HET EFFECT VAN TRAINING OP DE
BETROUWBAARHEID VAN DE PERCEPTUELE
BEOORDELING VAN SPRAAK BIJ INDIVIDUEN
MET EEN (CHEILOGNATO)PALATOSCHISIS
DOOR ONERVAREN LUISTERAARS
Aantal woorden: 11110
Astrid Danhieux
Stamnummer: 01508319Promotor: Prof. dr. Kristiane Van Lierde
Copromotor: dr. Laura Bruneel
Masterproef voorgelegd voor het behalen van de graad master in de richting Logopedische en Audiologische Wetenschappen
Dankwoord
Graag zou ik mijn dank willen betuigen aan alle mensen die rechtstreeks, maar ook onrechtreeks hun steentje hebben bijgedragen bij de verwezenlijking van deze masterproef.
In de eerste plaats zou ik graag Prof. dr. Van Lierde willen bedanken voor het voorleggen van dit boeiende onderwerp en haar intellectuele bijdrage aan deze masterproef.
Daarnaast gaat een bijzondere dank uit naar dr. Bruneel, die mij op een fantastische manier heeft begeleid doorheen deze ervaring. Zij volgde mijn werk van heel nabij op en stond steeds klaar om uitgebreid antwoorden te bieden op al mijn vragen. Deze antwoorden en daarnaast de deskundige feedback en bijhorende suggesties zorgden ervoor dat ik deze masterproef tot een hoger niveau heb kunnen tillen. De expertise van dr. Bruneel in dit domein van de logopedie fascineerde mij enorm en zorgde voor een extra motivatie om mij te verdiepen in dit onderwerp. Dit heeft als resultaat dat ik ontzettend veel heb bijgeleerd.
Natuurlijk wil ik ook mijn medestudenten via deze weg bedanken voor hun deelname aan dit onderzoek. Zonder hen was deze masterproef niet tot stand gekomen.
Als laatste zou ik graag mijn vrienden en familie willen bedanken voor de vele steun die ze me geboden hebben de afgelopen jaren en voor hun oeverloos geduld met mij en deze masterproef. Zij stonden altijd paraat om mijn teksten aandachtig na te lezen of hulp te bieden bij het finaliseren van de lay-out van deze masterproef. Hartelijk bedankt!
Abstract – Nederlandstalige versie
Achtergrond: Voor de beoordeling van de spraak bij individuen met een (cheilognato)palatoschisis geldt de perceptuele beoordeling als gouden standaard. Recent werd het CAPS-A-NL ontwikkeld, een Nederlandstalig perceptueel beoordelingsinstrument specifiek om de spraakoutcome van Vlaamse individuen met een (cheilognato)palatoschisis te evalueren. Het effect van training op de betrouwbaarheid van de perceptuele beoordeling volgens dit instrument is nog niet voorhanden.
Doelstelling: Het doel van deze studie betreft de evaluatie van het effect van training op de betrouwbaarheid van de perceptuele beoordeling van spraak bij onervaren luisteraars gebruik makend van het CAPS-A-NL beoordelingsinstrument.
Methode: Vijfendertig eerste masterstudenten Logopedische Wetenschappen (Universiteit Gent) beoordeelden tien spraakstalen van individuen met een (cheilognato)palatoschisis gebruik makend van het CAPS-A-NL. Enkel de spraakparameters met ordinale schalen uit dit instrument werden opgenomen in deze studie, namelijk spraakverstaanbaarheid, hypernasaliteit, hyponasaliteit, nasale emissie, nasale turbulentie, stem en spraakaanvaardbaarheid. In totaal werden alle spraakstalen driemaal individueel beluisterd en beoordeeld. Een eerste beoordeling vond plaats voorafgaand aan de training. Vervolgens werden de studenten getraind in het beoordelen van de spraak bij individuen met een (cheilognato)palatoschisis. Tijdens deze twee uur durende training werden alle onderdelen van het CAPS-A-NL besproken en klassikaal ingeoefend. Onmiddellijk na deze training werden opnieuw tien spraakstalen beluisterd en beoordeeld aan de hand van het CAPS-A-NL. Tot slot vond één maand later de derde beoordeling plaats. De inter- en intrabeoordelaarsbetrouwbaarheid werden getoetst. Na afloop van elk beoordelingsmoment werden de studenten gevraagd de toepasbaarheid van en de suggesties voor de training met betrekking tot het invullen van het beoordelingsinstrument te evalueren aan de hand van een vragenlijst met een vijfpuntenschaal.
Resultaten: De interbeoordelaarsbetrouwbaarheid steeg onmiddellijk na de training voor alle zeven spraakparameters. Bij de beoordeling één maand later daalde de interbeoordelaarsbetrouwbaarheid voor vijf van de zeven spraakparameters, maar behoudens hyponasaliteit was de interbeoordelaarsbetrouwbaarheid één maand na de training voor alle spraakparameters hoger dan voor de training. De intrabeoordelaarsbetrouwbaarheid daalde onmiddellijk na de training voor vijf spraakparameters. Vervolgens steeg deze één maand na de training met uitzondering van spraakverstaanbaarheid voor alle spraakparameters. Niettemin was één maand na de training de intrabeoordelaarsbetrouwbaarheid voor alle spraakparameters hoger dan voor de training. Algemeen rapporteerden 87.6% van de studenten dat de inhoud van de training (zeer) relevant was voor het invullen van het CAPS-A-NL, maar vond 34.4% de voorziene trainingsduur onvoldoende.
Conclusie: Het volgen van een training in het perceptueel beoordelen door onervaren luisteraars heeft een verhoging van de inter- en intrabeoordelaarsbetrouwbaarheid tot gevolg en deze verbeteringen zijn één maand na de training nog steeds aanwezig. De positieve effecten van de training zijn echter niet voor alle spraakparameters op elk beoordelingsmoment in dezelfde mate aanwezig.
Abstract – English version
Background: The perceptual assessment is considered the golden standard for the evaluation of speech for individuals with cleft palate ± lip. The CAPS-A-NL was recently developed as a Belgian Dutch outcome tool for the perceptual assessment of speech for individuals with a cleft palate ± lip. Results regarding the effect of training on the reliability of the perceptual evaluation with this tool are not yet available.
Purpose: The present study aims to investigate the effect of training on the reliability of the perceptual evaluation of speech for individuals with cleft palate ± lip by untrained listeners with the CAPS-A-NL tool.
Method: Thirty-five speech-language pathology first master students (from the University of Ghent) were provided with ten speech samples of individuals with cleft palate ± lip to analyse according to the CAPS-A-NL. Only the parameters with ordinal scales were used in this investigation, i.e. intelligibility, hypernasality, hyponasality, nasal emission, nasal turbulence, voice and speech acceptability. All speech samples were analyzed individually and assessed three times by each student. A first evaluation took place prior to the training. Afterwards, the students were trained in assessing the speech for individuals with cleft plate ± lip. During this two-hour training, all parts of the CAPS-A-NL were discussed and practiced in group. Immediately after this training, the students listened again to ten speech samples and made a new assessment. Finally, the third evaluation took place after one month. Both the inter- and intra-rater reliability were tested. At the end of each assessment, the students were requested to complete a questionnaire with a five-point scale to evaluate the effectiveness of the training and to provide suggestions.
Results: The inter-rater reliability increased immediately for all seven parameters after the training. One month later, the inter-rater reliability decreased for five of the seven parameters. It was also noticed that except for hyponasality, inter-rater reliability was higher for all parameters one month after the training in comparison with the evaluation that took place prior to the training. The intra-rater reliability decreased directly for five parameters after the training. One month later, the intra-rater reliability increased for all parameters except for intelligibility. Nonetheless, the intra-rater reliability was still higher one month after the training for all seven parameters than before the training. In general, 87.6% of the students reported that the content of the training was (very) relevant for the completion of the CAPS-A-NL. However, 34.4% of the students reported that the duration of the training was insufficient.
Conclusion: Following a program of training in perceptual assessment by untrained listeners improves the inter- and intra- rater reliability and these improvements are still present one month after the training. It should however be noted that the positive effects of the training are not consistent across all parameters each time the assessment was made.
Inhoudstabel
1. INLEIDING ... 8
2. METHODE ... 14
2.1PARTICIPANTEN ... 14
2.2WERKWIJZE ... 15
2.2.1 Inhoud van de spraakstalen ... 15
2.2.2 Spraakparameters en luistervolgorde van het CAPS-A-NL ... 15
2.2.3 Perceptuele beoordeling aan de hand van het CAPS-A-NL ... 17
2.2.4 Statistische analyse ... 18
3. RESULTATEN ... 19
3.1INTERBEOORDELAARSBETROUWBAARHEID ... 19
3.2INTRABEOORDELAARSBETROUWBAARHEID ... 21
3.3VRAGENLIJSTEN MET FEEDBACK EN SUGGESTIES ... 23
4. DISCUSSIE ... 28
5. CONCLUSIE ... 34
6. REFERENTIES ... 35
1. Inleiding
(Cheilognato)palatoschisis, een lip-, kaak- en/of verhemeltespleet is een congenitale aandoening en treft ongeveer 1 op 700 levendgeborenen (Mossey, Little, Munger, Dixon, & Shaw, 2009; Dixon, Marazita, Beaty, & Murray, 2011). De etiologie van deze aandoening is multifactorieel, waarbij genetische en omgevingsfactoren aan de basis liggen (Murray, 2002; Wong & Hägg, 2004). Uit de literatuur blijkt dat individuen met een (cheilognato)palatoschisis een verhoogd risico hebben op het ontwikkelen van voedingsmoeilijkheden, meer specifiek slikproblemen (Clarren, Anderson, & Wolf, 1987; de Vries et al., 2014), gehoorverlies, tand- en mondafwijkingen, sociale en psychologische problemen, esthetische problemen en spraakstoornissen. Deze hebben bijgevolg een (negatieve) impact op de (gezondheidsgerelateerde) levenskwaliteit (Setó-salvia & Stanier, 2014; Allori et al., 2017).
In de literatuur worden hypernasaliteit, nasale emissie, nasale turbulentie en schisisgerelateerde consonantproductiefouten beschreven als zijnde typische spraakkenmerken geassocieerd bij een (cheilognato)palatoschisis (Whitehill, 2002; Brunnegård, Lohmander, & Van Doorn, 2009; Baylis, Munson, & Moller, 2011; Chapman et al., 2016). De typische spraakkenmerken bij individuen met een (cheilognato)palatoschisis kunnen voor een daling van de natuurlijkheid en aanvaardbaarheid van de spraak zorgen, alsook de spraakverstaanbaarheid bemoeilijken (Whitehill, 2002). De beoordeling van de spraak kan enerzijds op basis van instrumentele technieken gebeuren, anderzijds kan geopteerd worden voor het gebruik van een perceptuele beoordeling (Brunnegård et al., 2009).
De perceptuele beoordeling van de spraak bij individuen met een (cheilognato)palatoschisis wordt als de gouden standaard beschouwd (Kuehn & Moller, 2000; Sell, 2005; Henningsson et al., 2008; Chapman et al., 2016). Dit wordt verklaard vanuit het principe dat een spraakstoornis enkel bestaat als deze door het individu en anderen uit de nabije omgeving herkend wordt (Kuehn & Moller, 2000; Bettens et al., 2016). Het gebruik van perceptuele beoordelingen door clinici is volgens Bettens et al. (2016) gebaseerd op dit principe en kan tot op heden niet vervangen worden door een instrumentele beoordeling. Naast dit klinische belang kan opgemerkt worden dat een perceptuele beoordeling nog andere voordelen heeft, zoals het niet-invasieve karakter en het relatief eenvoudige gebruik (Kuehn & Moller, 2000).
Uit de literatuur blijkt dat er verschillende protocollen in de omloop zijn voor het perceptueel beoordelen van spraak bij individuen met een (cheilognato)palatoschisis (Dalston, Marsh, Vig, Witzel, & Bumstead, 1988; Sell, Harding, & Grunwell, 1994; Harding, Harland, & Razzell, 1997; Sell, Harding, & Grunwell, 1999; Dotevall, Lohmander-Agerskov, Ejnell, & Bake, 2002; John, Sell, Harding-Bell, Sweeney, & Williams, 2006; Henningsson et al., 2008; Chapman et al., 2016). Deze protocollen werden specifiek ontwikkeld om een gestandaardiseerde benadering van de spraakdocumentatie en spraakanalyse te bekomen (Kuehn & Moller, 2000; John et al., 2006). De grote verscheidenheid aan protocollen is onder andere te wijten aan het feit dat deze instrumenten taalafhankelijk zijn en verschillende doeleinden kennen. Een protocol kan ontwikkeld zijn voor klinische, outcome- of auditstudies (Kuehn & Moller, 2000). Deze laatste studies hebben tot doel het kwaliteitsverbeteringsproces in kaart te brengen door middel van een systematische toetsing van de zorg aan expliciete criteria ter verbetering en monitoring
van de zorg (Britton et al., 2014). Een andere verklaring voor de verscheidenheid aan perceptuele beoordelingsprotocollen zou volgens enkele auteurs voortvloeien uit een gebrek aan algemene terminologieën, definities en afspraken omtrent dataverzameling en analyse bij de verschillende beoordelingsinstrumenten (Kuehn & Moller, 2000; Lohmander & Olsson, 2004; Sell, 2005; Henningsson et al., 2008).
Sell, Harding en Grunwell (1994) ontwikkelden ‘The Great Ormond Street Speech Assessment’ (GOS.SP.ASS) een klinisch protocol voor het evalueren van de spraak bij een palatoschisis of een velofaryngeale dysfunctie. Het protocol werd herzien in 1998, getiteld als de GOS.SP.ASS.’98 (Sell et al., 1999). Het resultaat van deze herziening betreft een uitgebreid, praktisch instrument voor klinische doeleinden (Ahl & Harding-Bell, 2018), maar werd door John et al. (2006) beschouwd als te gedetailleerd voor het gebruik in auditstudies. Gelijktijdig met de revisie van de GOS.SP.ASS.’98 werd het Cleft Audit Protocol for Speech (CAPS) uitgebracht (Harding et al., 1997). Het CAPS werd specifiek ontworpen voor auditstudies en vindt zijn grondslag in het GOS.SP.ASS. Beide protocollen kunnen onafhankelijk van elkaar gebruikt worden, maar de resultaten zijn volgens Sell et al. (1999) vergelijkbaar. Het CAPS werd herzien door John et al. (2006), resulterend in het Cleft Audit Protocol for Speech-Augmented (CAPS-A) protocol. Deze herziening had tot doel een toepasbaar, valide en betrouwbaar instrument te ontwikkelen voor de evaluatie van de spraak bij individuen met een cheilognatopalatoschisis in auditstudies. De beoordeling gebeurt telkens volgens een gestandaardiseerd luisterprotocol. In dit protocol wordt gedefinieerd welk spraakstaal voor welke spraakparameter wordt gebruikt en in welke volgorde dit moet gebeuren. Daarnaast wordt ook elke spraakparameter gedefinieerd. De gedefinieerde spraakparameters beogen een uitvoerige beschrijving voor de beoordelaar als hulp om de verschillende spraakparameters correct en systematisch te beoordelen en de validiteit van het instrument te verzekeren (John et al., 2006). Hoewel de inhoud van bovenstaande protocollen enigszins vergelijkbaar was op vlak van beoordelingsparameters en beoordelingsschalen wezen Henningsson en collega’s (2008) erop dat een universeel, taalonafhankelijk protocol voor het rapporteren van de spraakoutcome bij individuen met een (cheilognato)palatoschisis ontbrak. Daarom gaven Henningsson et al. (2008) de aanzet tot het ontwikkelen van een universeel systeem voor het rapporteren van de spraakoutcome bij individuen met een palatoschisis (UPS). In dit instrument wordt elke spraakparameter gedefinieerd door distinctieve kenmerken en zijn richtlijnen voor de scoring voorhanden. Daarnaast leggen Henningsson et al. (2008) in dit spraakoutcome instrument de nadruk op het belang van de informatieverzameling en identificatie van het individu, alsook de richtlijnen voor fonetische gebalanceerde spraakstalen om cross-linguïstische vergelijkingen mogelijk te maken. De validiteit en betrouwbaarheid van dit protocol werden tot op heden nog niet aangetoond (Bruneel et al., 2020).
Ondanks het grote aantal Engelstalige perceptuele boordelingsprotocollen (Dalston et al., 1988; Sell et al., 1994; Harding et al., 1997; Sell et al., 1999; Dotevall et al., 2002; John et al., 2006; Henningsson et al., 2008; Chapman et al., 2016) blijkt een te kort te zijn aan Nederlandstalige perceptuele beoordelingsinstrumenten die de internationale richtlijnen omtrent spraakanalyse en spraakdocumentatie volgen, valide en betrouwbaar zijn en geschikt zijn voor wetenschappelijk
onderzoek. Op basis van deze drie criteria werd recent door Bruneel et al. (2020) een Nederlandstalig perceptueel beoordelingsinstrument ontwikkeld voor de evaluatie van de spraak bij individuen met een (cheilognato)palatoschisis. Hoofdzakelijk werd dit instrument gebaseerd op het CAPS-A protocol (John et al., 2006), voornamelijk voor wat betreft de spraakanalyse. Daarnaast werden ook elementen opgenomen uit het UPS opgemaakt door Henningsson et al. (2008), meer bepaald de richtlijnen voor het samenstellen van de spraakstalen, alsook de beoordelingsparameters spraakverstaanbaarheid en spraakaanvaardbaarheid. Uit onderzoek blijkt het instrument valide en betrouwbaar te zijn voor onderzoeksdoeleinden bij Vlaamse individuen met een (cheilognato)palatoschisis (Bruneel et al., 2020). Aan de basis van deze masterproef ligt het gebruik van dit recent ontwikkelde beoordelingsinstrument. Deze masterproef wil het effect van training na gaan op de betrouwbaarheid van de perceptuele beoordeling van spraak bij onervaren luisteraars, namelijk eerste masterstudenten logopedie gemeten met het CAPS-A-NL.
In de literatuur bestaat onenigheid over de invloed van ervaring op de betrouwbaarheid van de perceptuele beoordeling. De meeste studies omtrent de perceptuele beoordeling van spraak bij individuen met een (cheilognato)palatoschisis maakten gebruik van ervaren beoordelaars (Whitehill, 2002; Lohmander & Olsson, 2004; Chapman et al., 2016; Ahl & Harding-Bell, 2018). In de literatuur zijn echter ook studies te vinden waarbij de beoordelaars onervaren zijn (Starr, Moller, Dawson, Graham, & Skaar, 1984; Bagnall & David, 1988; Witt, Berry, Marsh, Grames, & Pilgram, 1996; Santelmann, Sussman, & Chapman, 1999; Tönz et al., 2002; Lewis, Watterson, & Houghton, 2003; Brunnegård et al., 2009; Butts, Truong, Forde, Stefanov, & Marrinan, 2016). Deze studies hadden tot doel de beoordeling van onervaren luisteraars te vergelijken met deze van ervaren luisteraars om zo het effect op de betrouwbaarheid van de beoordeling door beide groepen luisteraars te evalueren (Bradford, Brooks, & Shelton, 1964; Starr et al.,1984; Bagnall & David, 1988; Witt et al., 1996; Santelmann et al., 1999; Tönz et al., 2002; Lewis et al., 2003; Laczi, Sussman, Stathopoulos, & Huber, 2005; Brunnegård et al., 2009). Bij deze vergelijking werden wisselende resultaten gevonden, die volgens Chapman et al. (2016) het gevolg zijn van een verschil in definiëring van ervaren en onervaren doorheen de verschillende studies. Veelal werden logopedisten gerekruteerd als ervaren beoordelaars (Starr et al., 1984; Witt et al., 1996; Keuning, Wieneke, & Dejonckere, 1999; Lewis et al., 2003; Laczi et al., 2005; Brunnegård et al., 2009; Chapman et al., 2016). Deze logopedisten konden al dan niet vertrouwd en expert zijn in het beoordelen van de spraak bij een (cheilognato)palatoschisis. Daarnaast werden ook leden van het schisisteam, zoals bijvoorbeeld een plastische chirurg, als ervaren beoordelaars beschouwd (Lewis et al., 2003). Studenten logopedie werden eveneens opgenomen als beoordelaars, afhankelijk van studie tot studie werden deze studenten als ervaren of onervaren bestempeld (Chapman et al., 2016). De studies waarbij gebruik werd gemaakt van zowel ervaren, als onervaren luisteraars voor het beoordelen van de spraak bij een (cheilognato)palatoschisis, gebeurden veelal aan de hand van verschillende beoordelingsmethodes voor de verschillende groepen luisteraars (Sell, 2005; Brunnegård et al., 2009). In onderzoeken werd gebruik gemaakt van beoordelingen volgens ordinale schalen (Ramig, 1982; Bagnall & David, 1988), dichotome en equal appearing interval schalen (Witt et al., 1996). Starr et al. (1984) en Lewis et al. (2003) kozen echter binnen hun studie voor het gebruik van eenzelfde beoordelingsmethode door zowel de onervaren als ervaren luisteraars. Sell (2005) en
Brunnegård et al. (2009) benadrukten het belang om eenzelfde beoordelingsmethode te hanteren voor elke groep luisteraars zodat een vergelijking van de beoordelingsresultaten mogelijk is.
Verscheidene auteurs waren daarnaast van mening dat de perceptuele beoordeling voornamelijk beïnvloed werd door de interne standaard van de beoordelaar (Keuning et al., 1999; Brunnegård et al., 2009; Lee, Whitehill, & Ciocca, 2009). Interne standaard slaat op de interne, persoonlijke standaard die de beoordelaar heeft ontwikkeld door de ervaring die de beoordelaar heeft met de spraak van individuen met een (cheilognato)palatoschisis en op basis waarvan de spraak uiteindelijk zal worden beoordeeld (Gerratt, Kreiman, Antonanzas-Barroso, & Berke, 1993). De interne standaard verschilt dan ook volgens Gerratt en collega’s (1993) van luisteraar tot luisteraar en kan beïnvloed worden door zowel externe factoren als interne factoren. Een voorbeeld van een externe factor is de context waarin de beoordeling zal gebeuren (Kreiman, Gerratt, & Ito, 2007). Interne factoren zijn (specifieke) kenmerken van de beoordelaar zoals ervaring en achtergrond (Brunnegård et al., 2009; Chapman et al., 2016). Bijgevolg is het belangrijk op te merken dat de interne standaard onderhevig is aan verandering en dit onstabiele karakter zorgt ervoor dat training en hertraining een onmisbare component zijn bij de perceptuele beoordeling (Keuning et al., 1999; Gooch, Hardin-Jones, Chapman, Trost-Cardamone, & Sussman, 2001; Lee et al., 2009; Sell et al., 2009; Chapman et al., 2016).
In de literatuur pleitten daarom verschillende auteurs voor het opmaken van een gestructureerde training in het perceptueel beoordelen voor zowel onervaren als ervaren beoordelaars. Deze training zou tot doel hebben de betrouwbaarheid van de perceptuele beoordeling te verhogen (Gooch et al., 2001; Brunnegård et al., 2009; Sell et al., 2009, Chapman et al., 2016). Binnen de training adviseerde Sell (2005) om gebruik te maken van externe referentiespraakstalen. Dit beoogt de interne standaard tussen de verschillende beoordelaars bij het perceptueel beoordelen van spraak bij individuen met een (cheilognato)palatoschisis op elkaar af te stemmen (Keuning et al.,1999; Gooch et al., 2001; Sell, 2005). Ondanks vele aanbevelingen, werden echter weinig studies opgezet om dit te staven (Chapman et al., 2016).
Een eerste studie, van Lee et al. (2009) onderzocht het effect van training en feedback op de beoordeling van hypernasaliteit bij onervaren luisteraars, namelijk 36 studenten logopedie. Alle studenten volgden bij aanvang van het onderzoek een presentatie van 30 minuten omtrent het topic “hypernasaliteit” met aansluitend voorbeeldfragmenten van resonantie-, articulatie- en stemstoornissen. Daarna werden de luisteraars in drie verschillende groepen verdeeld, één groep kreeg training en bijhorende feedback, de andere groep enkel training en de laatste groep kreeg noch training, noch feedback. De training bestond uit vier delen. Het eerste deel omvatte het beoordelen van de aan- of afwezigheid van hypernasaliteit bij acht spraakstalen. Deze procedure werd vervolgens herhaald voor de spraakparameters nasale emissie, stemstoornis en schisisgerelateerde articulatiefouten. In het tweede deel van de training werd gevraagd om de spraakstoornis te identificeren bij het beluisteren van tien spraakstalen. In het derde deel van de training werden telkens twee spraakstalen beluisterd en was de opdracht om het meest hypernasale spraakstaal van de twee aan te duiden. Als laatste werden tien spraakstalen beoordeeld volgens de direct magnitude estimation schaal. Er werd op vlak van interbeoordelaarsbetrouwbaarheid een significant verschil gevonden tussen de twee getrainde groepen
en de niet-getrainde groep bij het scoren van de spraakparameter hypernasaliteit. De twee getrainde groepen durfden namelijk vaker de uiterste punten van de beoordelingsschalen opzoeken. De intrabeoordelaarsbetrouwbaarheid bleek voor alle drie de groepen vergelijkbaar. Een mogelijke verklaring voor deze vergelijkbare resultaten kon volgens Lee en collega’s (2009) worden toegeschreven aan de kleine steekproefomvang en het feit dat de trainingsduur mogelijks niet voldoende was voor alle luisteraars. Daarnaast ontbrak in deze studie een meting voorafgaand aan de training (Butts et al., 2016).
Een andere studie, van Sell et al. (2009) had specifiek tot doel het ontwerpen, uitvoeren en evalueren van een trainingsprogramma voor logopedisten over het systematisch en betrouwbaar gebruik van het CAPS-A beoordelingsinstrument. Zesendertig logopedisten, ervaren in het beoordelen van de spraak bij individuen met een (cheilognato)palatoschisis, namen deel aan een vier dagen durend programma. Het ontstaansproces en de functie van het CAPS-A beoordelingsinstrument, het luister- en beoordelingsprotocol, definiëring van de verschillende spraakparameters en het beluisteren van spraakstalen waren de inhoud van de eerste twee dagen. Het beluisteren van spraakstalen werd opgesplitst in vooreerst tien casussen als lesmateriaal en vervolgens vier casussen voor het inoefenen met behulp van consensusbeoordelingen. De derde dag werd de toepassing van het protocol herhaald aan de hand van een consensusbeoordeling bij een nieuwe casus, daarna werd overgegaan tot het individueel beoordelen van tien nieuwe casussen gebruik makend van het CAPS-A beoordelingsinstrument. Testmoment vier bevatte dezelfde taak, met name eerst de consensusbeoordeling van een casus en vervolgens het individueel beoordelen van diezelfde tien casussen, maar gebeurde één maand later. Op vlak van interbeoordelaarsbetrouwbaarheid werd een goede overeenkomst vastgesteld tussen de beoordelingen van de verschillende logopedisten op acht van de dertien spraakparameters. Wanneer de intrabeoordelaarsbetrouwbaarheid werd bekeken, bleek ook hier over het algemeen een goede overeenkomst te zijn tussen de twee beoordelingen. Daarnaast werd uit bovenstaande resultaten geconcludeerd dat het gebruik van gestandaardiseerde procedures, zoals een voorop vastgesteld luisterprotocol, de betrouwbaarheid van het beoordelingsinstrument tevens kan verhogen.
Chapman et al. (2016) gebruikten eveneens het CAPS-A beoordelingsinstrument en includeerden in deze studie een extra meetmoment voorafgaand aan de training. De training werd gebaseerd op de voorgaande studie van Sell et al. (2009) en werd door drie auteurs (A.H., D.S. en T.S.) van het CAPS- A gegeven. Negen logopedisten, ervaren in het beoordelen van spraak bij individuen met een (cheilognato)palatoschisis namen deel aan dit onderzoek. De studie zag er als volgt uit: vooreerst werden spraakstalen beluisterd en beoordeeld voorafgaand aan de training, onmiddellijk daarna werd de training geven, gevolgd door een tweede beoordelingsmoment. Een laatste beoordelingsmoment vond ongeveer één maand later plaats. Dezelfde tien spraakstalen werden doorheen de drie beoordelingsmomenten gebruikt. De driedaagse training werd gegeven om het gebruik van het CAPS-A instrument de luisteraars eigen te maken. Elke categorie en subcategorie met bijhorende parameters van het beoordelingsinstrument werden in detail beschreven en gedefinieerd. Vervolgens werden deze parameters geïllustreerd aan de hand van video-opnames. De training includeerde tevens een
bespreking van de principes van tien audio- en video-opnames, richtlijnen voor het luisteren en herbeluisteren van de spraakstalen en het gestructureerde luister- en beoordelingsprotocol van het CAPS-A. Het resultaat uit deze studie stemde overeen met de bevindingen van Lee en collega’s (2009), met name de intra- en interbeoordelaarsbetrouwbaarheid kan verbeteren door een trainingsprogramma te volgen in het perceptueel beoordelen van spraak bij individuen met een (cheilognato)palatoschisis. Daarenboven bleek uit het onderzoek van Chapman et al. (2016) het effect van training ten minste één maand stand te houden.
Gezien het CAPS-A-NL beoordelingsinstrument (Bruneel et al., 2020) een recente ontwikkeling betreft, is het effect van training op de betrouwbaarheid van de perceptuele beoordeling bij onervaren luisteraars met dit instrument nog niet voorhanden. De doelstelling van deze masterproef is nagaan wat het effect is van training op de betrouwbaarheid van de perceptuele beoordeling van spraak bij onervaren luisteraars gebruik makend van het CAPS-A-NL beoordelingsinstrument. Onervaren luisteraars zullen getraind worden in het beoordelen van spraak bij Vlaamse individuen met een (cheilognato)palatoschisis. De training zal inhoudelijk bestaan uit een bespreking van de verschillende beoordelingsparameters, het luisterprotocol en de scoringsrichtlijnen van het CAPS-A-NL. Vervolgens zullen deze aspecten worden toegepast door middel van het beluisteren en beoordelen van oefenspraakstalen. Het luisterexperiment zal drie keer plaatsvinden, namelijk voor de training, onmiddellijk na de training en één maand na de training, opdat de inter- en intrabeoordelaarsbetrouwbaarheid van de drie beoordelingsmomenten en de evolutie van de betrouwbaarheid in kaart kan worden gebracht.
Op basis van de bestaande literatuur kan als hypothese worden gesteld dat de training de betrouwbaarheid van de perceptuele beoordeling ten goede zal komen. Bovendien kan verwacht worden dat het positieve effect van de training op de betrouwbaarheid van de beoordeling naar waarschijnlijkheid stand zal houden gedurende minstens één maand (Chapman et al., 2016).
2. Methode
Dit onderzoek werd op 22 februari 2019 goedgekeurd door het Ethisch Comité van het U.Z. Gent (B670201939070). Alle participanten ondertekenden voor akkoord een informatie- en toestemmingsformulier.
2.1 Participanten
De perceptuele beoordeling gebeurde door een groep onervaren luisteraars, namelijk 35 vrouwelijke eerste masterstudenten Logopedische Wetenschappen aan de Universiteit van Gent. De studenten namen allen deel aan de Masterclass stem, resonantie en slikken. Tijdens deze Masterclass werden de studenten op de hoogte gebracht van dit onderzoek en hun deelname viel binnen het kader van de lessen. De gemiddelde leeftijd van de groep onervaren luisteraars bedroeg 21.8 jaar (standaarddeviatie (SD) 0.40; range [21.2-22.9]).
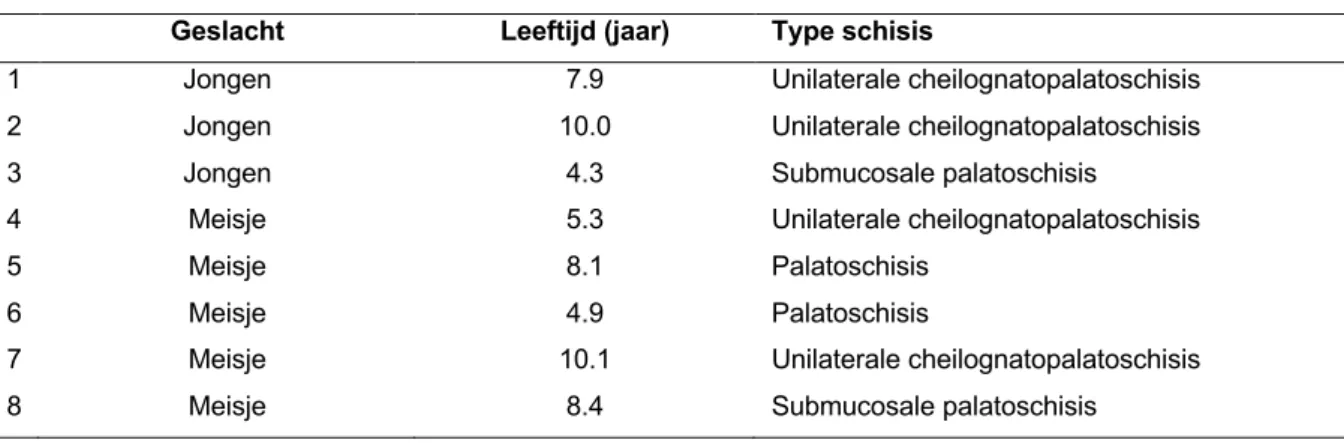
De spraakstalen die werden beoordeeld door de onervaren studenten waren reeds samengesteld binnen het kader van het opstellen van het Nederlandstalige beoordelingsinstrument, CAPS-A-NL (Bruneel et al., 2020). De spraakstalen werden afgenomen bij acht kinderen met een (cheilognato)palatoschisis, meer specifiek drie jongens en vijf meisjes. De gemiddelde leeftijd van deze kinderen bedroeg 7.4 jaar (SD 2.28; range [4.3-10.1]). Alle kinderen werden opgevoed met het Nederlands als moedertaal. Tabel 1 geeft een overzicht van het geslacht, leeftijd en type schisis van de kinderen met een (cheilognato)palatoschisis. De rekrutering van de kinderen met een (cheilognato)palatoschisis gebeurde vanuit het schisisteam van het U.Z. Gent. De ouders van deze proefpersonen werden gecontacteerd via mail om toestemming te vragen voor de kinderen hun deelname aan dit onderzoek.
Tabel 1: Overzicht van de kenmerken van de kinderen met een (cheilognato)palatoschisis Geslacht Leeftijd (jaar) Type schisis
1 Jongen 7.9 Unilaterale cheilognatopalatoschisis 2 Jongen 10.0 Unilaterale cheilognatopalatoschisis
3 Jongen 4.3 Submucosale palatoschisis
4 Meisje 5.3 Unilaterale cheilognatopalatoschisis
5 Meisje 8.1 Palatoschisis
6 Meisje 4.9 Palatoschisis
7 Meisje 10.1 Unilaterale cheilognatopalatoschisis
2.2 Werkwijze
2.2.1 Inhoud van de spraakstalen
De spraakstalen werden samengesteld naar analogie met het CAPS-A protocol (Sell et al., 2009), meer specifiek bestond een spraakstaal uit spontane spraak, automatische reeksen en uitingen op zinsniveau.
Spontane spraak
Voor de opname van de spontane spraak werd door de onderzoeker aan elk kind dezelfde vragen gesteld omtrent hobby’s en interesses. De uitingen van de onderzoeker werden uit het fragment geknipt om de invloed van context op het spraakstaal te elimineren. Dit gebeurde met behulp van het softwareprogramma Praat, versie 6.1.05 (Boersma & Weenink). De lengte van het fragment werd gecontroleerd met een totaal van 60 syllaben per fragment.
Automatische reeksen
De kinderen werden gevraagd om automatische reeksen te produceren, meer specifiek tellen van 1 tot 10 voor kinderen jonger dan zeven, kinderen ouder dan zeven telden van 1 tot 20 en van 60 tot 70. Tevens werden ook alle kinderen gevraagd de dagen van de week op te noemen.
Uitingen op zinsniveau
Bruneel et al. (2020) ontwikkelden een set van twintig zinnen die tot doel hadden een representatieve weergave te zijn voor het in kaart brengen van de consonantproductie, nasale luchtstroom en resonantie bij Vlaamse individuen met een (cheilognato)palatoschisis. Bijzondere aandacht bij het ontwerp van deze zinnen ging naar drukconsonanten en gesloten vocalen gezien deze beschreven werden in literatuur als zijnde stoornis gevoelig bij individuen met een (cheilognato)palatoschisis (Henningsson et al., 2008; Bruneel et al., 2020). Daarnaast werden de zinnen met de drukconsonanten en de gesloten versus open vocalen fonetisch gebalanceerd volgens de beschreven richtlijnen van Henningsson et al. (2008). De twintig zinnen werden voorgezegd door de onderzoeker en vervolgens herhaald door de kinderen met een (cheilognato)palatoschisis.
De spraakstalen werden opgenomen tijdens de consultaties in het U.Z. Gent en bij thuisbezoeken door dr. Bruneel en dr. Bettens. Alle spraakstalen werden audiovisueel geregistreerd met behulp van een videocamera (Sony Handcam HDR-CQ280E). Tevens gebeurde een aparte auditieve registratie aan de hand van een unidirectionele microfoon (Samson C01U). Tijdens de opnames werd het kind steeds van hoofd tot schouders in beeld gebracht. Gedurende het hele luisterexperiment werden dezelfde spraakstalen gebruikt die steeds gerandomiseerd en geanonimiseerd werden aangeboden aan de onervaren luisteraars.
2.2.2 Spraakparameters en luistervolgorde van het CAPS-A-NL
De evaluatie van de spraakstalen door de onervaren luisteraars gebeurde aan de hand van het CAPS-A-NL beoordelingsinstrument (Bruneel et al., 2020). Wegens tijdsgebrek, werden echter niet alle spraakparameters van dit beoordelingsinstrument opgenomen in het onderzoek. Enkel de spraakparameters met een ordinale beoordelingsschaal werden opgenomen, zijnde
spraakverstaanbaarheid, resonantie, nasale luchtstroom, stem en spraakaanvaardbaarheid. Gebaseerd op het werk van Sell et al. (2009) werden de spraakparameters beoordeeld volgens een gestandaardiseerd luisterprotocol.
Spraakverstaanbaarheid was de eerste spraakparameter die overeenkomstig met het luisterprotocol beoordeeld werd. Volgens John et al. (2006) kan spraakverstaanbaarheid gedefinieerd worden als de mate waarin de spraak verstaanbaar is voor een persoon die niet vertrouwd is met de spreker. De beoordeling van deze spraakparameter gebeurde op basis van een fragment spontane spraak. Het fragment werd louter auditief aangeboden en mocht slechts eenmaal beluisterd worden. Vervolgens scoorde de student dit op een vierpuntenschaal.
Daaropvolgend werden resonantie en nasale luchtstroom beoordeeld. De beoordeling van de resonantie werd onderverdeeld in hypernasaliteit en hyponasaliteit. Hypernasaliteit kan omschreven worden als een abnormale verhoging van de nasale resonantie tijdens het produceren van vocalen en stemhebbende consonanten (John et al., 2006; Henningsson et al., 2008). Hyponasaliteit wordt gedefinieerd als elke abnormale afwezigheid van nasale resonantie tijdens de spraakproductie van vocalen en stemhebbende consonanten. Beide spraakparameters werden gescoord op respectievelijk een vijfpunten- en driepuntenschaal.
Nasale luchtstroom beschreven door John en collega’s (2006), als elke abnormale luchtstroom of ongepaste luchtontsnapping door de nasale caviteit die samengaat met de productie van stemhebbende en stemloze orale drukconsonanten, werd onderverdeeld in nasale emissie en nasale turbulentie. Onder nasale emissie wordt elke abnormale hoorbare luchtontsnapping uit de nasale caviteit verstaan die samengaat met de productie van orale drukconsonanten (John et al., 2006). Nasale turbulentie wordt beschreven als elk turbulent geluid dat samengaat met de productie van orale drukconsonanten (John et al., 2006). De scoring van de twee parameters gebeurde apart en beide op basis van een driepuntenschaal. De beoordeling van zowel de resonantie als nasale luchtstroom gebeurde aan de hand van het spraakstaal automatische reeksen en het spraakstaal op zinsniveau. Deze werden eerst enkel auditief aangeboden, nadien werden ze audiovisueel gepresenteerd aan de studenten. Het herbeluisteren van de fragmenten was toegestaan.
Voor het scoren van de stemkwaliteit en aanvaardbaarheid van de spraak moesten de studenten zich baseren op het totale spraakstaal. Het ging hier over de globale impressie inzake de stemkwaliteit en spraakaanvaardbaarheid. De stemkwaliteit werd beoordeeld als kenmerkend of afwijkend wanneer deze de beoordeling van resonantie, en in het bijzonder hypernasaliteit, kan beïnvloeden (Bruneel et al., 2020). Dit werd gescoord op een tweepuntenschaal. De aanvaardbaarheid van de spraak gedefinieerd door Henningsson et al. (2008) als de mate waarin de spraak de aandacht trekt, onafhankelijk van de communicatieve boodschap, werd via een vierpuntenschaal gescoord.
Voor elk van de zeven bovenstaande spraakparameters had de luisteraar steeds de mogelijkheid om het cijfer 8 te omcirkelen indien het beoordelen van de desbetreffende spraakparameter niet mogelijk was en vervolgens te duiden waarom de spaakparameter niet gescoord kon worden. Het aangepaste beoordelingsformulier voor de drie beoordelingsmomenten is terug te vinden in de appendix, bijlage 1.
2.2.3 Perceptuele beoordeling aan de hand van het CAPS-A-NL
In totaal werden de verzamelde spraakstalen driemaal perceptueel beoordeeld door de onervaren luisteraars gebruik makend van het aangepaste CAPS-A-NL beoordelingsinstrument (Bruneel et al., 2020). Meer specifiek vond een beoordeling door de studenten plaats voor de training in het evalueren van de spraak bij individuen met een (cheilognato)palatoschisis, eenmaal onmiddellijk na de training en vervolgens een derde maal één maand na de training. De spraakstalen werden aangeboden via het online platform van de Universiteit Gent, Minerva. Op deze manier was het niet mogelijk om de spraakstalen te downloaden. De audio- en video- opnames werden door de studenten beluisterd op een door de student voorziene computer. Individueel werden de spraakstalen beluisterd door middel van een hoofdtelefoon. Ondanks dat vooraf werd aangegeven dat een hoofdtelefoon de voorkeur genoot, beluisterden verschillende studenten de spraakstalen met behulp van insert oortjes. De drie beoordelingen door de studenten vonden telkens gezamenlijk plaats in een klaslokaal van de Universiteit Gent op de campus van het U.Z. Gent en gebeurden schriftelijk.
De onervaren luisteraars konden zich bij de eerste perceptuele beoordeling baseren op een document dat reeds voor de les ter beschikking werd gesteld op Minerva. In dit document konden de luisteraars ondersteunende informatie vinden, met name de definities van de verschillende beoordelingsparameters. Daarnaast werden de richtlijnen omtrent de luistervolgorde klassikaal meegedeeld. Verdere inhoudelijke duiding werd niet gegeven. Aan deze eerste beoordeling namen 32 studenten deel. Vijf van de 32 studenten (15.6%) beluisterden de spraakstalen door middel van insert oortjes, de andere 27 studenten (84.4%) gebruikten een hoofdtelefoon. De perceptuele beoordeling van één student bij dit beoordelingsmoment werd echter niet opgenomen bij het verwerken van de resultaten, gezien deze student door technische problemen maar de helft van de spraakstalen beoordeelde.
Na deze eerste beoordeling, werden de onervaren luisteraars diezelfde dag getraind in het perceptueel beoordelen van spraak bij individuen met een (cheilognato)palatoschisis. De training werd gegeven door dr. Bruneel en duurde ongeveer twee uur. Binnen deze training werden alle verschillende onderdelen van het CAPS-A-NL besproken aan de hand van een presentatie. Meer specifiek werd ingegaan op de verschillende spraakparameters en bijhorende scoringsrichtlijnen van het beoordelingsinstrument. Dit werd geïllustreerd met een totaal van twintig audiospraakstalen in een vrij veld met behulp van luidsprekers (Creative Technology Ltd., Creative Inspire 265). Als laatste deel van de training werden twee voorbeeldcasussen gepresenteerd aan de onervaren luisteraars om het gebruik van het CAPS-A-NL beoordelingsinstrument verder in te oefenen. De oefenspraakstalen werden klassikaal beoordeeld en verschilden van de spraakstalen die gebruikt werden tijdens de drie beoordelingsmomenten.
Onmiddellijk na deze training vond het luisterexperiment nogmaals plaats. Opnieuw namen dezelfde 32 studenten deel. Dezelfde spraakstalen die werden gebruikt bij de eerste beoordeling voor de training werden opnieuw, maar in een andere volgorde individueel beluisterd en beoordeeld door de studenten aan de hand van het luisterprotocol en het CAPS-A-NL instrument.
Het luisterexperiment werd vervolgens na één maand herhaald, opdat de intra- en interbeoordelaarsbetrouwbaarheid van de drie beoordelingsmomenten en de evolutie van de betrouwbaarheid in kaart kon worden gebracht. Vierendertig studenten namen deel aan deze laatste beoordeling, waarvan negen van de 34 studenten (26.5%) de spraakstalen met behulp van insert oortjes beluisterden. De andere 25 studenten (73.5%) maakten gebruik van een hoofdtelefoon. Individueel beluisterden en beoordeelden alle studenten opnieuw dezelfde spraakstalen, maar in een andere volgorde op hun eigen computer. Bij deze laatste beoordeling konden de studenten wederom gebruik maken van het document met de ondersteunde informatie met betrekking tot de definities van de spraakparameters en de scoringsrichtlijnen.
Tot slot werd aan de studenten gevraagd de toepasbaarheid van en suggesties voor de training met betrekking tot het invullen van het Nederlandstalige CAPS-A beoordelingsinstrument te evalueren. Deze evaluatie gebeurde eveneens driemaal, met name na elke beoordeling, en schriftelijk. De studenten beantwoordden de vragen aan de hand van een vijfpuntenschaal. Daarnaast werd een vrij veld voorzien voor bijkomende opmerkingen. De vragenlijsten voor de drie beoordelingsmomenten zijn terug te vinden in de appendix, bijlage 2.
2.2.4 Statistische analyse
De statistische verwerking werd uitgevoerd met behulp van het softwareprogramma SPSS Statistics (versie 25). De inter- en intrabeoordelaarsbetrouwbaarheid werden nagegaan voor de drie verschillende beoordelingsmomenten. Voor het bekomen van de resultaten van de interbeoordelaarsbetrouwbaarheid werd gebruik gemaakt van de two-way mixed single measures intraclass correlatiecoëfficiënt, type absolute agreement en geïnterpreteerd volgens de classificatie van Landis en Koch (1977), aangepast volgens Altman (1990). Voor de bepaling van de intrabeoordelaarsbetrouwbaarheid werden bij elk beoordelingsmoment at random twee spraakstalen gedupliceerd. Per luisteraar werd het percentage van absolute overeenkomst volgens Hallgren (2012) berekend om vervolgens met deze bekomen waarden verder analyses uit te voeren, namelijk de berekening van het gemiddelde en het mediane percentage van absolute overeenkomst gebaseerd op het totale percentage van absolute overeenkomst van alle luisteraars afzonderlijk. Daarnaast werd via de Wilcoxon matched-pairs signed-ranks test per spraakparameter nagegaan of de intrabeoordelaarsbetrouwbaarheid significant verschilde voor de drie beoordelingsmomenten. Om type I fouten te corrigeren werd een Bonferroni-correctie uitgevoerd waardoor een significantieniveau van α ≤ 0.017 (0.05/3) werd gehanteerd. Voor de verwerking van de resultaten op basis van de vragenlijsten, beoordeeld door de studenten aan de hand van een ordinale vijfpuntenschaal, over de toepasbaarheid van en suggesties voor de training, werden de vragen inhoudelijk geanalyseerd en werd de frequentieverdeling voor elke vraag afzonderlijk nagegaan. Daarnaast werd de Wilcoxon matched-pairs signed-ranks test eveneens gebruikt om het verschil in moeilijkheidsgraad bij de perceptuele beoordeling per spraakparameter en de tijdsvoorziening voor het invullen van het CAPS-A-NL beoordelingsinstrument tussen de drie beoordelingsmomenten in kaart te brengen, waarbij eveneens een Bonferroni-correctie werd uitgevoerd en het significantieniveau werd vastgesteld op α ≤ 0.017 (0.05/3).
3. Resultaten
3.1 Interbeoordelaarsbetrouwbaarheid
Pre-training
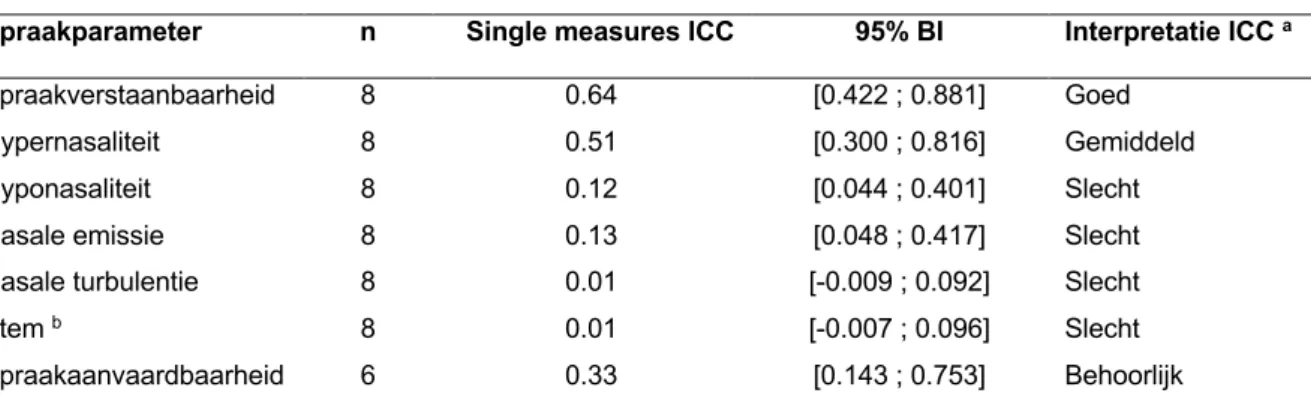
Voor de training werd een goede interbeoordelaarsbetrouwbaarheid, gebaseerd op de ICC-waarden, gevonden bij slechts één van de zeven spraakparameters, namelijk bij spraakverstaanbaarheid (tabel 2). Een behoorlijke tot gemiddelde interbeoordelaarsbetrouwbaarheid werd voor de spraakparameters spraakaanvaardbaarheid en hypernasaliteit gezien. De interbeoordelaarsbetrouwbaarheid voor hyponasaliteit, nasale emissie, nasale turbulentie en stem was slecht.
Tabel 2: Resultaten interbeoordelaarsbetrouwbaarheid van de 31 beoordelaars: voor de training Spraakparameter n Single measures ICC 95% BI Interpretatie ICC a
Spraakverstaanbaarheid 8 0.64 [0.422 ; 0.881] Goed Hypernasaliteit 8 0.51 [0.300 ; 0.816] Gemiddeld Hyponasaliteit 8 0.12 [0.044 ; 0.401] Slecht Nasale emissie 8 0.13 [0.048 ; 0.417] Slecht Nasale turbulentie 8 0.01 [-0.009 ; 0.092] Slecht
Stem b 8 0.01 [-0.007 ; 0.096] Slecht
Spraakaanvaardbaarheid 6 0.33 [0.143 ; 0.753] Behoorlijk Noot. n, aantal spraakstalen; ICC, intraclass correlatiecoëfficiënt; BI, betrouwbaarheidsinterval.
a Gebaseerd op Altman (1990): ICC < 0.20: slecht, 0.21-0.40: behoorlijk, 0.41-0.60: gemiddeld, 0.61-0.80: goed,
0.81-1.00: zeer goed.
b Minstens één spraakstaal zonder variantie.
Post-training
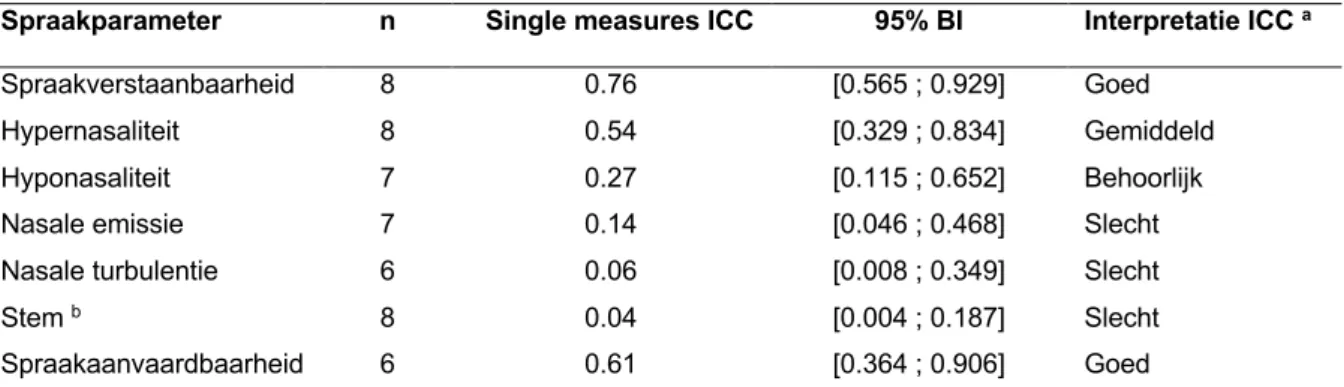
Onmiddellijk na de training werd een stijging gezien van de interbeoordelaarsbetrouwbaarheid, gebaseerd op de ICC-waarden, voor alle zeven spraakparameters (tabel 3). Voor de spraakparameters hyponasaliteit en spraakaanvaardbaarheid resulteerde de verhoogde ICC-waarden tot een verandering van de interpretatie, respectievelijke evolutie van een slechte naar een behoorlijke en van een behoorlijke naar een goede interbeoordelaarsbetrouwbaarheid.
Follow-up
Wanneer de interbeoordelaarsbetrouwbaarheid onmiddellijk na de training vergeleken werd met de bekomen ICC-waarden één maand na de training, kan een daling beschreven worden bij vijf van de zeven spraakparameters (tabel 4). Voor de spraakparameters hyponasaliteit en spraakaanvaardbaarheid resulteerde de daling tevens in een verandering van de ICC-interpretatie, respectievelijk van een behoorlijke naar een slechte en van een goede naar een gemiddelde interbeoordelaarsbetrouwbaarheid. Bij de spraakparameters nasale turbulentie en stem werd een stijging van de interbeoordelaarsbetrouwbaarheid, gebaseerd op ICC-waarden opgemerkt, maar deze stijging resulteerde niet in een verandering van de ICC-interpretatie. De interbeoordelaarsbetrouwbaarheid voor deze spraakparameters bleef slecht.
Een vergelijking van de interbeoordelaarsbetrouwbaarheid voor de training en één maand na de training wees uit dat het merendeel van de spraakparameters steeg (6/7, tabel 4). Hyponasaliteit was de enige spraakparameter waarvan de interbeoordelaarsbetrouwbaarheid daalde. Echter zowel de stijging als de daling voor de verschillende spraakparameters resulteerde niet in een verandering van de ICC-interpretatie.
Tabel 3: Resultaten interbeoordelaarsbetrouwbaarheid van de 32 beoordelaars: onmiddellijk na de training
Spraakparameter n Single measures ICC 95% BI Interpretatie ICC a
Spraakverstaanbaarheid 8 0.76 [0.565 ; 0.929] Goed Hypernasaliteit 8 0.54 [0.329 ; 0.834] Gemiddeld Hyponasaliteit 7 0.27 [0.115 ; 0.652] Behoorlijk Nasale emissie 7 0.14 [0.046 ; 0.468] Slecht Nasale turbulentie 6 0.06 [0.008 ; 0.349] Slecht
Stem b 8 0.04 [0.004 ; 0.187] Slecht
Spraakaanvaardbaarheid 6 0.61 [0.364 ; 0.906] Goed Noot. n, aantal spraakstalen; ICC, intraclass correlatiecoëfficiënt; BI, betrouwbaarheidsinterval.
a Gebaseerd op Altman (1990): ICC < 0.20: slecht, 0.21-0.40: behoorlijk, 0.41-0.60: gemiddeld, 0.61-0.80: goed,
0.81-1.00: zeer goed.
b Minstens één spraakstaal zonder variantie.
Tabel 4: Resultaten interbeoordelaarsbetrouwbaarheid van de 34 beoordelaars: één maand na de training
Spraakparameter n Single measures ICC 95% BI Interpretatie ICC a
Spraakverstaanbaarheid 7 0.71 [0.497 ; 0.924] Goed Hypernasaliteit 8 0.41 [0.218 ; 0.746] Gemiddeld
Hyponasaliteit 8 0.14 [0.055 ; 0.434 Slecht
Nasale emissie 7 0.13 [0.045 ; 0.448] Slecht Nasale turbulentie 8 0.11 [0.035 ; 0.359] Slecht
Stem b 8 0.13 [0.048 ; 0.420] Slecht
Spraakaanvaardbaarheid 8 0.55 [0.334 ; 0.843] Gemiddeld Noot. n, aantal spraakstalen; ICC, intraclass correlatiecoëfficiënt; BI, betrouwbaarheidsinterval.
a Gebaseerd op Altman (1990): ICC < 0.20: slecht, 0.21-0.40: behoorlijk, 0.41-0.60: gemiddeld, 0.61-0.80: goed,
0.81-1.00: zeer goed.
3.2 Intrabeoordelaarsbetrouwbaarheid
Tabel 5 geeft de evolutie van de intrabeoordelaarsbetrouwbaarheid weer aan de hand van het gemiddelde en mediane percentage van absolute overeenkomst dat werd berekend voor de drie beoordelingsmomenten, pre-training, onmiddellijk post-training en één maand na de training en dit voor elke spraakparameter afzonderlijk. Daarnaast wordt de evolutie van het gemiddelde percentage van absolute overeenkomst in figuur 1 nogmaals aan de hand van een lijndiagram uiteengezet.
De resultaten voor wat betreft de intrabeoordelaarsbetrouwbaarheid varieerden voor de training van 55.00% tot 95.00%, onmiddellijk na de training breidde de range uit van 23.44% tot 90.63% en één maand na de training varieerde de intrabeoordelaarsbetrouwbaarheid nog van 61.76% tot 95.59%.
Pre-training en post-training
De intrabeoordelaarsbetrouwbaarheid daalde onmiddellijk na de training voor vijf van de zeven spraakparameters, betreffende hypernasaliteit, nasale emissie, nasale turbulentie, stem en spraakaanvaardbaarheid. Uit de vergelijking van het gemiddelde percentage van absolute overeenkomst vooraf de training en deze onmiddellijk na de training bleek de daling enkel significant te zijn voor de spraakparameters hypernasaliteit (Z = -2.870, p = 0.004) en nasale turbulentie (Z = -3.444, p = 0.001). De stijging van de twee spraakparameters, spraakverstaanbaarheid en hyponasaliteit was niet significant (tabel 6).
Post-training en follow-up
Wanneer de intrabeoordelaarsbetrouwbaarheid voor de verschillende spraakparameters onmiddellijk na de training met deze één maand na de training vergeleken werd, bleek de intrabeoordelaarsbetrouwbaarheid gestegen bij op één na alle spraakparameters. Deze stijging was voor drie spraakparameters significant, namelijk voor hypernasaliteit (Z = -2.805, p = 0.005), nasale turbulentie (Z = -3.785, p < 0.001) en spraakaanvaardbaarheid (Z = -2.424, p = 0.015). De daling van de intrabeoordelaarsbetrouwbaarheid bij de spraakparameter spraakverstaanbaarheid bleek niet significant te zijn (tabel 6).
Pre-training en follow-up
Een vergelijking van de intrabeoordelaarsbetrouwbaarheid van het eerste beoordelingsmoment, voor de training, en het laatste beoordelingsmoment, één maand na de training, wees uit dat de intrabeoordelaarsbetrouwbaarheid voor alle zeven spraakparamters hoger lag één maand na de training, maar dit verschil bleek voor geen enkele spraakparameter significant (tabel 6).
Tabel 5: Resultaten intrabeoordelaarsbetrouwbaarheid voor de drie beoordelingsmomenten per spraakparameter Spraakparameter n Gemiddelde % absolute overeenkomst Standaard- deviatie Mediane % absolute overeenkomst Interkwartiel- range Pre-training Spraakverstaanbaarheid 30 56.67 36.52 50 50 – 100 Hypernasaliteit 30 55.00 42.24 50 0 – 100 Hyponasaliteit 30 83.33 30.32 100 50 – 100 Nasale emissie 30 76.67 28.57 100 50 – 100 Nasale turbulentie 30 80.00 28.16 100 50 – 100 Stem 30 95.00 15.26 100 100 – 100 Spraakaanvaardbaarheid 29 67.24 33.48 50 50 – 100 Post-training Spraakverstaanbaarheid 32 76.56 35.89 100 50 – 100 Hypernasaliteit 32 23.44 38.07 0 0 – 50 Hyponasaliteit 32 87.50 31.11 100 100 – 100 Nasale emissie 31 61.29 38.10 50 50 – 100 Nasale turbulentie 32 43.76 43.53 50 0 – 100 Stem 32 90.63 26.75 100 100 – 100 Spraakaanvaardbaarheid 32 48.44 43.04 50 0 – 100 Follow-up Spraakverstaanbaarheid 34 70.59 35.07 100 50 – 100 Hypernasaliteit 34 61.76 37.05 50 50 – 100 Hyponasaliteit 34 91.18 22.93 100 100 – 100 Nasale emissie 34 80.88 32.60 100 50 – 100 Nasale turbulentie 34 89.71 23.93 100 100 – 100 Stem 34 95.59 14.40 100 100 – 100 Spraakaanvaardbaarheid 33 77.27 33.29 100 50 – 100 Noot. n, aantal studenten; pre-training, voor de training; post-training, onmiddellijk na de training; follow-up, één maand na de training.
Tabel 6: Resultaten van de Wilcoxon matched-pairs signed-ranks test voor de vergelijking van de intrabeoordelaarsbetrouwbaarheid, gebaseerd op het mediane percentage van absolute overeenkomst, tussen de drie beoordelingsmomenten per spraakparameter
Pre – post Post – fu Pre – fu
Spraakparameter Z p Z p Z p Spraakverstaanbaarheid -1.757 0.079 -0.349 0.727 -1.577 0.115 Hypernasaliteit -2.870 0.004 a -2.805 0.005 a -0.868 0.385 Hyponasaliteit -0.229 0.819 -0.649 0.516 -2.111 0.035 Nasale emissie -1.822 0.068 -2.057 0.040 0.000 1.000 Nasale turbulentie -3.444 0.001 a -3.785 < 0.001 a -2.121 0.034 Stem -0.333 0.739 -0.879 0.380 0.000 1.000 Spraakaanvaardbaarheid -1.826 0.068 -2.424 0.015 a -1.856 0.063
Noot. pre, pre-training (voor de training); post, post-training (onmiddellijk na de training); fu, follow-up (één maand na de training).
Figuur 1: Resultaten evolutie van de intrabeoordelaarsbetrouwbaarheid, gebaseerd op het gemiddelde percentage van absolute overeenkomst, voor de drie beoordelingsmomenten per spraakparameter
3.3 Vragenlijsten met feedback en suggesties
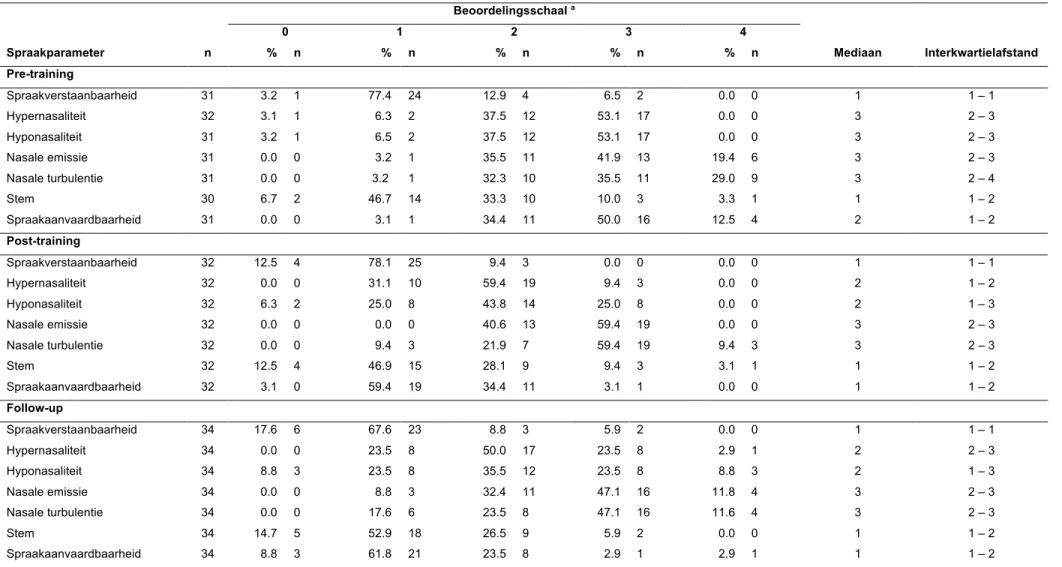
In tabel 7 worden de resultaten voor de eerste vraag van de vragenlijst voor de studenten met betrekking tot de ondervonden moeilijkheden bij het beoordelen van de zeven spraakparameters per beoordelingsmoment uiteengezet.
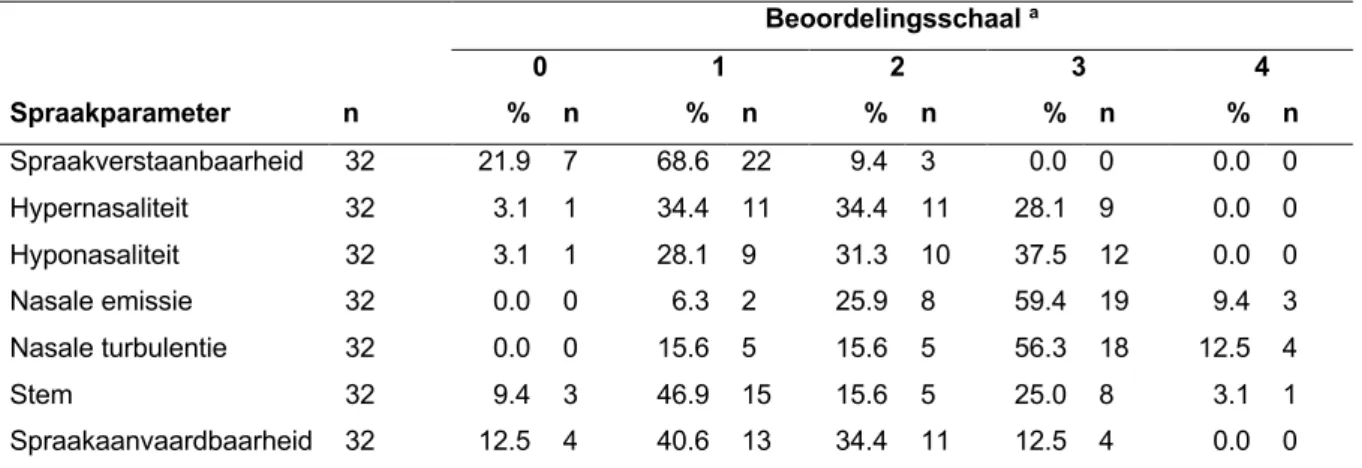
Voor de training kon uit de mediane waarden worden opgemerkt dat de studenten veel moeilijkheden ondervonden bij het beoordelen van de spraakparameters hypernasaliteit, hyponasaliteit, nasale emissie en nasale turbulentie. Voor de beoordeling van spraakverstaanbaarheid en stem daarentegen bleken bijna geen moeilijkheden te bestaan en ten opzichte van de beoordeling voor de spraakparameter spraakaanvaardbaarheid leken de studenten een neutrale houding aan te nemen. Wanneer dit vergeleken werd met de resultaten onmiddellijk na de training, bleken de studenten voor drie van de zeven spraakparameters minder moeilijkheden te ondervinden bij de perceptuele beoordeling, namelijk voor spraakaanvaardbaarheid (Z = -2.269, p = 0.023), hypernasaliteit (Z = -3.750, p < 0.001) en hyponasaliteit (Z = -3.269, p = 0.001). Enkel voor deze twee laatste spraakparameters bleek dit verschil significant. De moeilijkheidsgraad voor de beoordeling van de spraakparameters spraakverstaanbaarheid (Z = -2.309, p = 0.021), nasale emissie (Z = -1.147, p = 0.251), nasale turbulentie (Z = -1.186, p = 0.236) en stem (Z = -0.423, p = 0.672) bleef daarentegen gelijk en bleek niet significant te verschillen.
Eén maand na de training bleef de mediane waarde voor elke spraakparameter dezelfde als deze onmiddellijk na de training. Ook uit de statistische analyse bleek er geen significant verschil aanwezig voor de spraakparameters: spraakverstaanbaarheid (Z < 0.001, p = 1.000), hypernasaliteit (Z = -1.606, p = 0.108), hyponasaliteit (Z = -0.025, p = 0.980), nasale emissie (Z = -0.500, p = 0.617), nasale
turbulentie (Z = -1.129, p = 0.259), stem (Z = -1.133, p = 0.257) en spraakaanvaardbaarheid (Z = -0.842, p = 0.400) bij een vergelijking van de mediane waarde onmiddellijk na de training en één maand later. Wanneer de mediane waarde voor wat betreft de ondervonden moeilijkheden vooraf de training en één maand na de training werden vergeleken, ondervonden de studenten één maand na de training significant minder moeilijkheden bij het perceptueel beoordelen van hypernasaliteit (Z = -2.600, p = 0.009), hyponasaliteit (Z = -3.257, p = 0.001) en spraakaanvaardbaarheid (Z = -3.273, p = 0.001). Voor de andere vier spraakparameters: spraakverstaanbaarheid (Z = -1.538, p = 0.124), nasale emissie, (Z = -0.600, p = 0.549), nasale turbulentie (Z = -1.634, p = 0.102) en stem (Z = -1.977, p = 0.048) bleven de mediane waarden gelijk en kon geen significant verschil worden opgemerkt.
De beoordeling gebeurde zoals eerder beschreven volgens een gestandaardiseerd luisterprotocol. De relevantie van dit luisterprotocol werd tevens bevraagd in de vragenlijst. Uit deze bevraging beek dat 28 van de 32 studenten (87.5%) akkoord gingen met de relevantie van een luisterprotocol bij een perceptuele beoordeling. Drie studenten (9.4%) gaven zelfs aan helemaal akkoord te zijn. Slechts één student (3.1%) hield zich neutraal ten opzichte van deze vraag. De scores 0 en 1, respectievelijk helemaal niet akkoord en niet akkoord werden door niemand aangeduid.
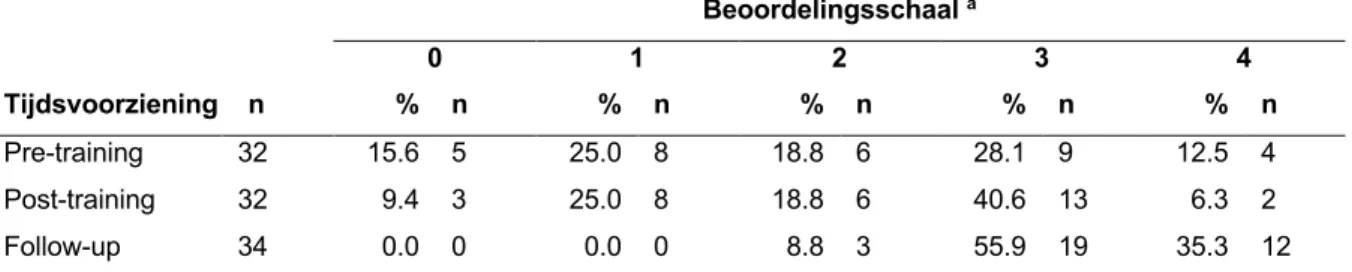
Ook de tijdvoorziening voor het beoordelen van de tien spraakstalen aan de hand van het CAPS-A-NL werd na elk beoordelingsmoment bevraagd bij de studenten. In tabel 8 wordt de frequentieverdeling van deze resultaten weergeven. De Wilcoxon matched-pairs signed-ranks test werd eveneens uitgevoerd om na te gaan of er een significant verschil aanwezig was tussen de drie verschillende beoordelingsmomenten. Zowel voor als onmiddellijk na de training stonden de studenten algemeen neutraal ten opzichte van de voorziene tijd voor het invullen van het CAPS-A-NL. De mediaan bedroeg voor beide beoordelingsmomenten 2 (IQR 1-3) en bleek niet significant te verschillen (Z = -0.493, p = 0.622). Eén maand na de training bedroeg de mediaan 3 (IQR 3-4). De studenten bleken bij deze laatste beoordeling algemeen akkoord te zijn met de voorziene tijd voor het invullen van het CAPS-A-NL. Dit bleek uit de statistische analyse significant te verschillen met de eerste beoordeling, alsook met de tweede beoordeling respectievelijk (Z = -4.083, p < 0.001) en (Z = 3.910, p < 0.001). Desondanks stelde een student zich de vraag of iedereen de aangeboden tijd wel voldoende benutte voor de perceptuele beoordeling en kwam er daarnaast vanuit een andere student expliciet de vraag om meer tijd te voorzien voor de verschillende beoordelingen.
Tabel 7: Resultaten vragenlijst: Bij welk onderdeel van het CAPS-A-NL beoordelingsinstrument ondervond u de meeste moeilijkheden pre-training, post-training en follow-up?
Noot. n, aantal studenten; %, procentueel aantal studenten; pre-training, voor de training; post-training, onmiddellijk na de training; follow-up, één maand na de training.
aBeoordelingsschaal: 0, helemaal geen moeilijkheden; 1, bijna geen moeilijkheden; 2, neutraal; 3, veel moeilijkheden; 4, zeer veel moeilijkheden.
Beoordelingsschaal a
0 1 2 3 4
Spraakparameter n % n % n % n % n % n Mediaan Interkwartielafstand
Pre-training Spraakverstaanbaarheid 31 3.2 1 77.4 24 12.9 4 6.5 2 0.0 0 1 1 – 1 Hypernasaliteit 32 3.1 1 6.3 2 37.5 12 53.1 17 0.0 0 3 2 – 3 Hyponasaliteit 31 3.2 1 6.5 2 37.5 12 53.1 17 0.0 0 3 2 – 3 Nasale emissie 31 0.0 0 3.2 1 35.5 11 41.9 13 19.4 6 3 2 – 3 Nasale turbulentie 31 0.0 0 3.2 1 32.3 10 35.5 11 29.0 9 3 2 – 4 Stem 30 6.7 2 46.7 14 33.3 10 10.0 3 3.3 1 1 1 – 2 Spraakaanvaardbaarheid 31 0.0 0 3.1 1 34.4 11 50.0 16 12.5 4 2 1 – 2 Post-training Spraakverstaanbaarheid 32 12.5 4 78.1 25 9.4 3 0.0 0 0.0 0 1 1 – 1 Hypernasaliteit 32 0.0 0 31.1 10 59.4 19 9.4 3 0.0 0 2 1 – 2 Hyponasaliteit 32 6.3 2 25.0 8 43.8 14 25.0 8 0.0 0 2 1 – 3 Nasale emissie 32 0.0 0 0.0 0 40.6 13 59.4 19 0.0 0 3 2 – 3 Nasale turbulentie 32 0.0 0 9.4 3 21.9 7 59.4 19 9.4 3 3 2 – 3 Stem 32 12.5 4 46.9 15 28.1 9 9.4 3 3.1 1 1 1 – 2 Spraakaanvaardbaarheid 32 3.1 0 59.4 19 34.4 11 3.1 1 0.0 0 1 1 – 2 Follow-up Spraakverstaanbaarheid 34 17.6 6 67.6 23 8.8 3 5.9 2 0.0 0 1 1 – 1 Hypernasaliteit 34 0.0 0 23.5 8 50.0 17 23.5 8 2.9 1 2 2 – 3 Hyponasaliteit 34 8.8 3 23.5 8 35.5 12 23.5 8 8.8 3 2 1 – 3 Nasale emissie 34 0.0 0 8.8 3 32.4 11 47.1 16 11.8 4 3 2 – 3 Nasale turbulentie 34 0.0 0 17.6 6 23.5 8 47.1 16 11.6 4 3 2 – 3 Stem 34 14.7 5 52.9 18 26.5 9 5.9 2 0.0 0 1 1 – 2 Spraakaanvaardbaarheid 34 8.8 3 61.8 21 23.5 8 2.9 1 2.9 1 1 1 – 2
Tabel 8: Resultaten vragenlijst: Werd er voldoende tijd voorzien voor het invullen van het CAPS-A-NL beoordelingsinstrument pre-training, post-training en follow-up?
Beoordelingsschaal a 0 1 2 3 4 Tijdsvoorziening n % n % n % n % n % n Pre-training 32 15.6 5 25.0 8 18.8 6 28.1 9 12.5 4 Post-training 32 9.4 3 25.0 8 18.8 6 40.6 13 6.3 2 Follow-up 34 0.0 0 0.0 0 8.8 3 55.9 19 35.3 12 Noot. n, aantal studenten; %, procentueel aantal studenten; pre-training, voor de training; post-training, onmiddellijk na de training; follow-up, één maand na de training.
a Beoordelingsschaal: 0, helemaal niet akkoord; 1, niet akkoord; 2, neutraal; 3, akkoord; 4, helemaal akkoord.
Voor wat betreft de vragen die peilden naar de gegeven training werden volgende resultaten bekomen. De studenten vonden over het algemeen dat de inhoud van de training relevant was voor het invullen van het CAPS-A-NL, meer specifiek vonden achttien van de 32 studenten (56.3%) de training relevant en tien studenten (31.3%) vonden dit zelfs zeer relevant. Slechts vier studenten (12.5%) stonden neutraal ten opzichte van de relevantie van de training met betrekking tot het invullen van het CAPS-A-NL. De scores 0 en 1, respectievelijk helemaal niet relevant en niet relevant werden door niemand aangeduid.
Binnen de inhoud van de training werd er specifiek gepeild naar de mening van de onervaren luisteraars omtrent het aantal aangeboden voorbeeldcasussen. Akkoord tot helemaal akkoord met het aantal aangeboden voorbeeldcasussen waren achttien van de 32 studenten (56.2%). Slechts zeven studenten (21.9%) waren van mening dat er onvoldoende voorbeeldcasussen aangeboden werden. Daarnaast stelden zeven andere studenten (21.9%) zich neutraal op ten opzichte van deze vraag. Sommige studenten vroegen om specifiek meer voorbeeldcasussen tijdens de training waarbij nasale emissie en nasale turbulentie samen werden behandeld of waarbij spraakaanvaardbaarheid centraal zou staan tijdens het beluisteren en beoordelen van een voorbeeldcasus.
Daarnaast werd gevraagd bij welke spraakparameter van het CAPS-A-NL de student graag dieper had ingegaan tijdens de training. Tabel 9 geeft een overzicht weer van de antwoorden op deze vraag. Voor de spraakparameter spraakverstaanbaarheid kan opgemerkt worden dat meer dan 90% van de studenten aangaf (helemaal) geen nood te hebben om deze spraakparameter dieper uit te werken tijdens de training. Daartegenover vroeg meer dan twee derde van de studenten om verdieping van de spraakparameters nasale emissie en nasale turbulentie. Voor wat betreft de spraakparameters stem en spraakaanvaardbaarheid werd door de helft van de studenten een verdere uitwerking gewenst. De vraag naar verdieping bij hyper- en hyponasaliteit was verdeeld, waarbij ongeveer een derde van de studenten geen nood had aan verdieping, vroeg een ander derde om verdieping en als laatste stond ongeveer een derde van de studenten neutraal tegenover een verdieping tijdens de training bij deze twee spraakparameters.
Tabel 9: Resultaten vragenlijst: Op welk onderdeel van het CAPS-A-NL beoordelingsinstrument had u graag dieper ingegaan tijdens de training?
Beoordelingsschaal a 0 1 2 3 4 Spraakparameter n % n % n % n % n % n Spraakverstaanbaarheid 32 21.9 7 68.6 22 9.4 3 0.0 0 0.0 0 Hypernasaliteit 32 3.1 1 34.4 11 34.4 11 28.1 9 0.0 0 Hyponasaliteit 32 3.1 1 28.1 9 31.3 10 37.5 12 0.0 0 Nasale emissie 32 0.0 0 6.3 2 25.9 8 59.4 19 9.4 3 Nasale turbulentie 32 0.0 0 15.6 5 15.6 5 56.3 18 12.5 4 Stem 32 9.4 3 46.9 15 15.6 5 25.0 8 3.1 1 Spraakaanvaardbaarheid 32 12.5 4 40.6 13 34.4 11 12.5 4 0.0 0 Noot. n, aantal studenten; %, procentueel aantal studenten.
a Beoordelingsschaal: 0, helemaal geen verdieping nodig; 1, geen verdieping nodig; 2, neutraal; 3, verdieping
nodig; 4, veel verdieping nodig.
Tot slot werd de mening van de studenten bevraagd omtrent de voorziene tijd voor de training. De meningen hieromtrent waren verdeeld. Akkoord tot helemaal akkoord waren dertien van de 32 studenten (40.6%) met de voorziene trainingstijd. Acht studenten (25.0%) hielden zich neutraal ten opzichte van deze stelling en elf studenten (34.4%) lieten uitschijnen dat de voorziene trainingstijd onvoldoende was. Bovendien gaf een student als suggestie om meerdere trainingsmomenten te voorzien in plaats van maar één trainingsmoment.
4. Discussie
Deze studie onderzocht het effect van training op de betrouwbaarheid van de perceptuele beoordeling van spraak bij onervaren luisteraars. Vijfendertig eerste masterstudenten Logopedische Wetenschappen aan de Universiteit van Gent beoordeelden driemaal tien spraakstalen van individuen met een (cheilognato)palatoschisis, gebruik makend van het CAPS-A-NL beoordelingsinstrument (Bruneel et al., 2020). Een eerste beoordeling vond plaats voor de training. Na deze eerste beoordeling werden de onervaren luisteraars twee uur getraind in het perceptueel beoordelen van spraak bij individuen met een (cheilognato)palatoschisis. Onmiddellijk daarna vond het luisterexperiment opnieuw plaats. De derde beoordeling vond ten slotte één maand later plaats. De inter- en intrabeoordelaarsbetrouwbaarheid werden bij de drie beoordelingsmomenten getoetst opdat de evolutie van de betrouwbaarheid in kaart kon worden gebracht. Na elke beoordeling werden de studenten gevraagd de toepasbaarheid van en suggesties voor de training met betrekking tot het CAPS-A-NL beoordelingsinstrument te evalueren aan de hand van een vragenlijst met een vijfpuntenschaal.
Als hypothese werd, op basis van de bestaande literatuur, vooropgesteld dat training de inter- en intrabeoordelaarsbetrouwbaarheid ten goede zou komen (Gooch et al., 2001; Brunnegård et al., 2009; Sell et al., 2009; Chapman et al., 2016). Daarenboven zouden de positieve effecten van de training op de betrouwbaarheid van de perceptuele beoordeling naar waarschijnlijkheid standhouden gedurende minstens één maand (Chapman et al., 2016).
In dit onderzoek varieerde de interbeoordelaarsbetrouwbaarheid voor de training van behoorlijk tot goed voor drie van de zeven spraakparameters, namelijk spraakverstaanbaarheid, hypernasaliteit en spraakaanvaardbaarheid. De interbeoordelaarsbetrouwbaarheid voor hyponasaliteit, nasale emissie, nasale turbulentie en stem was slecht. Gelijkaardig aan voorgaand onderzoek stegen de ICC-waarden na de training (Chapman et al., 2016) en specifieker stegen in dit onderzoek alle zeven spraakparameters. Ondanks deze stijging bleef de interbeoordelaarsbetrouwbaarheid slecht voor nasale emissie, nasale turbulentie en stem. Eén maand na de training werd terug een stijging gezien
van de spraakparameters nasale turbulentie en stem, maar de interbeoordelaarsbetrouwbaarheid bleef
algemeen slecht voor deze twee spraakparameters. Een daling werd daarentegen gezien voor de vijf andere spraakparameters, namelijk spraakverstaanbaarheid, hypernasaliteit, hyponasaliteit, nasale
emissie en spraakaanvaardbaarheid. Ondanks deze dalingen was de
interbeoordelaarsbetrouwbaarheid bij op één na alle spraakparameters één maand na de training nog steeds hoger dan de interbeoordelaarsbetrouwbaarheid voor de training. Dit is in overeenstemming met de studie van Chapman en collega’s (2016) waar de interbeoordelaarsbetrouwbaarheid voor dezelfde spraakparameters als in dit onderzoek één maand na de training ook hoger waren dan voor de training.
Verder traden in de studies van John et al. (2006), Sell et al. (2009) en Chapman et al. (2016) ook moeilijkheden op bij het berekenen en interpreteren van de interbeoordelaarsbetrouwbaarheid van bepaalde spraakparameters zoals bijvoorbeeld de spraakparameter stem die inherent bleken te zijn aan de gebruikte statistische methodes in deze onderzoeken, namelijk de ICC en de Cohen’s kappa. Redenen die hieraan werden toegeschreven door bovenstaande auteurs zijn: het niet frequent voorkomen van de desbetreffende spraakparameter in de spraakstalen of wanneer alle beoordelingen