EEN CASE STUDY IN DATA MINING:
WEBANALYTICS
Aantal woorden: 17 265
Stamnummer : 01601355
Promotor: Prof. Dr. Els Clarysse
Masterproef voorgedragen tot het bekomen van de graad van: Master in de handelswetenschappen: management en informatica
II
PREAMBULE
Deze masterproef werd uitgevoerd tijdens de periode van de COVID-19-pandemie. De impact op deze masterproef was echter relatief klein. Hieronder wordt de initiële opzet, de stappen die niet konden uitgevoerd worden en de manier waarop dit is aangepakt beschreven.
Initieel was het de bedoeling om het aanbevelingssysteem ook werkelijk te testen op de website van Bloovi. Het doel was om de focus te leggen op het bouwen van een systeem dat in productie genomen kon worden door Bloovi. Het aanbevelingssysteem zou getest worden via een A/B test, waarin de resultaten van het aanbevelingssysteem vergeleken zou worden met het bestaande systeem dat artikels aanbeveelt op basis van categorieën.
De COVID-19-pandemie zorgde er echter voor dat Bloovi heel andere prioriteiten had dan het implementeren van een aanbevelingssysteem. In samenspraak met hen en de promotor is dan ook besloten om deze masterproef uit te voeren zonder het aanbevelingssysteem te testen op de website van Bloovi. Er werd gekozen voor een systeem dat gebaseerd is op de historische data die beschikbaar is via Google Analytics en Storychief. Dit maakte het mogelijk om deze masterproef uit te voeren, zonder dat de mensen van Bloovi nog enige verdere inspanning moesten doen. Er werd daarnaast beslist om te werken met evaluatiemethoden die volledig losstaand van een implementatie op Bloovi konden gebeuren.
Hoewel dit een vrij grote sprong was in mijn opzet van de masterproef, bleek dat deze keuze slechts een minimaal effect had op de reeds gedane implementaties. Het werk dat reeds gedaan was, bleef ook nuttig voor de verdere uitvoering van deze masterproef. Deze verschuiving zorgde er dus voornamelijk voor dat enkele nieuwe denkpistes onderzocht moesten worden, terwijl de hoeveelheid werk relatief gelijk bleef.
Deze preambule werd in overleg tussen de student en de promotor opgesteld en door beiden goedgekeurd.
III
WOORD VOORAF
Deze masterproef is het sluitstuk van de opleiding Handelswetenschappen aan de Universiteit Gent. Ik wil dan ook graag meerdere mensen bedanken die dit mede mogelijk gemaakt hebben.
Om te beginnen wil ik mijn promotor, Els Clarysse, bedanken om de tijd vrij te maken. Zij zorgde ervoor dat ik terug in de juiste richting keek wanneer ik even niet meer wist hoe ik verder moest.
Daarnaast wil ik natuurlijk ook Bloovi en meer bepaald Maarten Van de Vondel bedanken. Hij zorgde ervoor dat ik zonder problemen toegang kreeg tot alle data, zodat ik het experiment in deze masterproef op een efficiënte manier kon uitvoeren.
Dit onderzoek werd uitgevoerd binnen de faculteit Economie en Bedrijfskunde. Graag wil ik ook hen bedanken voor deze opportuniteit.
Als laatste wil ik ook iedereen bedanken die deze thesis heeft nagelezen en vooral mijn vriendin en vader. Zonder hun oog voor detail waren er vermoedelijk heel wat foutjes door de mazen van het net geglipt.
IV
LIJST VAN TABELLEN
Tabel 1: Vergelijking geheugen- en modelgebaseerde systemen
Tabel 2: Vergelijkende tabel impliciete en expliciete feedback
Tabel 3: Voorbeeld dataframe gebruiker interacties
Tabel 4: Voorbeeld dataframe artikels
Tabel 5: Resultaten populariteitsmodel
Tabel 6: Resultaten content-based model
V
LIJST VAN FIGUREN
Figuur 1: Evolutie van het aantal internetgebruikers wereldwijd
VI
LIJST VAN AFKORTINGEN
API - Application Programming Interface CMS – Content management systeem CSV - Comma Separated Values df – Dataframe
ID – Identification
IDF - Inverse Document Frequency JSON - JavaScript Object Notation NLP – Natural Language Processing SaaS - Software as a Service SQL - Structured Query Language TF - Term Frequency
TF-IDF - Term Frequency Inverse Document Frequency U-I matrix – User-item matrix
URL - Universal Resource Locator wpm - Woorden per minuut
VII
INHOUDSTAFEL
Preambule ... II Woord vooraf ... III Lijst van tabellen ... IV Lijst van figuren ... V Lijst van afkortingen ... VI
Hoofdstuk 1 Inleiding ... 1 1.1 Probleemstelling ... 1 1.2 Doelstelling ... 3 1.3 Overzicht ... 3 Hoofdstuk 2 Literatuurstudie ... 5 2.1 Aanbevelingssystemen ... 5 2.1.1 Collaborative filtering ... 6 2.1.2 Content-based filtering ... 13 2.1.3 Hybride ... 16 2.2 Tekstanalyse ... 16 2.3 Gebruikersfeedback ... 20 Hoofdstuk 3 Ontwerp ... 22 3.1 Casestudy ... 22 3.2 Databronnen ... 23
3.2.1 Google analytics data ... 23
3.2.2 Artikels ... 23
3.3 Het aanbevelingssysteem ... 24
3.3.1 Scoremechanisme ... 24
VIII 3.4 Evaluatiemethode ... 25 3.4.1 Train- en testdata ... 26 3.4.2 Evaluatiemodel ... 26 3.5 Gebruikte technologieën ... 26 Hoofdstuk 4 Implementatie ... 28 4.1 Data verzameling ... 28 4.1.1 Google analytics ... 28 4.1.2 Storychief API ... 30 4.2 Data verwerking ... 31
4.2.1 Dataframe gebruiker interacties ... 31
4.2.2 Dataframe artikels ... 33
4.2.3 Dataframes samenvoegen ... 34
4.2.4 Scores berekenen ... 35
4.2.5 Aggregatie van de gebruiker interacties ... 37
4.3 Algoritmes ... 37
4.3.1 Populariteitsmodel ... 38
4.3.2 Content gebaseerd model ... 38
4.3.3 Collaborative filtering model ... 40
4.4 Evaluatie ... 40
4.4.1 Populariteitsmodel ... 40
4.4.2 Content gebaseerd model ... 41
4.4.3 Collaborative filtering ... 41
4.4.4 Opmerkingen ... 42
Hoofdstuk 5 Bespreking ... 43
IX
5.1.1 Hybride aanbevelingssysteem ... 43
5.1.2 Meer geavanceerde algoritmes... 44
5.1.3 Data ... 44
5.1.4 Exacte leessnelheid ... 44
5.1.5 Minimaal aantal artikels ... 45
5.1.6 Extra impliciete feedback in de score ... 45
5.1.7 Webscraping ... 46
5.2 Implementatiemogelijkheden ... 46
5.2.1 SaaS ... 46
5.2.2 Losstaand ... 47
5.2.3 Ondersteunend... 47
5.2.4 Inschatting van relevantie ... 47
5.2.5 Gesponsorde content ... 48
5.2.6 Kranten ... 48
5.3 Beperkingen... 49
5.3.1 Score ... 49
5.3.2 Schaalbaarheid ... 50
5.3.3 Testen in werkelijke omgeving ... 51
Hoofdstuk 6 Conclusie ... 52
Bibliografie ... 54
Bijlagen ... 57
Bijlage 1: JSON object Google Analytics ... 57
HOOFDSTUK 1
INLEIDING
1.1 PROBLEEMSTELLING
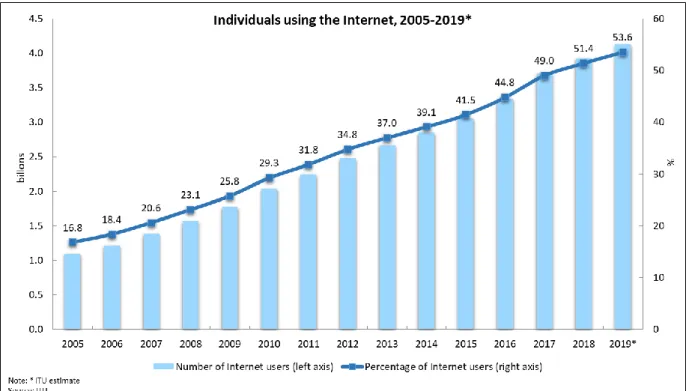
Het aantal internetgebruikers stijgt jaarlijks. Uit de cijfers van het ITU blijkt dat ondertussen meer dan de helft van de wereldbevolking gebruik maakt van het internet (International Telecommunication Union, sd). Zoals te zien is in figuur 1.1 schatte het ITU in dat het aantal internetgebruikers in 2019 nog verder ging stijgen van 51,4% naar 53,6% van de wereldbevolking, wat neerkomt op 4,1 miljard personen.
Figuur 1: Evolutie van het aantal internetgebruikers wereldwijd
De stijging van het aantal internetgebruikers leidt logischerwijs tot een toename in de hoeveelheid webpagina’s. Search Engine Land (2016) stelt dat Google reeds meer dan 130 biljoen webpagina’s geïndexeerd heeft. Kortom, de hoeveelheid beschikbare informatie op het internet is enorm en stijgt nog dagelijks. Veel websites bestaan uit honderden of zelfs duizenden artikels. Denk hierbij bijvoorbeeld aan nieuwswebsites of blogs.
De stijging van beschikbare informatie zorgt ervoor dat het steeds moeilijker wordt voor internetgebruikers om te weten welke artikels relevant zijn. Dit probleem leidde uiteindelijk tot het ontstaan van aanbevelingssystemen (Park, Kim, Choi, & Kim, 2012).
Aanbevelingssystemen gaan op zoek naar de voorkeuren van de gebruiker om zo items aan te bevelen die dicht bij deze voorkeuren liggen. Dit vermindert de informatie-overload waar de gebruiker mee te maken krijgt. De beschikbare informatie wordt namelijk al een eerste keer gefilterd door het aanbevelingssysteem.
Voordat een aanbevelingssysteem echter goede aanbevelingen kan doen, moet het systeem de voorkeuren van de gebruiker eerst leren kennen. Veelal gebeurt dit door de gebruiker te vragen om een beoordeling te geven aan meerdere artikels. Het aanbevelingssysteem kan aan de hand van deze beoordelingen dan gaan voorspellen welke andere artikels de gebruiker interessant zou vinden (Adomavicius & Tuzhilin, 2005).
Een veel voorkomend probleem is echter het cold start probleem. Dit komt voor wanneer een gebruiker onvoldoende data heeft achtergelaten om goede aanbevelingen te kunnen doen. Veelal is dit wanneer een gebruiker nog nieuw is of gewoon nog onvoldoende beoordelingen heeft gegeven (Adomavicius & Tuzhilin, 2005).
Voor deze gebruikers wordt veelal teruggevallen op populariteitsmodellen om aanbevelingen te doen. Concreet betekent dit dat de meest populaire artikels woorden aanbevolen in plaats van gepersonaliseerde artikels. De aanbevolen artikels zijn dus niet gebaseerd op de data van deze specifieke gebruiker. De kans is namelijk groot dat de gebruiker de meest populaire artikels ook interessant vindt.
Doordat heel wat gebruikers eerder passief gebruik maken van websites en dus zelf weinig informatie achterlaten, komt het cold start probleem frequent voor. Dit maakt het moeilijk voor het aanbevelingssysteem om gepersonaliseerde aanbevelingen te doen voor iedere gebruiker.
Een tweede moeilijkheid ligt bij de implementatie van een aanbevelingssysteem op een reeds bestaande website. Aangezien het aanbevelingssysteem volledig van nul moet beginnen, zonder dat er enige beoordelingen beschikbaar zijn, kan het initieel lastig zijn voor de website-gebruikers om de relevantie van het systeem in te zien. Dit maakt het moeilijk om voldoende data te verzamelen, waardoor het lastig is voor het aanbevelingssysteem om gepersonaliseerde aanbevelingen te doen.
1.2 DOELSTELLING
In de voorgaande paragraaf werd aangehaald dat het niet evident is om beoordelingen te verzamelen. Vaak geven gebruikers onvoldoende beoordelingen, waardoor het aanbevelingssysteem geen gepersonaliseerde aanbevelingen kan doen. Zoals hierboven beschreven, valt het aanbevelingssysteem dan meestal terug op het aanbevelen van de meest populaire artikels of krijgt de gebruiker gewoon geen aanbevelingen te zien. Hoewel het gebruik van een populariteitsmodel vaak tot relatief goede resultaten leidt, zorgt dit er toch voor dat de aanbevelingen een stuk minder gepersonaliseerd zijn. Gebruikers zullen dan dezelfde populaire artikels aanbevolen krijgen, waardoor deze meer gelezen worden en dus ook meer beoordelingen krijgen. Concreet betekent dit dat een kleine groep van populaire artikels vaak gelezen wordt, terwijl de grote massa aan artikels onder de radar van een grote groep gebruikers blijft (Moreira, 2019).
Het doel van deze masterproef is om bovenstaand probleem aan te pakken. Dit door een aanbevelingssysteem te bouwen dat volledig gebaseerd is op impliciete feedback. Er wordt doorheen het volledige systeem dus geen tussenkomst van de eindgebruiker verwacht. Aan de hand van de data die iedere gebruiker achterlaat op de website, zal het aanbevelingssysteem voorspellen welke artikels al dan niet interessant zijn voor de gebruiker.
Het aanbevelingssysteem maakt hiervoor gebruik van een scoring mechanisme dat de interesse van een gebruiker benadert. Aan de hand van deze score en de beschikbare informatie over zowel de artikels als de gebruiker, maakt het aanbevelingssysteem aanbevelingen die aansluiten bij de interesses van de eindgebruiker.
Concreet wordt er in deze masterproef gezocht naar een waardig alternatief voor het populariteitsmodel wanneer de gebruiker nog onvoldoende beoordelingen gegeven heeft. Hoewel dit systeem vermoedelijk minder zal presteren dan een systeem gebaseerd op expliciete feedback van gebruikers, hangen er ook heel wat voordelen vast aan een systeem dat geen directe input van gebruikers verwacht. Deze voordelen worden verder in deze masterproef nader toegelicht.
1.3 OVERZICHT
Om deze masterproef verder te kaderen, staat in hoofdstuk 2 de bestaande literatuur beschreven. Hierin worden de verschillende soorten aanbevelingssystemen aangehaald, inclusief de voor- en nadelen van deze methoden. Daarnaast worden ook verschillende manieren om met tekst om te gaan beschreven. Als laatste haalt dit hoofdstuk de mogelijkheden voor gebruikersfeedback aan.
Hoofdstuk 3 beschrijft het ontwerp van de casestudy. Hier worden o.a. de opzet beschreven, de verschillende databronnen, de gebruikte aanbevelings- en evaluatiemethoden en de gebruikte technologieën die dit mogelijk maakten.
Hoofdstuk 4 gaat dieper in op deze aspecten van de casestudy en beschrijft hierbij hoe dit exact geïmplementeerd werd. Daarnaast worden hier ook de resultaten van de verschillende aanbevelingsmethoden beschreven.
Als laatste worden in hoofdstuk 5 de verschillende implementatiemogelijkheden en uitbreidingen aangehaald. Ook worden hier nog eens de mogelijke verbeterpunten besproken.
HOOFDSTUK 2
LITERATUURSTUDIE
2.1
AANBEVELINGSSYSTEMEN
Sinds de eerste paper midden de jaren 90 over collaborative filtering, hebben aanbevelingssystemen zich ontwikkeld tot een belangrijk onderzoeksveld (Park, Kim, Choi, & Kim, 2012). Zoals reeds aangegeven in hoofdstuk 1, leidde de enorme hoeveelheid aan beschikbare informatie tot het ontstaan van aanbevelingssystemen.
Aanbevelingssystemen komen voort uit een combinatie van verschillende onderzoeksvelden. Zo hadden o.a. cognitieve wetenschappen, information retrieval en voorspellingstheorie een extensieve invloed op de creatie van dit onderzoeksveld (Adomavicius & Tuzhilin, 2005).
Het doel van een aanbevelingssysteem is om de meest relevantie informatie bij de eindgebruiker te krijgen (Adomavicius & Tuzhilin, 2005). Door de vele toepassingsmogelijkheden in o.a. e-commerce, zoekmachines en nieuwswebsites, hebben aanbevelingssystemen zich dan ook steeds verder ontwikkeld tot een eigen onderzoeksgebied.
Aanbevelingssystemen kunnen gedefinieerd worden als informatie filteringsystemen die omgaan met een grote hoeveelheid aan beschikbare informatie door vitale informatie te filteren uit een enorme hoeveelheid aan dynamisch gegenereerde informatie a.d.h.v. de voorkeuren van de gebruiker (Isinkaye, Folajimi, & Ojokoh, 2015). Deze definitie kan als volgt geconcretiseerd worden.
Waar C een set van gebruikers voorstelt, S een set van mogelijke items en u de nutsfunctie die het nut van een item s weergeeft. Dan willen we voor iedere gebruiker c een item s aanbevelen waarbij het nut het hoogst is. Formeel kan dit weergegeven worden in volgende formule (Adomavicius & Tuzhilin, 2005):
∀𝑐 𝜖 𝐶, 𝑠𝑐′ = arg max 𝑢(𝑐, 𝑠)
Hoewel aanbevelingssystemen eenzelfde doel hebben, nl. items aanbevelen die zo dicht mogelijk bij de voorkeuren van de gebruiker liggen, zijn er verschillende aanpakken mogelijk om dit doel te bereiken.
Aanbevelingssystemen worden in de literatuur dan ook veelal onderverdeeld in drie categorieën: 1. Content-based filtering: hierbij krijgt de gebruiker items aanbevolen die gelijkaardig zijn aan
items waar de gebruiker in het verleden de voorkeur aan gaf (Adomavicius & Tuzhilin, 2005). De items worden relatief tegenover elkaar geplaatst, waardoor een analyse gemaakt kan worden die aangeeft hoe gelijkaardig items zijn. Dit kan gemeten worden met behulp van afstandsfuncties. Op basis hiervan beveelt het aanbevelingssysteem dan items aan die zo dicht mogelijk bij de voorkeuren van de gebruiker liggen;
2. Collaborative filtering: hierbij krijgt de gebruiker aanbevelingen gebaseerd op andere gebruikers die in het verleden dezelfde voorkeuren aangaven als deze gebruiker (Adomavicius & Tuzhilin, 2005). Het aanbevelingssysteem gaat hierbij opzoek naar gebruikers die gelijkaardig gedrag vertonen. Op basis van het gedrag van deze gelijkaardige gebruikers, beveelt het systeem dan items aan;
3. Hybride systemen: hierbij worden content-based filtering en collaborative filtering gecombineerd (Isinkaye, Folajimi, & Ojokoh, 2015). Op deze manier worden de zwaktes van beide categorieën uitgebalanceerd, om een nog performanter systeem te kunnen opbouwen. Hoewel er verschillende soorten aanbevelingssystemen bestaan, is de onderliggende data-architectuur veelal dezelfde. Zo is er een database tabel met items die aanbevolen moeten worden en een database tabel met gebruikersinformatie. Het aanbevelingsalgoritme maakt dan gebruik van deze twee tabellen om aanbevelingen te doen. Nadien kan er feedback gegeven worden door de gebruiker, zodat het systeem zich kan aanpassen en verbeteren.
In 2.1.1 wordt verder ingegaan op de collaborative filtering methode, waarna in 2.1.2 content gebaseerde aanbevelingssystemen besproken worden. Paragraaf 2.1.3 gaat dan verder over hybride aanbevelingssystemen. Hoewel we met de beschrijving deze drie soorten aanbevelingssystemen de voornaamste lading dekken, wordt in 2.1.4 en 2.1.5 tekstanalyse en gebruikersfeedback achtereenvolgens besproken. Waar tekstanalyse een belangrijk aspect is van de dataverwerking, zorgt een correcte manier van gebruikersfeedback dat de aanbevolen items wel degelijk aansluiten bij de voorkeuren van de gebruiker.
2.1.1 COLLABORATIVE FILTERING
Collaborative filtering is de meest bestudeerde en gebruikte methode voor aanbevelingssystemen (Bobadilla, Ortega, Hernando, & Bernal, 2012). De term collaborative filtering werd voor het eerst vermeld in Goldberg et al., waar het gebruikt werd om een e-mail systeem te beschrijven. In dit systeem kon iedere gebruiker een annotatie toevoegen aan een e-mail bericht.
Deze annotaties werden dan gedeeld met een groep van gebruikers. Aan de hand van deze annotaties konden de e-mail berichten dan gefilterd worden. Het was echter wel nog nodig dat de gebruiker, op een eerder gecompliceerde manier, vragen stelde aan het systeem. Dit maakte het mogelijk om relevante informatie te vinden (Deshpande & Karypis, 2004).
Het eerste systeem dat er in slaagde om volledig geautomatiseerde aanbevelingen te doen, was het Grouplens systeem. Deze aanbevelingen steunden op het neighborhood principe, waarbij het systeem zocht naar de meest gelijkaardige gebruikers. De artikels van deze groep gelijkaardige gebruikers werden dan aanbevolen (Deshpande & Karypis, 2004).
Het basisidee waarop collaborative filtering steunt, is dat wanneer twee gebruikers gelijkaardige beoordelingen geven aan items, deze gebruikers als gelijkaardig aanschouwd kunnen worden. Hierdoor geven ze namelijk aan dat hun voorkeuren dicht bij elkaar liggen. Waar gebruiker A en B gelijkaardige gebruikers zijn, kunnen de beoordelingen die gebruiker A aan items geeft die nog niet werden gezien door gebruiker B, gezien worden als een benadering van hoe interessant deze items voor gebruiker B zijn.
Concreet wordt bij collaborative filtering het nut van een item voor een bepaalde gebruiker voorspeld aan de hand van items die reeds een bepaalde beoordeling kregen van andere gebruikers (Adomavicius & Tuzhilin, 2005). Hierbij wordt gekeken naar de beoordelingen van andere gebruikers die het meest gemeen hebben met de gebruiker in kwestie. De kwaliteit van het aanbevelingssysteem hangt hierbij dan ook sterk af van de mate waarin het in staat is om te bepalen welke gebruikers vergelijkbaar zijn (Bobadilla, Ortega, Hernando, & Bernal, 2012). Hoe vergelijkbaar gebruikers zijn, kan dan gemeten worden a.d.h.v. een afstandsberekening tussen de vectoren van user-ratings. Dit kan bijvoorbeeld door gebruik te maken van de cosinus afstandsberekening methode (Adomavicius & Tuzhilin, 2005). Collaborative filtering maakt gebruik van een U-I matrix (user-item matrix). Deze matrix geeft de voorkeuren van de gebruiker weer. Deze voorkeuren kunnen direct, door bijvoorbeeld beoordelingen, of indirect, door bijvoorbeeld data die weergeeft of een gebruiker geklikt heeft, voorgesteld worden (Shi, Larson, & Hanjalic, 2014). Aan de hand van deze matrix worden dan voorspellingen gedaan. Een groot voordeel van collaborative filtering is dat de noodzaak om voorkeuren van gebruikers te formaliseren in features wegvalt. De informatie die hiervoor nodig is, zit allemaal in de (expliciete of impliciete) beoordelingen van gebruikers (Yu, Schwaighofer, Tresp, Xu, & Kriegel, 2004). De beoordelingen die een gebruiker geeft aan een item, weerspiegelen namelijk rechtstreeks de voorkeuren van deze gebruiker.
Aanbevelingssystemen die gebruik maken van collaborative filtering kunnen ingedeeld worden in twee algemene klassen: geheugen gebaseerd en modelgebaseerd (Adomavicius & Tuzhilin, 2005). Daarnaast is er ook hier een hybride aanpak, die geheugen gebaseerde en modelgebaseerde collaborative filtering combineert (Bobadilla, Serradilla, & Hernando, 2009).
Bij een vergelijking van de modelgebaseerde en geheugen gebaseerde aanpak blijkt uit de literatuur dat de modelgebaseerde aanpak accurater is dan geheugen gebaseerde. Deze stelling is echter enkel gebaseerd op empirische data. Er is dus nog geen theoretisch bewijs dat dit ook aangeeft (Adomavicius & Tuzhilin, 2005).
Hierop volgend zijn zowel de geheugen gebaseerde als model gebaseerde methode beschreven. Daarnaast is er ook een verduidelijkende tabel voorzien waar beide methodes duidelijk naast elkaar worden geplaatst. Nadien worden de sterktes en zwaktes van collaborative filtering ook nog kort aangehaald.
2.1.1.1 GEHEUGEN GEBASEERD
Geheugen gebaseerde collaborative filtering is een methode voor een aanbevelingssysteem dat typisch gebruikt wordt in commerciële applicaties (Bobadilla, Serradilla, & Hernando, 2009). Deze methode is gebaseerd op de observatie dat mensen vaak vertrouwen op aanbevelingen van vrienden met gelijkaardige interesses. Dit is dan ook exact wat de geheugen gebaseerde methode probeert te simuleren (Yu, Schwaighofer, Tresp, Xu, & Kriegel, 2004). Het aanbevelingssysteem maakt gebruik van de volledige collectie aan beoordelingen van de gebruiker (Adomavicius & Tuzhilin, 2005). Aan de hand van deze data kan het aanbevelingssysteem de afstand berekenen tussen twee gebruikers. Gebruikers waarbij de datapunten het dichtst bij elkaar liggen, worden gezien als gelijkaardig. Hoe groter de afstand tussen twee gebruikers, hoe minder gelijkaardig ze zijn volgens het aanbevelingssysteem. Op deze manier kan het systeem dan gaan voorspellen welke items de gebruiker interessant zal vinden (Bobadilla, Serradilla, & Hernando, 2009). Items die een gelijkaardige gebruiker interessant vindt, zal voor de gebruiker in kwestie vermoedelijk ook interessant zijn.
Concreet gaat een geheugen gebaseerd aanbevelingssysteem werken met een tabel van gebruikers die beoordelingen hebben van verschillende items. De voorspelling voor een item dat nog geen beoordeling heeft voor deze gebruiker wordt berekend door het aggregaat te nemen van de beoordelingen voor de meest gelijkaardige gebruikers voor dat item (Bobadilla, Serradilla, & Hernando, 2009). Meestal gebeurt de aggregatie door het gemiddelde of de gewogen som te nemen. Gelijkaardige items worden dan weer berekend aan de hand van een afstandsfunctie. Veelgebruikte afstandsfuncties zijn hier de Pearson correlatie- en cosinus-afstandsfuncties (Bobadilla, Serradilla, & Hernando, 2009).
Waar de hierboven beschreven methode gelijkaardige gebruikers probeert te vinden om voorspellingen te doen, is het binnen de geheugen gebaseerde methode ook mogelijk om op zoek te gaan naar gelijkaardige items. Bij deze item-gebaseerde methode gaat het aanbevelingssysteem dan opzoek naar items die gelijkaardig zijn aan diegene dat de gebruiker reeds gezien/gekocht heeft (Chen, Chen, & Wang, 2015).
Hoewel de aanbevelingen veelal van vrij hoge kwaliteit zijn, blijken aanbevelingssystemen gebaseerde op de geheugen gebaseerde methode veelal onvoldoende schaalbaar. De complexiteit van de berekening groeit namelijk lineair met het aantal gebruikers en items. Hoe groter de U-I-matrix, hoe langer de duurtijd om een aanbeveling te doen (Deshpande & Karypis, 2004).
2.1.1.2 MODEL GEBASEERD
In tegenstelling tot de geheugen gebaseerde methode, maakt de model gebaseerde methode gebruik van de collectie aan beoordelingen om een model op te bouwen waarmee de set van gelijkaardige gebruikers kan bepaald worden (Bobadilla, Serradilla, & Hernando, 2009). Het model gaat hierbij op zoek naar relaties tussen de items. Zo kan het bijvoorbeeld zijn dat wanneer gebruikers interesse tonen in een bepaald item, dit veelal betekent dat die gebruiker ook interesse toont in een ander item. Een simpel voorbeeld kan zijn dat, wanneer een gebruiker interesse toont in een nieuwe computer, hij vermoedelijk ook interesse zal tonen in een toetsenbord.
In werkelijkheid blijkt de model gebaseerde methode echter meer gebruikt te worden in onderzoek, terwijl de hierboven beschreven geheugen gebaseerde methode vaker voor commerciële applicaties gebruikt wordt (Bobadilla, Serradilla, & Hernando, 2009).
Veel gebruikte methodes om dit descriptieve model van gebruikersvoorkeuren op te stellen, zijn neurale netwerken, Baysiaanse classifiers en fussysystems (Bobadilla, Serradilla, & Hernando, 2009). De model gebaseerde methode focust op het leren van de latente factoren die de voorkeuren van de gebruiker voorstelen over de verschillende dimensies van een item (Chen, Chen, & Wang, 2015). Wanneer het model erin slaagt om deze latente factoren te leren, is het zo in staat om beoordelingen van ongekende items te voorspellen of om deze items te rangschikken.
Het voornaamste voordeel van de model gebaseerde methode is de snelheid waarmee aanbevelingen gedaan kunnen worden. De reden hiervoor is dat de methode gebruik maakt van vooraf berekende modellen. Een voorspelling doen vraagt dus weinig extra rekenkracht. Een nadeel dat hier direct aan vast zit, is dat het bouwen van het model vrij veel tijd en rekenkracht in beslag kan nemen (Deshpande & Karypis, 2004).
Hoewel de methode zich onderscheidt in de snelheid van aanbevelen, blijkt veelal dat de kwaliteit van de aanbevelingen eerder laag is in vergelijking met de geheugen gebaseerde methode.
2.1.1.3 VERGELIJKENDE TABEL
In onderstaande tabel worden de kenmerken van geheugen gebaseerde en model gebaseerde methode nog eens naast elkaar gezet.
Geheugen gebaseerd Model gebaseerd
Aanbeveel snelheid Traag Snel
Opbouw snelheid Snel Traag
Schaalbaarheid Minder schaalbaar Erg schaalbaar Gebruik Commerciële applicaties Onderzoek Tabel 1: Vergelijking geheugen- en modelgebaseerde systemen
2.1.1.4 VOORDELEN COLLABORATIVE FILTERING
In hoofdstuk 2.1.1 werd vermeld dat collaborative filtering de populairste methode is om aanbevelingssystemen te bouwen. Er zijn meerdere voordelen verbonden aan systemen die gebruik maken van deze methode. Hieronder worden de belangrijkste voordelen opgesomd.
Een eerste voordeel van collaborative filtering is dat er enkel data nodig is die de interacties van de gebruikers beschrijft. Het aanbevelingssysteem is niet afhankelijk van data over de items. Hierdoor kent collaborative filtering een enorm breed toepassingsgebied (Liu, Chen, Xiong, Ding, & Chen, 2012). Bijgevolg is dit de ideale methode om te gebruiken wanneer items niet makkelijk analyseerbaar zijn via een automatisch proces. Denk hierbij aan video’s, geluidsbestanden etc. Daarnaast zijn er ook minder inspanningen nodig om de correcte data te verzamelen.
Een tweede voordeel is dat items gefilterd kunnen worden op basis van voorkeuren en kwaliteit. Waar het voor computers erg moeilijk is om de kwaliteit van een item in te schatten, is het via collaborative filtering wel mogelijk om bijvoorbeeld enkel goed geschreven artikels weer te geven (Herlocker, Konstan, Borchers, & Riedl, 1999). De kwaliteit van de artikels kan namelijk ingeschat worden op basis van de beoordelingen die gegeven werden aan de artikels.
Als derde kan collaborative filtering items aanbevelen waarvan de gebruiker niet weet dat hij deze interessant vindt. Het systeem beveelt dan items aan die achteraf erg interessant blijken voor de gebruiker, maar die hij nooit zelf gekozen zou hebben (Herlocker, Konstan, Borchers, & Riedl, 1999).
Zo kan een gebruiker die tot nu toe enkel interesse toonde in artikels over machine learning een artikel aanbevolen krijgen dat gaat over blockchain. Het systeem beveelt dit artikel dan aan omdat gelijkaardige gebruikers, die ook voornamelijk interesse in machine learning vertoonden, ook interesse bleken te hebben in blockchain. Deze aanbeveling kan er uiteindelijk voor zorgen dat de gebruiker een heel nieuw interessegebied ontdekt. Zonder deze aanbeveling was die gebruiker vermoedelijk nooit in aanraking gekomen met artikels over blockchain.
2.1.1.5 NADELEN COLLABORATIVE FILTERING
Hoewel collaborative filtering meerdere voordelen kent, zijn er ook enkele nadelen. Hieronder worden de problemen van nieuwe gebruikers, nieuwe items en schaarste aangehaald. Hoewel deze hier gecategoriseerd worden onder nadelen van collaborative filtering, zijn dit veelal moeilijkheden die bij ieder soort aanbevelingssysteem voorkomen.
Nieuwe gebruikers
Ongeacht welke vorm van collaborative filtering gebruikt wordt, is er het probleem van nieuwe gebruikers. Dit staat ook wel bekend als het cold start probleem. Dit komt voor wanneer het aanbevelingssysteem niet in staat is om gepersonaliseerde aanbevelingen te doen, omdat de gebruiker nog niet gekend is in het systeem (Fernandez-Tobias, Braunhofer, Elahi, & Ricci, 2016). Doordat de nieuwe gebruiker nog onvoldoende data heeft achtergelaten, kan het aanbevelingssysteem onmogelijk de voorkeuren van de gebruiker bepalen. Dit maakt dat het niet mogelijk is om gepersonaliseerde aanbevelingen te doen voor deze gebruiker. Veelal wordt dan ook teruggevallen op het aanbevelen van items die binnen eenzelfde categorie zitten, of door populaire items aan te bevelen.
Hoewel hiervoor in de literatuur reeds meerdere oplossingen zijn voorgesteld, is dit een probleem dat nog steeds voor grote uitdagingen zorgt. Er is dan ook nog geen unieke oplossing gevonden die in iedere situatie werkt (Fernandez-Tobias, Braunhofer, Elahi, & Ricci, 2016). Een veel gebruikte oplossing is het combineren van de collaborative filtering en content-based methodologie, ook wel gekend als hybride aanbevelingssystemen (Adomavicius & Tuzhilin, 2005). Hoewel de content-based methodologie artikels kan aanbevelen die gelijkaardig zijn aan de reeds gelezen en beoordeelde artikels, blijft het probleem zich voordoen bij gebruikers die helemaal geen artikels beoordelen. Een echt sluitende oplossing voor het cold start probleem is er dus nog niet.
Nieuw item probleem
Naast nieuwe gebruikers, kunnen ook nieuwe items een probleem vormen. Aangezien collaborative filtering systemen volledig afhankelijk zijn van de voorkeuren van de gebruiker om items aan te bevelen, kan het aanbevelingssysteem pas een nieuw item aanbevelen van zodra er een substantieel aantal gebruikers dit item een beoordeling hebben gegeven (Adomavicius & Tuzhilin, 2005). Wanneer een nieuw item niet aanbevolen wordt aan gebruikers, bestaat de kans dat dit item amper wordt gelezen. Bijgevolg zullen er slechts weinig beoordelingen beschikbaar zijn voor dit nieuwe item, waardoor het item niet aanbevolen kan worden.
Adomavicius en Tuzhilin (2005) stellen dat ook dit probleem aangepakt kan worden door gebruik te maken van hybride aanbevelingssystemen. Daarnaast is ook de introductie van een vorm van randomisatie een mogelijke oplossing.
Schaarste
Een derde veel voorkomend probleem is dat het aantal beschikbare beoordelingen per gebruiker erg klein is in vergelijking met het aantal items waar voorspellingen voor moeten gebeuren (Adomavicius & Tuzhilin, 2005). Er is dus een noodzaak om een grote hoeveelheid items te voorspellen op basis van een kleine hoeveelheid data. Daarnaast hangt het succes van een collaborative filtering aanbevelingssysteem sterk af van de kritieke massa van gebruikers. Items die slechts van een kleine groep gebruikers een beoordeling hebben gekregen, zullen slechts heel uitzonderlijk aanbevolen worden aan andere gebruikers, zelfs wanneer dit item erg hoge beoordelingen kreeg (Adomavicius & Tuzhilin, 2005).
Een gerelateerd probleem is dat een gebruiker een heel specifieke smaak kan hebben. Wanneer er geen andere gebruikers met een gelijkaardige smaak in de populatie beschikbaar zijn, is het moeilijk voor het aanbevelingssysteem om correcte aanbevelingen te doen. Een mogelijke oplossing voor dit probleem is om naast de items die de gebruiker een beoordeling heeft gegeven, ook rekening te houden met bijvoorbeeld demografische gegevens van de gebruiker. Voorbeelden van deze demografische gegevens zijn: leeftijd, inkomen, burgerlijke staat etc. Dit principe wordt ook wel “demografische filtering” genoemd (Adomavicius & Tuzhilin, 2005). Op basis van deze demografische gegevens, kunnen toch gelijkaardige gebruikers gevonden worden. Deze groep van gelijkaardige gebruikers vormt dan de basis voor de aanbevelingen aan de gebruiker.
Het is duidelijk dat er zowel voor- als nadelen verbonden zijn aan het gebruik van collaborative filtering systemen. Vandaar dat er ook nog een andere methode is ontstaan voor het opbouwen van aanbevelingssystemen, nl. content-based filtering. In 2.1.2 wordt dieper ingegaan op de concrete werking van deze systemen.
2.1.2 CONTENT-BASED FILTERING
Waar een aanbevelingssysteem gebaseerd op collaborative filtering gaat kijken naar gelijkaardige gebruikers om nieuwe items aan te bevelen, gaat een content-based aanbevelingssysteem items aanbevelen die gelijkaardig zijn aan de items die de gebruiker in het verleden een hoge beoordeling heeft gegeven (Adomavicius & Tuzhilin, 2005). Enkel de items die sterk aansluiten bij de voorkeuren van de gebruiker, zullen dus aanbevolen worden.
Een moeilijkheid in het ontwikkelen van een content-based aanbevelingssysteem is dat het niet vanzelfsprekend is om menselijke perceptie en voorkeuren te formaliseren. Zo is het moeilijk uit te maken wat de exacte eigenschappen zijn die bepalen dat iemand een item als leuk of niet leuk classificeert (Yu, Schwaighofer, Tresp, Xu, & Kriegel, 2004). Juiste features afleiden om te bepalen of een item al dan niet leuk zal gevonden worden door een gebruiker, is dan ook een hele uitdaging. Rekening houdend met bovenstaande opmerking, gaat een content-based aanbevelingssysteem informatie putten uit een gedetailleerde representatie van de items. Deze features worden dan gebruikt om een gebruikersprofiel op te bouwen. Het model gaat ervan uit dat ieder item kan voorgesteld worden als een vector X = (x1, x2, …, xn), waar xi afgeleid wordt uit de eigenschappen van
een item. Dit kan gaan over een tekstuele beschrijving, meta-data, sleutelwoorden etc. (Chen, Chen, & Wang, 2015). Een veelgebruikte methode voor tekstuele items is de Term Frequency/Inverse Document Frequency (TF-IDF). Aan de hand van deze methode kan tekstuele data omgezet worden in een feature vector. De TF-IDF methode wordt gedetailleerd beschreven in 2.3.
Wanneer het content-based model gebruikersprofielen heeft samengesteld aan de hand van de opgestelde vectoren, probeert het model items aan te bevelen die het meest gelijkend zijn aan het gebruikersprofiel. Net zoals bij collaborative filtering wordt hier dus een afstand berekend (Chen, Chen, & Wang, 2015). In dit geval gaat het echter over de afstand tussen het gebruikersprofiel en het item-profiel, in plaats van de afstand tussen twee gebruikers. Een veel gebruikte methode om die afstand te berekenen is ook hier de cosinus afstandsmethode (Chen, Chen, & Wang, 2015).
Zoals hierboven reeds kort werd aangehaald, is een mogelijke toepassing voor content-based filtering het aanbevelen van items die tekstuele informatie bevatten. Dit kan gaan van documenten, websites tot nieuwsberichten. Content-based aanbevelingssystemen komen daarnaast ook voor bij webshops of aanbevelingen voor reizen (Chen, Chen, & Wang, 2015).
Hoewel content-based filtering systemen duidelijke use cases kennen, wordt deze methode toch minder extensief gebruikt dan collaborative filtering. Hierna worden achtereenvolgens de voor- en nadelen van content-based filtering aangehaald.
2.1.2.1 VOORDELEN CONTENT-BASED FILTERING Niche items
Een eerste voordeel van content-based filtering is dat dit systeem in staat is om niche items aan te bevelen (Google, sd). Het systeem gaat namelijk op zoek naar artikels die zo dicht mogelijk bij het gebruikersprofiel aanleunen. Wanneer een gebruiker in het verleden enkel interesse toonde in artikels over machine learning, zal een content-based filtering systeem opzoek gaan naar artikels die hier dichtbij aanleunen. Concreet worden dan steeds meer gespecialiseerde artikels aanbevolen. Hoewel dit een groot voordeel kan zijn, kan dit ook leiden tot overspecialisatie. Het probleem van overspecialisatie wordt verder beschreven in de nadelen.
Geen nood aan gebruikersdata
Een tweede voordeel van content-based filtering is dat het systeem geen nood heeft aan gebruikersdata om items te kunnen aanbevelen (Google, sd). Het is namelijk in staat om aan de hand van de attributen van de items die de gebruiker interessant vindt, andere items aan te bevelen. Dit maakt het ook een stuk makkelijker om het systeem op te schalen naar een groot aantal gebruikers. Relatief weinig resources
Gelinkt aan het hierboven beschreven voordeel, heeft een aanbevelingssysteem dat gebruik maakt van collaborative filtering nood aan eerder weinig resources. Aangezien de gebruikersmodellen automatisch opgesteld kunnen worden en dit ook relatief weinig computerkracht vereist in vergelijking met bijvoorbeeld een model gebaseerd collaborative filtering systeem, is het mogelijk om dit systeem te schalen zonder een enorme hoeveelheid resources nodig te hebben (Beel, Gipp, Langer, & Breitinger, 2016).
2.1.2.2 NADELEN CONTENT-BASED FILTERING Limiet aan content analyse
Een van de voornaamste nadelen van content-based filtering is dat deze techniek erg afhankelijk is van de beschikbare features die de items beschrijven. Daarnaast moeten deze features natuurlijk ook informatie bijhouden die relevant is om aanbevelingen te doen. Deze features zijn ofwel reeds beschikbaar, moeten ontleed worden door een computer (vb. tekstanalyse) of moeten manueel toegewezen worden. In veel situaties, bijvoorbeeld multimedia data, blijkt het niet vanzelf sprekend om features te ontleden met behulp van een computer. Daarnaast is het vaak niet praktisch om attributen manueel aan data toe te voegen. Hier zijn veelal onvoldoende middelen voor beschikbaar (Adomavicius & Tuzhilin, 2005).
Ook kan het probleem zich voordoen dat twee verschillende items voorgesteld worden door dezelfde attributen. Dit zorgt ervoor dat deze twee items niet te onderscheiden zijn (Adomavicius & Tuzhilin, 2005).
Overspecialisatie
Een tweede nadeel van content-based filtering is dat het aanbevelingssysteem snel te gespecialiseerde aanbevelingen gaat doen. Wanneer een aanbevelingssysteem enkel items aanbeveelt die dicht bij het gebruikersprofiel liggen, zal de gebruiker enkel items aanbevolen krijgen die dicht bij de items liggen die reeds een positieve beoordeling hebben gekregen (Adomavicius & Tuzhilin, 2005).
Wanneer een gebruiker bijvoorbeeld enkele hoge beoordelingen gegeven heeft aan artikels over machine learning, zal het aanbevelingssysteem enkel andere artikels over machine learning aanbevelen. Dit terwijl de gebruiker misschien ook interesse heeft in artikels over tuinieren.
Een veel gebruikte oplossing voor dit probleem is het introduceren van een vorm van randomisatie. Het aanbevelingssysteem beveelt dan regelmatig een willekeurig item aan, om ervoor te zorgen dat de aanbevelingen niet te gespecialiseerd worden (Adomavicius & Tuzhilin, 2005).
Overspecialisatie kan echter ook in een andere richting bekeken worden. Het is niet alleen een probleem wanneer een aanbevelingssysteem enkel items aanbeveelt die dicht bij elkaar liggen. Het kan ook een probleem vormen wanneer het aanbevelingssysteem items aanbeveelt die té dicht liggen bij de items die reeds een positieve beoordeling kregen van de gebruiker (Adomavicius & Tuzhilin, 2005). Zo willen we vermoedelijk vermijden dat een gebruiker een artikel aanbevolen krijgt dat exact hetzelfde onderwerp beschrijft als in andere artikels die reeds gelezen werden door de gebruiker. Vandaar dat bepaalde content-based aanbevelingssystemen niet enkel de items die te ver van het gebruikersprofiel liggen, maar ook diegene die te dicht liggen niet aanbevelen.
Nieuwe gebruikers
Net zoals bij collaborative filtering, komt hier het probleem van nieuwe gebruikers voor. Ook hier is het noodzakelijk dat een gebruiker voldoende items beoordeelt, zodat het aanbevelingssysteem betrouwbare aanbevelingen kan doen. Nieuwe gebruikers, die nog maar weinig items beoordeeld hebben, zullen dus veelal minder accurate aanbevelingen krijgen (Adomavicius & Tuzhilin, 2005). Uit de voor- en nadelen analyse van collaborative filtering en content-based filtering, blijkt dat beide systemen elkaars zwaktes vrij goed aanvullen. Vanuit deze redenering zijn dan ook hybride aanbevelingssystemen ontstaan. Deze systemen combineren de kracht van collaborative filtering met content-based filtering om een nog beter presterend aanbevelingssysteem te ontwerpen. In 2.1.3 staat de werking van hybride aanbevelingssystemen verder beschreven.
2.1.3 HYBRIDE
Om de nadelen van zowel collaborative filtering en content-based filtering te minimaliseren, wordt veelal gebruik gemaakt van hybride aanbevelingssystemen. De methodes worden dan als volgt gecombineerd (Adomavicius & Tuzhilin, 2005).
1. Content-based filtering en collaborative filtering apart implementeren. Beide voorspellingen worden dan gecombineerd en resulteren in de uiteindelijke aanbevelingen;
2. Bepaalde elementen van collaborative filtering implementeren in content-based filtering of vice versa. Dit wordt ook wel feature augmentation genoemd (Beel, Gipp, Langer, & Breitinger, 2016);
3. Een nieuw model opbouwen dat karakteristieken van beide methodes incorporeert.
Er kan nog veel dieper ingegaan worden op de verschillende implementatiemogelijkheden van hybride aanbevelingssystemen, maar dit ligt echter buiten de scope van deze masterproef. Vandaar dat dit hier niet verder beschreven wordt.
2.2 TEKSTANALYSE
Werken met tekst is één van de uitdagingen binnen aanbevelingssystemen en data-analyse. Wanneer items voornamelijk beschreven worden door tekst, is het noodzakelijk om deze tekst ook om te kunnen zetten in bruikbare features. De grote moeilijkheid zit hier in het feit dat tekst ongestructureerde data is. Het is dan ook een uitdaging om deze tekst te converteren naar een tabel met velden die allemaal één specifieke betekenis hebben. Daarnaast is er ook nog het probleem dat de teksten vaak schrijffouten en grammaticale fouten bevatten. Bijkomend zijn er ook nog afkortingen, synoniemen, homoniemen… die de complexiteit van het probleem verhogen.
Al deze factoren zorgen ervoor dat tekst niet zomaar in een machine learning algoritme kan gestoken worden. Eerst is er nood aan data engineering.
Om te beginnen moet er een onderscheid gemaakt worden tussen de verschillende soorten tekst. Tekst is vaak gewoon een string, maar niet iedere string moet behandeld worden als tekst data. Zo kan tekst in sommige situaties voorgesteld worden als een categorische variabele. Dit gebeurt wanneer de tekstdata slechts uit enkele waarden kan bestaan. Een voorbeeld hiervan is wanneer de data uit een webformulier komt waar er een favoriete kleur moest aangegeven worden en de enige mogelijkheden “rood”, “geel”, “groen”, “blauw” waren. Dit zijn allemaal strings, maar door de beperkte mogelijkheden kan deze data gewoon voorgesteld worden als een categorische variabele (Müller & Guido, 2017).
Wanneer we kijken naar werkelijke tekst data, die niet voorgesteld kan worden als een categorische variabele, gaat het over vrije tekst die bestaat uit zinnen en woorden. Dit kunnen nieuwsartikels, tweets, reviews etc. zijn. In de context van tekstanalyse wordt de dataset van teksten het corpus genoemd en wordt iedere individuele tekst een document genoemd. Deze termen zijn afkomstig uit de information retrieval (IR) en Natural language processing (NLP) gemeenschappen (Müller & Guido, 2017).
Bag of words
Een eerste mogelijkheid om tekst voor te stellen als feature vector is door gebruik te maken van een bag of words. Deze techniek behandelt iedere tekst als een collectie van individuele woorden. Grammatica, woordvolgorde, zinsbouw en interpunctie worden hier dus volledig buiten beschouwing gelaten. Ieder woord is hierbij een mogelijk feature. In zijn meest simpele vorm is ieder woord dan een token en stelt de feature vector voor of het woord al dan niet voorkomt in het document. Wat echter meer voorkomt, is dat er niet alleen gekeken wordt of het woord al dan niet voorkomt, maar daarnaast ook geteld wordt hoe vaak een woord voorkomt in ieder document. Deze techniek is ook wel bekend als de Term Frequency (Provost & Fawcett, 2013).
De technische implementatie voor de bag of word methode gaat als volgt (Müller & Guido, 2017): - Tokenisatie: Opsplitsen van documenten in een lijst van woorden. Dit gebeurt veelal door te
splitsen op spaties en interpunctie;
- Woordenschat opbouwen: Een genummerde lijst opbouwen van alle woorden die voorkomen in het corpus;
Bovenstaande benadering blijkt echter vaak onvoldoende te zijn om een goede feature vector samen te stellen. Zo wordt hetzelfde woord, waarbij het eens met en eens zonder hoofdletter voorkomt, als twee verschillende woorden gezien. Een gelijkaardig probleem komt voor met vervoegde en niet vervoegde werkwoorden.
Om deze problemen te vermijden moeten er nog enkele bewerkingen gebeuren op de tekstdata (Provost & Fawcett, 2013):
- Normalisatie: Ieder woord in kleine letters zetten;
- Stemming: alle achtervoegsels verwijderen. Zo blijft bij werkwoorden enkel de stam over en worden al deze vervoegde vormen als één term gezien;
- Verwijderen van stopwoorden: Bepaalde worden komen zo vaak voor dat ze geen meerwaarde zijn om op te nemen in het machine learning algoritme. Voorbeeld hiervan zijn: de, het, een, of …
TF-IDF
De hierboven beschreven term frequency techniek geeft weer hoe vaak een woord voorkomt in een bepaald document. Het is echter ook interessant om te weten hoe vaak dit woord voorkomt in het volledige corpus. Hierbij moet er rekening gehouden worden met twee overwegingen.
Ten eerste mag het woord niet te weinig voorkomen in het corpus. Als een woord bijvoorbeeld slechts in één document voorkomt, heeft het weinig voorspellende waarde voor de andere documenten. Ten tweede mag een woord ook niet te veel voorkomen. Wanneer een woord in bijna ieder document voorkomt, heeft het ook geen voorspellende waarde meer. Woorden die te vaak of te weinig voorkomen, worden dan ook meestal uit de data gefilterd (Provost & Fawcett, 2013).
Bovenstaande problemen kunnen aangepakt worden door gebruik te maken van de Inverse Document Frequency (IDF) van een woord t.
𝐼𝐷𝐹(𝑡) = 1 + log ( 𝑇𝑜𝑡𝑎𝑎𝑙 𝑎𝑎𝑛𝑡𝑎𝑙 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑒𝑛
𝐴𝑎𝑛𝑡𝑎𝑙 𝑑𝑜𝑐𝑢𝑚𝑒𝑛𝑡𝑒𝑛 𝑤𝑎𝑎𝑟 𝑡 𝑖𝑛 𝑣𝑜𝑜𝑟𝑘𝑜𝑚𝑡 )
IDF kan gezien worden als een boost voor een woord omdat het weinig voorkomt. In hoe minder documenten een woord voorkomt, hoe significanter het woord vermoedelijk is in het document waar het wel voorkomt (Provost & Fawcett, 2013).
Een veel gebruikte representatie van tekst is de combinatie van Term Frequency en Inverse Document Frequency. Ook wel bekend als TF-IDF. De berekening van de TF-IDF gebeurt als volgt, met term t en document d:
𝑇𝐹𝐼𝐷𝐹(𝑡, 𝑑) = 𝑇𝐹(𝑡, 𝑑) × 𝐼𝐷𝐹(𝑡)
De TF-IDF stelt hierbij voor hoe belangrijk een woord is in een document en corpus (Provost & Fawcett, 2013). Een woord dat vaak voorkomt in één bepaald document, maar in weinig documenten in het corpus krijgt hier dus een zwaarder gewicht (Müller & Guido, 2017).
N-gram
In de situatie die hierboven beschreven staat, is ieder individueel woord gelijk aan een term. Er wordt dus helemaal geen rekening gehouden met hoe de woorden geordend staan. Het kan echter voorkomen dat de ordening van de woorden juist erg belangrijk is. In plaats van enkel individuele woorden als termen te zien, kunnen ook sequenties van woorden gebruikt worden als term. Dit principe wordt ook wel n-grams genoemd. N staat hierbij voor het aantal woorden dat als sequentie genomen wordt (Provost & Fawcett, 2013). Wanneer een sequentie van twee woorden een term representeert, worden dit ook wel bigrams genoemd. In de praktijk zullen veelal zowel de individuele woorden als enkele n-grams opgenomen worden als termen (Müller & Guido, 2017).
Bij de keuze van het aantal n-grams, moet er echter rekening gehouden worden met het feit dat een grotere hoeveelheid features sneller leidt tot overfitting. Een hoog aantal n-grams opnemen in de dataset kan daarnaast ook leiden tot een enorme hoeveelheid extra data die verwerkt moet worden. Het staat dus zeker niet vast dat meer n-grams opnemen steeds leidt tot een beter begrip van de tekst en dus betere resultaten.
Named entity extraction
In sommige gevallen willen we nog een complexere manier gebruiken om zins- en woordconstructies te begrijpen. Typische woordcombinaties als Game of Thrones willen we niet als drie verschillende termen Game, of en Thrones opnemen, maar als één term. Dit proces heet named entity extraction en is een erg kennis intensief proces waar een grote hoeveelheid data voor nodig is (Provost & Fawcett, 2013).
Het is duidelijk dat het werken met tekst niet vanzelfsprekend is voor aanbevelingssystemen. Er moeten heel wat keuzes gemaakt worden bij het verwerken van de tekstdata zodat er feature vectoren ontstaan die een meerwaarde bieden voor het machine learning algoritme.
Andere keuzes bij het verwerken van de tekst, kunnen dan ook leiden tot heel andere resultaten. Een goede strategie is dan ook om verschillende tekstanalyse technieken met elkaar te vergelijken bij het testen van het machine learning algoritme.
2.3 GEBRUIKERSFEEDBACK
Een belangrijk element in aanbevelingssystemen is gebruikersfeedback. De gebruiker geeft hierbij aan wat eerder dichtbij of ver van zijn voorkeuren ligt. Aan de hand van deze feedback kan het aanbevelingssysteem zich dan aanpassen, om zo betere aanbevelingen te kunnen doen in de toekomst.
Veelal zijn aanbevelingssystemen intrusive. Om goede aanbevelingen te kunnen maken hebben ze nood aan expliciete feedback van de gebruiker, zoals het geven van een beoordeling. Dit vraag een significante tussenkomst van de gebruiker. In veel gevallen zal er gevraagd worden om een score van één tot vijf te geven aan een item. Het aanbevelingssysteem heeft eerst heel wat scores nodig voordat het in staat is om goede aanbevelingen te kunnen doen (Adomavicius & Tuzhilin, 2005).
Aangezien het niet vanzelfsprekend is om voldoende beoordelingen te krijgen van gebruikers, en dus veelal maar weinig data beschikbaar is, zijn non-intrusive feedbacksystemen ontstaan. Hierbij worden bepaalde datapunten gebruikt die de werkelijke beoordeling van een gebruiker moeten benaderen. Een voorbeeld hiervan is de tijd dat een gebruiker spendeerde aan het lezen van een bepaald artikel. Hier is echter het probleem dat deze benaderingen vaak niet voldoende aansluiten bij de werkelijke voorkeuren van de gebruiker (Adomavicius & Tuzhilin, 2005).
Expliciete feedback
De meeste gebruikte en meest voor de hand liggende methode om gebruikersfeedback te krijgen, is om deze rechtstreeks aan de gebruiker te vragen. Dit staat ook wel bekend als expliciete gebruikersfeedback. De gebruiker geeft hierbij dan zelf aan hoe goed hij een item vond. Veelal gebeurt dit door een score te geven van 1 tot en met 5.
Vaak blijkt echter dat gebruikers voornamelijk extreme scores geven. Gebruikers zullen namelijk vooral hun voorkeuren uitspreken wanneer ze erg sterk voor of tegen een bepaald item zijn (Jawaheer, Szomszor, & Kostkova, 2010). Op een schaal van 1 t.e.m. 5 zullen de scores 1 en 5 dus heel vaak voorkomen, terwijl de scores daartussen maar heel weinig voorkomen.
Een voordeel van expliciete feedback is dat de gebruiker zowel positieve als negatieve feedback kan achterlaten. Zo zal een lage score een negatief gevoel voor het item uitdrukken, terwijl een hoge score een positief gevoel uitdrukt (Jawaheer, Szomszor, & Kostkova, 2010).
Impliciete feedback
Impliciete feedback kan gebruikt worden om aanbevelingssystemen op te bouwen zonder dat de eindgebruiker moet tussenkomen door beoordelingen te geven. Impliciete feedback wordt verzameld door gebruikersgedrag te monitoren. Dit kan door gewoonweg de tijd te meten dat een gebruiker spendeert op een pagina, maar ook klik- en scrolgedrag kan in rekening genomen worden. Doordat deze data vrij makkelijk te verzamelen is, wordt deze dan ook in veel grotere hoeveelheden verkregen. Een groot nadeel is dan weer dat er veelal redelijk wat ruis aanwezig kan zijn op deze data. De data is dus een stuk moeilijker te interpreteren (Peska, 2016).
Het voornaamste voordeel van impliciete feedback is dat er een aanbevelingssysteem gebouwd kan worden zonder dat er aan de eindgebruiker beoordelingen gevraagd moeten worden. Er is dus geen nood aan de implementatie van een beoordelingssysteem om een werkend aanbevelingssysteem te hebben.
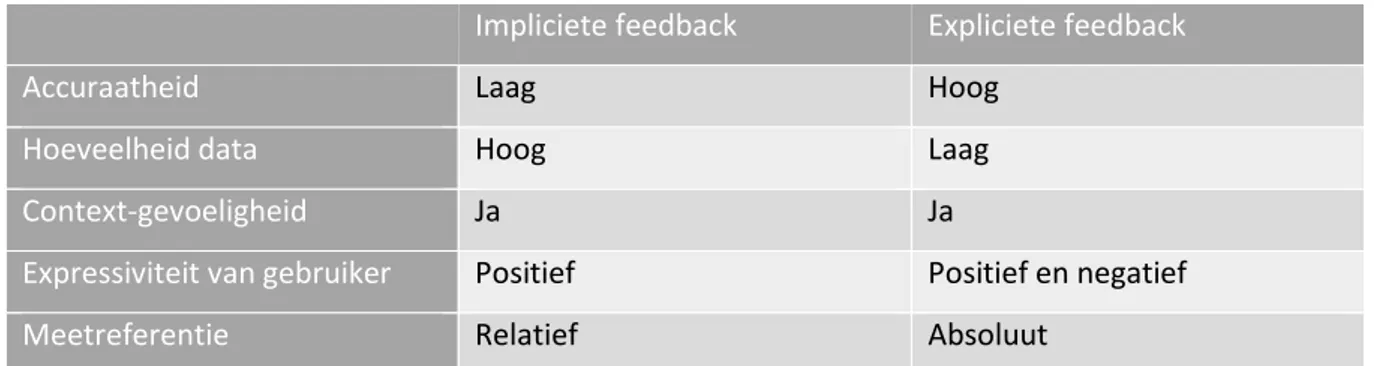
Vergelijkende tabel
Impliciete feedback Expliciete feedback
Accuraatheid Laag Hoog
Hoeveelheid data Hoog Laag
Context-gevoeligheid Ja Ja
Expressiviteit van gebruiker Positief Positief en negatief
Meetreferentie Relatief Absoluut
HOOFDSTUK 3
ONTWERP
Om de doelstellingen beschreven in 1.1 te behalen, beschrijft dit hoofdstuk de algemene opstelling van de casestudy. Hier wordt echter nog niet concreet ingegaan op de implementatie, die later in hoofdstuk 4 besproken wordt.
3.1 CASESTUDY
Deze casestudy werd opgebouwd in samenwerking met Bloovi bvba. Bloovi is een onderneming, gevestigd in Sint-Martens-Latem, die werd opgericht in 2012. Sindsdien is Bloovi uitgegroeid tot populair platform in België en Nederland waar dagelijks nieuwe artikels op verschijnen. Hun doelpubliek bestaat voornamelijk uit ondernemers die daarnaast ook interesse hebben in technologie. Naast content creatie organiseert Bloovi ook eigen evenementen en brengt het tweejaarlijks een eigen magazine uit. Met ca. 125 000 bezoekers per maand, meer dan 60 000 volgers op sociale media en bijna 21 000 gebruikers die ingeschreven zijn op hun nieuwsbrief, is Bloovi een content platform van formaat te noemen (D'Hoore, sd).
Bloovi doet echter nog geen beroep op een aanbevelingssysteem om artikels aan te bevelen aan gebruikers. Wanneer een gebruiker een bepaald artikel gelezen heeft, wordt er wel een volgend artikel weergegeven onder het gelezen artikel, maar dit is niet gepersonaliseerd. Dit gebeurt gewoon willekeurig of op basis van de categorieën waarin de artikels zijn ingedeeld.
Daarnaast is er bij Bloovi ook nog geen duidelijke opstelling om een aanbevelingssysteem te implementeren. Zo worden er geen beoordelingen gevraagd aan gebruikers over artikels en moeten gebruikers niet inloggen om artikels te lezen op het platform. Een aanbevelingssysteem implementeren op basis van expliciete gebruikersfeedback is in deze situatie dus niet evident en zou relatief grote inspanningen van Bloovi vragen.
Hoewel de implementatie op het eerste zicht niet evident lijkt, kan een goed werkend aanbevelingssysteem wel enorm relevant zijn voor Bloovi. Hoe meer tijd gebruikers op de website spenderen en hoe meer artikels ze lezen, hoe interessanter het is voor Bloovi. Artikels aanbevelen die aansluiten bij de voorkeuren van de gebruikers, zou deze statistieken de hoogte kunnen induwen. Wat wel aanwezig is bij Bloovi is een koppeling met Google Analytics. Daarnaast zijn de geschreven artikels, met bijbehorende data, makkelijk beschikbaar via de API van Storychief. Wat Google Analytics en Storychief exact zijn worden verder beschreven in 3.2.1 en 3.2.2.
Deze casestudy is opgebouwd om een aanbevelingssysteem te proberen ontwikkelen dat in staat is om artikels aan te bevelen die aansluiten bij de voorkeuren van de gebruikers, zonder expliciete feedback van de gebruikers te vragen. Het aanbevelingssysteem steunt dus enkel op data die gebruikers standaard achterlaten op de website.
3.2 DATABRONNEN
Aanbevelingssystemen worden aangedreven door data. Hoe meer en betere data er ter beschikking is, hoe betere voorspellingen het aanbevelingssysteem zal kunnen doen. Een belangrijke beperking in de data van Bloovi, is dat er geen expliciete gebruikersfeedback beschikbaar is. Aangezien dit voor hen niet vanzelfsprekend is om te implementeren, wordt er in deze casestudy enkel gebruik gemaakt van de impliciete gebruikersfeedback die achtergelaten wordt. De twee databronnen die voor deze casestudy gebruikt worden zijn de Google Analytics data en de data over de artikels die beschikbaar is via de API van Storychief.
3.2.1 GOOGLE ANALYTICS DATA
Google Analytics is een tool die ter beschikking gesteld wordt door Google om data te verzamelen op een website. Door een javascript trackingcode op de website te plaatsen worden verschillende events, zoals waar de gebruiker klikt, gemonitord. De data die hierdoor verzameld wordt, komt dan terecht in de Google Analytics applicatie.
Wanneer een gebruiker surft op een website waar de Google Analytics tracking code op staat, wordt er een cookie aangemaakt. De cookie bevat een uniek identificatienummer, de client ID, die het mogelijk maakt om de gebruiker te identificeren. Wanneer de gebruiker de website verlaat en later terugkomt, wordt de nieuwe sessie van deze gebruiker ook gelinkt aan deze client ID. Een cookie verloopt echter na twee jaar, waardoor enkel de sessies van de laatste twee jaar aan een gebruiker gelinkt kunnen worden. Daarna wordt deze gebruiker een nieuw client ID toegewezen, waardoor het lijkt voor Google Analytics dat dit een nieuwe gebruiker is (Google, sd). Dit kan een enorme impact hebben op de werking van het aanbevelingssysteem.
De data is ook beschikbaar via de Google Analytics reporting API. In deze casestudy werd gebruik gemaakt van deze API om de dataverzameling vlotter te laten verlopen.
3.2.2 ARTIKELS
Bloovi gebruik Storychief als tool om hun artikels te schrijven en te publiceren. De artikels worden in deze tool gepubliceerd en worden dan opgehaald via de API-laag die Storychief ter beschikking stelt om te laten zien op www.bloovi.be.
Naast de inhoud van het artikel, kan ook informatie over de auteur, publicatiedatum etc. opgehaald worden. In deze casestudy werden de artikels opgehaald via de Storychief API om het aanbevelingssysteem te kunnen trainen.
3.3 HET AANBEVELINGSSYSTEEM
3.3.1 SCOREMECHANISME
Aangezien er geen expliciete feedback in de vorm van beoordelingen beschikbaar is op de Bloovi website, wordt er een alternatieve methode voorgesteld om de voorkeuren van de gebruikers te benaderen. De beschikbare data in Google Analytics maakt het mogelijk om te achterhalen hoe lang een gebruiker spendeert op een bepaalde pagina. Daarnaast kan het aantal woorden waaruit een artikel bestaat berekend worden. De gemiddelde leessnelheid ligt veelal tussen 200 en 300 woorden per minuut (Jackson & McClelland, 1979). Aan de hand van deze gegevens kan berekend worden wat de gemiddelde duur is dat iemand nodig heeft om het volledige artikel te lezen.
Vanuit deze twee datapunten, nl. de tijd dat de gebruiker op de pagina heeft gespendeerd en de verwachte tijd die nodig is om het artikel volledig te lezen, kan een score berekend worden die aangeeft welk percentage van het artikel gelezen werd door de gebruiker. Dit kan hier dan ook gezien worden als een benadering van de interesse voor het artikel van de gebruiker. Wanneer de gebruiker het artikel interessant vond, zal hij een groter deel van het artikel gelezen hebben wat dus leidt tot een betere score.
Er moet echter wel rekening gehouden worden met een belangrijke beperking van deze score. We gaan ervan uit dat bovenstaand scoremechanisme een benadering is voor de interesse die een gebruiker heeft in het artikel. Het ligt echter niet vast dat, wanneer een gebruiker een artikel volledig gelezen heeft, hij dit artikel weldegelijk interessant vond. Er is ook steeds een mogelijkheid dat de gebruiker het artikel wel volledig gelezen heeft, maar achteraf beseft dat het artikel niet interessant was voor hem. Het hierboven beschreven scoremechanisme maakt geen onderscheid tussen een gebruiker die het artikel volledig gelezen heeft en het ook interessant vond, en een gebruiker die het artikel volledig gelezen heeft maar dit niet interessant vond.
3.3.2 AANBEVELINGSSYSTEEM
Om een duidelijk beeld te geven van de mogelijkheden van dit impliciete feedbacksysteem, worden er drie methodes gebruikt. Namelijk het populariteitsmodel, content-based filtering en collaborative filtering.
Populariteitsmodel
Deze methode wordt typisch gebruikt om een baseline te kunnen vastleggen. Waar deze methode niet-gepersonaliseerde aanbevelingen geeft, blijkt het veelal moeilijk te zijn om het resultaat van dit model te overtreffen. Het populariteitsmodel beveelt gewoonweg de meest populaire artikels aan die de gebruiker nog niet heeft gelezen. Hierbij wordt uitgegaan van het principe dat, wanneer een grote groep gebruikers het artikel interessant vinden, de kans groot is dat deze gebruiker het ook interessant zal vinden.
Content-based filtering
Zoals eerder uitgebreid werd beschreven in de literatuurstudie, worden bij content-based filtering de features van items gebruikt om aanbevelingen te doen. Er wordt een gebruikersprofiel opgezet, dat een aggregatie is van de attributen van de reeds gelezen items. Daarna zoekt het aanbevelingssysteem naar items waarvan de attributen dicht aansluiten bij het gebruikersprofiel.
Collaborative filtering
In tegenstelling tot content-based filtering, wordt er bij collaborative filtering gezocht naar gelijkaardige gebruikers. Gebruikers die in het verleden gelijkaardig gedrag vertoonden, kunnen gezien worden als gelijkaardig. De artikels die gelijkaardige gebruikers interessant vonden, zullen dus vermoedelijk ook interessant zijn voor deze gebruiker.
Door de resultaten van deze drie modellen te bekijken, kan een goed idee gevormd worden over de mogelijke prestaties van een aanbevelingssysteem gebaseerd op de impliciete feedbackmethode die hierboven reeds beschreven werd.
3.4 EVALUATIEMETHODE
Aangezien het gebouwde aanbevelingssysteem niet in productie getest wordt op Bloovi, moet er gezocht worden naar een evaluatiemethode die een zo goed mogelijke benadering is van de werkelijkheid. Ook hier moet echter weer direct de opmerking gemaakt worden dat, ongeacht de gekozen evaluatiemethode, de scoringsmethode die gebruikt wordt niet altijd de werkelijke voorkeuren van de gebruiker weergeeft. Er wordt namelijk geen onderscheid gemaakt tussen een gebruiker die het volledige artikel gelezen heeft, maar dit niet interessant vond en een gebruiker die het volledige artikel heeft gelezen en het wel interessant vond.
3.4.1 TRAIN- EN TESTDATA
Om de train- en testdata zo dicht mogelijk te laten aansluiten bij de werkelijkheid, werd de data opgedeeld volgens datum. De volledige dataset strijkt over een tijdsperiode van één jaar, nl. 01/04/2019 – 01/04/2020. Om een verdeling te krijgen van 80% trainingsdata en 20% testdata, werden alle sessies van voor 01/01/2020 in de trainingsdata geplaatst, en de sessies na 01/01/2020 in de testdata. Op die manier simuleert de dataset de werkelijke situatie op 01/01/2020. Zo wordt ook vermeden dat er data gebruikt wordt die in de werkelijke situatie niet aanwezig zou zijn (bv. een gebruikersprofiel dat opgebouwd wordt aan de hand van artikels die gelezen werden in de toekomst).
3.4.2 EVALUATIEMODEL
Om een beeld te krijgen van de prestatie van het aanbevelingssysteem, werd een evaluatiemodel uitgewerkt gebaseerd op de recall@k methode. De recall@k wordt als volgt berekend:
𝑟𝑒𝑐𝑎𝑙𝑙@𝑘 = # 𝑔𝑒𝑐𝑎𝑝𝑡𝑒𝑒𝑟𝑑𝑒 𝑇𝑟𝑢𝑒 𝑙𝑎𝑏𝑒𝑙𝑠 # 𝑇𝑟𝑢𝑒 𝑙𝑎𝑏𝑒𝑙𝑠
In deze casestudy wordt zowel gebruik gemaakt van de recall@5 als de recall@10, om een meer algemeen beeld van de prestaties van het aanbevelingssysteem weer te geven. De gebruikte evaluatiemethode werkt als volgt.
Voor iedere gebruiker wordt er voor ieder item waarmee de gebruiker interactie heeft gehad 100 items geselecteerd waarmee de gebruiker nog geen interactie heeft gehad. Er moet opgemerkt worden dat ervan uitgegaan wordt dat deze items niet relevant zijn voor de gebruiker. In werkelijkheid zal dit echter niet altijd het geval zijn. Nadien stelt het aanbevelingssysteem een gerangschikte lijst van aanbevolen items samen van de set die bestaat uit één item waar interactie mee was en de 100 items waar geen interactie mee was. De recall@k evalueert dan of het item waar de gebruiker interactie mee gehad heeft in de top k items zat van de gerangschikte lijst van 101 items (Moreira, 2019).
Uiteindelijk worden deze scores dan geaggregeerd tot één algemene score voor het model.
3.5 GEBRUIKTE TECHNOLOGIEËN
Om de data te verwerken en het aanbevelingssysteem op te bouwen, werd gebruik gemaakt van een hele reeks technologieën. In deze casestudy wordt gebruik gemaakt van Python en verschillende frameworks en libraries die gebaseerd zijn op Python.
Pandas: Pandas is een open source data analyse en manipulatie tool, gebaseerd op Python (Pandas, sd).
Scikit-learn: Scikit-learn is een open source machine learning library, gebaseerd op Python, Numpy, Scipy en matplotlib (scikit-learn, sd).
Numpy: Numpy is een Python package dat het makkelijk maakt om wetenschappelijke berekeningen uit te voeren. Numpy wordt veelal gebruikt voor multidimensionale arrays op te stellen (Numpy, sd).
HOOFDSTUK 4
IMPLEMENTATIE
In dit hoofdstuk staat de concrete implementatie voor deze casestudy beschreven en de keuzes die hierbij gemaakt werden. Naast de data verzameling wordt ook de dataverwerking, opbouw van de modellen en evaluatie van de modellen onder de loep genomen.
4.1 DATA VERZAMELING
Een essentieel element in een aanbevelingssysteem is de beschikbare data. Zoals eerder beschreven in hoofdstuk 5 is deze afkomstig uit twee databronnen. Ten eerste, de Google Analytics account van Bloovi die gekoppeld is aan de Bloovi website. Hier worden de sessies en alle bijhorende data van gebruikers bijgehouden. Daarnaast is de data over de artikels beschikbaar via de Storychief API.
4.1.1 GOOGLE ANALYTICS
De voornaamste data die uit Google Analytics gehaald moet worden is de data die de gebruikersinteracties op de website beschrijft. Belangrijk hierbij is dat de gebruikers uniek geïdentificeerd worden, zodat de verschillende sessies aan de correcte gebruiker gelinkt kan worden. Google Analytics stelt hierbij twee ID’s ter beschikking, nl. de user ID en de client ID.
Client ID. De client ID wordt aan iedere nieuw apparaat toegewezen. Alle sessies die gebeuren van op hetzelfde apparaat worden dan gezien als sessies van dezelfde gebruiker (Google, sd).
User ID. Typisch blijkt dat gebruikers meerdere apparaten gebruiken om dezelfde website te bezoeken. Zo zal de gebruiker bijvoorbeeld bepaalde artikels op een laptop lezen, terwijl hij andere artikels op een smartphone leest. De user ID maakt het mogelijk om eenzelfde gebruiker te volgen overheen meerdere apparaten. Om gebruik te maken van deze user ID is het echter noodzakelijk om de gebruikers al te identificeren in de webapplicatie. Dit gebeurt veelal door de gebruiker te laten inloggen (Google, sd).
Aangezien Bloovi geen mogelijkheid heeft ingebouwd om een gebruiker in de webapplicatie te identificeren, werd ervoor gekozen om gebruik te maken van de client ID. Ieder nieuw apparaat dat op de website komt, wordt voor het aanbevelingssysteem dus gelijk gesteld aan een unieke gebruiker. Dit kan dan ook tot gevolg hebben dat een bepaalde gebruiker op het ene apparaat aanbevelingen krijgt die dichter aansluiten bij zijn of haar voorkeuren, dan op een ander apparaat.

![Gemiddelde duur [minuten per jaar per getroffen afnemer]](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)