ARTIFICIELE INTELLIGENTIE EN BIG
DATA IN DE GENEESKUNDE: EEN
SYSTEMATISCH OVERZICHT
Matthieu Batens
Stamnummer: 01410903
Promotor: Prof. Dr. Phillip Blondeel Copromotor: Dr. Bernard Depypere
Masterproef voorgelegd in het kader tot het behalen van de graad Master of Medicine in de Geneeskunde
Deze pagina is niet beschikbaar omdat ze persoonsgegevens bevat.
Universiteitsbibliotheek Gent, 2021.
This page is not available because it contains personal information.
Ghent University, Library, 2021.
Voorwoord
De afgelopen jaren miste ik een technologisch en innovatief aspect in mijn studies. Dankzij het schrijven van deze masterproef werd dit tegemoet gekomen. Ik maakte kennis met de heel fascinerende wereld van Artificiële Intelligentie en Big Data en hun bijzonder interessante toepassingen in de geneeskunde. Daarnaast heeft de masterproef me geleerd om telkens en opnieuw met een kritische bril naar de wetenschap te kijken.
De inleiding van deze masterproef verschaft een overzicht van wat Artificiële Intelligentie en Big Data is en hoe het werkt. Het kan als handleiding gebruikt worden voor medisch opgeleide personen zonder achtergrond in de computerwetenshappen of data science. Het tweede deel omvat het werkelijke onderzoek van deze masterproef.
In het bijzonder wil ik mijn promotor, Dr. Bernard Depypere, bedanken. Zijn tijd, inzicht en advies waren onontbeerlijk voor de totstandkoming van deze masterproef. Daarnaast wil ik professor Decruyenaere bedanken voor zijn kritische reflecties.
Verder wil ik mijn familie, vriendin en vrienden bedanken. Hun steun en toeverlaat zijn van ontzettend grote waarde.
Veel plezier met de fascinerende wereld van Aritificiële Intelligentie en Big data
Matthieu Batens
“Some people call this artificial intelligence, but the reality is this technology will enhance us. So instead of artificial intelligence, I think we'll augment our
intelligence.” -
Inhoudsopgave
Voorwoord ... II Inhoudsopgave ... IV Abstract... 1 Inleiding ... 2 Data ... 2 Big data ... 4 Data mining ... 5 Artificiële intelligentie ... 8 Geschiedenis ... 8 Toepassingen ... 10 Machine learning ... 11Supervised vs. unsupervised leren ... 11
De 5 families van machine learning ... 12
Overfitting ... 19 Vraagstelling ... 20 Methodologie... 21 Onderzoeksvragen ... 21 Onderzoeksvraag 1: ... 21 Rationale: ... 21 Onderzoeksvraag 2: ... 21 Rationale: ... 21 Onderzoeksvraag 3: ... 21 Rationale: ... 21 Zoekstrategie en zoekcriteria ... 22 Inclusie- en exclusiecriteria ... 22 Classificatieproces ... 23
Eerste database ... 23
Tweede database ... 25
Data-analyse ... 25
Samenvatting methodologie ... 26
Resultaten ... 27
Onderzoeksvraag 1: soorten onderzoek ... 27
Onderzoeksvraag 2: disciplines... 27
Onderzoeksvraag 3: tekorten ... 28
Onderzoeksvraag 3.1: identificatie van de tekorten ... 28
Onderzoeksvraag 3.2: ontwikkelingen van het belangrijkste tekort ... 29
Discussie... 31
Onderzoeksvraag 1: soorten onderzoek ... 31
Onderzoeksvraag 2: discipline ... 31
Onderzoeksvraag 3: tekorten ... 33
Onderzoeksvraag 3.1 ... 33
Onderzoeksvraag 3.2 ... 34
AI en Big Data in de geneeskunde: effectief een meerwaarde? ... 35
Artificiële intelligentie en Big Data in het UZ Gent ... 37
Beperkingen ... 38
Conclusie ... 39
Referenties ... 41 Bijlage ... I
Abstract
De laatste jaren is er steeds meer belangstelling voor Artificiële Intelligentie en Big Data in de geneeskunde. Het doel van dit onderzoek is de huidige situatie hieromtrent in kaart te brengen. In de inleiding wordt een definitie gegeven van Artificiële Intelligentie en Big Data en wordt hun werking uitgelegd. Vervolgens werd een analyse uitgevoerd op 1.356 artikels. De resultaten hieruit gaven aan dat het meeste onderzoek wordt verricht naar AI Devices (45,7%) en in de discipline revalidatie (28,5%) en dat er minder onderzoek verricht wordt naar het opslaan, verwerven of verwerken van data (2,9%), de implementatie van AI (0,07%) en het sociale en maatschappelijk kader (1,7%). Nadien werden 5 ontwikkelingen in het onderzoek daar medische data geïdentificeerd: 1. Aan 55% van de onderzoeken werken Health informatics en in 37,5% wordt er samengewerkt tussen verschillende disciplines. 2. De VS verrichtten met 62,5% de meeste onderzoeken. 3. 55% van de onderzoeken werd verricht door 1 universiteit en in 40% werd er samengewerkt tussen verschillende instellingen. 4. Er is een toename van het aantal artikels van 2014 tot 2018. 5. In 60% van de onderzoeken werd zelf iets ontwikkeld. Ondanks het vele onderzoek slaagde Artificiële Intelligentie er tot op vandaag niet in om te voldoen aan de verwachtingen. De belangrijkste redenen hiervoor zijn: de fundamentele beperkingen in de wetenschap van machine learning, de soorten onderzoeken die worden uitgevoerd naar Artificiële Intelligentie en Big Data en de logistieke, sociale en maatschappelijke hindernissen die met de implementatie gepaard gaan.
Inleiding
Data
De wereldbevolking oversteeg in mei 2018 het aantal van 7,6 miljard mensen. Hiervan zitten meer dan 2 miljard mensen op het internet en gebruiken meer dan 5 miljard mensen een mobiel apparaat. (1) Sinds de digitale revolutie in de jaren 80 van de vorige eeuw is het verzamelen van data makkelijker en goedkoper. Dit resulteert in het genereren van ontzettend grote hoeveelheden nieuwe data. (2)
De totale hoeveelheid data nam tussen 1987 en 2007 toe met een factor 100. (1) De onderzoeksgroep IDC (International Data Corporation) schatte de totale grootte in 2011 op 2,7 ZB (Zettabyte of 1021 bytes of 1 miljard TB) en 5 jaar later op 16,1 ZB. Deze groei blijft exponentieel
toenemen met een verdubbeling van de data om de 2 jaar. Dit wil zeggen dat er elk jaar meer dan 40% van de bestaande data nieuw bijkomt. (2)
Naast de absolute toename van de totale hoeveelheid data ontstaat er ook een relatieve toename. Er wordt relatief meer informatie over 1 specifiek onderwerp verzameld dan voordien. Zowel deze absolute als relatieve toename is van groot belang voor Big Data en Machine Learning. (2) Even opmerkelijk is de bliksemsnelle verandering van analoge naar digitale data, gekend als de digitale revolutie. In het jaar 2000 was 75 percent van de totale hoeveelheid data analoog en 25 percent digitaal. In 2015 daarentegen telde het aandeel analoge data maar slechts 1 percent meer. (2)
Door de vele soorten bronnen die informatie leveren kan de data gestructureerd, semigestructureerd of ongestructureerd zijn. Voorbeelden van gestructureerde data zijn het rijksregister en een medisch dossier waar alle gegevens mooi geordend zijn in rijen en kolommen. Een e-mail waar de zender, ontvanger en onderwerp gekend en gestructureerd zijn, maar de tekst niet, is een voorbeeld van semigestructureerde data. Foto’s op facebook, tweets of Twitter en video’s op YouTube zijn allen voorbeelden van ongestructureerde data. Daarnaast kan data onderverdeeld worden in primaire en secundaire data. Data die verzameld wordt door een onderzoeker (een wetenschapper, een overheid, een bedrijf, etc.) aan de hand van onderzoeken, vragenlijsten, experimenten, etc. noemt men primaire data. Deze data ondergingen nog geen structurering of statistische bewerking. Data die reeds verzameld en opgeslagen werden door
iemand anders en vervolgens gestructureerd en/of bewerkt worden, noemt men secundaire data. (1)
In 2016 publiceerde de IDC een rapport over de evolutie van data tegen 2025. Hierin schat ze dat tegen 2025 de totale hoeveelheid data maar liefst 163 ZB zou bedragen. Dit staat gelijk aan 489 miljoen keer het gehele Netflixaanbod of 40 biljoen DVD’s, die naast elkaar een afstand overbruggen van 100 miljoen keer naar de maan én terug. In het rapport worden ook 5 punten aangehaald waarin de digitale wereld tegen 2025 zal veranderen. Ten eerste zal de oriëntatie van data veranderen van voornamelijk bedrijfsgerelateerd naar ook levensnoodzakelijk, zoals bijvoorbeeld een continue hartmonitoring van op afstand. Ten tweede zal data niet meer gecentraliseerd zijn, maar een interactief onderdeel uitmaken van IoT (Internet of Things: het netwerk van gsm’s, tablets, auto’s, en apparatuur geïntegreerd met elektronica, software, sensors en internet) en geïntegreerde systemen. Zo zal een geconnecteerde persoon met een geconnecteerd apparaat per dag maar liefst 4800 keer interageren en zullen er per persoon niet 1 maar 4 geïntegreerde systemen, zoals gsm’s en tablets, gegevens uitwisselen. Ten derde zal het grootste deel van de data niet meer geproduceerd worden door de consument, maar door ondernemingen. Zo zal een sociale mediawebsite de foto’s, video’s en tekst die gebruikers uploaden, moeten opslaan en beheren op hun infrastructuur. Daarnaast zal de hoeveelheid data die geanalyseerd wordt met artificiële intelligentie toenemen met een factor 100 tot 1.4 ZB. Als vijfde en laatste punt zal het grootste deel van de data continu geconnecteerd en interactief zijn. Data zullen onmiddellijk verwerkt en geanalyseerd worden om de resultaten direct te kunnen gebruiken, zoals bijvoorbeeld al het geval is bij een GPS-systeem. Tenslotte wordt in het rapport ook vermeld dat bijna 90% van de data beveiliging nodig heeft, maar minder dan 50% beveiligd zal zijn. (3)
Voor de digitale revolutie was het verzamelen van data echter zeer tijdrovend en, meestal noodgedwongen, duur. Als gevolg hiervan werd er zo weinig mogelijk data verzameld en werd ervan uitgegaan dat het gebrek aan data eigen was aan het onderzoek. Als antwoord op deze assumptie werd de methode van data sampling, en in het bijzonder randomized data sampling, ontwikkeld. Dit maakte het mogelijk om slechts naar een deel te kijken en toch te redeneren over het geheel. Zo kon men toch relevante en bruikbare verbanden leggen in zo’n klein mogelijke hoeveelheid data. Deze aanpak heeft weliswaar structurele tekortkomingen: het kleine deel moet de essentie van het geheel omvatten. Aangezien dit moeilijk doelgericht te doen is zonder het geheel te kennen, zochten onderzoekers hun toevlucht in randomized sampling. Zelfs een perfecte
random sample zal het geheel slechts omvatten met een gelimiteerde graad van likelihood, daar
de sample per definitie nooit alle gegevens van het geheel kan bevatten. Dit resulteert in fouten. (4)
Dit kan mooi geïllustreerd worden aan de hand van een geval in het sumoworstelen. Jarenlang dacht men dat de sport ondermijnt werd door matchfixing. De analyse op een gerichte steekproef uit de belangrijkste wedstrijden toonde echter geen bewijs van vals spel. Noch toonde de analyse op een steekproef uit alle wedstrijden bewijs van matchfixing. Pas wanneer men de data verzamelde van elke wedstrijd over een periode van 10 jaar werd er bewijs gevonden. De matchfixing vond dus wel degelijk plaats, alleen niet waar men dacht en niet zo geselecteerd dat een gerandomiseerde steekproef dit significant kon weergeven. (4)
Door de toenemende technische mogelijkheden zal het over de komende jaren mogelijk zijn om steeds meer, en zelfs compleet geautomatiseerd, data te verzamelen. Geautomatiseerde analyse van grotere hoeveelheden data zal leiden tot meer kennis en inzicht in de onderzoekdomeinen. (2,4,5)
Big data
Er bestaat geen algemeen aanvaarde definitie over Big Data in de literatuur. Toch hebben heel wat onderzoekers geprobeerd de term te definiëren.
De meest gangbare definitie beschrijft Big Data als volgt: data die niet meer verwerkt en geanalyseerd kan worden aan de hand van traditionele statistische technologieën en methodes (4).
Volgens het onderzoeksbureau Gartner wordt Big Data gekenmerkt door 3 dimensies: variëteit, snelheid en volume. Variëteit refereert naar het grote aantal soorten data. Zo kan data gaan om tweets op Twitter, likes op Facebook, views op YouTube, maar ook om mails, documenten, elektronische patiëntendossiers, klantbestanden, etc. Snelheid staat voor het hoge tempo waarmee men data verwerft en soms tegelijk gebruikt. Volume refereert naar de noodzaak van grote hoeveelheden data. Deze 3 dimensies worden ook wel de 3 v’s (naar analogie van het Engelse variety, velocity en volume) van Big Data genoemd (1,2).
Verder werd Big Data gedefinieerd als data met minstens log (n*p) ³ 7 (n= aantal waarnemingen, p= aantal variabelen) en met de kenmerken van grote variëteit en hoge snelheid. Data in de medische sector bestaan inderdaad uit heel wat soorten informatie afkomstig van verschillende bronnen. Voorbeelden van bronnen die medische data leveren zijn het EPD (elektronisch patiëntendossier, bestaande uit onder meer de voorgeschiedenis, medicatie, laboresultaten en radiologische beeldvorming), machines of sensors (zoals vaste of draagbare apparaten die vitale parameters meten), maar ook medische tijdschriften met hun wetenschappelijke artikels (6).
Het Amerikaanse National Institutes of Health richtte in 2013 het project Big Data to Knowledge
Initiative op. Het project focust op kennisverwerving uit Big Data en definieert Big Data als volgt:
‘een klein aantal groepen die zeer grote hoeveelheden data produceren, dikwijls als onderdeel van projecten speciaal gefinancierd om belangrijke bronnen te verwerven voor de gehele onderzoeksgemeenschap; individuele onderzoekers die grote datasets produceren, dikwijls geholpen door nieuwe toepasbare technologieën; en een nog groter aantal databronnen die elk afzonderlijk kleine datasets produceren waarvan de meerwaarde zit in het samen brengen en integreren met andere data’. (7)
In 2013 en 2014 organiseerde het centrum voor gezondheidsinformatica van de Nationale Universiteit van Singapore de eerste en tweede internationale conferentie van Big Data en Analytics in de gezondheidszorg. Hierdoor kwam er voor onderzoekers en beleidsmakers in de medische sector een forum voor het verspreiden van baanbrekend onderzoek naar Big Data. Men deelt er de nieuwste strategieën, analytische hulpmiddelen en technieken voor het omgaan met Big Data. Sindsdien worden er jaarlijks door heel wat universiteiten en associaties internationale congressen over Big Data georganiseerd. (4)
In de klinische praktijk en in deze masterproef wordt Big Data gezien als data die te uitgebreid zijn om er nog handmatig mee om te gaan. Ze bestaan uit zowel gestructureerde als ongestructureerde data en zijn typisch opgeslagen in verschillende medische databases. (5,9)
Data mining
De toenemende groei aan data brengt een grote uitdaging met zich mee: Big Data kan niet meer verwerkt en geanalyseerd worden aan de hand van traditionele statistische technologieën en methodes. Als oplossing hiervoor werden nieuwe manieren ontwikkeld voor data-analyse en kennisverwerving, ook gekend onder de term Data Mining. (1)
Het concept data mining werd voor het eerst genoemd in 1995 op de toenmalig eerste conferentie van het AMC SIGKDD (Association for Computing Machinery’s Special Interest Group on
Knowledge Discovering and Data mining). Data mining bestond daarvoor als interdisciplinair
studiedomein tussen de klassieke statistiek en machine learning, een onderdeel van artificiële intelligentie (cfr. infra). Van daaruit ontwikkelde het zich tot een computerwetenschap die zich bezighoudt met het analyseren van data en omvat onder meer patroonherkenning, database design, artificiële intelligentie en visualisatie.
Hoewel er ook hier heel wat definities gehanteerd worden, luidt de meest duidelijke als volgt: ‘data mining is het proces waarbij betekenisvolle correlaties, patronen en trends ontdekt worden tijdens het onderzoeken van grote hoeveelheden data in datasets, gebruikmakend van algoritmes uit de statistiek, wiskunde en machine learning’.
Een andere veelgebruikte definitie beschrijft data mining als ‘de analyse van een, dikwijls, grote dataset voor het vinden van onverwachte relaties en het samenvatten van de informatie op een nieuwe manier zodat ze zowel verstaanbaar als bruikbaar is voor de gebruiker’. (10)
Zoals beide definities impliceren, is het doel van data mining om nieuwe, diepere inzichten en ongekende verbanden te zoeken, die dan vervolgens kunnen gebruikt worden in beslissings-ondersteunende systemen. Daarnaast laat data mining ook toe om nieuwe wetenschappelijke hypothesen te genereren uit zowel grote experimentele medische datasets als uit de medische literatuur. Data mining is een manier om het gat tussen de groeiende hoeveelheid data en het gebruik van de kennis die erin verweven zit te overbruggen. (11)
Door de toepassing van data mining kan men nieuwe biomedische en medische kennis verwerven. De kennis kan dan gebruikt worden in klinische beslissingsondersteuningssystemen (stellen van diagnose, kiezen van therapie, …) of in administratieve beslissingsondersteuningssystemen (demografische trends, kwaliteitscontrole, kostenefficiëntie, …). Informatie uit de beslissings-ondersteuningssystemen kan dan op haar beurt de clinicus helpen in de praktijk of de beleidsvoerder in haar beleidsmaking. (10-12)
Wat is nu het verschil tussen het verwerven van kennis uit databases (KDD, knowledge discovery in databases) en data mining? Volgens Cross-Industry Standard Proces for Data Mining (CRISP-DM), dat werd opgericht in 1996 door 4 bedrijven met als doel de oprichting van een uitgebreide
data mining methodologie en procesmodel, bestaat het proces van data mining uit 6 stappen: het verstaan van het onderwerp, het begrijpen van de data, het voorbereiden van de data, het modelleren, de evaluatie en de implementatie. Het verwerven van kennis uit databases, KDD, bestaat uit dataselectie, data voorbewerking, data transformatie, data mining en interpretatie of evaluatie. Door deze gelijkenis worden de twee begrippen door elkaar gebruikt. Toch is er een consensus dat data mining een van de grootste stappen van het KDD-proces is. Dus, data mining is een onderdeel van KDD en data mining in het KDD-proces is een set van applicaties of algoritmes voor het vinden van patronen in voorbewerkte data. (10)
Heel wat onderzoekers onderzochten ook het verschil tussen de klassieke statistiek en data mining. Zo wordt statistiek aanzien als primaire data-analyse (analyse op primaire data, zie eerder) en data mining als secundaire data-analyse (analyse op secundaire data). Een van de redenen achter deze visie is dat volgens CRISP-DM data mining de stap is nadat de data begrepen zijn, waarvoor diverse statistische procedures nodig zijn. Volgens andere is data mining vergeleken met statistiek eerder een verschil in kind dan een verschil in degree. Dit omwille van vier significante verschillen tussen statistiek en data mining.
Terwijl statistiek gebruikmaakt van conservatieve strategieën en een wiskunde aanpak prefereert om de data te analyseren, is data mining meer flexibel over welke methode in welke volgorde gebruikt wordt.
Ten tweede maakt de statistiek typisch gebruik van data sampling met ten hoogste een paar duizend gevallen, data mining daarentegen gebruikt data die de gehele populatie omvat. In de statistiek verschaft data sampling bijna dezelfde statistische significantie als het geval zou zijn indien de onderzoeker data gebruikt van de gehele populatie. Zoals hierboven reeds aangehaald was dit een noodzaak voor de digitale revolutie wanneer de onderzoekers de middelen niet hadden om de gehele populatie te includeren en de computerwetenschappen nog niet in staat waren om zo’n grote hoeveelheden data te verwerken. Daartegenover moet data mining, omdat het data clustert en verborgen patronen herkent, alle data van de populatie gebruiken om tot een goed en betrouwbaar resultaat te komen.
Ten derde verschilt de statistiek met data mining in het soort data dat ze analyseren. Statistiek verwerkt door zijn pure wiskundige aanpak enkel numerieke gegevens (categorische gegevens vereisen een numerieke codering). Data mining kan daarnaast ook andere soorten data, zoals tekst, geluiden, foto’s, analyseren. Data mining kan dus zowel numerieke als categorische data
direct analyseren. Sommige data mining algoritmes kunnen echter slechts 1 soort variabele verwerken.
Ten laatste is statistiek hypothetisch-deductief en data mining inductief. In de statistiek vertrekt men, zoals in elke wetenschap vandaag, van een hypothese die men vervolgens gaat testen op primaire data. Statistiek is dus een proces waarbij men redeneert uit het geheel, de hypothese, naar het specifieke, de data. Data mining analyseert, zonder vooropgestelde hypothese, secundaire data op zoek naar verborgen verbanden en patronen. Data mining hanteert dus een tegenovergestelde denkwijze: data mining is een proces waarbij men redeneert vanuit het specifieke, de data, naar het geheel, kennis of een evidence-based hypothese. (13)
Vooraleer data mining toegepast kan worden op medische data, moeten onderzoekers weten welke data mining algoritmes bestaan en hoe ze werken. Zoals de definitie zegt, is data mining een proces dat algoritmes gebruikt gebaseerd op wiskunde, statistiek en machine learning. Wiskunde en statistiek worden al gebruikt sinds men aan onderzoek doet en worden beheerst door elke onderzoeker. Het laatste is een onderdeel van een nieuwe wetenschap, artificiële intelligentie, die voor heel wat medische onderzoekers ongekend territorium is.
Artificiële intelligentie
Artificiële intelligentie (AI) of kunstmatige intelligentie (KI) is een term die gebruikt wordt voor de intelligentie die een computer of machine bezit. Het is een nieuwe wetenschap die zich focust op het modelleren van intelligent gedrag bij een computer aan de hand van een minimaal menselijke interventie of programmering. (14)
De meest gekende voorbeelden van technologieën met artificiële intelligentie zijn spraakherkennings-systemen, zelfrijdende auto’s, zoekmachines zoals Google, computersystemen die op het hoogste niveau strategische spellen spelen, spamfilters in mailprogramma’s en content delivery networks. Content delivery networks zijn geografisch over het internet verspreide netwerken van proxyservers gegroepeerd in verschillende datacenters. Ze zorgen ervoor dat internetgebruikers snel en onvertraagd informatie kunnen ophalen. (15)
Geschiedenis
De roots van artificiële intelligentie zijn terug te vinden bij de uitvinding van robotica. Het woord robot verscheen voor het eerst in het werkstuk R.U.R. (Rossum’s Universal Robots) van de
Tsjechische schrijver Karel Capek in 1921. Het Tsjechische woord robota verwees naar de biosynthetische machines die gebruikt werden als dwangarbeiders. 30 jaar later werd het woord robot vereeuwigd door Isaac Asimov in een reeks sciencefictionverhalen.
De zoektocht naar een zelfgestuurde machine houdt de mens al lang bezig. De oudste verwijzing naar een ‘menselijke machine’ wordt teruggevonden in China in de 3 de eeuw. Een ingenieur presenteerde toen aan het keizerlijke hof voor het eerst een handgemaakt menselijk figuur vervaardigd uit hout, leer en artificiële organen. Ook in de Islamitische wereld worden verwijzingen naar geautomatiseerde poppen teruggevonden vanuit de 12de eeuw. In Europa zette Leonardo da Vinci met zijn gedetailleerde werk over de menselijke anatomie een grote stap in de ontwikkeling van de robots. Zijn tekenboeken bleken voor heel wat latere ingenieurs een grote inspiratiebron. Vandaar dat het Amerikaanse bedrijf Intuitive Surgical haar chirurgische robotica de naam ‘Da Vinci’ als erkenning gaf. De eerste elektrische autonome robot, Machine Speculatrix, werd in 1948 gebouwd door William Gray Water. Hij had als doel te illustreren hoe het menselijk brein functioneert en toonde met zijn robot dat connecties tussen een klein aantal hersencellen tot complex gedrag kunnen leiden.
De term artificiële intelligentie werd in 1955 voor het eerst gebruikt door John McCarthy. Hij definieerde het als ‘de wetenschap en de bouwkunde van het creëren van intelligentie machines’. McCarthy was van groot belang in de vroege ontwikkeling van artificiële intelligentie. Hij richtte samen met zijn collega’s aan de Universiteit van Dartmouth het interdisciplinair studiedomein op. Het bood een eerste kader voor de komende ontwikkelingen.
Tijdens de jaren zestig en zeventig kende artificiële intelligentie weinig vooruitgang. Deze stagnerende periode wordt beschreven als de AI-winter. In de jaren tachtig kwam er uiteindelijk een doorbraak door belangstelling vanuit de logistieke sector en werd AI steeds meer gebruikt voor data mining en voor het voorspellen van medische diagnoses. De performantie van de systemen steeg met de jaren. Zo kon Big Blue (Big Blue is de bijnaam voor IBM, International Business Machines Corporation) uiteindelijk op 11 mei 1997 de wereldkampioen schaken, Gary Kasparov, verslaan.
Door de continue vooruitgang op het gebied van elektronische snelheid, capaciteit en softwareprogrammering sinds begin jaren 2000 vindt AI steeds meer en meer toepassingen. Vandaag is het leven zonder AI gestuurde systemen gewoon niet meer denkbaar. (14,16)
Toepassingen
Zoals reeds vermeld wordt artificiële intelligentie dagelijks in heel wat domeinen toegepast. Hoewel de lijst van alle bestaande toepassingen nagenoeg eindeloos is, zijn er toch een aantal specifieke vakgebieden waar er op AI sterk werd ingezet.
In de auto-industrie kwam er door de komst van artificiële intelligentie een doorbraak in de zelfrijdende auto. Bimbrow beschrijft in zijn artikel mooi de ontwikkelingen naar een zelfrijdende auto. De eerste ideeën van een zelfrijdende auto ontstonden in de jaren 20 van de vorige eeuw. Toen ontwikkelde men de eerste radio gestuurde auto. In de daaropvolgende jaren kwamen er elektrische auto’s aangedreven door vaste elektrische circuits op de weg. In de jaren 80 werd AI geïmplementeerd aan de hand van zichtgeleidenauto’s, wat een ware doorbraak was. Vandaag gebruikt men een combinatie van de moderne radio en zicht gestuurde technologieën. In 2016 waren er meer dan 30 verschillende bedrijven die zich toespitsten op AI in zelfrijdende auto’s. De grote spelers zijn onder meer Google, Tesla en Renault. Google beschikt over 7 zelfrijdende auto’s die tot op heden samen meer dan 1 miljoen kilometer volledig zelfstandig hebben gereden. De huidige modellen van Tesla zijn level 2, hoewel Tesla’s oprichter Elon Musk beweert dat ze snel een volledig zelfrijdende auto (level 4) op de markt zullen brengen. De meest autonome auto is een concept car van Renault, de Symbioz (level 4). (17)
Ook in de economische en financiële wereld kende AI zijn doorbraak. Zo werd in de jaren 90 van de vorige eeuw al aangetoond dat de aandelenmarkt accuraat voorspeld kon worden a.d.h.v. AI. (18) Videogames maken gebruik van AI onder meer onder de vorm van dynamisch en doelgericht gedrag bij niet-speler-personages. Ook in het leger wordt er heel wat AI toegepast. Zo ontwikkelden zich de LAW (lethal autonomous weapons), een soort autonome militaire robot die zelfstandig doelwitten kan zoeken en aanvallen. Een voorbeeld hiervan zijn autonome drones in de lucht. (19) Een bizarre toepassing van AI vindt men terug in de kunst. Kunstenaars creëerden reeds werken met behulp van computergestuurde algoritmes gebaseerd op bestaande werken. (20)
Een zeer groot toepassingsgebied van AI vindt men in de geneeskunde. In de medische wereld kan AI opgedeeld worden in 2 takken, een fysieke en een virtuele. De fysieke tak bestaat uit fysieke objecten, medische apparatuur en medische robotica. Het meest gekende voorbeeld is het gebruik van robots in de chirurgie. Een minder gekend voorbeeld in België, maar heel populair in Japan, zijn de zogenaamde Carebots. Deze robots kunnen bijvoorbeeld ouderen helpen met boodschappen doen, kuisen, enz. Het is een enorme markt door de steeds toenemende vergrijzing.
Robots kunnen ook gebruikt worden in de nanotechnologie. Zo slaagden onderzoekers erin om antikankermedicatie met nanorobots meer in de ischemische zone en dus tumor te krijgen. (14,21)
De virtuele tak bestaat uit machine learning, ook deep learning genoemd en wordt besproken in de volgende paragraaf (14).
Machine learning
Machine learning is een onderdeel van artificiële intelligentie dat zich bezighoudt met hoe computers kunnen leren uit data. Het hanteert computerwetenschappen en statistiek om een computer de vaardigheid te geven om nieuwe taken te leren en uit te voeren, zonder daar expliciet voor geprogrammeerd te worden.
In de geneeskunde kan machine learning in heel wat disciplines worden gebruikt. Enkele veel besproken toepassingen zijn het interpreteren van radiologische beelden of histologische stalen en biopten, het identificeren van oorzakelijke genen of farmacologische bijwerkingen, het achterhalen van biochemische reacties in de cel en het ondersteunen van medische beslissingen zoals de diagnose en de therapie (15,21,22).
Supervised vs. unsupervised leren
Er zijn verschillende manieren van leren, gewoonlijk worden ze onderverdeeld in supervised
learning en unsupervised learning.
Bij supervised learning laat men een computer eerst data analyseren en taken leren waarvan de uitkomst gekend is. Vervolgens beschrijft en/of voorspelt de computer een nieuw geval. Dit gebeurt aan de hand van classificatie. Hierbij kiest de computer uit overeenkomende subgroepen om het nieuwe geval zo goed mogelijk te beschrijven en voorspellen. Enkele voorbeelden in de medische sector zijn het interpreteren van een ECG, de detectie van een longnodule op een radiografische beeld en het herkennen van maligne cellen op anatomische preparaten. In dit geval kan een computer wat een getraind arts kan.
In tegenstelling tot bij supervised learning zijn er bij unsupervised learning geen uitkomsten gekend. De computer tracht zelf patronen of groepen in de data te herkennen. Dit is vanzelfsprekend een veel moeilijkere taak aangezien de waarde en relevantie van de uitkomst niet gekend is en dus geëvalueerd moet worden op basis van zijn prestatie bij het sequentieel uitvoeren van supervised
learning met deze gegenereerde uitkomsten als nu wel gekende uitkomsten. Voorbeelden in de
medische sector zijn het identificeren van specifieke genenclusters, het achterhalen van de pathofysiologische mechanismen en het zoeken naar factoren die wondgenezing beïnvloeden. In dit geval kan de computer veel meer dan een getraind arts kan. (10,22,23)
De 5 families van machine learning
Elke dag worden er ontelbaar veel nieuwe algoritmes bedacht om machines te doen leren. Toch zijn deze allemaal gebaseerd op dezelfde basisideeën. Deze ideeën trachten antwoorden te geven op een vraag die ons allen bezighoudt: hoe leren we?
Pedro Domingos beschrijft in zijn boek The Master Algorithm de 5 grote families van machine
learning uitvoerig. Elk van deze families vertrekt vanuit haar eigen grondlegging, waarnaar ze
vernoemd wordt, en hanteert telkens een specfiek basisalgoritme.
De eerste familie, de symbolisten, zien de omgekeerde deductie als het basisalgoritme. Ze baseren zich op ideeën vanuit de filosofie, psychologie en logica. Connectionisten, de tweede familie, gebruiken als basisalgoritme backpropagation in neurale netwerken. Ze inspireren zich op neurowetenschappen en fysica. Ze proberen de complexiteit van het menselijk brein te achterhalen en het in een voor een computer uitvoerbaar algoritme te vertalen. Evolutionisten bootsen het evolutionair proces na op de computer en gebruiken genetische programmering als basisalgoritme. Ze leren hiervoor uit de genetica en de evolutionaire biologie. Bayesianen zien machine learning als een vorm van probabilistische gevolgtrekking. Ze vertrekken vanuit de statistiek en gebruiken het theorema van Bayes als hun basisalgortime. De laatste familie, de Analogizers, baseert zich op extrapolaties van gelijkheidsoordelen aan de hand van de support vector machines, hun basisalgoritme. Ze combineren psychologie en wiskundige optimalisatie. (15,24)
Symbolisten
Symbolisten gebruiken inductie, het omgekeerde van deductie, als uitgangspunt. Ze zien dit als regels die ze in de computer implementeren.
Bij deductie wordt er een gevolgtrekking gemaakt vanuit het algemene naar het bijzondere. Dit wordt gewoonlijk geïllustreerd aan de hand van volgende redenering: Socrates is een mens en alle mensen zijn sterfelijk dus Socrates is bijgevolg sterfelijk. Bij inductie gebeurt juist het omgekeerde, vanuit het bijzondere wordt het algemene gezocht. Dit geeft in het voorbeeld: Socrates is een mens en Socrates is sterfelijk dus mensen zijn sterfelijk. De symbolisten zien elk van deze premisse als
een regel die men in een computer kan implementeren. Inductie is voor hen hierbij de stap om het ontbrekende te vinden. Het systeem kijkt welke informatie er mist en zoekt die vervolgens specifiek in de beschikbare datasets. Deze manier van werken sluit het best aan met wat wetenschappers al vele jaren doen.
De methode heeft zijn voor- en nadelen. Zo is het volgens Domingos langs de ene kant mogelijk om nagenoeg altijd een regel te vinden die bij de data past, maar langs de andere kant is het risico op het vinden van een compleet nutteloze regel groot. In feite kan er door inductie steeds een nieuwe regel gevonden worden wat op zijn beurt leidt tot alweer een nieuwe regel. Er ontstaat dus een vicieuze cirkel waarbij er telkens informatie bijkomt. Dit leidt naar het grootste probleem van machine learning in het algemeen: overfitting (cfr. infra). (15,24)
Connectionisten (deep learning - deep NN)
De connectionisten trachten de werking van het menselijk brein te achterhalen om te weten hoe wij leren en trachten deze kennis vervolgens toe te passen op de computer zodat die zelf kan leren. Hiervoor ontwikkelden ze artificiële neuronen en verbonden hen in neurale netwerken.
Het menselijk brein bestaat uit een netwerk van neuronen. Deze neuronen krijgen signalen van tal van andere neuronen hetgeen leidt tot excitatie of inhibitie. Enkel wanneer de netto-input de drempel voor excitatie bereikt, plant de actiepotentiaal zich voort. Dus de output van een neuron heeft altijd dezelfde relatie t.o.v. zijn netto-input (on-off-fenomeen). Bijgevolg concludeerde Donald Hebb in 1949 dat de eigenschap om te adapteren en te leren, verweven zit in de verandering in de sterkte van de verschillende connecties tussen de neuronen. Hij stelde dat de kracht van een neuron om een ander neuron te exciteren of te inhiberen, en dus ook de relatie tussen de output van een netwerk neuronen t.o.v. de input in het netwerk, varieert doorheen de tijd door middel van ervaring (synaptische plasticiteit) (25).
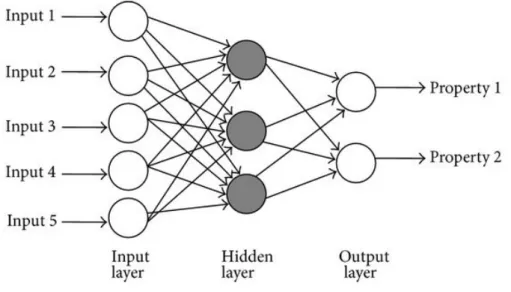
Een belangrijke stap in de ontwikkeling van neurale netwerken werd in de jaren 50 van de vorige eeuw gezet door Rosenblatt. Hij ontwikkelde een soort neuraal netwerk, gekend als perceptrons. Het eenvoudigste perceptron bestond uit 3 lagen van cellen (Figuur 1). De cellen van de eerste laag zijn willekeurig en gedeeltelijk verbonden met de cellen van de middelste of associatielaag. De cellen van deze middelste laag zijn vervolgens willekeurig verbonden met de cellen van de outputlaag of de responslaag. De outputlaag produceert verschillende outputs en inhibeert ook de andere cellen van de outputlaag en de cellen van de associatielaag waarvan ze geen input krijgen. Het proces loopt dus zo: activatie door verschillende inputsignalen waardoor verschillende
associatiecellen geactiveerd worden die op hun beurt enkele outputcellen activeren. De outputcel met de sterkste input inhibeert vervolgens andere cellen waardoor zijn output de definitieve output wordt. Deze vorm van cyclische perceptrons had jammer genoeg het grote nadeel van beperkt te zijn in haar diversiteit van herkenbare patronen. (26)
Figuur 1: een multilayor perceptron
De ontwikkeling van artificiële neurale netwerken lag gedurende de daaropvolgende jaren stil tot de komst van de multilayer feedforward neurale netwerken (MLFF of MLP). Daarnaast werden er ook andere types neurale netwerken ontwikkeld zoals de radial basis function network (RBF), die ook gebruik maken van perceptrons, recurrent neural networks (RNN) en tal van andere. Aangezien voornamelijk de multilayer feedfoward neurale netwerken veelvuldig worden toegepast in de geneeskunde, worden de andere buiten beschouwing gelaten. (26)
Pedro Domingos beschrijft in zijn boek de werking van een MLP als volgt: ‘Eerst wordt het neurale netwerk in de computer geprogrammeerd, daarna wordt het netwerk getraind en gevalideerd. De meest gebruikte methode hiervoor is backpropagation. Backpropagation tracht de kleinste mean
square error van de gehele dataset te verkleinen. De trainingset bestaat uit een groot aantal
gevallen waarvan de uitkomst reeds gekend is. De eerste laag cellen vertegenwoordigen de geselecteerde inputparameters. De middelste laag is de verborgen laag aangezien ze geen directe link heeft met de gekende data. Wanneer vervolgens het netwerk geactiveerd wordt, worden aan de connecties tussen de input en verborgen laag willekeurige sterktes, of weights, gegeven zodat het netwerk een output genereert. Nadien wordt de output vergeleken met de gekende, ware uitkomst en wordt de fout teruggekoppeld (backpropagation) naar het netwerk om zo de sterktes
van de connecties aan te passen en de mean square error verder te verkleinen. Dit proces wordt herhaald totdat de kleinste waarde gevonden wordt via de gradient descentmethode. De grootte van de aanpassingen aan de sterkte tussen de connecties wordt op voorhand vastgesteld. Algemeen stelt men dat hoe complexer de data zijn, hoe kleiner de aanpassingen moeten zijn. Dit omdat het netwerk anders niet in staat is om kleine verschillen in de data te detecteren. Het grote probleem met backpropagation is het vinden van het globale minimum en niet te blijven vastzitten in lokale minima. Dit is een wiskundig probleem waar tot op heden nog geen oplossing voor gevonden werd. Men stelt de vraag of het wel degelijk nodig is om het globale minimum te vinden. De gevonden minima, waarvan we niet weten of die globaal of lokaal is, voldoet meestal. Ze zou zelfs beter zijn tegen overfitting. Eens het artificiële neurale netwerk ontwikkeld is, moet ze gevalideerd worden op andere dataset alvorens ze daadwerkelijk gebruikt kan worden. ‘
De toepassingsgebieden van artificiële neurale netwerken zijn enorm. Al vroeg werden ze gebruikt voor het voorspellen van de aandelenmarkt. Daarnaast zijn ze geschikt om patronen te herkennen in foto’s, zo gebruikt Google ze onder meer voor het gekende experiment waar ze de computer katten wil leren herkennen. In de geneeskunde vindt men eindeloze hoeveelheden toepassingen terug, zo kan bijvoorbeeld a.d.h.v. een ontwikkeld ANN de genezingstijd bij brandwonden accuraat voorspeld worden. (26-27,29)
Evolutionisten
Evolutionisten baseren zich op de principes van de evolutionaire biologie en de genetica. Ze ontwikkelden genetische algoritmes die gebaseerd zijn op de evolutietheorie van Darwin en de biologische fenomenen die voor genetische diversiteit zorgen zoals mutatie en genetische recombinatie. Ze combineren verschillende mogelijk oplossingsmethodes om een probleem op te lossen, laten deze met elkaar mengen en tegen elkaar concurreren. Alleen de best geadapteerde methodes blijven over en worden geselecteerd waardoor de computer progressief betere algoritmes ontwikkelt. (15,24,28,30)
In de praktijk begint men met alle mogelijke oplossingen genetisch voor te stellen. Dit doet men door de computer op te bouwen vergelijkend het menselijk DNA. Een blok met computergeheugen die 1 oplossing bevat, wordt een individu genoemd en de data in de blok een chromosoom. Genen coderen vervolgens voor de attributen bij die oplossing en de waarde die elk attribuut kan aannemen noemt men allelen. Alle individuen van de populatie of alle mogelijke oplossingen voor het probleem worden gecodeerd aan de hand van binaire codering, permutation encoding,
encoding by a tree of andere, minder gebruikte coderingstechnieken. (30) De tweede stap is het
opstellen van een fitnessfunctie (tekening toevoegen). De fitnessfunctie of fitheidsfunctie geeft weer hoe dicht de oplossing van elke oplossingsmethode ligt bij het vooropgestelde doel. (15) Nadat de fitness geëvalueerd is voor elke oplossing of chromosoom, worden ze door kansrekening geselecteerd op basis van hun fitnesswaarde, d.w.z. hogere fitnesswaarden hebben hogere kans om geselecteerd te worden. Sommige chromosomen of oplossingen ondergaan vervolgens willekeurig een soort paringsproces waarbij nieuwe chromosomen of oplossingen gevormd worden. Hierbij ontstaat, zoals in de natuur, diversiteit door mutatie en crossing-over. De nakomelingen met een hogere fitnesswaarde hebben vervolgens meer kans om geselecteerd te worden. Deze cyclus wordt herhaald totdat het gewenste resultaat bekomen wordt. (28)
Bayesianen
Bayesianen danken hun naam aan de 18de eeuwse Britse wiskundige Thomas Bayes, de bedenker van het bekende theorema dat naar hem vernoemd werd. Voor hen staat de statistiek centraal en is machine learning het steeds doorlopen en aanpassen van data op basis van het theorema (31). Het theorema van Bayes zegt:
"($|&) = "($) × "(&|$) / "(&) Of anders:
"(++,-../|011023) = "(++,-../) × "(011023|++,-../)/ "(011023)
De formule implementeren in de computer is echter extreem moeilijk en ondervindt heel wat controverse volgens Domingos: ‘De controverse ligt niet in de formule zelf, maar in de interpretatie van wat de kansen juist betekenen. De meeste statistici zien de kansen als frequenties, zo is de a priori kans op een ziekte de prevalentie in een gegeven populatie. Bayesianen echter zien de a priori kansen eerder als een subjectieve maat van overtuiging. Hierdoor wordt het niet meer dan de voorovertuigingen updaten met nieuwe evidentie tot na-overtuigingen, dit fenomeen is ook gekend als turning the Bayesian crank. Zoals reeds aangehaald werd, is het omzetten van het theorema naar een bruikbaar algoritme voor een computer geen makkelijke zaak. Het grootste probleem kwam door het feit dat er meerdere effecten zijn van een oorzaak die bovendien afhankelijk zijn van elkaar. Dit geeft een explosie aan combinaties die onmogelijk door de computer verwerkt kunnen worden, laat staan uit de data gehaald kunnen worden. In 1973 bedacht men toch een manier om het theorema in computer te implementeren, namelijk de Naïve Bayes classifier.
Naïef staat voor de naïeve assumptie dat de meerdere effecten onafhankelijk zijn van de gegeven oorzaak’ (15,24). Toch levert het model volgens andere onderzoekers verbazend goede resultaten (32).
De precieze werking van de naïve bayes classifier is te mathematisch en zou te ver gaan voor dit werk. Het algemene principe is dat de kans op de oorzaak gegeven bij verschillende effecten apart wordt berekend, vandaar ‘naïeve’ aangezien dit ver van de werkelijkheid ligt, a.d.h.v. data die beschikbaar is in het netwerk. Dit proces wordt telkens herhaald totdat een goed resultaat wordt bekomen.
Zoals de naam zegt, is de naïve Bayes classifier goed in het classificeren van informatie. Zo werd hij gebruikt voor het filteren van spammails uit berichten. In de geneeskunde kan hij vooral gebruikt worden om beslissingen (vb diagnose, therapie) te ondersteunen. (15,24,31-32)
Analogizers
Analogizers zijn ervan overtuigd dat analogie de basis is van het menselijk redeneren. Zo kijken we bij het oplossen van een probleem naar het verleden, herinneren we wat er gebeurde bij welke acties en handelen dan adequaat met een actie die in het verleden tot het gewenste resultaat leidde. Analogizers trachten analogie in een algoritme te gieten.
Het meest eenvoudigste algoritme dat analogizers gebruiken is nearest neighbor. De werking ervan kan volgens Domingos makkelijk begrepen worden aan de hand van een hedendaags voorbeeld dat hij geeft: ‘Stel dat een persoon een nieuwe foto uploadt op facebook en facebook wil weten of er een gezicht opstaat. Het nearest neighbor algoritme zoekt in de gigantische databases aan foto’s die facebook heeft een foto die het meest op de nieuwe foto lijkt (m.a.w. data die het meest op elkaar lijkt), de nearest neighbor. Als die foto een gezicht bevat, dan bevat de nieuw geüploade foto dat ook. Ondanks de zoektocht in potentieel immense database, werkt het algoritme zeer snel en bijzonder efficiënt. Het algoritme kreeg zelfs als bijnaam lazy learning omdat het maar 1 ding doet en dat is de best overeenkomende gelijkenis vinden. Men zegt dat dit het simpelste en snelste algoritme voor machine learning is die ooit werd uitgevonden. Nearest neighbor is echter niet perfect doordat ze enorm vatbaar is voor overfitting: indien een foto verkeerd wordt geclassificeerd alsof er geen gezicht opstaat, worden snel een groot aantal nieuwe foto’s met gezichten ook verkeerd geclassificeerd.
Om het probleem van overfitting tegen te gaan bedacht men het k-nearest algoritme. Als de meest overeenkomende foto ook een gezicht bevat, maar de 2 volgende meest overeenkomende foto’s niet, dan beslist het k-nearest algoritme, hier 3-nearest neighbors, dat de nieuwe foto toch geen gezicht bevat. Dit algoritmes is meer robuust tegen fouten aangezien er meerdere foto’s tegelijk fout geclassificeerd moeten zijn vooraleer een nieuwe foto ook fout wordt geclassificeerd.
In 1994 werd het k-nearest neighbor verder uitgebreid tot het weighted k-nearest neighbor. Hierin worden aan de k meest overeenkomende gevallen een ‘gewicht’ gegeven. Ook dit wordt duidelijker met een hedendaags voorbeeld. Gebruikers van Netflix geven een rating van 1 tot 5 aan films die ze keken. Stel dat Netflix wil weten of Jan film x goed zou vinden, dan zoekt men andere gebruikers waarvan de ratings het meest overeenkomen met die van Jan. Als zij allemaal film x een goede rating gaven, zal Jan hoogstwaarschijnlijk film x goed vinden. Maar niet elke overeenkomst is even sterk, zo moet een sterkere overeenkomst meer waarde krijgen. De overeenkomsten krijgen dus een coëfficiënt, een gewicht, die de sterkte van de gelijkenis vertegenwoordigt. Op die manier kan er een gewogen voorspelling gemaakt worden uit de k meest gelijke overeenstemmingen.’
Ondanks de goede accuraatheid van alle nearest neighbors, kampen ze toch met een groot probleem. Het aantal attributen, voor een online webwinkel bijvoorbeeld elke klik op een item, loopt op tot veel te hoge aantallen. Te grote aantallen waartoe het algoritme niet in staat is. (15,24)
Naast de nearest neighbor hebben de analogizers nog een ander algoritme, de support vector
machines (SVM). Support vector machines classificeren data in 2 klassen en worden daarom ook
binaire classifiers genoemd. In SVM worden datapunten gezien als p-dimensionale vectoren in een p-dimensionale vectorruimte. Vervolgens wordt er gezocht naar een p-1-dimensionaal hypervlak die een scheiding kan vormen tussen de 2 klassen van data. Bij het ingeven van een nieuw datapunt wordt de relatie t.o.v. dat scheidend hypervlak en dus t.o.v. van de klassen geanalyseerd en vervolgens wordt de nieuwe data geclassificeerd in één van beide klassen. (15,33) SVM worden vandaag veelvuldig toegepast voor de classificatie van foto’s, spammails uit uw mailbox te halen, handgeschreven teksten door de computer te doen lezen, etc. In de geneeskunde kan men ze bijvoorbeeld gebruiken om de classificatie van ziektes beter te achterhalen. (15,24)
Combinaties tussen de families
Elk van deze algoritmes heeft zijn voor- en nadelen. Hieruit is het idee ontstaan om er twee of meerdere te combineren. Dikwijls wordt het ene algoritme gebruikt om een probleem op te lossen bij een ander. Er zijn veel combinaties mogelijk en allen hebben ze op hun beurt ook hun sterktes
en zwaktes. (15,24) Een voorbeeld in de medische sector is het voorspellen van de prognose van kritisch zieke patiënten aan de hand van artificiële neurale netwerken met behulp van genetische algoritmes. (34)
Overfitting
Het grootste probleem in machine learning is overfitting. Alle basisalgoritmes van alle vijf de families worden hiermee geconfronteerd.
Een learning algorithm overfits de data als het verbanden vindt die op de gegeven dataset gelden, maar niet kunnen doorgetrokken worden naar een nieuwe dataset of de werkelijkheid. Overfitting treedt op als er te veel hypotheses zijn en niet genoeg data om de juiste te selecteren. Vandaar het grote belang aan gigantische hoeveelheden data. Overfitting komt doordat het aantal hypotheses exponentieel groeit met het aantal attributen (combinatorische explosie). Het aantal mogelijke gevallen van een concept is een exponentiële functie van het aantal attributen en is op zichzelf een exponentiële functie van het aantal mogelijke concepten. Samen wil dit zeggen dat het aantal mogelijke concepten een exponentiële functie is van de exponentiële toename aan attributen. Dit maakt van machine learning een combinatorische explosie van een combinatorische explosie. (15,24,35)
Tot nu toe werd er voor het probleem van overfitting, ondanks het vele onderzoek, nog geen adequate oplossing gevonden. Men zou principieel strenge restricties kunnen opleggen aan het algoritme, maar dit beperkt juist haar sterkste punt (15). Machine learning blijft dus een continue zoektocht naar het evenwicht tussen de hoeveelheid beschikbare data, en dus de hoeveelheid attributen, en het aantal mogelijke hypotheses (22,15, 24,35).
Vraagstelling
Vanwege de toenemende belangstelling voor Artificiële Intelligentie en Big Data van de laatste jaren werd de vraag gesteld om de huidige situatie omtrent het onderzoek naar Artificiële Intelligentie in de geneeskunde te analyseren. Deze masterproef dient als overzicht van de bestaande ontwikkelingen in het onderzoek naar AI en verschaft een kritische blik op de stand van zaken.
Methodologie
Om de huidige situatie omtrent het onderzoek naar AI in de geneeskunde in kaart te brengen werden 5 onderzoeksvragen opgesteld. De onderzoeksvragen werden beantwoord aan de hand van een kwantitatieve analyse van 2 opgestelde databases. De eerste database werd opgesteld uit 1.356 artikels en beantwoordde 4 onderzoeksvragen. De tweede database werd opgesteld uit 40 artikels en beantwoordde 1 onderzoeksvraag. Elke vraag tracht met haar antwoord meer inzicht te geven over het bestaande onderzoek of de tekortkomingen van AI in de geneeskunde.
Onderzoeksvragen
5 onderzoeksvragen werden opgesteld. Elke vraag werd verduidelijkt met een rationale.
Onderzoeksvraag 1:
Welke soorten onderzoek worden er voornamelijk uitgevoerd op het gebied van AI in de geneeskunde?
Rationale:
Deze vraag beoogt een overzicht te geven over de voornaamste soorten onderzoeken omtrent AI in de geneeskunde.
Onderzoeksvraag 2:
In welke disciplines worden AI in de geneeskunde voornamelijk gebruikt?
Rationale:
Deze vraag beoogt een overzicht te geven over de verschillende disciplines waarin AI in de geneeskunde voornamelijk wordt gebruikt. Op deze manier worden disciplines waarin AI verder ontwikkeld werd geïdentificeerd.
Onderzoeksvraag 3:
Zijn er tekorten in het onderzoek naar AI in de geneeskunde?
Rationale:
Deze vraag beoogt na te gaan of er tekorten zijn in het onderzoek van AI in de geneeskunde.
Onderzoeksvraag 3.1:
Rationale:
Deze vraag beoogt de tekorten in het onderzoek van AI in de geneeskunde te identificeren.
Onderzoeksvraag 3.2:
Wat zijn de ontwikkelingen in het belangrijkste tekort van het onderzoek naar AI in de geneeskunde?
Rationale:
Deze vraag beoogt een overzicht te geven van de ontwikkelingen in het belangrijkste tekort van het onderzoek van AI in de geneeskunde. Inzicht in de ontwikkelingen kan helpen met de opzet van verder onderzoek.
Zoekstrategie en zoekcriteria
Voor het zoeken van de artikels werd gebruik gemaakt van de onlinedatabase PubMed. De zoekterm ‘artificial intelligence’ leverde op 17 september 2019 92.945 resultaten en ‘artificial intelligence’ als MeSH-term 87.212 resultaten. Wanneer bij deze laatste zoekterm enkel de resultaten van de laatste 5 jaar werden gevraagd, resulteerde dit in 28.573 resultaten. Vervolgens werd er gezocht door beide MeSH-termen ‘artificial intelligence’ en ‘medicine’ te combineren. Dit leverde 4.875 resultaten. Wanneer deze laatste beperkt werd tot artikels gepubliceerd in de laatste 5 jaar bleven er 1.557 resultaten over. Deze 1.557 resultaten werden geselecteerd voor verdere analyse.
Inclusie- en exclusiecriteria
De 1.557 resultaten werden in een volgende stap onderworpen aan inclusie- en exclusiecriteria. Alle dubbele resultaten, alle opmerkingen of antwoorden op artikels en alle resultaten zonder een volledig verkrijgbaar artikel (via het UGent-account) werden uitgesloten. Vervolgens werden enkel artikels die handelen over AI, zich situeren in de geneeskunde en in het Engels geschreven zijn weerhouden. Dit resulteerde in een selectie van 1.356 artikels. Met deze 1.356 artikels werd een eerste database aangelegd (Figuur 2).
Nadien werd een tweede database opgesteld. Voor de artikels in deze database werden bijkomende criteria opgelegd. De artikels over machine learning algoritmes, de artikels over artificieel intelligente apparatuur en de reviews en inzichten over artificiële intelligentie of machine
learning werden uitgesloten (de tweede database bevat de artikels over het thema dat geselecteerd
Figuur 2: PRISMA Flow Diagram
Classificatieproces
De artikels werden vervolgens geclassificeerd in Microsoft Excel a.d.h.v. hun titel, abstract, introductie en conclusie. In de eerste database werden alle 1.356 artikels 2 maal geclassificeerd. In de tweede database werden alle 40 artikels 5 maal geclassificeerd.
Eerste database
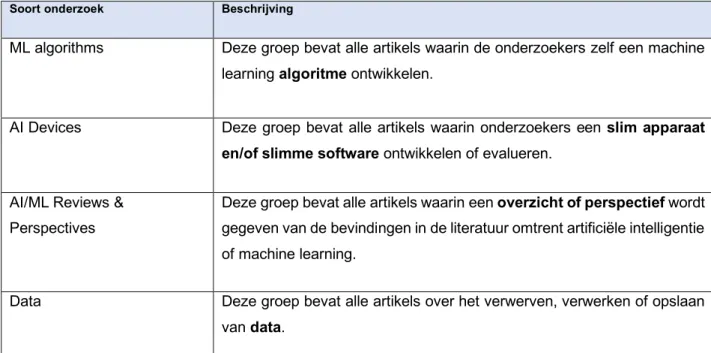
In de eerste database werden de 1.356 artikels eerst verdeeld in 4 groepen naargelang het soort onderzoek: ML algorithms, AI Devices, AI/ML Reviews & Perspectives en Data. Deze worden verder verduidelijkt in tabel 1.
Soort onderzoek Beschrijving
ML algorithms Deze groep bevat alle artikels waarin de onderzoekers zelf een machine learning algoritme ontwikkelen.
AI Devices Deze groep bevat alle artikels waarin onderzoekers een slim apparaat
en/of slimme software ontwikkelen of evalueren.
AI/ML Reviews & Perspectives
Deze groep bevat alle artikels waarin een overzicht of perspectief wordt gegeven van de bevindingen in de literatuur omtrent artificiële intelligentie of machine learning.
Data Deze groep bevat alle artikels over het verwerven, verwerken of opslaan van data.
Tabel 1: eerste classificatie in de eerste database
Deze classificatie beoogt een antwoord te formuleren op de vraag welk soort onderzoek er voornamelijk verricht wordt (onderzoeksvraag 1), of er tekorten zijn in het onderzoek (onderzoeksvraag 3) en welke de tekorten zijn (onderzoeksvraag 3.1).
Vervolgens werden de artikels uit de 4 groepen verder verdeeld naargelang medische discipline of soorten apparatuur. Dit wordt verduidelijkt in tabel 2.
Groep Opdeling
ML algorithms Deze groep werd verder opgedeeld in verschillende medische
disciplines.
AI Devices Deze groep werd verder opgedeeld in verschillende soorten apparatuur.
AI/ML Reviews & Perspectives
Deze groep werd verder opgedeeld in verschillende medische
disciplines.
Data Deze groep werd verder opgedeeld in verschillende medische
disciplines.
Tabel 2: tweede classificatie in de eerste database
Deze classificatie beoogt een antwoord te formuleren op de vraag in welke disciplines AI voornamelijk wordt gebruikt (onderzoeksvraag 2).
Tweede database
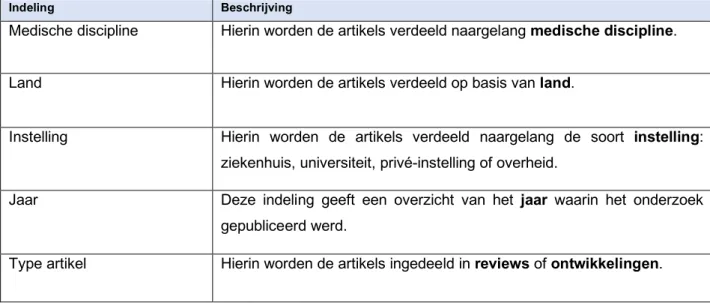
De tweede database bestaat uit de artikels die geïdentificeerd werden uit de eerste database als belangrijkste tekort (onderzoeksvraag 3). Deze 40 artikels werden verder geclassificeerd naargelang medische discipline, land, instelling, jaar en type onderzoek. Dit wordt verduidelijkt in tabel 3.
Indeling Beschrijving
Medische discipline Hierin worden de artikels verdeeld naargelang medische discipline. Land Hierin worden de artikels verdeeld op basis van land.
Instelling Hierin worden de artikels verdeeld naargelang de soort instelling: ziekenhuis, universiteit, privé-instelling of overheid.
Jaar Deze indeling geeft een overzicht van het jaar waarin het onderzoek gepubliceerd werd.
Type artikel Hierin worden de artikels ingedeeld in reviews of ontwikkelingen.
Tabel 3: de 5 classificaties in de tweede database
Deze classificatie beoogt een overzicht te creëren van de ontwikkelingen in het belangrijkste tekort (onderzoeksvraag 3.2).
Data-analyse
Om de onderzoeksvragen te beantwoorden werden de 2 databases achtereenvolgens geanalyseerd.
De gegevens uit de eerste database werden gevisualiseerd en geïnterpreteerd met Microsoft Excel. Op die manier werd een antwoord geformuleerd op de vragen: welke soort onderzoek wordt het meest uitgevoerd, in welke discipline wordt er meest onderzoek verricht, zijn er tekorten in het onderzoek en welke zijn die.
De gegevens uit de tweede database werden gevisualiseerd en geïnterpreteerd met Microsoft Excel en het softwarepakket R, daar dit meer mogelijkheden heeft om complexere relaties te zien. Op die manier werd een overzicht gecreëerd van de ontwikkelingen van het grootste tekort.
Samenvatting methodologie
Allereerst werd het doel bepaald en de onderzoeksvragen opgesteld. Vervolgens werden in PubMed 1.557 artikels van de laatste 5 jaar met de MeSH-termen ‘Artificial Intelligence’ en ‘Medicine’ geselecteerd. Hiervan werden 201 artikels uitgesloten. De resterende 1.356 artikels werden in een eerste database ingedeeld op basis van soort onderzoek en discipline. Deze database werd geanalyseerd. Hierdoor werden de eerste 4 onderzoeksvragen beantwoord, alsook het grootste tekort geïdentificeerd. Van dit grootste tekort werd vervolgens een tweede database opgesteld van 40 artikels. De analyse hiervan creëerde een overzicht van de recente ontwikkelingen in dit grootste tekort.
Resultaten
De resultaten uit de analyse van de 2 databases werden gekoppeld aan de relevante onderzoeksvragen. Zo leverde de eerste database antwoord op onderzoeksvraag 1, 2, 3 en 3.1 en leverde de tweede database antwoord op onderzoeksvraag 3.2.
Onderzoeksvraag 1: soorten onderzoek
De 4 groepen, waarin de 1.356 resultaten in de eerste database werden ingedeeld, vertegenwoordigen 4 grote soorten onderzoek naar AI in de geneeskunde.
In 45,7% van de artikels werd onderzoek verricht naar de ontwikkeling of evaluatie van een slim apparaat en/of slimme software (AI Devices). In 28% van de artikels ontwikkelden onderzoekers zelf een machine learning algoritme. 23,4% van de artikels bestond uit reviews of inzichten. 2,9% van de artikels ging over het opslaan, verwerven en/of verwerken van data.
Deze resultaten geven aan dat de laatste 5 jaar het meest onderzoek verricht werd naar de ontwikkeling of evaluatie van slimme apparaten en/of slimme software.
Onderzoeksvraag 2: disciplines
De 1.356 artikels werden binnen de 4 groepen soorten onderzoek verder verdeeld naargelang medische discipline of soorten apparatuur.
In de groep waar onderzoekers zelf een machine learning algoritme ontwikkelden (ML Algorithms) vertegenwoordigde de algemene discipline automated search 10,6% van de artikels en de discipline oncology 9%. In de groep waar onderzoek verricht werd naar de ontwikkeling of evaluatie van een slim apparaat en/of slimme software (AI Devices) ging 60% van de artikels over
rehabilitation robots. Radiology was de grootste discipline met 22,1% van de artikels uit de groep
met reviews of inzichten in AI en Big Data (AI/ML Reviews & Perspectives). General Medicine en
oncology vertegenwoordigen respectievelijke 18,9% en 5,4% van de artikels uit diezelfde groep. In
Grafiek 1: verdeling ngl. soort onderzoek
de groep over het opslaan, verwerven en/of verwerken van data (Data) vertegenwoordigde Health
informatics het grootste deel met 55% van de artikels, gevolgd door Oncology met 30%.
Worden de totale aantallen met elkaar vergeleken, dan wordt
Rehabilitation de grootste discipline met 28,5% van het totale
aantal artikels, radiology de tweede grootste discipline met 6,9% van het totale aantal artikels en oncology de derde grootste discipline met 4,7% van het totale aantal artikels.
General Medicine, Automated search en health informatics
vertegenwoordigen respectievelijk 4,4%, 3% en 1,6% van het totale aantal artikels.
Deze resultaten geven aan dat de laatste 5 jaar het meeste onderzoek verricht werd in de discipline revalidatie, gevolgd door de discipline radiologie en de discipline oncologie.
Onderzoeksvraag 3: tekorten
De analyse van de eerste database gaf aan dat er op verschillende niveaus minder onderzoek verricht werd.
Onderzoeksvraag 3.1: identificatie van de tekorten
2,9% van de artikels ging over het opslaan, verwerven of verwerken van data. Vergeleken met de percentages van de andere soorten onderzoek (AI Devices 45,7%; ML Algorithms 28%; AI/ML Reviews & Perspectives 23,4%) is dit duidelijk het minst.
Over de implementatie van AI en Big Data werd 1 artikel (0,07%) geschreven, over de rol van de overheid 3 artikels (0,2%) en over sociale, ethische en veiligheid gerelateerde reflecties 20 artikels (1,5%).
De medische disciplines die het minst aan bod kwamen (0,4%) waren: nefrologie, endocrinologie, geriatrie, gynaecologie, neus-keel-oorziekten en gastro-enterologie.
De resultaten geven aan dat de laatste 5 jaar minder onderzoek werd verricht naar het opslaan, verwerven of verwerken van data; naar de implementatie van AI, de rol van de overheid en sociale, ethische en veiligheid gerelateerde onderwerpen. De disciplines die het minst aan bod kwamen
zijn nefrologie, endocrinologie, geriatrie, gynaecologie, neus-keel-oorziekten en gastro-enterologie.
Aangezien data en het beheren ervan een heel belangrijk onderdeel is van Artificiële Intelligentie (4) en er duidelijk minder geschreven werd over dit thema, werd besloten dit te beschouwen als het belangrijkste tekort.
Onderzoeksvraag 3.2: ontwikkelingen van het belangrijkste tekort
Na het identificeren van het belangrijkste tekort uit de eerste database werden de 40 artikels over data in de tweede database geclassificeerd. Uit de analyse hiervan werden 5 ontwikkelingen gehaald:
1. In 55% van de gevallen werkten health informatics aan het onderzoek. In 37,5 % werd er tussen verschillende medische disciplines samengewerkt. (Grafiek 3.1)
2. Het meeste onderzoek (62,5%) werd verricht in de VS, gevolgd door het Verenigd Koninkrijk (25%). In 9% van de publicaties werd er samengewerkt tussen auteurs van verschillende landen. (Grafiek 3.2)
3. In 55% van de publicaties werd het onderzoek verricht door 1 universiteit. Aan 40% van de publicaties werd er door verschillende instellingen samengewerkt. (Grafiek 3.3)
4. Er is een toename van het aantal publicaties van 2014 tot 2018. (Grafiek 3.4)
5. In 60% van de publicaties werd door de onderzoekers iets ontwikkeld. In 70,8% van de publicaties betreffende een ontwikkeling, werd er samengewerkt tussen onderzoekers uit verschillende instellingen. Bij de overzichtsartikels werd 62,5% geschreven door auteurs van 1 instelling. (Grafiek 3.5)
Deze 5 ontwikkelingen geven een overzicht van het onderzoek naar data van de afgelopen 5 jaar. Ze kunnen gebruikt worden voor de opzet van verder onderzoek naar het opslaan, verwerven of verwerken van medische data.
Discussie
Slechts 1 artikel met dezelfde opzet en hetzelfde doel als deze masterproef werd gevonden. Dit artikel werd recent in pre-release gepubliceerd en beschreef de resultaten van een knowlegde mapping van 2.421 artikels van het jaar 2013 tot 2019 omtrent het onderzoek naar AI en Big Data in de gezondheidssector (36). De resultaten van deze masterproef werden met deze knowlegde mapping en andere relevante studies vergeleken.
Onderzoeksvraag 1: soorten onderzoek
De resultaten geven aan dat de laatste 5 jaar het meeste onderzoek verricht werd naar de ontwikkeling of evaluatie van slimme apparatuur en/of slimme software. Indien de artikels uit deze groep verder worden geanalyseerd, wordt duidelijk dat meer dan 50% van de artikels over
rehabilitation robots handelen. Het onderzoek naar deze rehabilitation robots begon reeds voor de
recente hipe van AI in de geneeskunde. Sinds de jaren 70 van de vorige eeuw neemt het onderzoek naar rehabilitation robots progressief toe. Het is sindsdien een studiegebied waarin heel wat wetenschappers en bedrijven onderzoek verrichtten. De toenemende interesse voor rehabilitation
robots is te wijten aan de sterk toenemende nood aan geavanceerde revalidatietechnieken van de
steeds vergrijzende populatie (37).
Indien bij de resultaten van deze masterproef de artikels over rehabilitation robots niet worden meegeteld, wordt de volgende verdeling bekomen: 35% van publicaties handelen over machine
learning models, 25% zijn reviews en meningen en 20% beschrijft een slimme apparatuur of
software. Deze verdeling komt overeen met de actuele trend die in dit onderzoeksdomein heerst (36).
Onderzoeksvraag 2: discipline
De resultaten gaven aan dat de laatste 5 jaar voornamelijk onderzoek verricht werd in de disciplines revalidatie, radiologie en oncologie. Verder nazicht van het soort onderzoek toont aan dat het grote aantal onderzoeken in de discipline revalidatie kan worden toegeschreven aan de ontwikkeling van
rehabilitation robots. Zoals in de discussie van onderzoeksvraag 1 (cfr. supra) werd verduidelijkt,
is dit een onderzoekdomein waar reeds voor de recente hipe van AI en Big Data veel onderzoek naar verricht werd (37).
Het onderzoek in de discipline radiologie bestaat voor 75% uit Reviews & Perspectives. Een reden voor dit grote percentage kan zijn dat de ontwikkeling van AI in de radiologie al verder staat en er de laatste 5 jaar bijgevolg meer nood was aan overzichtsartikels. En andere reden kan zijn dat er door de vele beweringen, waarin er geopperd wordt dat AI en Big Data radiologen in de toekomst overbodig maken, nood was aan perspectief (38,39). Een antwoord daarop werd al door veel onderzoekers gegeven: geen ‘replacement’ wel ‘engagement’. (36,38,40).
In de discipline oncologie zijn de soorten onderzoeken die verricht worden meer gelijk verdeeld. Zo komt oncologie het tweede meest voor bij het onderzoek naar het ontwikkelen van machine
learning algoritmes en bij het onderzoek naar het opslaan, verwerven of verwerken van data. Bij
de groep van reviews en perspectieven komt oncologie het derde meest voor. Volgens vele onderzoekers is ook oncologie een discipline waar consistent veel onderzoek verricht wordt naar AI (36,41). De discipline oncologie moet hier wel in een brede zin geïnterpreteerd worden: van het ontstaan tot de diagnose en therapie van kanker. Zo kan AI gebruikt worden in de vorm van
machine learning algoritmes voor het vinden van geassocieerde genmutaties, het stellen van een
diagnose op histologische coupes, het zoeken naar een specifieke target therapie, etc.
Hoewel neurologie en cardiologie ook disciplines zijn met veel onderzoek naar AI (36,41), kwamen ze in deze masterproef niet frequenter voor. Slechts 2,1% van het totale aantal in deze masterproef geanalyseerde artikels werd ingedeeld in de discipline cardiologie en 1,3% in de discipline neurologie. Deze lage percentages kunnen te wijten zijn aan de aard van de indeling van de groep
AI Devices. Deze groep werd ingedeeld naargelang soorten devices en niet naargelang discipline.
In deze groep is het dus mogelijk dat bijvoorbeeld de onderdelen telemedecine of apps/software artikels bevatten uit de discipline cardiologie en de onderdelen rehabilitation robots of
telerehabilitation artikels bevatten uit de discipline neurologie. Bijgevolg werden deze artikels, die
in se wel behoren tot een medische discipline, niet meegeteld bij de telling van het aantal artikels per discipline wat tot een lager percentage leidt van deze disciplines.
Het substantiële aantal artikels over automated search in de groep waar onderzoekers zelf een
machine learning algoritme ontwikkelden ligt in de lijn van de belangstelling naar het onderzoek
van natural language processing in de geneeskunde (41).
Het hoge percentage artikels uit de discipline health informatics in de groep Data is logisch te verklaren door de nood aan health informatics bij bijvoorbeeld het maken van een database of een elektronisch patiëntendossier.