AUTOMATIC DETECTION OF
SENTIMENT AND STANCE IN
Aantal woorden: 23.713
Joeran De Jaeghere
Studentennummer: 01514832Begeleider: Prof. dr. Els Lefever
Masterproef voorgelegd voor het behalen van de graad van master in de meertalige communicatie
De auteur en de promotor(en) geven de toelating deze studie als geheel voor consultatie beschikbaar te stellen voor persoonlijk gebruik. Elk ander gebruik valt onder de beperkingen van het auteursrecht, in het bijzonder met betrekking tot de verplichting de bron uitdrukkelijk te vermelden bij het aanhalen van gegevens uit deze studie.
The introduction and expansion of the World Wide Web has allowed policy makers and large enterprises to collect vast amounts of useful information on their customers’ opinions. In light of this observation, the Natural Language Processing (NLP) research has grown accordingly by creating computational techniques that help cope with the increasingly large datasets. The aim of this research was to create and evaluate a supervised machine learning system that would attempt to automatically label sentiment and stance for 500 English tweets on the topic of the Battlefield V controversy. As this controversy clearly divided the target audience into the ‘#everyonesbattlefield’ and ‘#notmybattlefield’ group, we explored how these hashtags as well as various paralinguistic mechanisms influenced the classifier’s performance. From our research, we uncovered that the system performs fairly well with an accuracy score of 0.72 for both sentiment and stance detection. However, with an f-score of 0.45 for sentiment and 0.46 for stance, our system appeared to be biased towards the ‘negative’ sentiment label and the ‘in favour’ label for stance. Furthermore, while the inclusion of the two hashtags barely influenced the classifier’s performance, both capitalisation and emoticons appear to enhance the stance detection process. Nonetheless, expanding the size of the dataset and adding additional features may yield more meaningful and fruitful results.
First and foremost, I would like to express my deepest gratitude and appreciation to my supervisor, Prof. Dr. Lefever for giving me the opportunity to immerse myself into a topic which really sparks my interest. Her constructive feedback, accessibility and deep knowledge of the subject have guided me through my Master’s thesis and have made this a tolerable and enlightening experience.
Next, I would also like to show my gratitude to my fellow colleague Milan Pollet for helping me with any of my questions as well as encouraging me throughout this entire Master’s thesis. Lastly, I wish to pay my special regards to Bethsabee Lampaert for her continuous support when writing my thesis. Her words of encouragement were key in the completion of this project.
The outbreak of the coronavirus had a huge impact worldwide. However, in terms of my Master’s thesis, I do not feel as if I was affected that much by the virus. It is true that I was no longer able to physically meet with my supervisor, Prof. Dr. Lefever, but we quickly shifted our communication to e-mails and Skype. In my opinion, this did not change the situation much as my supervisor still responded to all my questions and uncertainties. Additionally, she also delivered all the data I needed to complete my research through e-mail and offered me the opportunity to call via Skype should I have any further questions. For that reason, I would also like to thank her for her accessibility and for adapting so quickly to this exceptional situation.
This preamble was drawn up in consultation between the student and the supervisor and was approved by both parties.
List of abbreviations ... 1
List of tables and figures ... 2
1. Introduction ... 3
2. Related research ... 6
2.1 Sentiment Analysis ... 6
2.1.1 General overview ... 6
2.1.2 Affect, emotion and mood ... 7
2.1.2.1 State of mind ... 8
2.1.2.2 Affect, emotion and mood in sentiment analysis ... 8
2.1.2.3 The cognitive gap ... 11
2.2 Stance Detection ... 11
2.3 Sentiment and stance classification techniques... 13
2.3.1 Unsupervised and semi-structured machine learning ... 14
2.3.2 Supervised machine learning ... 15
2.3.2.1 Collecting the dataset ... 16
2.3.2.2 Data preparation and pre-processing ... 17
2.3.2.3 Feature extraction ... 20
2.3.2.4 Algorithm selection and evaluation ... 22
3. Methodology ... 25
3.1 Topic motivation ... 25
3.2 Data collection process ... 26
3.3 Experimental approach ... 29
4. Results and Discussion ... 37
4.1 The manually annotated corpus ... 37
4.1.1 Sentiment analysis in the MA corpus... 37
4.1.2 Stance detection in the MA corpus ... 40
4.1.3 Comparison between sentiment and stance in MA corpus ... 41
4.1.4 The distribution of the paralinguistic mechanisms ... 42
4.2 Performance of the machine learning system ... 45
4.2.1 Results sentiment analysis for the machine learning system ... 46
4.2.2 Results stance detection for the machine learning system ... 50
4.2.3 Comparison results sentiment analysis and stance detection ... 54
4.3 Analysis of the automatically labelled corpus ... 55
4.4 Special case: the machine learning system that includes hashtags ... 61
4.4.1 Comparing and evaluating the machine learning systems ... 61
4.4.2 Results and comparison for automatic sentiment and stance labelling with hashtags ... 64
4.5 The error analysis ... 68
4.5.1 The influence of the paralinguistic mechanisms ... 68
4.5.2 Bias towards certain stance and sentiment labels ... 71
4.5.3 The inclusion of hashtags ... 72
4.5.4 The influence of curse, swear or blame words ... 72
5. Conclusion and suggestions for future research... 74
6. Bibliography ... 78
LIST OF ABBREVIATIONS
BFV = Battlefield V WWW = World Wide Web
ABSA= Aspect-Based Sentiment Analysis
EARL = Emotion Annotation and Representation Language SVM = Support vector machines
NLP = Natural Language Processing PMI = Pointwise mutual information POS = Part-of-speech tagging
OSH = Optimal separating hyperplane FPS = First-person shooter
SJW = Social justice warrior TP = True positives TN = True negatives FP = False positives FN = False negatives MA = Manually annotated ML = Machine learning
APL = Average score per label TA = Total average
LIST OF TABLES AND FIGURES
Table 1: The emotion and representation language by HUMAINE (2006) ... 9
Table 2: The most important search terms used to collect the dataset ... 27
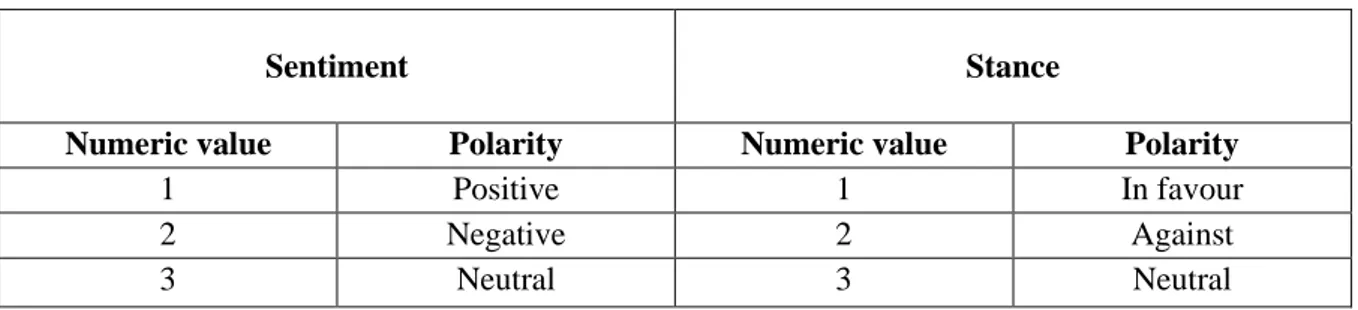
Table 3: Visualisation of numeric values 1-3 and their corresponding annotated label ... 30
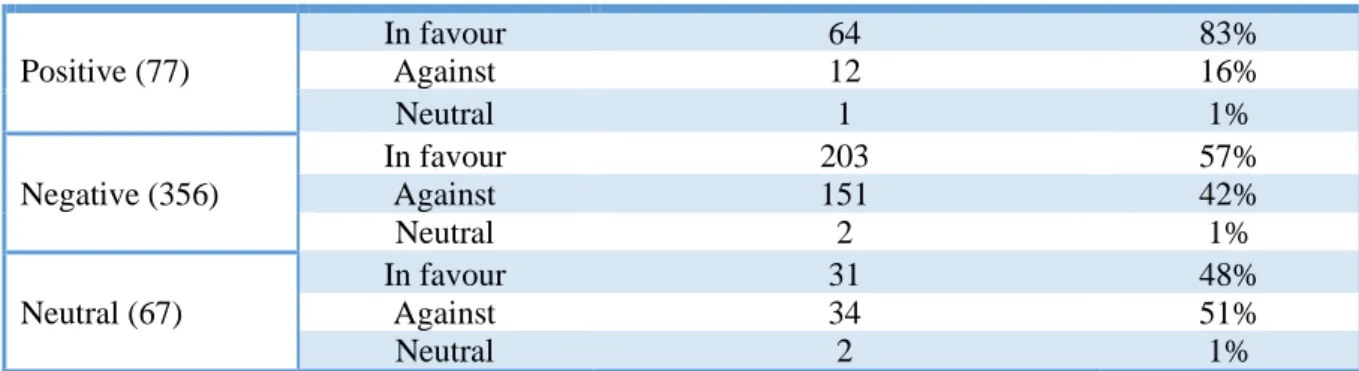
Table 4: Distribution of sentiment and stance in MA corpus in numbers and percentages ... 42
Table 5: Results of the 10-fold cross validation method with regards to sentiment analysis ... 48
Table 6: The total average score and average score per label for all 4 evaluation metrics (sentiment) ... 49
Table 7: Comparison of the gold standard for sentiment and the predicted labels by the machine learning system ... 50
Table 8: Results of the 10-fold cross validation method with regards to stance detection ... 52
Table 9: The total average score and average score per label for all 4 evaluation metrics (stance) ... 53
Table 10: Comparison of the gold standard for stance and the predicted labels for the machine learning system53 Table 11: Comparison of the total average and average per label for sentiment and stance for the machine learning system ... 55
Table 12: Distribution of sentiment and stance for the machine learning system in numbers and percentages ... 61
Table 13: Results of the 10-fold cross validation method with regards to sentiment analysis (with hashtags) .... 62
Table 14: Results of the 10-fold cross validation method with regards to stance detection (with hashtags) ... 63
Table 15: Comparison of the total average score and average score per label for all 4 evaluation metrics for both corpora ... 64
Table 16: Distribution of sentiment and stance for the machine learning system (with hashtags) in numbers and percentages... 68
Figure 1: Sentiment classification techniques (Serrano-Guerrero, Olivas, Romero & Herrera-Viedma, 2015) ... 14
Figure 2: The process of supervised machine learning (Kotsiantis, Zaharakis & Pintelas, 2007) ... 16
Figure 3: Pre-processing in sentiment analysis (Singh & Kumari, 2016) ... 18
Figure 4: The margin on either side of the hyperplane (Bhavsar & Ganatra, 2012) ... 23
Figure 5: Searching for the optimal separating hyperplane (Bhavsar & Ganatra, 2012) ... 23
Figure 6: Illustration of the k-fold cross validation technique (Boehmke & Greenwell, 2020) ... 24
Figure 7: Visualisation of the formulae used to calculate the 4 metrics (Dai et al., 2016) ... 36
Figure 8: The results of the sentiment analysis for the MA corpus ... 38
Figure 9: Results of the stance detection of the MA corpus ... 40
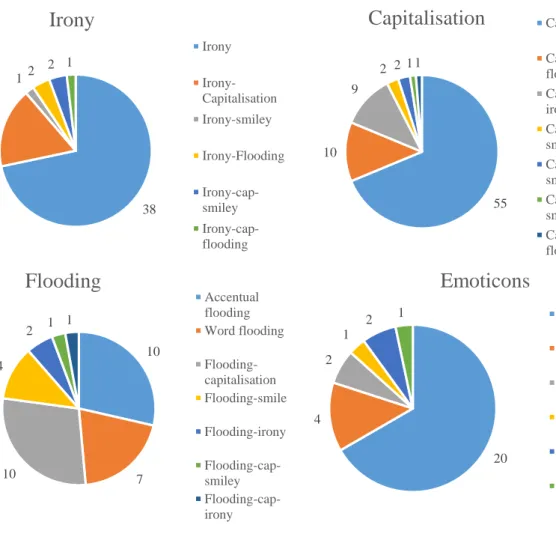
Figure 10: The distribution of the paralinguistic mechanisms ... 43
Figure 11: The results of the sentiment analysis for the machine learning system ... 56
Figure 12: The results of the stance detection for the machine learning system... 59
Figure 13: The results of the sentiment analysis for the machine learning system (with hashtags) ... 65
Figure 14: The results of the stance detection for the machine learning system (with hashtags) ... 65
Figure 15: The number of correctly and incorrectly labelled instances for each separate paralinguistic mechanism with regard to sentiment ... 70
Figure 16: The number of correctly and incorrectly labelled instances for each separate paralinguistic mechanism with regard to stance. ... 71
1. INTRODUCTION
Large enterprises and policy makers have always tried to gather as much data on their customers as possible. The most common way to do so, was through manually distributing surveys to the public. However, due to the technological advancements of the 21st century, technology has become omnipresent in society. Consequently, companies have had to evolve and adapt to the expanding technological market. With the introduction of the World Wide Web (WWW), companies were faced with a new means of not only distributing, but also collecting large amounts of data. Moreover, this entailed drastic changes to the term ‘survey research’, as surveys were no longer limited to manual distribution or via phone or e-mail (Solomon, 2000).
The ever-expanding amounts of data the companies collect through the WWW, is often referred to as big data. Even though there are many different points of view on how to define the term, Laney (2001) attempted to explain the term by introducing the 3V model, which refers to volume, velocity and variety. However, as technology improves and expands, so does big data. Many researchers (Koseleva & Ropaite, 2017; Zhou, Fu & Yang, 2016) have adapted the 3V model into the 4V model by adding another dimension (value) or they have simply adopted another model (the 3E model) to define the term big data. Nevertheless, this study will make use of the 5V model (Ishwarappa & Anuradha, 2015; Yin & Kaynak, 2015) to define the term. This model consists of 5 different elements: (1) Volume: the amount of data generated by customers, (2) Velocity: refers to the speed at which all the data is generated, processed and analysed, (3) Variety: implies whether the data is structured or unstructured, (4) Veracity: refers to the quality of the dataset, (5) Value: whether or not the valuable data can be extracted from the large amounts of big data.
While the technological advancements have helped large enterprises and policy makers with distributing and gathering large amounts of data from the WWW, these enterprises still lack the time to manually analyse all the data. In light of this observation, the Natural Language Processing (NLP) research has improved drastically over the past decennia to help these enterprises cope with the increasing amounts of data. NLP can be defined as the research field that “employs computational techniques for the purpose of learning, understanding, and producing human language content” (Hirschberg & Manning, 2015, p. 261).
The explosive growth of social media has greatly increased the amount of valuable data large organisations have to process. If these companies know their customers’ opinions and points of view on certain topics, they can distribute their advertisements and communication more adequately. Therefore, researchers are attempting to automate the detection of sentiment in messages, as well as a person’s opinion (stance) in social media texts through a machine learning tool. Sentiment analysis implies determining the polarity (positive, negative or neutral) of, for example, a tweet, while stance detection attempts to detect whether a person is in favour, against or neutral towards a certain proposition (Mohammad, Sobhani & Kiritchenko, 2017). This study focuses on the automatic detection of sentiment and stance on social media and more specifically, Twitter. In order to do so, we have manually labelled sentiment and stance in 500 English tweets taken from Twitter. Next, we will train a machine learning tool and let the system automatically label sentiment and stance in the same 500 tweets. To evaluate the performance of the machine learning system, the predicted labels are compared with the manually annotated labels by means of a 10-fold cross validation method (cf. section 4.2 and 4.3). Additionally, we will also evaluate the effects of the hashtags ‘#everyonesbattlefield’ and ‘#notmybattlefield’ on the performance of the classifier by training two versions of the system: one version including and another version excluding these hashtags in the corpus. The next step is to compare the labels for both the manually and automatically annotated tweets. It is important to note that this study takes into account various paralinguistic mechanisms, such as capitalisation, flooding, etc., which can complicate or facilitate the process of correctly predicting sentiment and stance by a machine learning tool (Cambria, Bandyopadhyay & Feraco, 2017). The mechanisms employed for this study will be explained in more detail in the methodology (cf. section 3.3). Before being able to determine sentiment and especially stance, it is essential to formulate a certain (controversial) question to which a person can either agree, disagree or have no opinion towards. For this study, the questions are as follows:
- Are you in favour or against female characters in video games and more specifically, Battlefield V?
- Do you find female characters in Battlefield V historically accurate as the scenery takes place during WWII?
After gathering and analysing the results, the aim of this study is to answer the following research questions:
- Is it possible to automatically detect sentiment and stance accurately with a machine learning tool?
- How do certain paralinguistic mechanisms (flooding, irony, emoticons, capitalisation, etc.) influence the classification of sentiment and stance by a machine learning tool?
In order to fully comprehend sentiment analysis and stance detection, there are various terms, metrics, concepts, etc. that need to be discussed and explained. Furthermore, it is also essential to elaborate on the more recent research regarding sentiment and stance in order to get a grasp of what this field of study has accomplished so far. For that reason, we will provide a theoretical background to support this study in chapter 2. This chapter will consist of a detailed explanation of sentiment analysis, stance detection and the machine learning process. Next, we will turn our attention to the methodology in section 3 to inform the reader on the details of how this research was conducted. In other words, this chapter encompasses the data creation and machine learning setup before moving on to the actual research and discussion in chapter 4. The aim of this chapter is to evaluate the performance of the machine learning system (with and without hashtags) by comparing the predicted labels with the manually annotated corpus. Finally, we will draw a conclusion from the most relevant findings of this study. Please note that the entire corpus can be found in the appendix (cf. section 7).
2. RELATED RESEARCH
2.1 Sentiment Analysis
2.1.1 General overview
Sentiment analysis, often referred to as opinion mining¸ analyses people’s sentiment – opinions, attitudes, emotions, etc. – towards a certain proposition, which can range from products, to other individuals, to certain events or issues (Liu, 2012). Sentiment can be analysed by determining the polarity (positive, negative, neutral) of a certain entity. While there are different synonyms for sentiment analysis (opinion mining, sentiment mining, subjectivity analysis, etc.), this study will only refer to the term ‘sentiment analysis’. Furthermore, Liu (2012) explains how there are three different levels at which you can investigate sentiment: (1) document level, (2) sentence level and (3) entity and aspect level. (1) At document level, it is important to analyse the document as a whole and, therefore, also determine the polarity of the document as a whole. This way, a review, for example, is simply perceived as positive or negative (or neutral). (2) Determining the polarity of each sentence separately and no longer as a whole text, is called sentiment analysis on sentence level. On this level, sentences can be divided into two categories (Wiebe & Riloff, 2005): objective sentences, which provide only factual information, and subjective sentences, which express a person’s opinion or point of view. To determine the polarity of a text on sentence level, it is important to first decide whether a sentence is objective or subjective. Objective sentences are perceived as neutral and do not influence the overall polarity, whereas subjective sentences express a positive or negative sentiment. After the tool has defined each sentence’s polarity separately, the polarity that has appeared most frequently is proclaimed as the overall polarity of the document. (3) Nonetheless, neither document nor sentence level analyses are as fine-grained in terms of uncovering sentiment information as sentiment analysis on entity and aspect level. Sentiment analysis at this level is also often referred to as ABSA or Aspect-Based Sentiment Analysis. According to Liu (2012), on entity and aspect level, every opinion can be divided into the opinion itself (target) and the sentiment towards it (positive, negative, neutral). To explain this idea more in detail, we will analyse and employ this idea on an example, tweet 28, from the manually annotated corpus:
“Battlefield 1 was great and I feel #BattlefieldV just adds to that already established gem. Plus women characters makes me happy. The #NotMyBattlefield incels will just have to deal.” Old Man Ocey (2018)
After analysing the sentence, it is clear that there are 4 target opinions: ‘Battlefield 1’, ‘#BattlefieldV’, ‘women characters’ and ‘#Notmybattlefield incels’. On entity and aspect level, each target opinion will be annotated with its own sentiment. In this example, 3 target opinions can be considered positive as the words: ‘great’, ‘adds to’, ‘established gem’, ‘happy’, clearly refer to the first three targets. However, ‘#NotmyBattlefield incels’ can be labelled as negative as the following phrase ‘will just have to deal’ expresses a negative sentiment. Furthermore, in this example, the target itself ‘#NotmyBattlefield incels’ conveys a negative sentiment, which is not the case with the other three targets as they do not express any sentiment.
Nonetheless, not all sentences can be labelled as easily as the previous sentence. Determining sentiment as we did in the previous example is not as straightforward and could cause a whole variety of problems, some of which we will further elaborate on in chapter 3.2. Furthermore, it is important to note that all 500 tweets for this study were manually annotated on tweet level. In other words, these tweets were manually annotated based on the overall sentiment and stance that they evoked, not based on the sentiment or stance that every sentence or entity conjured up separately.
2.1.2 Affect, emotion and mood
Affect, emotion and mood are 3 key concepts for (automatic) sentiment analysis. However, these concepts are present in various different fields of study such as psychology, sociology, etc. We will therefore first discuss what these concepts entail for this study, before applying them to sentiment analysis. Lastly, we will also discuss the cognitive gap and how it affects sentiment analysis. We will use the book, A Practical Guide to Sentiment Analysis, by Cambria, Bandyopadhyay & Feraco (2017) as our key source of information.
2.1.2.1 State of mind
Before we can discuss how these 3 concepts influence sentiment analysis, we must first provide a clear definition of affect, emotion and mood. All three of the following definitions were gathered from the Merriam-Webster dictionary1. (1) Affect can be defined as “the conscious subjective aspect of an emotion considered apart from bodily changes”. (2) Emotion is “a conscious mental reaction (such as anger or fear) subjectively experienced as strong feeling usually directed towards a specific object and typically accompanied by physiological and behavioural changes in the body”. (3) Lastly, mood is “a conscious state of mind of predominant emotion”.
Even though these definitions give an idea of what these concepts entail, it does not provide us with a clear distinction. However, affect, emotion and mood have been studied extensively in the field of psychology. According to Russell (2003), the concept of affect can be compared to the feeling of fear (in the mind) a person has when watching a scary movie. However, when a person’s mind has also processed this feeling of fear and has converted it to body language, than this fear can be perceived as emotion. Lastly, mood is very similar to emotion, yet there is a small difference. Emotion usually only lasts for a small amount of time and is clearly visible, while mood is a feeling a person wakes up with, for example, happiness. Therefore, it is also less easy to determine a person’s mood.
2.1.2.2 Affect, emotion and mood in sentiment analysis
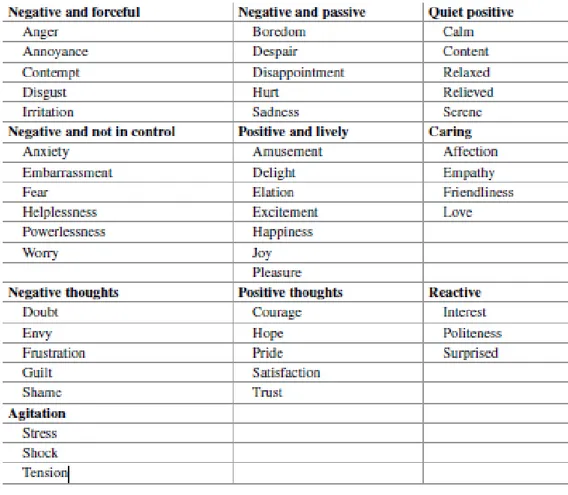
As discussed in 2.1.1, sentiment analysis is based on determining the polarity (positive or negative) of certain subjective words or sentences. However, there are means to aid an NLP tool in determining which sentiment a certain word or sentence conveys and what sentiment it should attribute to that word or sentence. EARL, the Emotion Annotation and Representation Language¸ has set up a table (Table 1) which classifies a wide variety of emotions and what sentiment they usually convey (HUMAINE, 2006). It is important to note that some emotions, such as surprise or politeness, are more difficult to annotate than other emotions. As mood is
very similar to emotion, the words used to express a person’s mood are comparable to those used to express emotions. Therefore, table 1 is also relevant for determining mood.
After discussing how affect, emotion and mood influence people’s state of mind, it is time to turn our attention to the linguistic effect of these 3 concepts on sentiment analysis. Humans have two ways of expressing themselves: oral and written communication. During oral communication we can observe a person’s body language and facial expression. This is, however, not relevant for this study. Therefore, we will take a closer look at how people express their emotions in writing. Similar to Brody & Diakopoulos (2011), whose study we discussed in 2.1.2, and Davidov, Tsur & Rappoport (2010), Cambria, Bandyopadhyay & Feraco (2017) address the fact that flooding and emoticons express a certain subjectivity. Additionally, they state that other paralinguistic mechanisms, such as punctuation and capitalisation, also express a subjective voice. Furthermore, a person’s emotion or mood is often expressed through grammatical and lexical expressions (Boiy, Hens, Deschacht & Moens, 2007; Cambria, Bandyopadhyay & Feraco, 2017). We will now discuss 6 different forms of expressing emotions through these grammatical and lexical expressions, providing an example from our
own corpus as explanation. The following 6 items clearly express or amplify a sentiment and can therefore aid a machine learning system when labelling a tweet with regard to sentiment:
• Through basic emotion words (also called sentiment words or opinion words) or phrases which express a certain feeling, such as those discussed in table 1.
Example (tweet 1): “I really hope Battlefield fails …” • Describing emotion-related behaviour.
Example (tweet 132): “Also, please dont include silly customization like in the trailer. we dont want to see mad max, god of war, and solid snake. THAT ruins immersion. NOT THE FEMALE. LISTEN TO ME DICE. THIS ISN'T FORTNITE. F$$$ THAT GAME!!!”
This person clearly becomes angry (capitalisation, swearing, flooding) after thinking about the trailer for Battlefield V.
• Using intensifiers to strengthen one’s argument.
Example (tweet 157): “Yes we should clearly accept a game that changes history just to force diversity and a political agenda down our throats.”
• Using superlatives to strengthen one’s argument.
Example (tweet 296): “EA CCO Patrick Soderlund with the best possible comments on Battlefield V’s diversity. It’s about time that misogynists felt ostracised rather than women themselves.”
• Using pejoratives or sarcasm.
Example (tweet 5): “I actually appreciate what EA/Dice did with BFV. They saved me 100 bucks this time around.”
• Using swear, curse or blame words.
Example (tweet 36): “The trend of gamers being butthurt by reveals leading to things such as #NotMyBattlefield and #NotMyPokemon is just ridiculous. If you are offended by a women on the cover of Battlefield V or Pokemon trying something new, or even the #Fallout76 reveal. Just fuck off.”
In chapter 3.3 and 4, we will go into more detail on what paralinguistic mechanisms are being employed for current sentiment analysis research as well as what mechanisms are present in this study and how they influence the classifier’s performance.
2.1.2.3 The cognitive gap
While the previously mentioned items facilitate the sentiment labelling process, many researchers (Cambria, Bandyopadhyay & Feraco, 2017; Liu, 2012) also state that there is a frequently recurring problem in regard to sentiment analysis referred to as ‘the cognitive gap’. This cognitive gap implies that there is a significant difference between what people think, their state of mind, and the language they use to express their thoughts (Cambria, Bandyopadhyay & Feraco, 2017). The previously mentioned authors state that there are different reasons as to why this phenomenon occurs, such as politeness or hiding one’s true feelings. In other words, the cognitive gap implies that “language does not always represent psychological reality” (Cambria, Bandyopadhyay & Feraco, 2017, p.31). In his book, Sentiment Analysis and Opinion Mining, Liu (2012) also discusses a plethora of different problems sentiment analysis has to face (sarcastic sentences, sentiment words that do not express any sentiment, etc.). However, the author also warns the reader that, while it has already become a difficult task to keep track of all the different problems, there are still new complications being discovered every day. As an example, Liu (2012) warns other researchers to be cautious when aiding an NLP system in determining sentiment in grammatical and lexical expressions, as seen in 2.1.3.2. The detection of sentiment words, such as ‘good’, can be ambiguous and, therefore, not always express the expected sentiment. He also adds that this phenomenon frequently occurs in interrogative sentences.
2.2 Stance Detection
As we have already briefly discussed in the introduction, stance detection implies determining whether a person is in favour or against a certain target by analysing their opinion (Augenstein, Rocktäschel, Vlachos & Bontcheva, 2016; Mohammad, Sobhani & Kiritchenko, 2016). Stance detection is related to sentiment analysis in the sense that you define a certain target, which is female characters in Battlefield V for this study, and that you analyse a person’s point of view towards that target. This can result in a person being either in favour, against or neutral towards a given target. In other words, stance detection can provide large enterprises with valuable data, as they would be able to distribute large amounts of surveys through social media and the World Wide Web in general and then analyse the data through automatic stance detection (Augenstein, Rocktäschel, Vlachos & Bontcheva, 2016). However, as stance
detection is still in its infancy, there have not been conducted that many studies on the topic. Moreover, from the few conclusions that have been drawn, we can deduct that not all researchers are on the same page. On the one hand, Mohammad, Sobhani and Kiritchenko (2016) show that, while humans are perfectly able to manually detect and label stance in a number of texts, an automatic system does not perform this task as successfully. On the contrary, the authors go as far as to say that their classifier performed poorly. On the other hand, Wei, Zhang, Liu, Chen & Wang (2016) claim that the system they have developed obtains good ranks in terms of automatic stance detection. Additionally, they state that their system can be applied for other related tasks.
While stance detection is very similar to sentiment analysis, we can also encounter some differences. As previously discussed in 2.1.1, sentiment analysis attempts to determine the polarity of a given text. However, in the case of stance detection, the aim is to determine favourability towards that entity, which can be labelled as in favour or against but also neutral. When a person’s opinion is perceived as neutral, this could imply that the person simply does not take a stance. However, this could also mean that it is not possible to deduce that person’s stance from the text (Mohammad, Kiritchenko, Sobhani, Zhu & Cherry, 2016). This phenomenon is also present in the corpus used for this study, as can be seen in tweet 365:
“Battlefield V Fans Are Not Happy With the Inclusion of Female Combatants, Calling it Feminist SJW Propaganda” SegmentNext (2018)
In this example, the author of the tweet takes a neutral stance in the Battlefield V controversy. This is probably due to the fact that the author is a news website which is supposed to be neutral.
Similar to sentiment analysis, a wide range of features (information sources) can help a machine learning tool successfully annotate the stance of an author. We will now list some of the most commonly used features in stance detection research. (1) First of all, Rao, Yarowsky, Shreevats & Guta (2010) mainly focussed on socio-linguistic features, such as emoticons and abbreviations. They claim that including these types of utterances significantly increases the performance of their classifier in terms of stance detection. (2) If we turn out
attention to other authors (Magdy, Darwish, Rahimi, Baldwin & Abokhodair, 2016), they tend to focus on completely different features than Rao et al. To be more precise, Magdy et al. (2016) concentrate on user-declared information, for example, a person’s name or location, user profile information, retweeted or mentioned accounts, etc. Similar to the previous authors, Magdy et al. (2016) claim that their classifier performed well with a precision score ranging between 70% and 90%. (3) Lastly, if we shift our focus to more recent research, such as Darwish, Stefanov, Aupetit & Nakov’s (2019) research, these authors incorporate fairly similar features to Magdy et al. However, similar to our study, Darwish et al. (2019) also focus on hashtags as a useful tool for stance labelling. In section 3.3, we will discuss in more detail how including hashtags can influence the annotation process of the machine learning system for both sentiment and stance. With regard to the features for our study, we will list and discuss all the features employed for this study in section 3.3.
2.3 Sentiment and stance classification techniques
In order to fully comprehend how sentiment and stance analysis works and how the sentiment or stance of a tweet is determined, it is essential to discuss the different approaches to sentiment analysis and stance detection and, more importantly, explore which approach will be employed for this study. There are two main approaches when analysing sentiment or stance, namely: the machine learning approach and the lexicon-based approach. The latter involves “calculating the sentiment from the semantic orientation of words or phrases that occur in a text” (Jurek, Mulvenna & Bi, 2015, para. 8). This approach requires a dictionary that has a positive or negative value added to each word. According to Zhang, Ghosh, Dekhil, Hsu & Liu (2011, p.2), the dictionary used to identify sentiment polarity is called the “opinion lexicon” or sentiment lexicon. Using these opinion words and opinion lexicon to determine “opinion orientations” is called the lexicon-based approach (Zhang et al., 2011, p.2). According to Ding, Liu & Yu (2008), these opinion words, or words that express a certain feeling, are frequently used for the lexicon based approach, as discussed in 2.1.3.2 in example 1. Next to this dictionary-based approach, a lexicon-based method can also adopt a corpus-based approach, which constructs a “domain-dependent sentiment lexicon” by analysing the relationship between the words in the tweet and some “seed sentiment words” (Hu, Tang, Gao, & Liu, 2013, p.608).
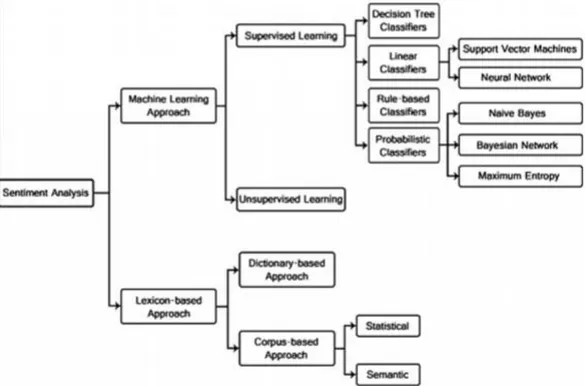
However, for this study, a machine learning approach, and more specifically a supervised machine learning approach, will be employed to automatically determine sentiment and stance in 500 tweets. The machine learning method can be divided into two main approaches: unsupervised machine learning and supervised machine learning. The latter adopts a wide variety of learning algorithms (as can be seen in figure 1), most notably: support vector machines, neural networks, the naive Bayes classifier, the Bayesian network and maximum entropy. Even though other algorithms exist (decision trees, k-nearest neighbour algorithm, etc.), this study adopts the support vector machine approach, which will be discussed more in detail in 2.3.2.3. In the following paragraphs we will briefly touch upon unsupervised machine learning before giving a more detailed explanation of supervised machine learning and support vector machines (SVM) and discussing how these concepts are fundamental to this study.
Figure 1: Sentiment classification techniques (Serrano-Guerrero, Olivas, Romero & Herrera-Viedma, 2015)
2.3.1 Unsupervised and semi-structured machine learning
A commonly used method for sentiment analysis is the unsupervised machine learning approach. For this approach, the machine learning tool simply tries to investigate and learn patterns from an unlabelled set of examples. Out all the information gathered from these learning patterns, the system tries to divide the data into, for example, positive and negative instances without actually labelling them (Hu, Tang, Gao, & Liu, 2013).According to Tripahty,
Agrawal and Rath (2016), processing data through an unsupervised machine learning approach can prove to be difficult due to the lack of labelled data. However, “the problem of processing unlabelled data” can be solved by clustering data into two groups: positive and negative sentiment labels in this case (Tripahty, Agrawal and Rath, 2016, p.117). In their book, The Elements of Statistical Learning, Hastie, Tibshirani and Friedman (2009) refer to this process as ‘clustering algorithms’. Moreover, this approach attempts to determine the polarity of, for example, a tweet without having been trained based on a relevant training corpus (Hu, Singh, Scalettar, 2017; Wan, 2008). In other words, the system is left to its own devise to analyse, annotate and interpret the data as there is no labelled dataset.
Another machine learning method is called the semi-supervised machine learning approach. This method implies that a tool is provided with both a labelled and unlabelled dataset which it can use to determine, for example, the polarity of a text (Ortigosa-Hernández, Rodríguez & Alzate, 2012). This approach is often adopted as gathering a sufficient amount of data for a labelled dataset can be time-consuming. However, we will not go into further detail on these approaches as they are not very relevant to this study. Contrary to unsupervised and semi-supervised machine learning, the supervised machine learning approach will be discussed extensively in the next paragraph as this method will be employed for this study.
2.3.2 Supervised machine learning
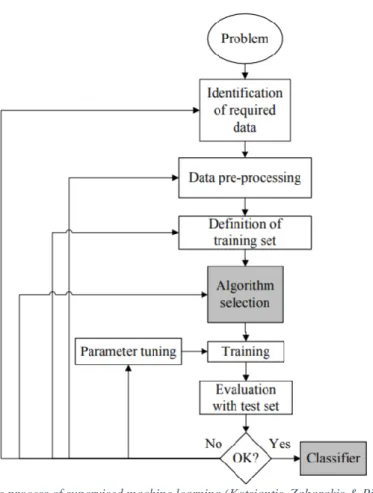
For this study, both sentiment and stance will be automatically annotated by a supervised machine learning tool. This implies that a machine learning tool can train, learn and improve based on a labelled dataset (Serrano-Guerrero, Olivas, Romero & Herrera-Viedma, 2015; Tripahty, Agrawal and Rath, 2016). In other words, this tool will analyse and learn from tweets which have been manually labelled in terms of both sentiment and stance. Gautam and Yadav (2014) prefer a supervised machine learning approach as providing a labelled dataset will aid the tool in making the correct decision and, consequently, also solve any problems that unlabelled datasets may cause, as discussed in 2.3.1 (Tripahty, Agrawal and Rath, 2016). As the aim of this study is to generate a classifier that can successfully annotate sentiment and stance taking into account the different paralinguistic mechanisms (as will be discussed 3.3) and applying the 10-fold cross validation method for evaluation, we will first discuss how this classifier actually works. In the following paragraphs, we will further elaborate on the process
of supervised machine learning in four big steps which has been illustrated in figure 2 by Kotsiantis, Zaharakis and Pintelas (2007).
2.3.2.1 Collecting the dataset
The first step in the process of supervised machine learning is collecting the dataset. There are two ways to gather a useful and practical dataset according to Kotsiantis, Zaharakis & Pintelas (2007). On the one hand, one could enlist an expert who could locate and advise all the features and attributes which are relevant to the study. On the other hand, one might use “brute-force” which implies measuring and scanning the entire corpus in the hopes of finding enough relevant data to continue the study (Kotsiantis et al., 2007, p.250). However, Zhang, Zhang & Yang (2002) argue that the ‘brute-force method’ not only fails collecting a vast majority of the relevant features, it also brings about a considerable amount of noise. Similar to Zhang et al. (2002), Li & Wu (2010) maintain that noise data is irrelevant data and must be avoided at all costs. It is, therefore, recommended to avoid the ‘brute-force method’ if possible, to reduce the noise data and extract as many relevant features as possible. Consequently, Zhang et al. (2002) recommend pre-processing the data to avoid this problem.
2.3.2.2 Data preparation and pre-processing
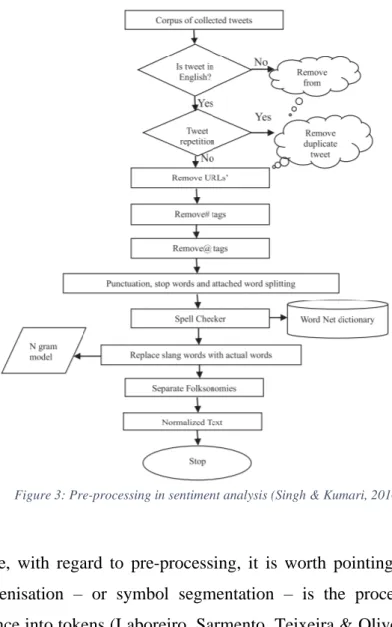
After collecting the dataset, it is important to prepare the data and start pre-processing the information. Pre-processing the dataset implies “cleaning and preparing the text for classification” (Haddi, Liu & Shi, 2013, p.27). Asghar, Khan, Ahmad & Kundi (2014, p.183) refer to the term “feature cleansing” to describe this process of removing all irrelevant features in the dataset. As concluded by Haddi et al. (2013), pre-processing reduces the amount of noise, removes all irrelevant features and, therefore, improves the overall performance of the classifier significantly. To sum up, pre-processing is a constant process of removing, replacing and reverting certain features to enhance a classifiers performance (Jianqiang & Xiaolin, 2017). We will now discuss some of the most commonly used pre-processing methods (Jianqiang & Xiaolin, 2017; Singh & Kumari, 2016):
(1) Replacing negative contracted forms implies detecting all negative contracted forms in the dataset, such as: ‘won’t’, ‘can’t’, ‘shouldn’t’, etc. and transforming them into ‘will not’, ‘cannot’ and ‘should not’, respectively.
(2) Removing URL links is an important step in pre-processing as many researchers (Jianqiang & Xiaolin, 2017; Sun, Belatreche, Coleman, McGinnity & Li, 2014) have concluded that URL links do not add any relevant information to the process of sentiment analysis.
(3) Flooding or word lengthening or, in other words, removing irrelevant repeated letters. This phenomenon will be discussed in the methodology (cf. section 3.3).
(4) Removing numbers as they carry little information which could aid a machine learning tool in determining polarity.
(5) Removing stop words is another important step in pre-processing the dataset as most stop words are considered to worsen the performance of the classifier. To aid the machine learning tool with this task, many researchers such as, for example, Fox (1992) have developed a stop list which contains the most frequently used stop words.
(6) Acronyms and slang remain troublesome as the internet contains an ever-increasing number of slang and acronyms which prove to be a difficult area for machine learning tools.
It is important to note that the majority of these ‘problems’ listed above are also present in the corpus used for this study. However, unlike other research that adopts the supervised machine learning approach, this study will not be employing the previously mentioned methods of pre-processing. It is possible that these so-called ‘uninformative elements’, ranging from flooding to curse words or slang, contain valuable information with regard to sentiment and stance detection and can, therefore, aid the automatic labelling process (Haddi, Liu & Shi,
2013). Haddi et al. (2013) add that, besides the previously mentioned list, other uninformative elements can be encountered in tweets, such as for example: advertisements, white spaces and abbreviations. Keeping these uninformative elements in mind and addressing them accordingly is essential as it will improve the quality and performance of the classifier (Jianqiang & Xiaolin, 2017). The figure below illustrates various different steps of pre-processing in sentiment analysis (Singh & Kumari, 2016).
Furthermore, with regard to pre-processing, it is worth pointing out the concept of
tokenisation. Tokenisation – or symbol segmentation – is the process of dividing and
classifying a sentence into tokens (Laboreiro, Sarmento, Teixeira & Oliveira, 2010; Maynard & Greenwood, 2014). This way, the resulting tokens can be better analysed by a machine learning tool. However, tokenisation does entail various problems, some of which have already been mentioned above. Laboreiro et al. (2010) have summed up several problems that occurred during their own study. One problem was the use of a slash (‘/’). While a slash may be unambiguous from the tokenizer’s point of view, this punctuation mark can also be used in hyperlinks or smileys. Therefore, as mentioned above, it is recommended to remove any
hyperlinks from the corpus. However, when discussing emoticons, this may form a problem as this feature, unlike hyperlinks, will be analysed in this study. Furthermore, the authors mention that white spaces, spelling mistakes, bullet points, punctuation marks, etc. can also cause problems when tokenising. Laboreiro et al. (2010) would even go as far as to say that this ambiguity is almost unavoidable.
Another pre-processing step could consist of running a part-of-speech tagger.
Part-of-speech tagging (POS), as the word implies, tags every single word and classifies it accordingly
into grammatical categories, such as, for example, a noun, adjective, verb, etc. (Asghar, Khan, Ahmad & Kundi, 2014). This technique should help determine which word categories tend to accompany other word categories, such as for example verbs which are often preceded by nouns. However, Asghar et al. (2014) state that the process of POS-tagging becomes increasingly difficult when classifying implicit features (as listed above).
Furthermore, stemming and lemmatisation are two essential steps when pre-processing the dataset. The first concept simply implies converting every word back to its root or stem, for example: ‘automatic’, ‘automate’ and ‘automation’ will all be converted back to their stem ‘automat’ (Asghar, Khan, Ahmad & Kundi, 2014). Stemming allows the classifier to perform faster if there are no problems regarding accuracy (Asghar et al., 2014). Lemmatisation means grouping “together various inflected forms of a word into a single one”, such as for example the words ‘plays’, ‘played’ and ‘playing’ which all have the word ‘play’ as their lemma (Asghar et al., 2014, p. 182). According to the previously mentioned authors, the difference between these two concepts lies within the fact that stemming only eliminates these word inflections, whereas lemmatisation attempts to change every word back to its lemma or base form.
Lastly, we will briefly discuss three other ways of pre-processing the dataset. The first way is simply dividing the dataset into sentences (viz. sentence splitting). The second way is called named entity recognition. This concept entails extracting structured information from an unstructured text or, in other words, automatically detecting information units, such as person names, organisations and locations, as well as numeric expression, such as time, money, etc. (Nadeau & Sekine, 2007). The last pre-processing step could then be chunking. According to Kudo and Matsumoto (2001), chunking can be divided into two processes. The first one is
to locate and pinpoint all the ‘chunks’ from a series of tokens. The second process consists of categorising those chunks into ‘grammatical classes’. To give an example to help clarify this process, an example of a chunked sentence would be: “[NP] I [VP] love [NP] my Master’s thesis”.
2.3.2.3 Feature extraction
After detecting and resolving the problem of the uninformative elements, as discussed above, the next step is to identify and extract all the relevant features from the dataset. This process if often referred to as “feature extraction” and it involves different techniques which help identify “relevant attributes” and increase “classification accuracy” (Asghar, Khan, Ahmad & Kundi, 2014, p.182). According to Abbasi, Chen and Salem (2008) these features can be divided into five main categories, namely: syntactic, semantic, link-based, lexical and stylistic features. However, this study will mainly focus on syntactic and lexical features as these features are most relevant for this study and, additionally, are very commonly used in modern machine learning research. All the relevant features for this study will be discussed in more detail and clarified with an example from our own corpus in the methodology section (cf. section 3.3). However, we will now further elaborate on some of the most commonly used features in modern sentiment research, as they form a key part of this study and are essential to understanding the process of supervised machine learning (Asghar et al., 2014).
Should we compare the list of features employed for this study (cf. section 3.3), it would appear to be very similar to many features that are being analysed and extracted in modern sentiment analysis in Twitter. An important research for sentiment analysis in Twitter would be the Semeval-2015 task (Rosenthal et al., 2019). In order to complete the different subtasks that were given to the classifier, the authors carefully selected many different features for extraction. Rosenthal et al. (2019) mention that nowadays the features that are most frequently being incorporated into sentiment analysis research are lexical features and, to a lesser extent, syntactic features. They claim that the most important features for their classifier were those that they extracted from the sentiment lexicon. Additionally, Rosenthal et al. (2019, p.11) state that other features were also incorporated into their research, such as: “bag-of-words-features, hashtags, handling of negotiation, word shape, punctuation features and elongated words”. If we shift our focus to other studies regarding sentiment analysis, we can deduce that many
features employed by the Semeval-2015 systems reoccur. To give an example, Shirbhate & Deshmukh (2016) opted for negations and opinion words or Agarwal, Xie, Vovsha, Rambow & Passonneau (2011) elected capitalised words, negations, hashtags, punctuation marks, etc. as the main features for their study. In other words, while there exists a wide variety of features for a classifier to extract, the previously listed features are the most frequently recurring ones for the current research in sentiment analysis in Twitter.
If we turn our attention to other recent research with regard to sentiment analysis, we can deduce that many different classifiers as well as features are being incorporated into this field of research. In the SemEval-2017 Task 4 by Rosenthal, Farra & Nakov (2019) for example, the authors indicate that classifiers such as maximum entropy, naïve Bayes, random forest and support vector machines, the system used in this study, are popular in recent research. Furthermore, it remains essential to briefly list some of the features that are being employed at the time of this research. Rosenthal et al. (2019) claim that there is a wide range of different features being used depending on which classifier was chosen for the annotation process. To give an example, the authors indicate that SVM mainly adopt deep learning, lexical, semantic, surface or even dense word embedding features. Moreover, for their study, a naïve Bayes classifier primarily focussed on lexical and sentiment features. However, it is important to note that many of these features will not be utilised for this study.
Lastly, it is worth pointing out that there are still many other features that are being used in the current sentiment and stance research. One example would be the PMI features or pointwise mutual information features. According to Van Hee, Van de Kauter, De Clercq, Lefever & Hoste (2014), this concept implies associating a word with a certain sentiment (positive, negative) and giving a value to that association. The stronger the association between a word and its sentiment, the higher the PMI value will be. In other words, PMI indicates to what extent adding or removing a term contributes to the annotation process. Practically, these PMI values can be attributed to any n-gram (unigram, bigram, etc.) and added to a sentiment lexicon which may then be used by the machine learning system to aid the annotation process. Similar to Van Hee et al. (2014), many other researchers such as Mohammad, Kiritchenko & Zhu (2013) apply PMI values to help create a successful SVM classifier. Lastly, it can be noted that these PMI values are calculated by subtracting the association score of a term with a
negative sentiment label with the association score of a term with a positive sentiment label (Van Hee et al., 2014).
2.3.2.4 Algorithm selection and evaluation
After pre-processing and extracting all the required features, the next is step is choosing the appropriate algorithm for the (supervised) machine learning task. Even though sentiment analysis is a fairly recent phenomenon, a wide variety of algorithms have been created to classify and analyse the data. These algorithms are continuously tested to uncover how they can be used more beneficially and to discover which algorithm is more apt for a certain situation. Kotsiantis, Zaharakis and Pintelas (2007) have divided the most commonly used algorithms into three groups: logical/symbolic techniques (decision trees), perception-based techniques (single- or multi-layered perceptrons, radial basis function) and statistical approaches (naïve Bayes classifiers, Bayesian networks, instance-based learning). For our research, we will apply a supervised machine learning technique which is called support
vector machines (SVM). SVM is a statistical learning technique that not only has a “regression
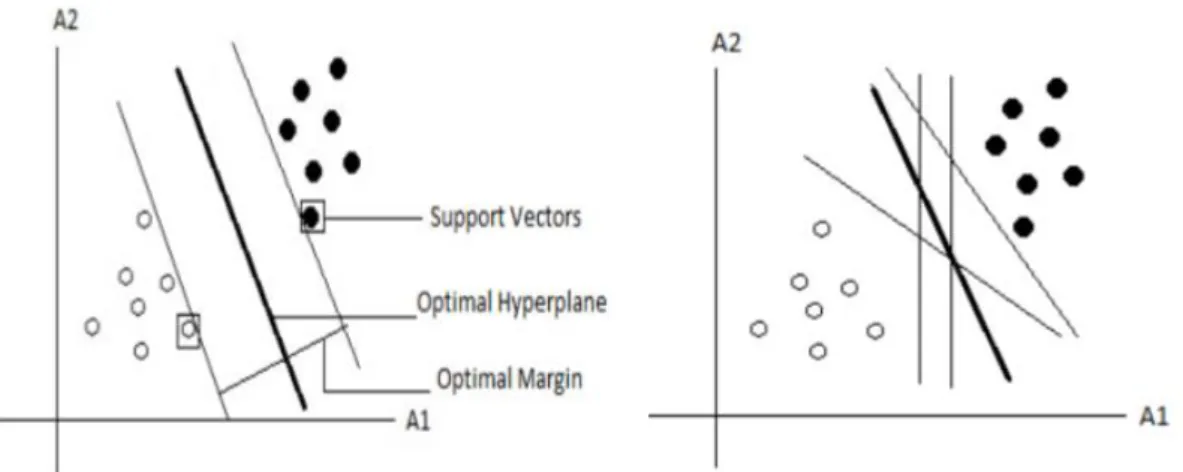
or ranking function”, but it is also mainly “used for learning classification” (Bhavsar & Ganatra, 2012, p.78). The support vector machine method attempts to classify, for example, every tweet as positive or negative based on the sentiment in a multidimensional space. To this end, the SVM attempts to draw a line which separates the positively and negatively annotated tweets from one another. This line is referred as the hyperplane (Al Amrani, Lazaar & El Kadiri, 2018; Bhavsar & Ganatra, 2012; Kotsiantis, et al., 2007). However, finding the “optimal separating hyperplane” (OSH) can prove to be a difficult task as demonstrated in figure 5 (Bhavsar & Ganatra, 2012, p.78). Figure 4 illustrates how the SVM determines the optimal hyperplane and margin, by selecting the support vectors.
The OSH can generally be determined by the algorithm with a relatively small dataset. After the OSH has been drawn up and after providing the SVM with enough training data, the algorithm can predict to which side of the hyperplane any new instances would be placed (Joshi & Itkat, 2014). As illustrated in figure 4, by drawing this hyperplane, a “margin” is created on either side of the line (Kotsiantis et al., 2007, p.260). Any new instances that are annotated and allocated inside the margin on either side of the hyperplane are called support vectors (see figure 4) and provide the most information for classifying the data (Bhavsar & Ganatra, 2012). All instances that fail to be allocated inside the margin are considered useless and will not be taken into consideration by the algorithm. Moreover, for every new instance, new features need to be analysed, which implies that, every time a new instance is introduced, a new feature vector has to be made up. In other words, the support vector machine method creates a classifier that is able to handle an infinite amount of feature vectors. For this study, the linear kernel support vector machine method will be employed. In the early 2000s, Xia, Rui, Zong & Li (2001) claimed that the SVM method is the best method for classifying labelled data. Nowadays, many researchers (Al Amrani, Lazaari, El Kadiri, 2018; Joshi & Itkat, 2014) still claim that SVM outperforms other algorithms in terms of classification. However, while this method has many advantages and is being hailed for its performance, it is important to also take note of the disadvantages and research issues regarding this algorithm. Bhavsar & Ganatra (2012) have concluded that every single algorithm has its own specific advantages and disadvantages and that, therefore, each algorithm should be implemented based on the context and desired results.
Figure 5: Searching for the optimal separating hyperplane (Bhavsar & Ganatra, 2012) Figure 4: The margin on either side of the hyperplane
Lastly, evaluating the results is arguably the most important step in the process of supervised machine learning. By doing so, it is possible to determine the accuracy of the classifier and evaluate how well the classifier performed in comparison to the manually annotated dataset and in comparison to other classifiers. There is a wide variety of techniques that can be used to measure a classifier’s accuracy. In this study, we will employ a technique called ‘cross validation’ or more specifically: 10-fold cross validation to train the system and test the performance of our machine learning tool. In this study’s case, 9 folds are used to train the dataset (90%) and one fold will be used for testing (10%). This process is repeated 10 times in order to successfully determine the accuracy of the machine learning tool. The process of 10-fold cross validation will be discussed more in detail in the methodology and results section (section 3 and 4). Figure 6 illustrates how the k-fold validation (5-fold in this case) for this study will operate.
As a final note on the supervised machine learning process, it is important to take into account that if the results of the classifier should be unsatisfactory, the researcher must return to the previous step and analyse what went wrong and how the classifier can be improved. This could imply that the researcher may have to trail back all the way to the first step of collecting the dataset in order to improve the classifier’s accuracy. This process of returning to the previous step has also been illustrated in figure 3 (p.18).
3. METHODOLOGY
In order to provide an answer to our research questions listed in the introduction, we must compare the labels from the manually annotated corpus with the labels predicted by a machine learning tool (with and without hashtags) for sentiment and stance classification. However, before we can do so, it is important to explain how the data was collected and how it will be interpreted. Therefore, we will discuss in the following paragraphs what topic was chosen for this research and why, before moving on to the actual data collection process. Finally, we will provide the reader with more information on how the experimental approach was prepared and executed.
3.1 Topic motivation
On 23 May 2018, EA DICE, a video game developer, released the official reveal trailer for Battlefield V on YouTube. Battlefield is a first-person shooter (FPS) series generally known for its realistic and historically accurate gameplay. However, this reveal trailer sparked great controversy due to claims that the content of the trailer was not historically accurate. The trailer received very negative feedback and around 536.000 dislikes in comparison to 350.000 likes. Soon, the verbal conflict moved to social media and especially Twitter. The most frequently recurring complaint was about a woman in the trailer fighting on the front lines during World War II with a prosthetic arm. Many people believed that this was historically inaccurate and filed their complaints on Twitter using the ‘#notmybattlefield’. Not much later, EA DICE responded by stating that gamers should accept diversity and by attempting to launch a new hashtag called ‘#everyonesbattlefield’. In order to determine a person’s stance towards a given subject, it is important to phrase a controversial question to which the person can either agree or disagree. Therefore, based on the previous two hashtags, we formulated the following two questions to determine whether the Twitter user belonged to the #everyonesbattlefield or the #notmybattlefield group:
- Are you in favour or against female characters in video games and more specifically, Battlefield V?
- Do you find female characters in Battlefield V historically accurate as the scenery takes place during WWII?
After collecting all 500 tweets for our corpus and labelling them based on the previously formulated questions, we were able to determine people’s motives for choosing a certain stance. Most people who were in favour of female characters in Battlefield V shared EA DICE’s point of view that gamers should learn to accept diversity. However, surprisingly, those who were against female characters had various motives ranging from historical inaccuracy to publicity stunts. The following list contains frequently recurring ideas from those arguing against female characters in Battlefield V:
- The game is no longer historically accurate.
- They state that they have a more conservative opinion.
- Females during World War II are simply unrealistic as they did not fight at the border.
- EA DICE is trying to impose a political idea. (sjw)
- The female character in the trailer is a publicity stunt by EA DICE.
Notably, the abbreviation ‘sjw’ or ‘social justice warrior’, reappears very frequently in our corpus and appears to be used to take a negative stance. We will discuss this further in the results section (cf. section 4).
3.2 Data collection process
In order to start collecting data for our research, we first had to choose a social media platform from which the data would be collected. For this study, we opted to gather our dataset through Twitter, a social media platform that focusses primarily on letting people express their opinions through text. On Twitter, each message can consist of a maximum of 280 characters (including punctuation marks and emoticons), which ensures that the messages will not be too long and, therefore, too complicated for our machine learning tool to handle. Additionally, as will be discussed in 3.3, paralinguistic mechanisms, such as flooding, capitalisation, etc., tend to facilitate or sometimes mislead a machine learning tool when annotating both sentiment and stance. In order to express their opinion, Twitter users tend to use these paralinguistic mechanisms to reinforce their message. For this very reason, we have collected 500 tweets regarding the Battlefield V controversy (see 3.1) from Twitter. This will not only provide us with a dataset from which we can deduct a clear sentiment and stance, the messages will also include various paralinguistic mechanisms in different combinations which will help us
determine whether this influences the accuracy of the classification or not. In other words, Twitter is the perfect platform to help provide an answer to both our research questions mentioned in the introduction.
Before proceeding to the collection of the dataset, several criteria were taken into account to ensure the relevancy of the data for this research. Firstly, the overall majority of the 500 tweets date back to May and June 2018, the 2-month period after which the Battlefield V reveal trailer was released. The minority of the tweets were published during the summer holidays (July, August and September). Nonetheless, even though these people did not immediately share their opinions, we can still distinguish a clear #everyonesbattlefield group and #notmybattlefield group. Secondly, to guarantee the consistency of this study, only English tweets were selected. Lastly, the entire corpus was gathered via Twitter’s Advanced Search Tool3. To ensure the significance and relevancy of the results, various search terms, favouring one group over the other or none at all, were chosen to guarantee that the search terms would not interfere with the results. In other words, should only search terms be entered that mainly lists the opinions of one specific group, then the possibility of creating a bias towards a certain label would have been greater.If we noticed, for example, that ‘#notmybattlefield’ favours one group over the other then another search term favouring the other group was chosen to attempt to maintain the balance. The table below contains the most fruitful search terms used via the advanced search tool:
2 SJW or Social Justice Warrior is “An often mocking term for one who is seen as overly progressive” (Merriam-Webster Dictionary)
3 https://twitter.com/search-advanced Search terms favouring female characters
Neutral search terms Search terms against female characters
#everyonesbattlefield Battlefield V women #notmybattlefield
female characters (from:ogabrielson) Battlefield V female characters Battlefield V backlash Battlefield V historically accurate Battlefield V female protagonist Battlefield V historically inaccurate
Battlefield V diversity Battlefield V SJW2
The last step in the data collection process is annotating the dataset. This step consists of listing all 500 tweets in an Excel spreadsheet and manually labelling them in terms of sentiment, stance and paralinguistic mechanisms. Firstly, sentiment, which has been discussed in detail in 2.1, entails labelling the polarity of the tweet (positive, negative or neutral) based on what overall emotion or opinion the message conveys (tweet level). Secondly, stance detection, as discussed in 2.2, attempts to verify whether a person is in favour or against a given target, which is the Battlefield V controversy in this case. Lastly, 4 paralinguistic mechanisms were also taken into consideration, namely: flooding, irony, capitalisation and emoticons. This way, we will attempt to uncover how these 4 elements influence the machine learning tool’s performance in terms of automatically determining sentiment and stance. Additionally, as there were two frequently recurring hashtags present in the dataset, namely ‘#everyonesbattlefield’ and ‘#notmybattlefield’, we trained and evaluated the machine learning system a second time. For the standard experiment, all 500 tweets were automatically classified in regard to sentiment and stance while the two previously mentioned hashtags were not taken into account. All other hashtags were taken into consideration. For the second experiment, the machine learning system automatically labelled the same 500 tweets, yet this time, these hashtags were included in the training and test data. The aim is to investigate whether these hashtags convey a certain sentiment or hint towards a certain stance and, consequently, improve the machine learning system’s performance. The standard experiment will be discussed in sections 4.1, 4.2 and 4.3 and the experiment including the hashtags in section 4.4.
One frequently recurring aspect in our dataset, was irony. To measure the impact of irony on the classification performance, we manually flagged ironic tweets while annotating the corpus. As mentioned in the introduction, social media has become a valuable source of user-generated content for many organizations. However, the content on social media platforms is often filled with figurative speech, which “represents one of the most challenging tasks in natural language processing” (Vanhee, Lefever & Hoste, 2016, p. 1794). In this study, figurative speech refers to verbal irony, which means saying the opposite of what was actually implied (Vanhee, Lefever & Hoste, 2016). This verbal irony, along other forms of irony, is also clearly present in the corpus used for this study. This can be demonstrated through the following example (tweet 158 in the corpus):
“Yes we should clearly accept a game that changes history just to force diversity and a political agenda down our throats.” Froggo (2018)
In tweet 158, the user is against forced diversity. However, as the user said the opposite of what he actually meant, an NLP tool may have difficulties correctly determining the stance and sentiment of the tweet. Furthermore, as this verbal irony is difficult to detect for NLP tools, the accuracy can be significantly lower than when manually annotated. It could therefore be beneficial to train and provide a machine learning tool with enough data to be able to correctly detect and analyse irony.
It is important to point out that a successful automatic annotation is not easily accomplished and that the machine learning system has to overcome several hurdles. Firstly, it is possible that some paralinguistic mechanisms, especially irony, mislead the machine learning tool during the annotation process and, consequently, increase the number of incorrectly labelled tweets. Secondly, abbreviations, slang and curse words can also cause problems as it may be quite difficult for the system to detect what sentiment or stance they convey. Put differently, these words or abbreviations may not appear in the sentiment lexicon, nor may they frequently reappear in the corpus itself. Hashtags, the third hurdle, are especially relevant for this study as the aim is to compare the manually annotated corpus with an automatically annotated corpus that includes hashtags and another corpus that does not include hashtags. These three hurdles will be discussed in more detail in the error analysis of the machine learning tool (cf. section 4.5).
3.3 Experimental approach
The aim of this research is to investigate whether a machine learning tool can automatically determine sentiment and stance by comparing the labels of the classifier with those of the manually annotated corpus containing the same 500 tweets. In 3.2, we discussed that the dataset had been compiled in an Excel spreadsheet and manually annotated. For the machine learning tool, that spreadsheet has been converted into a text file (.txt). It is important to note that, even though sentiment and stance were manually labelled using alphabetic words