deictic behaviour in interactive agents
Design and evaluation of integrated verbal and
Academic year 2019-2020
Master of Science in de informatica
Master's dissertation submitted in order to obtain the academic degree of Counsellor: Pieter Wolfert
Supervisors: Prof. Tony Belpaeme, Prof. dr. ir. Francis wyffels Student number: 01502893
Preamble
On the 13th of May 2020, Belgium decided to start a lockdown due to the corona virus
outbreak. I respected the laws that would limit the spread of the virus and stayed in quarantine. This also means that I was not able to execute some parts of my thesis and had to change the planning in order to fit the new circumstances. In the section below, the changes to the planning of this thesis will be described.
This paper would have originally contained a proposal for an autonomous robot that could be used to repeat the user study of suyoshi Komatsubara,Masahiro Shiomi, Takayuki Kanda and Hiroshi Ishiguro [1]. We hoped to confirm the theory of this study and get more insight of how robust the implementation would be in this kind of situation. Be-cause of the quarantine, there was no access to the robot and conducting a user study also was not possible anymore. Luckily, I still had access to the servers and an RGBD camera. This allowed me to create a more general proof of concept for all interactive agents that would have access to such a camera. The user study was replaced by multiple smaller tests that are a first proof of the quality and perceived added value of the product. These tests were performed on my close contacts and they had no prior knowledge of the concepts.
This preamble was created and accepted in consultation between the student and the supervisors.
Abstract
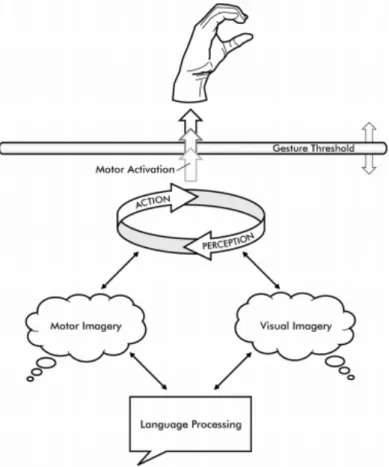
When humans communicate with each other, they use more than one communication channel. Next to verbal communication, deictic behaviour is often used to draw some-ones attention to a direction or target. Earlier research states that adding pointing gesture recognition to social robots would cause children to ask more questions during a poster presentation. This research was conducted without an autonomous robot. This thesis proposes an autonomous implementation that can present any poster presentation without any retraining or reprogramming.
The implementation consists of two main parts: deictic interaction and verbal interaction. The goal of the deictic interaction is to detect the target to which the user is pointing and passing this to the chatbot to use in its conversation. With the help of one depth camera, the program detects the user’s body position. With this position, the program can detect if and when the user is pointing, what the pointing direction is and to which target this direction belongs.
The chatbot is build using the Artificial Intelligence Markup Language (AIML). This state-of-the-art pattern matching interpreter can match specific keyword patterns with a question about the poster. This question can contain a target object or the target can be derived from the deictic interaction.
The initial tests show us that the deictic interaction, except for the gesture recognition, is very competitive with state-of-the-art techniques. In a small proof of concept study, the participants evaluated the implementation very positively and they perceived the deictic behaviour as an added value to the conversation. The chatbot received very good feedback and detected almost all questions correctly. Future testing is required, but this implementation could be the foundation for improved interactive agents.
Samenvatting
Wanneer mensen met elkaar communiceren, gebruiken ze vaak meer dan ´e´en commu-nicatiekanaal. Naast verbale communicatie wordt ook deiktische communicatie vaak ge-bruikt om bijvoorbeeld de aandacht op een bepaalde richting of object te plaatsen. Eerder onderzoek toont aan dat het toevoegen van herkenning van aanwijzingen aan een sociale robot als gevolg heeft dat kinderen meer vragen stellen tijdens een poster presentatie. Dit onderzoek werd echter zonder autonome robot uitgevoerd. Deze thesis stelt een au-tonome implementatie voor die elke poster kan presenteren zonder opnieuw getraind of geprogrammeerd te worden.
Deze implementatie bestaat uit twee grote delen: de deiktische interactie en de verbale interactie. Het doel van de deiktische interactie is om het object waar de gebruiker naar aan het wijzen is, te herkennen en door te geven aan de chatbot om te gebruiken in zijn conversatie. Met behulp van een dieptecamera kan het programma de lichaamspositie van de gebruiker herkennen. Met deze positie kan het programma detecteren of de ge-bruiker aan het wijzen is, wat de wijsrichting is en naar welk object de gege-bruiker verwijst.
De chatbot is gemaakt met behulp van de Artificial Intelligence Markup Language (AIML). Deze veelgebruikte techniek kan specifieke kernwoorden matchen met een vraag over de poster. Deze vraag kan doelobject bevatten of het doelobject kan afgeleid worden uit de deiktische interactie.
De initi¨ele testen tonen aan dat de deiktische interactie, met uitzondering van de herken-ning van gebaren, heel competitief is met de huidige technieken. In een kleine proof of concept studie evalueerden de gebruikers de implementatie zeer positief en ervoeren ze de deiktische interactie als een meerwaarde voor het gesprek. De chatbot ontving ook heel goede feedback en detecteerde bijna alle vragen correct. Voor toekomstig onderzoek is het noodzakelijk om de testen verder te zetten, maar deze implementatie ziet er voor nu veelbelovend uit en zou zelfs kunnen dienen als basis voor toekomstige interactieve media.
1
Design and evaluation of integrated verbal and
deictic behaviour in interactive agents
Julie De Meyer
Supervisors: Tony Belpaeme, Francis wyffels Counsellor: Pieter Wolfert Abstract – When humans communicate with each other, they
use more than one communication channel. Next to verbal com-munication, deictic behaviour is often used to draw someones attention to a direction or target. Earlier research states that adding pointing gesture recognition to social robots would cause children to ask more questions during a poster presentation. This research was conducted without an autonomous robot. This paper proposes an autonomous implementation that can present any poster presentation without any retraining or re-programming. The implementation consists of two main parts: deictic interaction and verbal interaction. The initial tests show us that the deictic interaction, except for the gesture recognition, is very competitive with state of the art techniques. In a small proof of concept study, the participants evaluated the implemen-tation very positively and they perceived the deictic behaviour as an added value to the conversation. Future testing is required, but this implementation could be the foundation for improved interactive agents.
human-robot interaction | multimodal interaction | social robots | deictic ges-tures
Introduction
Conversational agents take more and more place into our lives as their human-like verbal communication becomes better. Human communication does, however, include many other communication channels like facial expressions, gaze and gestures. These channels can be used as input to create an environmental analysis or as output to provide the user with extra information. Using multiple of these channels creates a multimodal conversation.
Komatsubara et al. (1) propose the use of an additional deictic interaction channel to a social robot that answers questions about an educational poster. They put up an experiment where the robot had to present a poster of a space station and a space shuttle to primary school students. After the presentation, the children were allowed and even encouraged to ask questions. They divided the experiment into two conditions. In one condition, the robot could only understand verbal questions. In the other condition, the robot could also perceive pointing gestures. Their results verified their hypothesis that a social robot’s capability to perceive pointing gestures would encourage children to ask more questions. It is important to note that this experiment was a Wizard-of-Oz study. This means that the robot was teleoperated by a human at all time.
In this paper, we will propose an autonomous system that could give such a poster presentation. We will go even further and prepare the system to present any poster presentation without any retraining or adaptation to the code. We analysed how accurate the system performs and if there are situations where it fails. We also performed a small proof of concept study with the complete system that evaluates if the participants experience the deictic gestures as an improvement to a verbal-only variant.
This system could be used with minimal hardware require-ments, but it would also be possible to implement this inside a social robot in the future. Doing this would increase the evaluation of the conversation (2) and create even more pos-sibilities for extra communication channels.
Related work
This implementation will exist out of a chatbot imple-mentation integrated with a pointing gesture recognition program. There exist multiple pointing recognition designs. However, a lot of them do not work with the domain-specific environment of a poster presentation. All comparable implementations are summarised in table1.
Shukla et al. (3) created a hand gesture dataset and recog-nition model for human-robot interaction. Their recogrecog-nition model recognises more than only pointing gestures and has a very good accuracy of 93.45%. This model does need limited training data (39 training images and 12 tuning images) and does not need any human kinematic knowledge. They also created a pointing direction estimation (4) with an accuracy of 76.42% using two cameras and 64.20% using one camera. For this implementation, we prefer a single camera to make it possible to integrate it into a social robot. This model is also tested on close-up images of a hand, like in figure
1. This would not be possible for our implementation as we need an overview of the environment including the poster. They also compared different pointing direction estimations. Their implementation consists of a hand-only direction and scored the best with a mean error of only 8.33cm. The second best estimation was from Droeschel et al. (5), who created a Gaussian Process Regression on the shoulder-hand direction. This method came closer to what we need because they use a full-body image. Unfortunately, the implementation had a mean error of 17.0 cm, which is very
2 high if you consider that the poster elements should then
be placed with a minimum of 17.0 cm from each other to be recognised correctly. Droeschel’s gesture recognition is not built on hand keypoints but uses a combination of three arm phases: the preparation phase, the hold phase and the retraction phase. This method is very fast but will give many false-positives.
Fig. 1. Setup experiment Shukla et al. (3)
A more recent and closer related paper (6) by Naina Dhingra et al. (2020) contains a proof of concept on pointing direction estimation and object recognition on a poster using stereoscopic range information. This method comes closer to what we want to realise in this paper. They use a full-body image and a user pointing towards a poster. However, the camera is located on top of the poster, an unnatural location for a robot. Their average performance is also only 78.01% and their testing targets had a width of more than 45cm. This implementation does however not only exist out of the challenge to create an accurate pointing direction estimation but also out of an integration with a chatbot. There is however less related work on this topic and we found no standard that would perfectly match with our goal. One example is an im-plementation of Richard A. Bolt (7) and dates from 1980. He created a controlled syntax, such as ‘put < point > that <
point > there’, to give the coordinates of targets as input for
tasks. More recently, iCub (8), a cognitive robot, was used to combine deictic gestures and spoken language for learning new vocabulary (Pizzuto, 2019). The centre of the recognised object is used to fill a database that can be recalled later. Both examples do not match the conversation style that our robot should have, so we will have to come up with a new idea.
Deictic interaction
Setup.The setup for our deictic interaction is illustrated in figure2. We use an Intel Realsense camera which is capable of capturing RGB as well as depth images. We use a single camera setup with a poster located as in the figure to measure our accuracy. It is, however, possible to arrange a different setup with different distances. The only requirement is that
the poster is visible and that the user’s head and hands can be captured by the camera.
Fig. 2. The camera and poster setup
Poster preprocessing.Before the actual communication starts, it is necessary to locate the poster in the environment. A preprocessing algorithm can use a mask to locate any green surfaces. Afterwar ds, it filters out every four circles that form a rectangle and the operator can accept the correct rectangle. This is the only preprocessing step and the location of the poster can be saved to skip this step if the camera was not moved. In this implementation, we assume that the camera does not move, but with a more accurate location algorithm, this could be used as a real-time tracking algorithm for a moving camera.
We are aiming for an implementation that could present and answer questions on any poster presentation. We want to do this as invisible as possible to the end-user, but we will have to give the implementation some knowledge about the ob-jects on the poster. This is why the end-user or a specialist on the topic will have to enter this information in a specific json configuration file. This file contains the object coordinates, a set of information about each object and multiple sets of keywords that are used to pattern match the questions. Each question can match general information or some specific in-formation about an object. The coordinates are used to calcu-late the location in camera space by calculating the offset to the corners. The result of this process can be found in image
3.
3 Method Y N g% d% µ δ D B Nickel et al. (9,10) 2007 1 88.00 90.00 39.0 17.0 50 V Ploetz et al. (11) 2008 2 - 60.10 - - 50 V Droeschel et al. (5) 2011 1 - - 17.0 12.0 141-361 V Shukla et al. (3,4) 2016 2 93.45 76.42 8.33 5.48 0-90 X Pizzuto et al. (8) 2019 1 70.00 76.67 - - 0-90 X Dhingra et al. (6) 2020 1 - 78.01 - - 150 V Our method 2020 1 79.12 88.33 4.29 3.36 80 V
Table 1. Comparison of related systems. Y: Year of publication, N: Number of cameras, g%: accuracy gesture recognition, d%: accuracy pointing direction,µcm: average error of the referenced object,δcm: standard deviation error, D: distance to target in cm, B: full body essential
Pose tracking.We used Openpose’s (12) hand and pose tracking algorithm to recognise the pointing gesture and cal-culate the pointing direction. Out of all current pose tracking software, Openpose performs very fast and accurate and it is the only one that can also track hand keypoints. The RGB images from the Intel Realsense camera go to a server that contains a Docker container with Openpose. The calculated keypoints are returned in json format and saved until new keypoints arrive. The depth value of the keypoints is also ex-tracted from the depth image and saved. This whole process runs in a loop and can calculate the keypoints for four frames per second. A projection of the resulting hand keypoints on the input image is shown in figure4.
Fig. 4. An example of the hand keypoint calculations.
Gesture recognition.Not all deictic gesture recognition algorithms have an accurate gesture recognition model. When only a pointing gesture is expected, it is enough to detect the movement of the arm like Droeschel et al. (5) or Nickel et al. (9,10) do. This is a very fast approach and is good enough when speed is more important than accuracy. For this proof of concept, we created multiple approaches. The first implementation was a single-class support vector machine. This implementation had issues learning on the 3D data and the model was not accurate enough on 2D data. The second implementation used a distance calculation technique that checked which fingers would be stretched out and which not. This technique is based on the idea of Ren.C.Luo et al. (13). This technique also did not perform well enough on the 3D data. Our last technique was a brute force technique that simply detected the highest arm and returned this information. An overview of the comparison
between these algorithms is shown in table2.
We detected during these tests that the depth values of the In-tel Realsense camera were often compleIn-tely wrong on small body parts like the fingers, causing the depth of the first object behind the hand to be returned. This confused the first two algorithms completely and left us no other choice than work-ing with the third brute force algorithm. This is however not a bad thing as we can guess when the user is pointing by the question he or she is asking.
Pointing direction estimation.Shukla et al. (14) com-pared the accuracy of different keypoint combinations to determine the pointing direction. From their results, it was clear that a complete hand-oriented direction would perform the best. For this implementation, it was not possible to use the depth values of the fingers, because of the inaccurate depth image. This is why the direction vector consisted out of the XY-direction from the wrist to the index finger and the Z-direction from the elbow to the wrist. When a user does not bend its wrist, this should return the same direction vector. We compared our approach to a complete XYZ-direction from the elbow to the wrist and our approach got a hugely better result of 89.58% accuracy versus 75.00% accuracy.
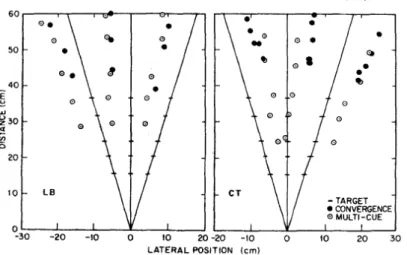
We tested the direction estimation with five test users with a test poster containing the numbers 1 to 12 in a 3x4 matrix on an A3 poster. The participants pointed to each number from four directions and three distances. For the first two direc-tions, the users stand in the middle of the poster and point straight to it with the left or right hand. For the two other di-rections, the users stand in the right corner of the poster and also point with the left or right hand. The results are shown in table3. Due to the corner of the camera, the person’s left hand will be less visible while pointing than the right. This causes Openpose to have issues detecting the hand keypoints and this reflects in a worse accuracy for the left hand at close distances. The accuracy while pointing from a corner is also less good. This is caused by the depth camera which is not able to detect any difference between the depth of the wrist and the poster while standing close to the poster.
4
Technique Acc left Acc right Detection rate Total acc s/image
Technique 1 76.83 81.49 67.62 79.12 0.0008
Technique 2 72.49 82.45 79.88 78.69 0.0001
Technique 3 - - 100.00 - 0.0001
Nickel et al. (9,10) - - 87.6 75 1.8
Shukla et al. (3,4) - - 93.45 64.20
-Table 2. A comparison of the gesture recognition techniques Distance Left
straight Rightstraight Leftcorner Rightcorner
0 cm 46.67 98.33 51.67 65.00
60 cm 38.33 91.67 65.00 80.00
80 cm 76.67 98.33 85.00 93.33
Table 3. Accuracy percentages from the pointing direction tests.
Verbal interaction
Research study.For this proof of concept, we used a rule-based chatbot implementation using the Artificial Intelligence Markup Language (AIML) (15). AIML is an XML extension where you can define complete conversation flows using input-output patterns. We created a preprocess-ing program that transforms the keywords from the json configuration file to an input pattern that can be used to match the user’s question to a question about poster objects. We conducted a small user study to gather some more insight into how many keywords are necessary to match the input accurately to the correct question.
In the study, we asked three users to ask ten questions while pointing and ten questions without pointing. We divided the questions into groups according to the number of keywords that were necessary to match the input with the right question from the json file. A pointing gesture was also interpreted as a keyword because it is a reference to an object. We recognised three groups of questions. The first group consisted of two keywords. An example of such a question is ‘What does a Spinosaurus eat?’. The keywords in such a sentence are ‘Spinosaurus’ and ‘eat’. The second group consisted of multiple keywords. This included an object and a description of a characteristic of the object. For example, in the sentence ‘How long is the tail of the Tyrannosaurus?’, the keywords are ‘long’, ‘tail’ and ‘Tyrannosaurus’. The third group consisted of all other questions, where it was not possible to gather a group of keywords that represent the question. In these kinds of questions, it also is necessary to know the structure of the sentence or other world knowledge. An example of such a question is ‘Does this animal jump or run?’.
73.33% of both the verbal-only and the deictic questions be-longed to the first two groups. This means that we could safely use this technique to answer most of the questions. Note that some of the questions from group 3 contained gen-eral questions and not questions about the characteristics of the objects. Thus, if the user gets the task to only ask ques-tions about the characteristics of the objects, the accuracy
{
. . . . # O b j e c t d e f i n i t i o n s " Q u e s t i o n s " : [
{
" i d " : " s i z e " ,
" keywords " : [ [ " BIG " ] , [ " HIGH " ] ] }
. . . # O th er q u e s t i o n s ]
}
Fig. 5. An example of the keyword definition in the json configuration file.
should be even better.
AIML preprocessing.Figure 5 shows an example of the keyword definition in the json configuration file. The list of keywords is shortened and should contain as much keyword combinations as you can think of that match with the corre-sponding characteristic. The array can also contain more than one keyword and the identifier matches with a characteristic identifier in the object definitions. To match the object, we need an extra keyword that represents its name or description like ‘Tyrannosaurus’ or it can be determined by following the pointing direction. When the object is defined by both a ver-bal keyword and a pointing direction, we choose to give the highest priority to the verbal identifier.
The AIML patterns consist of every combination of star tags and the keywords. The star tag is a tag that matches one or more words. If we assume that the keywords are already in the right order then the following combinations are possible for the keywords ‘LENGTH’ and ‘TAIL’: ‘LENGTH TAIL’, ‘* LENGTH TAIL’, ‘* LENGTH * TAIL’, ‘* LENGTH * TAIL *’, ‘LENGTH * TAIL *’ and ‘LENGTH TAIL *’. The object identifiers are separately matched using recursive pat-tern matching.
Integration of verbal and deictic behaviour.The finished implementation consists of two loops. The first loop uses the camera images to track the person standing in front of the camera. The highest hand is used to track the target to which the user is pointing. The second loop is waiting for the user to ask a question. The audio is transformed to text and this text is used as an input for the AIML interpreter. This interpreter recognises the keywords and returns a question and target id. If the target id is not found, the target is set as the pointing target from the first loop. The corresponding answer to the question is extracted from the json file and the response is transformed to speech and returned to the user.
5
Evaluation
The complete setup is evaluated by a small proof of concept study with five participants. They were ordered to only ask about the characteristics of the objects on the poster. The poster contained the sun and the planets of our galaxy. We first asked the participants to play around with the implementation and ask whatever they wanted. They were very positive about the chatbot implementation and its ability to understand each question. After these initial tests, we asked them to search for five characteristics in two ways. For the first task, they could only use their voice and for the second task they could not use the name of the object, but they had to use a pointing gesture instead.
The chatbot performed very well and 22 out of 25 verbal-only questions were correctly answered. The verbal-only mistakes were made in the speech to text transformation. With the integrated verbal and deictic interaction, 18 out of 25 questions were correctly answered. Six of those errors were faults of the target estimation while pointing to Mars and one of those while pointing to Pluto. Mars and Pluto are both small objects and users did not point very accurately or did point with a big angle, which caused the implementation to guess the wrong target.
The users found the deictic interaction a nice addition to the interaction and even found it easier to use the multimodal in-teraction to gather the information for the tasks. They found it, however, a bit hard to point exactly at very small objects, which is why they would like it more with bigger objects or even 3D objects.
Conclusion and future work
In this paper, we proposed a revolutionary proof of concept of a trained social robot that can demonstrate any poster presentation. It combines deictic gestures and verbal com-munication to improve human-robot interaction. With this implementation, the research of Komatsubara et al. (1) could be extended with a real autonomous robot and tested within multiple populations.
However, there are still a lot of things to do until this imple-mentation is ready to use in practice. Because of the lack of participants, the study should be expanded and thoroughly examined. This should give us more insight into the accuracy and possible improvements. We also still use brute gesture recognition. Another recognition algorithm could improve our implementation or expand it with new gestures. There were also some problems with Openpose, the depth camera and the voice recognition that could be improved in future implementations.
References
1. Tsuyoshi Komatsubara, Masahiro Shiomi, Takayuki Kanda, and Hiroshi Ishiguro. Can using pointing
ges-tures encourage children to ask questions? International Journal of Social Robotics, 10(4):387–399, 2018. 2. Kwan Min Lee, Younbo Jung, Jaywoo Kim, and
Sang Ryong Kim. Are physically embodied social agents better than disembodied social agents?: The ef-fects of physical embodiment, tactile interaction, and people’s loneliness in human–robot interaction. Interna-tional Journal of Human-Computer Studies, 64(10):962 – 973, 2006.
3. Dadhichi Shukla, Özgur Erkent, and Justus Piater. A multi-view hand gesture rgb-d dataset for human-robot interaction scenarios. pages 1084–1091, 08 2016. 4. Dadhichi Shukla, Özgur Erkent, and Justus Piater.
Prob-abilistic detection of pointing directions for human-robot interaction. pages 1–8, 11 2015.
5. David Droeschel, Jörg Stückler, and Sven Behnke. Learning to interpret pointing gestures with a time-of-flight camera. pages 481–488, 01 2011.
6. Naina Dhingra, Eugenio Valli, and Andreas Kunz. Recognition and localisation of pointing gestures using a rgb-d camera, 2020.
7. Richard A. Bolt. “put-that-there”: Voice and gesture at the graphics interface. In Proceedings of the 7th An-nual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’80, page 262–270, New York, NY, USA, 1980. Association for Computing Machinery. 8. G. Pizzuto and A. Cangelosi. Exploring deep models for comprehension of deictic gesture-word combinations in cognitive robotics. In 2019 International Joint Confer-ence on Neural Networks (IJCNN), pages 1–7, 2019. 9. Kai Nickel and Rainer Stiefelhagen. Real-time
recog-nition of 3d-pointing gestures for human-machine-interaction. volume 2781, pages 557–565, 09 2003. 10. Kai Nickel and Rainer Stiefelhagen. Visual recognition
of pointing gestures for humanrobot. Image Vision Com-put., 25:1875–1884, 12 2007.
11. Jan Richarz, Thomas Ploetz, and Gernot Fink. Real-time detection and interpretation of 3d deictic gestures for interaction with an intelligent environment. pages 1–4, 12 2008.
12. Z. Cao, G. Hidalgo Martinez, T. Simon, S. Wei, and Y. A. Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1– 1, 2019.
13. R. C. Luo, Shu-Ruei Chang, and Yee-Pien Yang. Track-ing with pointTrack-ing gesture recognition for human-robot interaction. In 2011 IEEE/SICE International Sym-posium on System Integration (SII), pages 1220–1225, 2011.
14. David Kortenkamp, Eric Huber, G. Wasson, and Met-rica Inc. Integrating a behavior-based approach to active stereo vision with an intelligent control architecture for mobile robots. 12 1997.
15. Aiml: "aiml 2.0 draft specification released". aiml. foundation, 01 2013.
1
Ontwerp en evaluatie van geïntegreerd verbaal
en deiktisch gedrag in interactieve media
Julie De Meyer
Promotors: Tony Belpaeme, Francis wyffels Begeleider: Pieter Wolfert
Abstract – Wanneer mensen met elkaar communiceren, gebrui-ken ze vaak meer dan één communicatiekanaal. Naast ver-bale communicatie wordt ook deiktische communicatie vaak ge-bruikt om bijvoorbeeld de aandacht op een bepaalde richting of object te plaatsen. Eerder onderzoek toont aan dat het toevoe-gen van herkenning van aanwijzintoevoe-gen aan een sociale robot als gevolg heeft dat kinderen meer vragen stellen tijdens een poster presentatie. Dit onderzoek werd echter zonder autonome robot uitgevoerd. Deze thesis stelt een autonome implementatie voor die elke poster kan presenteren zonder opnieuw getraind of ge-programmeerd te worden. Deze implementatie bestaat uit twee grote delen: de deiktische interactie en de verbale interactie. De initiële testen tonen aan dat de deiktische interactie, met uitzon-dering van de gebaren herkenning, heel competitief is met de huidige technieken. In een kleine proof of concept studie evalu-eerden de gebruikers de implementatie zeer positief en ervoeren ze de deiktische interactie als een meerwaarde voor het gesprek. De chatbot ontving ook heel goede feedback en detecteerde bijna alle vragen correct. Voor toekomstig onderzoek is het noodza-kelijk om de testen verder te zetten, maar deze implementatie ziet er voor nu veelbelovend uit en zou zelfs kunnen dienen als basis voor toekomstige interactieve media.
mens-robot interactie | multimodale interactie | sociale robots | deiktische ge-baren
Introductie
Spraak gestuurde media verschijnt meer en meer in ons da-gelijks leven terwijl hun mensachtige verbale communicatie steeds beter wordt. Mensachtige communicatie bevat echter meerdere andere communicatie kanalen zoals expressies, blik en gebaren. Deze kanalen kunnen gebruikt worden als input om een analyse van de omgeving te maken of als output om de gebruiker extra informatie aan te kunnen bieden. Wanneer een robot of agent meerdere van deze kanalen gebruikt, noemen we de communicatie multimodaal. Komatsubara et al. (1) stellen in hun onderzoek voor om een extra deiktisch communicatiekanaal te gebruiken bij een sociale robot om vragen te beantwoorden over educatieve posters. Ze hebben een experiment opgesteld waar een robot een presentatie gaf over een ruimtestation en ruimteschip aan kinderen van de lagere school. Na de presentatie werden de kinderen aangemoedigd om vragen te stellen. Het expe-riment werd opgedeeld in twee groepen onder verschillende condities. Bij de eerste groep kon de robot enkel verbale vragen verstaan. Bij de tweede groep kon de robot ook zien wat de kinderen aanwezen. De resultaten ondersteunden de hypothese dat de vaardigheid van een robot om aanwijzingen
te begrijpen kinderen zou aanmoedigen om meer vragen te stellen. Het is wel belangrijk om op te merken dat dit experiment een Wizard-of-Oz experiment was. Dit betekent dat de robot volledig bestuurd werd door een mens.
In deze paper wordt een autonoom systeem voorgesteld dat een vergelijkbare poster presentatie zou kunnen geven. We gaan er zelfs dieper op in en stellen een systeem voor dat elke poster zou kunnen presenteren zonder opnieuw getraind of geprogrammeerd te worden. We analyseerden hoe accuraat het systeem presteert en of er situaties voorkomen waar de robot faalt. We voerden ook een kleine proof of concept stu-die uit met het volledige systeem dat test of de gebruikers de deiktische gebaren als een meerwaarde aanvoelen bovenop de verbale communicatie.
Dit systeem kan gebruikt worden met minimale hardware vereisten en het is ook mogelijk om dit in een sociale robot te verwerken in de toekomst. Volgens eerder onderzoek (2) zou dit de evaluatie van het systeem moeten verbeteren. Een robot lichaam geeft bovendien ook meer mogelijkheden voor extra communicatie kanalen.
Gerelateerd werk
Deze implementatie bestaat uit een chatbot implementatie gecombineerd met een herkenning van aanwijzingen. Er bestaan meerdere ontwerpen voor het herkennen van aanwij-zingen, maar het merendeel van deze implementaties is niet van toepassing op deze domein-specifieke omgeving van een poster presentatie. Een vergelijking van de bestaande ontwerpen kan teruggevonden worden in tabel1.
Shukla et al. (3) ontwierpen een dataset voor handgebaren en een model om gebaren te herkennen voor mens-robot interactie. Hun model herkent meer dan enkel aanwijzingen en heeft een heel goede accuraatheid van 93.45%. Het model heeft ook maar een beperkte hoeveelheid training data nodig (39 training afbeeldingen en 12 tuning afbeeldingen) en het heeft geen kinematische kennis nodig. Ze implementeerden ook een richting schatter voor de aanwijzingen (4) met een accuraatheid van 76.42% met twee camera ’s en 64.20% met één camera. Voor deze implementatie verkiezen we een enkele camera om het mogelijk te maken om dit programma later te integreren met een sociale robot. Het model van Shukla et al. is ook getest op close-up afbeeldingen van de handen zoals in figuur1. Dit is niet geschikt voor onze
2 implementatie aangezien we altijd een overzicht van de
omgeving met de poster nodig hebben.
Shukla et al. hebben ook verschillende methoden voor de richting bepaling vergeleken. Hun eigen implementatie bestaat uit enkel hand coördinaten en scoort het best met een gemiddelde error van 8.33 cm. De tweede beste implementa-tie komt van Droeschel et al. (5), welke een Gaussian Process Regression creëerde van de schouder-hand richting. Deze methode komt dichter bij wat wij nodig hebben aangezien ze een afbeelding van het volledige lichaam gebruiken. Helaas bevat deze implementatie een gemiddelde error van 17.0 cm, wat vrij hoog is als je rekening houdt met dat de objecten op de poster dan minimum 17.0 cm van elkaar zouden moeten staan. Droeschel’s gebaar herkenning software gebruikt geen hand coördinaten, maar is eerder een combinatie van drie fases: de preparatie fase, de stilstaande fase en de terugtrekkende fase. Deze methode is ook vrij snel, maar geeft veel valse positieve resultaten.
Fig. 1. Opstelling experiment Shukla et al. (3)
Een recentere en meer gerelateerde paper (6) van Naina Dhingra et al. (2020) bevat een concept voor de schatting van de wijs richting en object herkenning op een poster met behulp van stereoscopische diepte informatie. Deze methode leunt dichter aan bij wat wij willen realiseren met onze implementatie. Ze gebruiken een afbeelding van het volledige lichaam waarin ook de poster in beeld is. De camera is echter wel bovenop de poster geplaatst, wat een onnatuurlijke locatie zou zijn voor de camera van een robot. Hun algemene performantie is slechts 78.01% en de test objecten op de poster hebben een breedte van meer dan 45 cm.
Deze implementatie bestaat niet enkel uit de uitdaging om een accurate detectie van de wijs beweging te implemente-ren, maar ook uit de integratie met een chatbot. Hierover is er echter veel minder gerelateerd werk en er werd geen stan-daard gevonden die voor deze implementatie geschikt zou zijn. Een voorbeeld is de implementatie van Richard A. Bold (7) en dateert al van 1980. Hij creëerde een syntaxis, zoals ‘put < point > that < point > there’, om coördinaten van
objecten als input te geven voor een bepaalde taak. De cog-nitieve robot iCub (8) is een nieuwer voorbeeld waar Pizzuto et al. verschillende deiktische gebaren combineerde met ge-sproken taal om de robot nieuwe woorden aan te leren. Het centrum van het herkende object werd gebruikt om een data-base aan te vullen die later kon bevraagd worden. Beide voor-beelden komen niet volledig overeen met de stijl van conver-satie die wij wensen op te bouwen, dus hebben we een nieuw idee uitgewerkt.
Deiktische interactie
Opstelling.De opstelling voor onze deiktische interactie is geïllustreerd in figuur2. We gebruiken een Intel Realsense camera die capabel is om RGB en diepte afbeeldingen te ma-ken. We gebruiken een enkele camera opstelling met een pos-ter die geplaatst is zoals in de figuur om de accuraatheid uit deze paper te meten. Het is echter wel mogelijk om een an-dere opstelling te gebruiken met anan-dere afstanden. De enige voorwaarde is dat het hoofd en de handen van de gebruiker en de poster zichtbaar zijn in de afbeelding.
Fig. 2. De camera en poster opstelling
Poster voorbereiding.Voor de eigenlijke communicatie start, is het noodzakelijk om de poster te lokaliseren in de omgeving. Een voorbereidend algoritme maakt gebruik van een masker om de groene oppervlakten te herkennen. Daarna worden elke vier cirkels uitgefilterd die een rechthoekig vorm aannemen. De gebruiker kan hieruit de juiste vier hoeken van de poster selecteren. Dit is de enige voorbereidende stap en de locatie kan hierna opgeslagen worden zodat dit niet elke keer moet uitgevoerd worden. In deze implementatie nemen we aan dat de camera niet beweegt, maar met een accurater detectie algoritme zou het ook mogelijk moeten zijn om realtime tracering van de poster toe te staan zodat de camera kan bewegen.
We probeerden een implementatie op te bouwen die elke pos-ter zou kunnen presenpos-teren en er vragen over zou kunnen be-antwoorden. We deden dit zo abstract als mogelijk voor de eindgebruiker, maar de robot moet natuurlijk wel weten wat er op de poster staat. Daarvoor hebben we een specifiek json configuratie bestand opgesteld waar de gebruiker of een spe-cialist deze informatie in kan toevoegen. Dit bestand bevat de object coördinaten, informatie over elk van de objecten en meerdere sleutelwoorden die gebruikt kunnen worden om een vraag te herkennen. De coördinaten worden gebruikt om de locatie van de objecten te berekenen in de afbeelding door
3 Method Y N g% d% µ δ D B Nickel et al. (9,10) 2007 1 88.00 90.00 39.0 17.0 50 V Ploetz et al. (11) 2008 2 - 60.10 - - 50 V Droeschel et al. (5) 2011 1 - - 17.0 12.0 141-361 V Shukla et al. (3,4) 2016 2 93.45 76.42 8.33 5.48 0-90 X Pizzuto et al. (8) 2019 1 70.00 76.67 - - 0-90 X Dhingra et al. (6) 2020 1 - 78.01 - - 150 V Our method 2020 1 79.12 88.33 4.29 3.36 80 V
Tabel 1. Vergelijking van gerelateerde systemen. Y: Jaar van publicatie, N: Aantal camera ’s, g%: Accuraatheid van de gebaren herkenning, d%: Accuraatheid van de wijs
richting,µcm: Gemiddelde error van het doel object,δcm: Standaard error, D: Afstand tot het doel in cm, B: Volledig lichaam zichtbaar de offset van de hoeken te gebruiken. Het resultaat van dit
proces wordt getoond in afbeelding3.
Fig. 3. De gelokaliseerde objecten op de poster
Lichaam tracering.We gebruikten Openpose’s (12) hand en lichaam tracering algoritme om het aanwijzen te herken-nen en de richting van het wijzen te berekeherken-nen. Van alle be-staande lichaam tracering software presteert Openpose heel snel en accuraat. Het is ook de enige die de hand coördinaten zo nauwkeurig kan traceren. De RGB afbeeldingen van de Intel Realsense camera worden naar een server gestuurd die een Docker container bevat met Openpose op. De berekende coördinaten worden teruggestuurd in json formaat en opge-slagen tot er nieuwe coördinaten arriveren. De diepte waar-des van de coördinaten worden geëxtraheerd van de diepte afbeelding en eveneens opgeslagen. Dit hele proces verloopt in een lus en verloopt aan vier frames per seconde. Een pro-jectie van de resulterende hand coördinaten wordt getoond in figuur4.
Fig. 4. Een voorbeeld van de berekende hand coördinaten.
Gebaar herkenning.Niet alle algoritmes voor het her-kennen van deiktische gebaren hebben een accuraat model om de types gebaren te herkennen. Wanneer we enkel wijs gebaren verwachten, is het ook genoeg om de beweging van de arm te volgen zoals Droeschel et al. (5) of Nickel et al. (9,10). Dit is een zeer snelle techniek en is voldoende wanneer snelheid belangrijker is dan accuraatheid. Voor deze implementatie creëerden we meerdere technieken. De eerste implementatie was een single-class support vector machine. Deze implementatie had problemen om op 3D data te leren en het model was beter, maar nog niet accuraat genoeg op 2D data. De tweede implementatie gebruikt een techniek met afstand berekeningen om na te gaan welke vingers uitgestrekt zijn en welke niet. Deze techniek is gebaseerd op het idee van Ren.C.Luo et al. (13). Deze techniek werkte ook niet heel goed op 3D data, maar detecteerde al sneller en meer wijs gebaren. De laatste techniek was een directe techniek die simpelweg de hoogste arm detecteerde en deze informatie terug gaf. Een overzicht van deze algoritmes wordt getoond in tabel2.
Tijdens deze testen ontdekten we dat de diepte waardes van de Intel Realsense camera soms compleet fout waren op kleine lichaamsdelen zoals de vingers. Dit zorgde ervoor dat de diepte van deze lichaamsdelen gelijk was aan de diepte van het eerste object achter het lichaamsdeel. Dit bracht de eerste twee algoritmes compleet in de war en gaf ons geen andere keuze dan te werken met het derde directe techniek. Dit is echter niet volledig een slechte keuze aangezien we in deze implementatie ook uit de verbale informatie kunnen ra-den wanneer de gebruiker aan het wijzen is.
4
Technique Acc left Acc right Detection rate Total acc s/image
Technique 1 76.83 81.49 67.62 79.12 0.0008
Technique 2 72.49 82.45 79.88 78.69 0.0001
Technique 3 - - 100.00 - 0.0001
Nickel et al. (9,10) - - 87.6 75 1.8
Shukla et al. (3,4) - - 93.45 64.20
-Tabel 2. Een vergelijking van de technieken voor het herkennen van wijs gebaren.
Schatting richting.Shukla et al. (14) vergeleek de accu-raatheid van verschillende coördinaat combinaties om de richting van het wijzen te bepalen. Uit hun resultaten was het duidelijk dat de volledige hand-georiënteerde richting het best presteert. Voor deze implementatie is het echter niet mogelijk om de diepte waardes van de vingers te gebruiken door de slechte accuraatheid van de diepte afbeeldingen. Daarom bestaat onze richtingsvector uit de XY-richting van de pols naar de wijsvinger en de Z-richting van de elleboog naar de pols. Wanneer de gebruiker zijn pols niet buigt, zou dit dezelfde richtingsvector moeten teruggeven. We vergeleken deze aanpak met de volledige XYZ-richting van de elleboog tot de pols en onze nieuwe aanpak behaalde een veel beter resultaat van 89.58% ten opzichte van 75.00% accuraatheid.
We testten de schatting voor de richting met vijf testpersonen en een A3 test poster met de nummers 1 tot 12 op in een 3x4 matrix. De deelnemers wezen naar elk van de nummers vanuit vier posities en vanuit drie afstanden. Bij de eerste twee posities stond de gebruiker in het midden voor de poster en wees hij recht naar de poster met zijn linker- of rechterhand. Voor de andere posities stond de gebruiker in de rechterhoek van de poster en wees hij ook met de linker- en rechterhand. De resultaten zijn zichtbaar in tabel3. Doordat de camera in een hoek staat, is de linkerhand van de persoon steeds iets minder goed zichtbaar dan de rechterhand. Dit zorgt ervoor dat Openpose moeite heeft met de coördinaten van deze hand te bepalen en dit is zichtbaar in de slechte score voor de linkerhand bij kleine afstanden. Wanneer de gebruikers vanuit de rechterhoek wezen, was de accuraatheid ook slechter. Dit wordt veroorzaakt door de camera die niet in staat is om het verschil in diepte tussen de hand en de poster te detecteren. Hoe dichter de persoon bij de poster staat, hoe slechter dit is.
Distance Left
straight Rightstraight Leftcorner Rightcorner
0 cm 46.67 98.33 51.67 65.00
60 cm 38.33 91.67 65.00 80.00
80 cm 76.67 98.33 85.00 93.33
Tabel 3. Accuraatheid in percentage van de richting testen.
Verbale interactie
Voorbereidend onderzoek.Voor deze implementatie gebruikten we een regel-gebaseerde chatbot die gebruik maakt van de Artificial Intelligence Markup Language
(AIML) (15). AIML is een XML extensie waarmee je volledige gesprekken kunt definiëren met gebruik van input-output patronen. Een voorbereidend script transfor-meert de sleutelwoorden van het json configuratie bestand om tot een input patroon dat kan gebruikt worden om de gebruiker ’s vraag te matchen met een vraag over een poster object. We voerden een kleine test uit om meer inzicht te krijgen in hoeveel sleutelwoorden noodzakelijk zijn om een input accuraat te matchen met de overeenkomstige vraag. In de test vroegen we drie personen om tien vragen te stellen terwijl ze wezen en tien vragen zonder te wijzen. We verdeelden achteraf de vragen in groepen volgens het aantal sleutelwoorden dat noodzakelijk bleek te zijn om de input met de juiste vraag van het json bestand te matchen. Een wijs beweging werd ook geïnterpreteerd als een sleutelwoord aangezien het een referentie is naar een object. Alle vragen werden uiteindelijk in drie groepen verdeeld. De eerste groep bestaat uit vragen die door twee sleutelwoorden gedefinieerd konden worden. Een voorbeeld van zo een vraag is ‘Wat eet een Spinosaurus?’. De sleutelwoorden in deze zin zijn ‘Spinosaurus’ en ‘eet’. De tweede groep bevat vragen die kunnen gedefinieerd worden door meerdere sleutelwoorden. Deze bevatten een onderwerp en een beschrijving van een karakteristiek die men te weten wil komen. Bijvoorbeeld, in de vraag ‘Hoe lang is de staart van de Tyrannosaurus?’ zijn de sleutelwoorden ‘lang’, ‘staart’ en ‘Tyrannosaurus’. De derde groep bestaat uit alle andere vragen die niet door sleutelwoorden voor te stellen zijn. Bij deze soort vragen is het noodzakelijk om de structuur van de zin goed te begrijpen of om een bepaalde voorgaande kennis te hebben. Een voorbeeld van een vraag uit de derde groep is ‘Loopt of springt dit dier?’.
73.33% van beide soorten vragen behoorde tot de eerste twee groepen. Dit betekent dat we met een techniek die sleutel-woorden zoekt, de meeste vragen juist zouden kunnen be-antwoorden. Sommige vragen van groep 3 waren echter wel heel generieke vragen en geen vragen over specifieke karak-teristieken van de objecten op de poster. Als we dus de ge-bruiker duidelijk maken dat de chatbot enkel vragen over de karakteristieken van de objecten kan beantwoorden, zou de performantie alleen maar stijgen.
AIML voorbereiding.Figuur 5 toont een voorbeeld van de definitie van de sleutelwoorden in het json configuratie bestand. De lijst van sleutelwoorden is verkort en kan zo veel sleutelwoorden bevatten als je kan bedenken die overeen komen met de bijhorende karakteristiek. Elke deellijst bevat
5 { . . . . # O b j e c t d e f i n i t i o n s " Q u e s t i o n s " : [ { " i d " : " s i z e " ,
" keywords " : [ [ " BIG " ] , [ " HIGH " ] ] }
. . . # O th er q u e s t i o n s ]
}
Fig. 5. Een voorbeeld van de sleutelwoord definities in het json configuratie
be-stand.
een combinatie van sleutelwoorden. De id komt overeen met een id voor een karakteristiek bij de object definitie. Om een object uit de input te kunnen halen, hebben we een extra sleutelwoord nodig die het object beschrijft. Het object kan ook bepaald worden door de aanwijsrichting te berekenen. Wanneer het object zowel gedefinieerd werd in de input tekst als bij de aanwijsrichting, dan wordt de tekst als hoogste prioriteit aanzien.
De AIML patronen bestaan uit elke combinatie van star tags en sleutelwoorden. De star tag is een tag die een of meerdere woorden matches. We nemen aan dat de sleutelwoorden al in de juiste volgorde staan. Dan zijn bijvoorbeeld alle mogelijke patronen voor de sleutelwoorden ‘LENGTH’ en ‘TAIL’ ge-lijk aan ‘LENGTH TAIL’, ‘* LENGTH TAIL’, ‘* LENGTH * TAIL’, ‘* LENGTH * TAIL *’, ‘LENGTH * TAIL *’ en ‘LENGTH TAIL *’. De id van het object wordt apart ge-matcht met behulp van recursieve pattern matching.
Integratie van verbale en deiktische communicatie.De afgewerkte implementatie bestaat uit twee lussen. De eer-ste lus start met de camera beelden die gebruikt worden om de locatie van de persoon voor de camera de detecteren. De hoogste hand wordt dan gebruikt om het object op de pos-ter te bepalen waar de gebruiker naar aan het wijzen is. De tweede lus wacht tot de gebruiker een vraag stelt. Het geluid wordt getransformeerd naar tekst en deze tekst wordt dan ge-bruikt als input voor de AIML verwerker. Deze verwerker herkent de sleutelwoorden en geeft de id van de vraag en het object terug. Als de id van het object niet in de tekst ge-vonden wordt, wordt de id van de wijsrichting gebruikt. Het antwoord op de vraag wordt opgezocht in het json configu-ratie bestand en het wordt vervolgens getransformeerd naar audio en afgespeeld.
Evaluatie
De volledige implementatie werd geëvalueerd met een kleine gebruikersevaluatie die bestond uit vijf deelnemers. We vroegen hen om enkel vragen te stellen over de karakteris-tieken van de objecten op de poster. De poster die gebruikt werd bevatten de zon en ons zonnestelsel. We vroegen de deelnemers eerst om even vrij de implementatie uit te proberen en hun bemerkingen mee te delen. Ze waren vooral
zeer positief over de chatbot implementatie en de vloeiende manier waarop vragen beantwoord werden. Na deze verken-ning, vroegen we hen om vijf karakteristieken te weten te komen op twee manieren. Bij de eerste manier mochten ze enkel hun stem gebruiken en voor de tweede manier mochten ze objecten aanwijzen op de poster, maar niet hun naam benoemen. Op deze manier moest de implementatie wel de wijsrichting bepalen om het object te weten te komen. De chatbot presteerde heel goed en beantwoorde 22 van de 25 verbale vragen correct. De enige fouten werden gemaakt door de transformatie van spraak naar tekst. Bij de ge-combineerde interactie werden 18 van de 25 vragen correct beantwoord. Zes van deze fouten werden gemaakt bij de bepaling van de wijsrichting en het object terwijl er gewezen werd naar Mars of Pluto. Dit zijn beide kleine planeten en de gebruikers bleken niet in staat om zeer accuraat naar deze kleine objecten te wijzen. Dit veroorzaakte een afwijking van de richting en zorgde ervoor dat de implementatie een verkeerd object detecteerde.
De gebruikers vonden de deiktische interactie een waarde-volle toevoeging bij de communicatie en ze vonden het zelfs gemakkelijker om de taken op te lossen met gebruik van de multimodale interactie. Ze vonden het echter wel moeilijk om exact naar de kleinere objecten te wijzen, waardoor ze het nog aangenamer zouden vinden als deze implementatie gebruikt zou worden bij grotere objecten of 3D objecten.
Conclusie and toekomstig werk
In deze paper stelden we een revolutionair concept voor van een getrainde implementatie voor sociale robots die elke poster kan demonstreren. Deiktische en verbale interactie worden gecombineerd met zicht op het verbeteren van de mens-robot interactie. Met deze implementatie zou het onderzoek van Komatsubara et al. (1) kunnen uitgebreid worden met een echte autonome robot en ook getest worden op meerdere populaties.
Er zijn echter nog veel zaken die verbeterd en uitgebreid kun-nen worden voordat deze implementatie in de praktijk wordt gebruikt. Door een gebrek aan testpersonen zou de gebruiker-sevaluatie nog uitgebreid en verder onderzocht moeten wor-den. Dit zou ons meer inzicht moeten geven in de accuraat-heid en mogelijke optimalisaties. We gebruiken hier ook nog steeds de directe herkenning voor het type gebaren. Een an-der algoritme zou de implementatie kunnen verbeteren, maar het ook mogelijk maken om andere gebaren toe te voegen. Er waren ook enkele problemen met Openpose, de diepte ca-mera en de stemherkenning.
Referenties
1. Tsuyoshi Komatsubara, Masahiro Shiomi, Takayuki Kanda, and Hiroshi Ishiguro. Can using pointing gestu-res encourage children to ask questions? International Journal of Social Robotics, 10(4):387–399, 2018.
6 2. Kwan Min Lee, Younbo Jung, Jaywoo Kim, and
Sang Ryong Kim. Are physically embodied social agents better than disembodied social agents?: The ef-fects of physical embodiment, tactile interaction, and people’s loneliness in human–robot interaction. Interna-tional Journal of Human-Computer Studies, 64(10):962 – 973, 2006.
3. Dadhichi Shukla, Özgur Erkent, and Justus Piater. A multi-view hand gesture rgb-d dataset for human-robot interaction scenarios. pages 1084–1091, 08 2016. 4. Dadhichi Shukla, Özgur Erkent, and Justus Piater.
Pro-babilistic detection of pointing directions for human-robot interaction. pages 1–8, 11 2015.
5. David Droeschel, Jörg Stückler, and Sven Behnke. Learning to interpret pointing gestures with a time-of-flight camera. pages 481–488, 01 2011.
6. Naina Dhingra, Eugenio Valli, and Andreas Kunz. Re-cognition and localisation of pointing gestures using a rgb-d camera, 2020.
7. Richard A. Bolt. “put-that-there”: Voice and gesture at the graphics interface. In Proceedings of the 7th An-nual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’80, page 262–270, New York, NY, USA, 1980. Association for Computing Machinery. 8. G. Pizzuto and A. Cangelosi. Exploring deep models for comprehension of deictic gesture-word combinations in cognitive robotics. In 2019 International Joint Confe-rence on Neural Networks (IJCNN), pages 1–7, 2019. 9. Kai Nickel and Rainer Stiefelhagen. Real-time
re-cognition of 3d-pointing gestures for human-machine-interaction. volume 2781, pages 557–565, 09 2003. 10. Kai Nickel and Rainer Stiefelhagen. Visual recognition
of pointing gestures for humanrobot. Image Vision Com-put., 25:1875–1884, 12 2007.
11. Jan Richarz, Thomas Ploetz, and Gernot Fink. Real-time detection and interpretation of 3d deictic gestures for interaction with an intelligent environment. pages 1–4, 12 2008.
12. Z. Cao, G. Hidalgo Martinez, T. Simon, S. Wei, and Y. A. Sheikh. Openpose: Realtime multi-person 2d pose estimation using part affinity fields. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1– 1, 2019.
13. R. C. Luo, Shu-Ruei Chang, and Yee-Pien Yang. Trac-king with pointing gesture recognition for human-robot interaction. In 2011 IEEE/SICE International Sym-posium on System Integration (SII), pages 1220–1225, 2011.
14. David Kortenkamp, Eric Huber, G. Wasson, and Me-trica Inc. Integrating a behavior-based approach to ac-tive stereo vision with an intelligent control architecture for mobile robots. 12 1997.
15. Aiml: äiml 2.0 draft specification released". aiml. foundation, 01 2013.
Lay summary
A social robot is a robot that has been built to help people. Some social robots can talk, others can perform actions like helping someone to get out of bed. Speaking to a robot is an easy technique to give commands because we already learn to talk to other people from a young age. However, for robots, it is not easy to understand a human. Without always knowing it, we use a lot more techniques to show other people what we mean. We show emotions, move our hands, make eye contact and more. One of the techniques that we explored more in this thesis is the use of deictic gestures. Deictic gestures are movements with the hands that we make to show someone a specific direction or object.
In 2019, a group of researchers set up a study with a robot that could answer questions about the content of a poster. Two groups of children were instructed to ask the robot as many questions as they wanted. The first group could only use their voice and the second group could use their voice, but also their hands to point at an object on the poster. The researchers found out that the children asked more questions when they were allowed to point at the poster. This is a very nice idea, but the robot that was used in this study was controlled by a human. In this thesis, we made a program that can answer questions on any poster presentation without the help of any human. Those questions can be asked by using only your voice or together with a deictic gesture.
The program exists out of two parts: the part that detects deictic gestures and the part that understands verbal questions. The goal of the first part is to detect the object on the poster to which the user is pointing. We use a special camera that can detect how far away something is. With the help of this camera, we can detect the position of the user talking to the robot. With this position, we can detect if and when the user is pointing, what the pointing direction is and to which target this direction belongs. The program then passes this information to the second part.
The second part is a chatbot, a program that can understand and respond to humans. This chatbot uses a technique that looks for certain words inside a sentence. If the right words are found, we can know which question was asked by the user. The user can men-tion a target inside the quesmen-tion or the target can be retrieved from the first part of the program.
Our tests show us that our implementation for the deictic gestures works at least as well as already existing research. Only the recognition of the type of gesture is not working very good. This is not a problem, because this program only needs one type of gestures. We created also a small study with some participants that could try out this program. The participants were very positive and they liked the implementation with the gestures more than the one without the gestures. The chatbot also received very good feedback and understood all participants very well.
We still need to perform more tests to make sure everything works well and to examine the behaviour of the participants towards a robot with this ability. There are some improvements to be made, but the current program already showed us that the idea works and that a robot can give a poster presentation on its own.
Acknowledgments
This thesis had been a great choice. I learned a lot of new things about a subject that I was not familiar with and I loved working with all these technologies. Combining and optimising them into something that works pretty well was a great satisfaction. I want to thank Tony Belpaeme for presenting this interesting subject and guiding me to find a problem and create a solution that I can proudly present here in this thesis.
I also want to thank Pieter Wolfert for helping me with technical issues, giving me tips and interesting papers and for making the time to give me feedback on my thesis. I also want to thank Mathieu De Coster for providing me with useful scripts to build the Docker containers, Brecht Vermeulen to spend a whole day helping me out with the servers when they suddenly were behaving weirdly and Jillisa Schittecatte for giving me constructive feedback for my written English.
This thesis took place during the corona outbreak and it was not easy to set up evalua-tions that should normally involve a lot of users. Special thanks to everyone of my family, neighbours and close friends who were so kind as to help me out with this.
The circumstances gave me more time to concentrate on the thesis, but I am very thankful to my friends and the full ‘graanpat´e’ chat group to help with my motivation. I also want to thank Seppe Bilcke, my mother and sister and all of my horse riding friends for helping me to relax. Without them, this thesis would not have progressed well.
Permission for usage
EN: The author gives permission to make this master dissertation available for consul-tation and to copy parts of this master disserconsul-tation for personal use. In the case of any other use, the copyright terms have to be respected, in particular with regard to the obligation to state expressly the source when quoting results from this master dissertation.
NL: De auteur geeft de toelating deze masterproef voor consultatie beschikbaar te stellen en delen van de masterproef te kopi¨eren voor persoonlijk gebruik. Elk ander gebruik valt onder de bepalingen van het auteursrecht, in het bijzonder met betrekking tot de verplichting de bron uitdrukkelijk te vermelden bij het aanhalen van resultaten uit deze masterproef.
Contents
Glossary 1
1 Introduction 3
2 A background on conversational agents 5
2.1 History and definition . . . 5
2.2 Types of chatbots . . . 6
2.2.1 Pattern-based chatbots . . . 6
2.2.2 Model-based chatbots . . . 8
2.2.3 Combining rules and models . . . 9
2.2.4 Natural language processing . . . 10
2.2.5 Task-completion and information-retrieval conversational systems 11 2.2.6 Intelligent personal assistants . . . 11
2.2.7 Social chatbots . . . 12
3 Towards social robots 13 3.1 History and definition . . . 13
3.2 Speech interaction . . . 16
3.3 How does embodiment change conversations? . . . 17
3.4 Multimodal interaction . . . 18
4 Gesticulation 20 4.1 Why do we use gestures? . . . 20
4.2 How do we use gestures to accompany the content of our speech? . . . . 21
5 Deictic gestures 23 5.1 Definition . . . 23
5.2 The accuracy of deictic gestures . . . 23
5.3 How do deictic gestures improve conversations? . . . 25
6 Related work 27 6.1 Goal of this thesis . . . 27
6.2 Related work on deictic interaction . . . 28
6.4 Summary of the related systems . . . 32
7 Implementation of deictic interaction 33 7.1 Camera setup . . . 33
7.2 Poster/input format . . . 34
7.3 Poster preprocessing . . . 37
7.3.1 Localising the corners of the poster . . . 37
7.3.2 Localising the poster objects . . . 38
7.4 Real-time human pose tracking . . . 40
7.4.1 Openpose . . . 41
7.4.2 Server setup . . . 42
7.4.3 Runtime analysis . . . 43
7.5 Gesture recognition . . . 43
7.5.1 The dataset . . . 43
7.5.2 Technique 1: Supervised learning . . . 44
7.5.3 Technique 2: Distance estimation . . . 45
7.5.4 Technique 3: Brute detection . . . 45
7.5.5 Comparison of the techniques . . . 46
7.6 Pointing direction estimation . . . 46
7.6.1 Pointing direction . . . 46
7.6.2 Accuracy tests . . . 47
7.6.3 Results . . . 49
7.7 Parallax optimisation . . . 49
7.8 Intermediate summary . . . 51
8 Implementation of verbal interaction 54 8.1 The chatbot requirements . . . 54
8.2 How do people ask questions about poster content? . . . 54
8.2.1 Results . . . 55
8.3 AIML preprocessing . . . 57
8.3.1 AIML structure . . . 57
8.3.2 Parsing poster information to AIML . . . 59
8.4 Speech to text . . . 61
8.4.1 Hotword detection . . . 61
8.4.2 Processing audio to text . . . 61
8.5 Text to speech . . . 61
8.6 Results . . . 61
8.7 Intermediate summary . . . 63
9 Evaluation 64 9.1 Purpose and hypotheses . . . 64
9.2 Setup . . . 64
9.3 Experiment . . . 65
9.3.1 Tasks and questions . . . 65
9.4 Results . . . 66
9.4.1 First impressions . . . 66
9.4.2 Technical results . . . 67
9.4.3 Other observations . . . 67
10 Conclusions and future work 69 10.1 The outlook . . . 69
Appendices 79
Glossary
AI Artificial Intelligence. 82
AIML Artificial Intelligence Markup Language. xx, 6, 7, 10, 54, 57–61, 81, 82
ANOVA ANalysis Of VAriance. 17
AP Average Precision. 40
API Application Program Interface. 12
CFG Context Free Grammar. 82
DeepQA Deep Question-Answering system. 11
DNN Deep Neural Net. 16
GMM Gaussian Mixture Models. 16
GPR Gaussian Process Regression. 29, 46
GPU Graphics Processing Unit. 42
HMM Hidden Markov Models. 16
HRI Human Robot Interaction. 13, 30, 31
ID Identifier. 51
IPA Intelligent Personal Assistant. 11, 12
MAP Mean Average Precision. 40
NLG Natural Language Generation. 10
NLI Natural Language Identification. 82
SRAI Symbolic Reduction in Artificial Intelligence. 57, 58
STT Speech To Text. 61–63, 70
SVM Support Vector Machine. 44
TTS Text To Speech. 61, 70
1
Introduction
As robots, chatbots and conversational agents are becoming more and more prevalent in our society, the need for reliable and easy communication grows. Unlike humans, these agents do not have six senses that cooperate in a blazingly fast neural net to give them a clear view of their surroundings. For a conversational agent, it is necessary to gather and process this information with additional hardware. This is not a simple task. Hu-mans will often draw links to their world knowledge that even a very smart robot can not derive from their current surroundings. For example (Ray Curzweil, 2018 [2]), on a third-grade language understanding test, a computer did not understand that if a boy had muddy shoes he probably got them muddy by walking in the mud outside and if he got mud on the kitchen floor it would make his mother mad. That may all seem ob-vious to us humans because we may have experienced that, but it is not obob-vious to the AI.
Researchers are still working on human-like chatbots and robots. Part by part they try to extend their world knowledge and information processing capabilities. For now, the human brain stays ahead with its complex construction and it is still an open question if robots would be able to become completely human-like or even surpass them.
It is pretty common for conversational agents to take place in closed domain communica-tion tasks like taking an order or processing a quescommunica-tion or complaint. They also appear in home environments as advanced toys, intelligent assistants or companions, but slowly they are also taking their place in educational tasks. These educational tasks are often fixed within a specific subject and preprogrammed at the factory. In this thesis, we will dive deeper into conversational agents and search for possibilities to present any poster presentation. To do this task, the agent should be aware of the user, the poster and the content of the poster. Within poster presentations, it is common for the user to ask questions to the speaker. In section 5.3, it will be explained that asking questions by using pointing gestures gives us a more positive experience.
This is why we will build a prove-of-concept for using deictic gestures inside a presen-tation robot or other agent and evaluate its usability and improvements to verbal-only communication. First, we will focus on a more elaborated literature study about chatbots, social robots and gestures. In chapter 2, there will be an elaborated history on chatbots. Chapter 3 will be about the embodiment of a chatbot in the form of a social robot. In chapter 4, there will be a short explanation about the importance of gestures to humans. In chapter 5, we will focus on deictic gestures and in chapter 6 on the related work. From
then on an elaborated explanation of the different parts of the proof-of-concept will be explained, together with the evaluation of those parts. In chapter 9 we will discuss the performance of the complete system and possible strengths and weaknesses while using the tool in practice.
2
A background on conversational agents
2.1
History and definition
A chatbot or conversational agent is an automated software program that simulates hu-man textual or verbal conversation [3]. Chatbots are very easy to engage with, can attend to customers at all times and are not limited by time or physical locations. This makes chatbots very attractive to organisations with less manpower or financial resources. An-other approach is to use chatbots as a filter and let them answer the simple repetitive questions and pass harder questions on to real humans.
The first interest in humanoid computer systems can be traced back to Alan Turing, who proposed the Turing Test in 1950 in the paper: ”Computing Machinery and Intel-ligence” [4]. This test, also called the imitation game, is a benchmark to evaluate the intelligence of a computer system. The original test consists of two players and a chatbot. One of the players performs the role of an interrogator and can ask questions to two other players. One of those other players is a computer. The goal of the interrogator is to find out which one is the computer and which one is human. When the interrogator is wrong, the chatbot passes the test. This test started raising the curiosity of researchers about whether or not a human conversation with a computer would be possible. One of those researchers was Joseph Weizenbaum, who created the first considered chatbot ELIZA [5]. There were some earlier chatbots, mostly in games and focused domain expert systems, but their implementations were not shared and there were no reviews published on this matter [6]. ELIZA was also the first to be considered passing the Turing Test in 1991. Although it did convince some people that it was human, the program was very limited.
ELIZA searches the user’s input for keywords. If a keyword is found, a rule that trans-forms the user’s input is applied, otherwise, a generic response is returned. This technique is based on the approach of a Rogerian psychotherapist [7]. This is a client-centred ap-proach to psychotherapy, often used in situations where the communication gets stuck due to emotions or conflicting arguments. Instead of forming new arguments, we try to understand the reasoning of the other person by asking questions. This makes the person feel heard and starts communication again. ELIZA uses this same principle by transform-ing questions into new questions, but she actually does not understand the conversation at all and merely deceives the user into thinking that she is following their conversation. A lot of criticism followed the Turing test [8], which states that chatbots do not have to
be intelligent to pass the Turing test. Despite this criticism, the test stayed a popular challenge for chatbot researchers. In 1990, Hugh Loebner even introduced the Loebner Prize [9] for chatbots that convinced the jury to be the most human-like. ELIZA was the first to win the prize in 1991 and Weizenbaum also won with improved variations of ELIZA in 1992, 1993 and 1995 [10]. In table A.1 and A.2, all previous Loebner Prize winners are summarised.
Like ELIZA, the first chatbots were pattern-matching based. In 1995 the Artificial In-telligence Markup Language (AIML) [11], a new Extensible Markup Language (XML) knowledge base for pattern-based chatbots was introduced together with the ALICE chatbot. This base can be modified for every domain-specific knowledge and is still used today with a good performance. This technique became very popular and was optimised with different strategies. It was only until the early 2000s that completely new tech-niques started popping up. Natural language processing techtech-niques could recognise the different parts of the question, which made it easier to learn the meaning and flow of conversations. Machine learning models solved the need of implementing every possible question and answer. IBM created one of the first deep learning chatbots which were able to answer open-domain questions and were trained on their distributed supercomputer Watson. It participated in the “Jeopardy! Competition” and won in 2011 [12]. However, the training of these open domain models is still very compute-and-time intensive and has moderate results. This is why larger companies prefer focusing on specific domains or sets of skills when bringing out commercial personal chatbots. Personal assistants like Siri or Alexa are very skilled in answering a large variety of questions and executing specific tasks. Although they are still limited to their set of knowledge, access to external data sources and implemented human traits such as humour make their communication more and more advanced [13].
Today, chatbots can be found not only online as part of help desks, (educational) games or marketing strategies, but they also start to pop up in public places, inside people’s homes and on their mobile devices as helpful personal assistants.
2.2
Types of chatbots
To be able to perform near human-like conversations, the chatbot has to be able to understand the question or sentence and find an appropriate response. In this section, the general techniques [14,15] to do this will be discussed. In reality, chatbots can be one or a combination of these techniques with specific optimisations for their tasks. Their advantages and disadvantages will be discussed, but the best one depends on the use case.
2.2.1
Pattern-based chatbots
The simplest technique, which comes with a high degree of adaptability is pattern-based chatbots. A set of rules, based on the structure of the sentence, defines the answer that the chatbot has to return. This technique is quite common in question answering sys-tems [10]. Eliza was one of the first known chatbots and used this technique to transform its input question to an output question as explained in section 2.1. Later Loebner prize

![Figure 2.4: DeepQA architecture of Watson [12]](https://thumb-eu.123doks.com/thumbv2/5doknet/3287609.21875/33.892.130.764.529.878/figure-deepqa-architecture-of-watson.webp)

![Figure 5.5: Results [1]: Number of questions asked in each condition](https://thumb-eu.123doks.com/thumbv2/5doknet/3287609.21875/48.892.248.643.534.794/figure-results-number-questions-asked-condition.webp)
![Figure 6.1: Setup experiment Shukla et al. [75]](https://thumb-eu.123doks.com/thumbv2/5doknet/3287609.21875/51.892.233.661.106.424/figure-setup-experiment-shukla-et-al.webp)
![Figure 6.2: Droeshel et al. [77]: Average distance and angular test set error To calculate pointing directions, 3D coordinates are necessary](https://thumb-eu.123doks.com/thumbv2/5doknet/3287609.21875/52.892.242.646.118.215/droeshel-average-distance-calculate-pointing-directions-coordinates-necessary.webp)
