digestive α-glucosidase could control the carbohydrate uptake in the intestines and therefore be applied in type II diabetes. Acarbose and many other inhibitor molecules are commercially available for treating this type of diabetes (Asano, 2003; Taslimi et al., 2018). Cancer cells have an altered carbohydrate array on the cell surface compared to normal cells. This is due to changed N-glycan processing. A Golgi α‐mannosidase II inhibitor, Swainsonine, proved to block tumour growth (Asano et al., 2000; Compain, 2019).
Glycosidase inhibitors such as iminosugars can also be used to inhibit viral activity. A lot of viruses require the endoplasmic reticulum for the glycosylation of viral envelope glycoproteins. Glucosidase inhibitors have shown to decrease the replication of human immunodeficiency virus. Another example of the application of GH inhibitors is the use of neuraminidase inhibitors for the treatment of influenza (Asano, 2003; Alonzi et al., 2017; Compain, 2019).
2.4
Multi-domain proteins
Proteins often consist of multiple modules, which are called domains. In the search for new lectins in 38 fully sequenced plant genomes, researchers found that the majority of lectin sequences encoded multiple protein modules (Van Holle and Van Damme, 2019). Genome analyses indicate that more than 70% of all eukaryotic proteins have multiple modules (Han et al., 2007). Multi-domain proteins do not occur solely in eukaryotes, they also occur in prokaryotes (Buljan and Bateman, 2009). The modules can be defined through different approaches: sequence, structure, function or evolution (Vishwanath et al., 2018). Despite the different ways to define protein domains, there are many cases in which the different approaches are compatible (Franzosa and Xia, 2008). There are multiple advantages of multi-domain proteins compared to single-domains. These advantages mainly relate to function, folding and stability (Vishwanath et al., 2018).
The properties of protein domains are similar to those of single-domain proteins. They have a characteristic pattern of secondary structures, a hydrophobic core and probably contain an active site for enzymatic catalysis or for binding ligands (Kuriyan, 1993). These modules could perform a certain function on their own, contributing to the overall biological function of the multi-modular protein (Han
et al., 2007; Itoh et al., 2007; Barrera et al., 2014). These features are used in biochemistry to
elucidate the properties of the separate domains. Due to interaction between the different modules the function of multi-domain proteins is often ‘not equal the sum of its parts’ (Yesylevskyy et al., 2006; Levy, 2017).
The inter-domain interactions can be advantageous for the function of the whole protein. The interface of two or multiple domains has been shown to be important because the inter-domain communication can facilitate the proper functioning of the whole protein (Bhaskara and Srinivasan, 2011). Additionally, there could be an emergence of a new function at the interface (Vishwanath et al., 2018). These new functions can consist of new binding sites, regulatory sites and allosteric sites (Bhaskara and Srinivasan, 2011). Next to the new functions, higher stability of the multi-domain proteins can be conferred due to the intricate relation between the different domains (Bhaskara and Srinivasan, 2011). Besides these synergistic effects it is possible that the linkage between different domains does not result in the advantageous effects as was described above. Destabilization of proteins can occur due to the fusion of domains (Levy, 2017).
From an evolutionary point of view multi-domain proteins emerged through major recombination events such as duplication, insertion, deletion and transposition of domains (Bhaskara and Srinivasan, 2011). These processes facilitated the formation of novel and complex protein functions from a small collection of domain families (Han et al., 2007). A vast majority of eukaryotic proteins tend to have multiple modules. This could indicate that there is an evolutionary advantage of the multi-domain proteins.
Carbohydrate Active enZymes (CAZymes) and lectins have the tendency to consist of multiple domains (Henrissat and Davies, 2000; Lombard et al., 2014; Van Holle and Van Damme, 2019).
2.4.1
Carbohydrate-binding modules
A carbohydrate-binding module (CBM) is a protein domain often found in CAZymes and, as the name suggests, CBMs have carbohydrate binding activity (Shoseyov et al., 2006). Initially these domains were defined as cellulose binding domains but more and more modules are found that bind other carbohydrates (Boraston et al., 2004).
The CBMs play a certain role in CAZymes. They have shown to improve the catalytic activity of the enzymes, but this might only be the case when the substrate is insoluble as is the case for crystalline cellulose. They also modify the surface or interfacial structures of the substrate (Shoseyov et al., 2006). The CBMs also play a role in the proximity effect, targeting function and disruptive function (Boraston et al., 2004).
There are several ways to classify CBMs, which can be sequence-based, fold-based or based on their sugar binding mode (Boraston et al., 2004; Fujimoto, 2013). The classification based on the amino acid sequence resulted in a total of 86 CBM families (Lombard et al., 2014). Despite this classification based on the sequences, one needs to take into account that the sequences themselves do not give any information about the ligand they bind. The CBM13 domain of Streptomyces
olivaceoviridis β-xylanase can bind xylose in xylan. However the CBM13 module of Streptomyces avermitilis β-L-arabinopyranosidase has the property to bind arabinose (Fujimoto, 2013). These two cases highlight that one cannot decide what kind of substrate the module binds based on the family (Guillén et al., 2010).
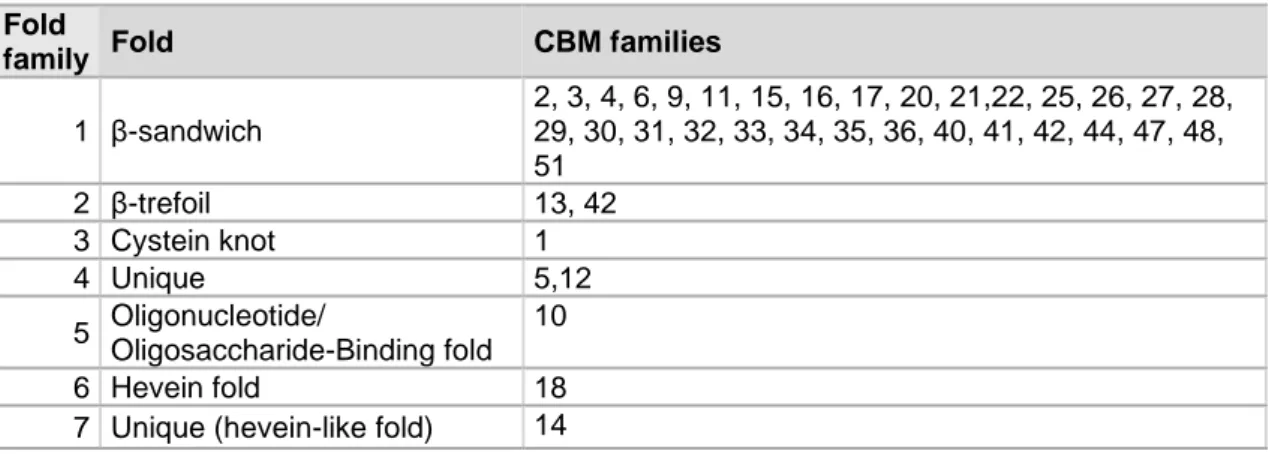
The CBMs can also be subdivided into fold families according to structural properties. To date, there are seven fold families known. Each CBM family can be appointed to a certain fold family (Table 1) (Gilbert et al., 2013).
Table 1: Overview of the different fold families and the respective CBM families related to the folds (Guillén et al.,
2010)
Fold
family Fold CBM families
1 β-sandwich 2, 3, 4, 6, 9, 11, 15, 16, 17, 20, 21,22, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 40, 41, 42, 44, 47, 48, 51 2 β-trefoil 13, 42 3 Cystein knot 1 4 Unique 5,12 5 Oligonucleotide/ Oligosaccharide-Binding fold 10 6 Hevein fold 18
7 Unique (hevein-like fold) 14
There are 3 different types to classify CBMs based on their sugar binding mode: the surface-binding CBMs (type A), glycan-chain-binding CBMs (type B) and small-sugar-binding lectin-like CBMs (type C) (Boraston et al., 2004). Type A CBMs are domains that interact with the surface of carbohydrates. This is mainly for insoluble and crystalline substrates (e.g. chitin and cellulose). The CBMs have a hydrophobic planar platform which contains three aromatic residues. These residues interact with the polysaccharide (Guillén et al., 2010; Gilbert et al., 2013). The type B CBMs preferably bind oligosaccharides with a degree of polymerization of three up to six carbohydrate residues. Type B CBMs have a groove or cleft in which aromatic residues are arranged and these residues can interact with carbohydrate chains (Guillén et al., 2010).
The C type CBMs have lectin-like binding properties and preferably bind short saccharides with a degree of polymerization of one up to three (Boraston et al., 2004). Gilbert et al. (2013) proposed a refinement for the definitions of the type B and type C CBMs. They suggest to redefine type B CBMs as endotype CBMs that bind internally on carbohydrate chains whereas type C CBMs bind carbohydrates at the terminal sites of glycans (Gilbert et al., 2013).
CBMs and lectins have a lot of similarities, both bind carbohydrates and have similar structures. In literature, sometimes a distinction is made between CBMs and lectins (Gilbert et al., 2013), but this distinction depends on the definition of a lectin. In this thesis the following definition for lectins is used: lectins are all proteins that consist of at least one noncatalytic domain that binds reversibly to a specific mono- or oligosaccharide (Van Holle and Van Damme, 2019). According to this definition type C CBMs and lectin domains can be considered as protein domains with similar activity.
2.4.2
Ricin and CBM13
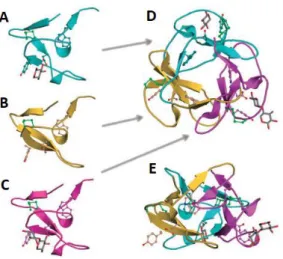
Ricin is the first plant lectin that has been studied. Peter Hermann Stillmark described the characteristics of ricin in 1888. The protein was discovered and isolated from castor bean (Ricinus communis) (Sharon and Lis, 2004). This plant lectin has toxic effects due to the ribosome inactivating activity of one of the polypeptide. Subsequently protein synthesis is inhibited and the cell dies due to the inability to synthesize new proteins. The presence of the lectin domains helps the ribosome inactivating protein (RIP) to enter cells and cause mortality in these cells. Ricin is a heteromeric protein consisting of an A and a B chain (30 and 28 kDa, resp.). The A-chain has the ability to inactivate the ribosomes, whereas the B -ricin chain binds specifically to galactose and thus has lectin properties (Lord et al., 1994; Olsnes and Kozlov, 2001). The B-chain consists of two globular ricinB-domains. Each domain is classified as a CBM13 family member, with the characteristic β-trefoil fold (Guillén et al., 2010; Fujimoto, 2013). The module consists of 40-52 amino acids, which is repeated three times. Therefore, the module can be divided into three subdomains (α, β and γ) (Figure 5) (Fujimoto, 2013). The subdomains of the ricinB domain are galactose binding peptides. Only one of the subdomains of the ricinB chain is active (Sphyris et al., 1995). The B-chain of ricin binds mainly to galactosides, such as β1,4-galactoses and N-acetylgalactosamine carbohydrate epitopes (Taubenschmid et al., 2017). Other members of the CBM13-family have different carbohydrate specificities e.g. arabinose and xylose (Fujimoto, 2013).
Figure 5: β-trefoil of the CBM13 domain of the xylanase SoXyl10. The different subdomains are shown separately: α (A), β (B) and γ (C) . A top view (D) and a side view (E) of the complete structure is given. Adapted from Fujimoto (2013).
2.5
Heterologous protein expression
Proteins are the workhorses of every biological system because they mediate the majority of the chemical reactions and biological processes. To understand the function and the properties of these biomolecules, purified proteins can assist in the characterization. The purified proteins can be used in experiments to elucidate the biophysical and biochemical properties (Zerbs et al., 2009). To obtain large quantities of proteins for research, therapeutics and industrial applications, one can express the gene in a heterologous host. This process requires the capability to clone the gene of interest in the host and the ability to express it (Rai and Padh, 2001).
Sadly enough there is no universal system for the production of heterologous proteins. The choice of the best expression system requires the evaluation of several aspects; yield , glycosylation, proper folding, cost, scale-up, etc. (Rai and Padh, 2001). The nature of the protein of interest and the use of the product are aspects that need to be considered before starting (Zerbs et al., 2009). Additionally the different hosts have their advantages and their limitations (Rai and Padh, 2001; Martínez-Alarcón
et al., 2018; Amos and Mohnen, 2019).
In general, two kinds of expression systems can be determined: prokaryotic and eukaryotic systems. The prokaryotic expression systems use bacteria for the production of the protein (Rai and Padh, 2001). Escherichia coli is the main organism employed for the production of recombinant proteins (Tateishi et al., 2014; Toufiq et al., 2018). Other bacteria like Bacillus subtilis and certain pseudomonads can also be used for the heterologous gene expression (Goeddel, 1990). In the case of eukaryotic expression systems, there are a lot of possibilities. Yeasts, insect cells, mammalian cells, and plant cells can be used as possible hosts for the production of proteins (Rai and Padh, 2001; Amos and Mohnen, 2019). There is a huge difference between the prokaryotic and eukaryotic system due to the differences in cellular machinery for protein expression in both systems. Eukaryotes have accessory proteins (chaperones), posttranslational modification proteins and maturation proteins. The latter indicates that there will be a difference in the proteins obtained from both systems (Zerbs et al., 2009).
The main advantage of using prokaryotes as host is the ease of the process and the overall high yields of proteins produced (Martínez-Alarcón et al., 2018). E. coli is widely used due to the fact that this organism is well-characterized. The whole genome and the physiology of E. coli are well known. This knowledge is already used to make different strains that can be applied in industrial processes due to the fact that they are Generally Recognized As Safe (GRAS) (Rai and Padh, 2001). The short doubling time of E. coli is another advantage as it accelerates experiments and processes significantly. In addition, fast growth reduces stringency of facility requirement (Zerbs et al., 2009). Despite the advantages, the use of bacterial expression systems has its limitations. Sometimes the proper processing of the proteins may not occur (Martínez-Alarcón et al., 2018). This processing consists of proper protein folding, glycosylation and disulphide bond formation (Rai and Padh, 2001; Amos and Mohnen, 2019). The production of insoluble cytoplasmic aggregates, known as inclusion bodies, also poses a problem. If this problem occurs the inclusion bodies need to be solubilized by using denaturing agents, followed by renaturing/refolding of the proteins (Martínez-Alarcón et al., 2018). There are already some technological advances that can solve some limitations such as the periplasmic-directed expression to obtain disulphide bonds (Amos and Mohnen, 2019).
Other preferred host systems for the heterologous gene expression are yeasts. Saccharomyces
cerevisiae and Pichia pastoris are examples of yeasts that are often used as host (Martínez-Alarcón et al., 2018). Yeasts can grow rapidly and have the eukaryotic machinery to perform certain
post-translational modifications of proteins. Despite the possibility of yeasts to glycosylate (both N and O-glycosylation) the proteins, hypermannosylation can occur. This process is certainly not wanted (Rai and Padh, 2001). It is noteworthy that each system has cases where the heterologous expression system was successful for the production of recombinant proteins. The optimal host and conditions for heterologous expression of proteins need to be defined experimentally.
2.6
Research objectives
In this thesis we aim to elucidate the activity and the biological role of two proteins that have a lectin/CBM domain and a GH domain: AT1G13130 and AT3G26140 from Arabidopsis thaliana. Both sequences encode proteins that can be considered as lectins due to the presence of a carbohydrate binding domain. Based on sequence similarity the lectin domain is part of the ricinB lectin family. The ricinB domain corresponds to the CBM family 13 (CBM13). This family of CBMs is characterized by a β-trefoil structure (Table 1). CBM13 members can exert galactoside, xylose or arabinose binding activity (Fujimoto, 2013; Taubenschmid et al., 2017). The specificity of the lectin domains in AT1G13130 and AT3G26140 cannot be determined based on the structural classification of either lectins nor CBMs. Wet lab experiments are required to determine the specificity of the CBMs of both AT1G13130 and AT3G26140.
Next to the ricinB/CBM13 domain, the selected target proteins also contain a GH domain. The glycosyl hydrolase domains of both proteins belong to the GH5_11 subfamily (Chen et al., 2019). Sequences for this subfamily are present in land plants probably after a horizontal gene transfer from fungi to plants (Chen et al., 2019). The GH5 family classifies groups of enzymes with specificity towards cellulose, mannan, xylan, galactan and xyloglucan suggesting that the specificity of enzymes within this family is very heterogeneous. Thus the carbohydrate specificity of the GH domain of AT1G13130 and AT3G26140 cannot be determined by comparison to other members from the same family (Aspeborg et al., 2012).
The focus of this thesis is to clone the sequences of AT1G13130 and AT3G26140 in a heterologous expression host system. Escherichia coli is the typical bacterial host system with different advantages for heterologous protein expression. Once active proteins are obtained, biochemical and enzymatic properties could be determined. Subsequently, a better understanding of the biological role of the proteins encoded by AT1G13130 and AT3G26140 within Arabidopsis thaliana will be achieved.
Parallel to the heterologous protein expression in E. coli, homozygous A. thaliana overexpression lines were created through floral dip. Using these transgenic lines, phenotypical and stress experiments will pinpoint the function of the two-domain proteins encoded by the sequences of AT1G13130 and AT3G26140.
3 MATERIALS AND METHODS
3.1
In silico analysis
Different databases were used for the in silico analysis. Data related to AT1G13130 and AT3G26140 were searched in The Arabidopsis Information Resource (TAIR) (https://www.arabidopsis.org/), ThaleMine (https://bar.utoronto.ca/thalemine/begin.do) and Bio-Analytic for Plant Biology (BAR) (http://bar.utoronto.ca/). These databases provide information concerning gene expression patterns, protein sequences, subcellular localization, and more.
Protein databases and online tools were employed for the protein analysis. UNIPROT was used to gain more insight in the size of the proteins. InterPRO (https://www.ebi.ac.uk/interpro/) is an online tool that gives an overview of the different protein domains occurring in a protein sequence. To improve our understanding of the post-translational modifications of the proteins, online prediction software was used. NetNGlyc (http://www.cbs.dtu.dk/services/NetNGlyc/) and DISULFIND (http://disulfind.dsi.unifi.it/) were employed to get more information about the presence of N-glycosylation and the disulphide formation, respectively.
GENEVESTIGATOR® (Hruz et al., 2008) was employed to investigate the expression profiles based on microarray data. This is a powerful tool for the exploration of the expression pattern. GENEVESTIGATOR® is an expression database which facilitates the selection of subsets for further research. The database contains data from a very broad range of experiments. Prior to the data mining a subset of relevant data was selected from the data provided by GENEVESTIGATOR®. For instance to elucidate the expression of the gene of interest during the different life stages of a plant, a subset of data was selected. BAR was also used to observe the expression profiles.
CloneManager was utilized for the construction of the recombinant genes for heterologous gene expression.
3.2
Plant section
3.2.1
Material
3.2.1.1 Plant material and growth conditions
Arabidopsis thaliana ecotype Columbia-0 (wild type or transformed) seeds were surface sterilized in
70% (v/v) ethanol for 2 min, followed by 10min in 5% (v/v) NaOCl. The seeds were rinsed 10 times with sterile distilled water. These seeds were sown on solid Murashige and Skoog (MS) medium (4.3g/L MS (Duchefa), 30g/L sucrose (for non-selective media) or 15g/L sucrose (for selective media) and 8g/L micro agar (Duchefa)). Additionally, the MS-medium can be supplemented with 75µg/mL kanamycin during selection experiments. Next to the in vitro growth of the plants, seeds were planted on soil or on artificial soil (Jiffy). Both the in vitro grown plants and the plants grown on soil were vernalized for 2-3 days at 4°C in the dark. After vernalization the plants were grown at 21°C under a photoperiod of 16h light and 8h dark.
3.2.1.2 Agrobacterium tumefaciens
The coding sequences for AT1G13130 and AT3G26140.1. were cloned in the vector pK7WG2 (Figure 6). The plasmids pK7WG2:p35S-AT1G13130 and pK7WG2:p35S-AT3G26140.1 were already present in the lab of professor Van Damme. The vector backbone contains both a kanamycin and spectinomycin resistance gene. The former is a bacterial resistance selection marker while the latter will confer resistance to the plant.
Figure 6: pK7WG2 vector used for the cloning of AT1G13130 and AT3G26140.1. (Karimi et al., 2002)
Agrobacterium tumefaciens strain C58C1 RifR pMP90 was used for the transformation of the
seven-week old Arabidopsis thaliana plants. This strain was present in the lab and contains gentamycin and rifampicin resistance.
3.2.2
Methods
3.2.2.1 Transgenic plants
Transformation of Agrobacterium tumefaciens
Agrobacterium tumefaciens cells were transformed with either pK7WG2:p35S-AT1G13130 or pK7WG2:p35S-AT3G26140.1. 100-500ng of plasmid was added to 40µL of electrocompetent A. tumefaciens cells. The samples were incubated for 1min on ice after which electroporation was
performed (2.5kV, 25µF and 200Ω). Afterwards, 960µL of YEB-medium (5 g/L beef extract (Lab M Ltd), 5 g/L peptone (MP Biomedicals), 1 g/L yeast extract (Merck), 5 g/L sucrose (Roth)) was added and the sample was incubated for 2h at 28°C. The solution was centrifuged at 4000 rpm for 5 min. The cell pellet was resuspended with 100µL YEB medium. The cell suspension was transferred on selective solid YEB medium (5 g/L beef extract, 5 g/L peptone, 1 g/L yeast extract, 5 g/L sucrose, 15 g/L agar (MP Biomedicals)) supplemented with 20µg/mL gentamycin, 200µg/mL rifampicin and 50µg/mL spectinomycin. The plates were incubated for 2 days at 28°C. Colony PCR allowed to check whether the colonies were really transformed. Prior to the PCR a lysis step was performed on the bacterial cells: 10min at 95°C. For AT1G13130, the primers L78 and L79 were applied (Appendix 1). The PCR program was: 10’ – 95 °C, 35x (30’’ – 95 °C, 60’’ – 52 °C, 2’ – 72 °C), 5’ – 72 °C. In the case of AT3G26140 primers L80 and L81 (Appendix 1) were utilized. Afterwards the following PCR-program was used: 10’ – 95 °C, 35x (30’’ – 95 °C, 30’’ – 60 °C, 2’ – 72 °C), 5’ – 72 °C.
Floral dip
Transformed A. tumefaciens cells were grown in 5mL of liquid YEB medium supplemented with 20µg/mL gentamycin and 50µg/mL spectinomycin for 2 days at 28°C. Thereafter 100mL of YEB medium without antibiotics was added and grown overnight at 28°C. The culture was separated into two equal volumes and centrifuged for 15min at 3000 rpm. The cell pellet was resuspended in 20mL infiltration medium (10% (m/v) sucrose and 0.05% (v/v) of Silwet).
Plants of A. thaliana ecotype Columbia were transformed with Agrobacterium tumefaciens strain C58C1 RifR pMP90 containing the following plasmid AT1G13130 or pK7WG2:p35S-AT3G26140.1 using the floral dip method (Clough and Bent, 1998). Wild type plants were grown on
soil as discussed in section ‘Plant material and growth conditions’. Plants start to flower when they are 6 to 8 weeks old. The inflorescences were dipped in the infiltration suspension solution and agitated gently for maximum 1 minute. Six days later, the floral dip was repeated on the same plants. The plants were grown in a plant growth room at 21°C until they matured and seeds were harvested.
Selection of transgenic plants
The primary transformants (T1), the harvested seeds from the floral dip transformed plants, were seed sterilized and sown on MS medium containing 75µg/ml kanamycin. The plants were grown as discussed in the section ‘Plant material and growth conditions’ but an additional stratification step was performed. After vernalization the plants were exposed to light for 4-5 hours after which they grow in the dark for 2 days at 21°C. After the incubation, the plants were grown at 21°C under a photoperiod of 16h light and 8h dark. At the four-leaf stage, green plants were transferred to artificial soil (Jiffy). DNA extraction was performed on two rosette leaves from each selected T1 plant. PCR was used for the detection of the inserted construct in the gDNA. The quality of the gDNA was tested by PCR using the reference gene actin. The PCR program utilized was 10’ – 95 °C, 35x (30’’ – 95 °C, 60’’ – 55 °C,
60’’ – 72 °C), 5’ – 72 °C. The primers used for the amplification of the actin gene was evd280-evd281 (Appendix 1). The following PCR program was used for checking the insertion of AT3G26140.1: 10’ – 95 °C, 35x (30’’ – 95 °C, 60’’ – 60 °C, 2’ – 72 °C), 5’ – 72 °C. Primers L80 and L81 (Appendix 1) were utilized during the PCR. For AT1G13130, the primers L78 and L79 were applied (Appendix 1). The PCR program was: 10’ – 95 °C, 35x (30’’ – 95 °C, 60’’ – 52 °C, 2’ – 72 °C), 5’ – 72 °C. The PCR amplification products were checked on 1.5% agarose gels and EtBr staining. Plants that did not contain the construct based on the PCR results were discarded.
Seeds were harvested from fully matured plants. These are the second generation of transformants and originate from self-pollinated plants. Fifty T2-seeds from the same T1-plant are sown on solid MS medium containing 75µg/ml kanamycin. At the four-leaf stage, the number of green plants was counted, which allowed for the calculation of the zygosity percentage. All seedlings from one primary transformant were transferred to artificial soil (Jiffy) and were further grown. At the senescence stage of the plant, seeds were harvested (T3).
DNA extraction from plant material
Leaves were crushed into a fine powder using mortar and pestle with liquid nitrogen. Hereafter, 400µL of Edward’s extraction buffer (200mM Tris HCl pH 7.5, 250mM NaCl, 25mM EDTA and 0.5% SDS) was added. The solution was mixed for 5 seconds and was centrifuged for 5min at 13,000 rpm. Approximately 300µL of the supernatant was combined with 300µL isopropanol (VWR) and this was incubated for 2min at 21°C. The solution was centrifuged for 5min at 13,000 rpm. The DNA pellet was washed twice with 500µL of 70% (v/v) ethanol. The two washing steps were interrupted with a centrifugation step (1min at 13,000 rpm). The DNA pellet was dissolved in 30µL of water. The quality and concentration of DNA was measured with NanoDrop 2000 spectrophotometer (Thermo Scientific). The DNA was stored at -20°C.
3.2.2.2 Amplification of transcripts for AT3G26140
ABA treatment
Wild type Col-0 seeds were grown on solid MS medium in the absence of antibiotics. 30 seeds were grown per plate. Twenty days after sowing, the seedlings were transferred to liquid MS medium supplemented with 100µM abscisic acid. The roots were fully immersed in the liquid medium. The seedlings were incubated for 3 hours at 21°C in the light (Chen et al., 2019). Afterwards the plants were rinsed with sterilized bidest and crushed in liquid nitrogen. The samples were stored at -80°C.
RNA extraction
The plant samples collected after the ABA treatment were used for a total RNA extraction. The samples were mixed with 1mL Trizol (Sigma-Aldrich) and were incubated for 10min at 21°C. Hereafter the samples were centrifuged for 15min at 12,000rpm at 4°C. The supernatant was added to 250µL chloroform and incubated for 3min at 21°C. The solution was centrifuged for 15min 14,000rpm at 4°C. The upper layer was mixed with 500µL isopropanol and the mixture was centrifuged for 10min at 4°C (12,000rpm). The pellet was resuspended in 1mL of 75% (v/v) ethanol. The ethanol solution was centrifuged for 5min at 7500rpm. This pellet was dried and resuspended in 50µL of sterilized distilled water. The nucleic acid concentration and quality were measured using the NanoDrop 2000 spectrophotometer (Thermo Scientific).