1
MASTERPROEF DEEL 2
DISCOURSE-ANALYSE
BIJ
AFASIEPATIËNTEN:
EEN
VERTALING EN NORMERING VAN DE MAIN CONCEPT
ANALYSIS
Aantal woorden: 12 540
Yana Criel & Marie Deleu
Studentennummer: 01507857 & 01408155
Promotoren: Prof. dr. Miet De Letter, Prof. dr. Annelies Bockstael, Drs. Evelien
De Groote
Masterproef voorgelegd voor het behalen van de graad master in de logopedische wetenschappen.
Academiejaar: 2019 - 2020
2
Inhoud
1. Abstract ... 3 2. Inleiding ... 5 3. Methode ... 9 3.1. Proefpersonen ... 9 3.2. Data-collectie ... 11 3.3. Data-analyse ... 12 3.4. Statistische analyse ... 15 4. Resultaten ... 17 4.1. Nederlandstalig scoreformulier ... 17 4.2. Normering ... 174.3. Vergelijking van de MCA-scores tussen vooropgestelde leeftijds-, educatie- en geslachtscategorieën ... 19 5. Discussie ... 24 6. Conclusie ... 30 7. Referenties ... 32 8. Bijlagen ... 37 8.1. Bijlage 1 ... 37 8.2. Bijlage 2 ... 38 8.3. Bijlage 3 ... 39 8.4. Bijlage 4 ... 40 8.5. Bijlage 5 ... 44 8.6. Bijlage 6 ... 54 8.7. Bijlage 7 ... 55 8.8. Bijlage 8 ... 60 8.9. Bijlage 9 ... 64
3
1. Abstract
Nederlandstalig abstract
Achtergrond: Verbale discourseproductie is noodzakelijk voor de menselijke interactie. Bij
afasiepatiënten is dit aspect van de taal vaak gestoord. Het in kaart brengen van discourseproductie bij afasiepatiënten vormt dan ook een belangrijk aspect van het klinisch-logopedisch onderzoek. De Main Concept Analysis (MCA) (Kong, 2009) is een test die de effectiviteit en efficiëntie van de informatieoverdracht tijdens verbale discourseproductie bij deze doelgroep kwantificeert aan de hand van vier afbeeldingssets. De test werd oorspronkelijk ontwikkeld voor het Cantonees en is op heden beschikbaar in het Amerikaans-Engels en Taiwanees-Mandarijns.
Doelstellingen: De vertaling en normering van de MCA voor gezonde personen met de Nederlandse
moedertaal werd vooropgesteld. Bijkomstig werd het effect van leeftijd, educatieniveau en geslacht op de MCA nagegaan.
Methode: Aan deze normeringsstudie namen 60 gezonde Nederlandse moedertaalsprekers deel,
waarvan twintig binnen elk van de drie vooropgestelde leeftijdscategorieën (jong: 20-39 jaar; middel 40-59 jaar; oud: 60-79 jaar). Binnen deze categorieën werd bovendien telkens een evenredig aantal mannen/vrouwen en midden-/hoogopgeleiden gerekruteerd. Geïncludeerde proefpersonen hadden een negatieve medische voorgeschiedenis van neurologische en/of psychiatrische aandoeningen. Cognitief en auditief functioneren werden nagegaan door middel van respectievelijk de MoCA en SSQ5. Voor de normering werden taalstalen verzameld van elk van de 60 proefpersonen door afname van de MCA. Uitingen die door minstens 75% van de proefpersonen werden geproduceerd, werden opgenomen als main concept in het Nederlandstalig scoreformulier. Op basis hiervan werden ook leeftijdsspecifieke normatieve data opgesteld voor alle MCA-parameters. Vervolgens werd het effect van leeftijd, educatieniveau en geslacht op MCA-score nagegaan. Tot slot werden ook de inter- en intrabeoordelaarsbetrouwbaarheid van de Nederlandstalige MCA geëvalueerd.
Resultaten: Op basis van taalstalen van de 60 proefpersonen werd het Nederlandstalig scoreformulier,
bestaande uit 19 main concepts, opgesteld. Leeftijdsspecifieke normen werden bekomen. Zowel leeftijd als educatieniveau bleken een significant effect te hebben op de MCA-score. Ouderen bleken zowel minder effectief als efficiënt in hun informatieoverdracht tijdens discourseproductie. Bovendien verloopt de informatieoverdracht bij hoogopgeleiden minder efficiënt in vergelijking met middenopgeleiden. De Nederlandstalige MCA bleek tot slot een betrouwbaar meetinstrument te zijn.
Conclusie: De Nederlandstalige MCA vormt een betrouwbaar instrument voor de evaluatie van
discoursevaardigheden. Verdere validatie van het de test voor een afatische populatie is noodzakelijk vooraleer de test kan worden gebruikt in een klinische praktijk.
4
Engelstalig abstractBackground: Verbal discourse production is a necessary competence in human interaction. People with
aphasia, however, often show deficits in this component of language production. It is therefore important to examine and map this aspect within the clinical evaluation of aphasia. The Main Concept Analysis (MCA) (Kong, 2009) is a test that quantifies the effectiveness and efficiency of information transfer during verbal discourse by means of four sets of sequential picture stimuli. This test was originally developed for a Cantonese speaking population and has been translated for an American-English and Taiwanese-Mandarin population.
Objectives: The main goal of this research was to translate and standardize the MCA for healthy, native
Dutch speaking adults. Secondary, the effect of age, education level and gender on MCA outcome was evaluated.
Methodology: In this standardization study, a total of 60 healthy native Dutch speakers participated,
twenty of which within each of the following three age categories: 20-39 years old, 40-59 years old and 60-79 years old. Within these categories, a proportional number of men/women and middle/highly educated participants were enrolled. None of the subjects had a history of neurological or psychiatric disorders. Cognitive and auditory functioning were evaluated by means of respectively the MoCA and SSQ5 questionnaire. Language samples were collected from each of the 60 participants through the administration of the MCA. Utterances produced by at least 75% of the subjects were included as a main concept in the Dutch version of the MCA. Subsequently, age-specific normative data were compiled for each of the MCA parameters. The effect of age, education level and gender on MCA outcome was thereupon evaluated. Finally, the inter and intra rater reliability of the Dutch MCA were assessed.
Results: The Dutch score form, consisting of 19 main concepts, was composed based on the language
samples from the 60 subjects. Age-specific normative data were obtained. Both age and education level were found to have a significant effect on MCA outcome. Elderly proved to transfer information during discourse production both less effectively and efficiently. Moreover, the information transfer of highly educated subjects appeared to be less efficient in comparison to middle educated subjects. The Dutch- MCA turned out to be a reliable measuring instrument.
Conclusion: The Dutch MCA is a reliable tool for the evaluation of discourse abilities. Validation of the
test for an aphasic population is necessary in order for the test to be useful in a clinical practice.
5
2. Inleiding
Het grootste deel van de menselijke interacties bestaat uit de productie van linguïstische eenheden die het zinsniveau overschrijden, ook wel discourse genoemd. Volgende definitie kan hieraan toegewezen worden: ‘een taalunit die het niveau van een enkel woord of zin overstijgt van een boodschap’ (Cherney, 1998; Olness, 2006; geciteerd uit Kong, 2009). Het begrip ‘discourse’ dient onderscheiden te worden van ‘conversatie’ en ‘spontane spraak’. Een conversatie wordt gekenmerkt als ‘een gesprek, meestal van informele aard, tussen twee of meer personen tijdens welke nieuws en ideeën uitgewisseld worden’. Een conversatie bestaat met andere woorden uit discourse, maar bevat naast dit talige aspect ook een interactiecomponent, die bijkomstige vaardigheden als beurtnemen (Sacks, Schegloff en Jefferson, 1974) en het sequentieel organiseren van gesprekken (Schegloff en Sacks, 1973) veronderstelt. Conversatie is met andere woorden een specifiek type discourse dat interactie tussen twee of meerdere personen veronderstelt. Spontane taal kan gedefinieerd worden als ‘expressieve verbale en non-verbale taal die voorkomt in de afwezigheid van aansporingen, instructies en andere verbale cues’. Indien discourse spontaan tot stand komt, kan dit ook vallen onder de noemer van spontane spraak.
Bij afasiepatiënten verloopt de productie van discourse vaak gestoord. Hierdoor ontstaan problemen op zowel sociaal als op professioneel vlak. Binnen het klinisch-logopedisch onderzoek wordt veel aandacht besteed aan de evaluatie van de linguïstische functies zoals fonologie, morfologie, semantiek en syntaxis op foneem-, woord- en zinsniveau (i.e. micro-linguïstische vaardigheden). Discourseproductie vergt echter heel wat bijkomende aspecten die ervoor zorgen dat de geproduceerde uitingen zowel thematisch als linguïstisch één geheel vormen en betrekking hebben op elkaar (i.e. macro-linguïstische vaardigheden). Zo is het mogelijk dat afasiepatiënten slechts milde microlinguïstische problemen vertonen maar er niet in slagen zich tijdens discourseproductie uit te drukken door een tekort in macro-linguïstische vaardigheden of andersom (Pritchard, Hilar, Cocks en Dipper, 2017). Gezien discourse zowel de micro- als macrolinguïstische vaardigheden vereist, kan gesteld worden dat discourse-analyse mogelijk representatiever is om het dagdagelijks functioneren van afasiepatiënten in kaart te brengen. Daarnaast wijst onderzoek uit dat het herstel van de discoursevaardigheden een kritieke invloed heeft op de levenskwaliteit (Mackenzie en Chang, 2002). Een integratie van discourse-analyse binnen de afasiediagnostiek biedt dan ook een enorme meerwaarde. Deze kan namelijk leiden tot bijkomende inzichten bij het bepalen van de therapienoden en maakt het bovendien mogelijk therapeutische vorderingen in kaart te brengen.
Binnen discourse-analyse kunnen verschillende aspecten beoordeeld worden. Algemeen wordt een onderscheid gemaakt tussen een linguïstische beoordeling en een beoordeling van de informatieoverdracht. Binnen een linguïstische beoordeling kunnen het micro- en macrolinguïstisch niveau onderscheiden worden, zoals hierboven reeds omschreven.Daarnaast kan ook een beoordeling gemaakt worden van de informatieoverdracht, waarbij de effectiviteit en efficiëntie van uitingen nagegaan wordt (Yorkston en Beukelman, 1980; Nicholas en Brookshire, 1993, 1995; Ruiter, Kolk, Rietveld, Dijkstra en Lotgering, 2011; Ruiter, Desain, Van Heesch, Van Hengel, Kraaij, Lindhout et al., 2015). De (non)-verbale effectiviteit vertelt iets over de hoeveelheid informatie die wordt overgebracht
6
in de boodschap (Armstrong, 2000). (Non)-verbale efficiëntie geeft weer met welke snelheid informatie wordt overgebracht (Ruiter et al., 2011). Een beoordeling volgens bovengenoemde niveaus kan op een kwantitatieve of kwalitatieve manier verlopen. Een kwantitatieve beoordeling bestaat uit het meten van de aan- of afwezigheid van bepaalde variabelen. De resultaten worden in cijfers weergegeven. Een kwalitatieve beoordeling wordt gerepresenteerd in de vorm van woorden of cijfers. Deze cijfers zijn echter niet gebaseerd op de uitkomst van metingen van de verschillende variabelen maar wel op de subjectieve perceptie van de onderzoeker. Om discourseproductie te beoordelen in de klinische praktijk wordt meestal geopteerd voor een kwantitatieve taalbeoordeling. Deze geniet hier de voorkeur om volgende redenen: (1) Een kwalitatieve beoordeling is diepgaand, waardoor deze enorm tijdrovend is. (2) Een kwantitatieve beoordeling is eenvoudig te normeren. (3) Een kwantitatieve beoordeling laat eenvoudige intra- en interindividuele vergelijking toe. (4) Een kwalitatief scoringsmodel zou veranderingen minder nauwkeurig kunnen vaststellen (Grande et al., 2008). (5) Tot slot is een kwantitatieve beoordeling in vergelijking met een kwalitatieve ook objectiever.Uit de literatuur blijken zowel leeftijd als educatieniveau mogelijks een invloed te hebben op verscheidene aspecten van discourseproductie. Binnen discourse-analyse is het belangrijk om met deze invloeden rekening te houden. Wat betreft leeftijd toonden verscheidene onderzoeken (Marini, Boewe, Caltagirone en Carlomagno, 2005; Duong en Ska, 2011; Kong en Yeh, 2015; Capilouto, Wright en Maddy, 2017) een significante daling aan in de effectiviteit van informatieoverdracht tijdens verbale discourseproductie bij stijgende leeftijd. Een frequent beschreven oorzaak hiervan is het stijgend gebruik van ambigue referenten dat gepaard gaat met een leeftijdsstijging (Marini et al., 2005; Hendriks, Koster en Hoeks, 2014; Sherrat en Bryan, 2018). Bovendien vertoonden ouderen meer moeilijkheden met het behoud van het gespreksonderwerp, vooral wanneer ze complexe discoursetaken (bv. het chronologisch vertellen van een verhaal) uitvoerden (Glosser en Deser, 1992). Dit significant verschil wordt echter niet in alle studies waargenomen. In het onderzoek van Richardson en Dalton (2016) werden drie vormen van uitlokkingsstimuli gebruikt om discourse uit te lokken, met name een enkele afbeelding, een reeks van sequentiële afbeeldingen en het uitleggen van een procedure. De enige vorm waar geen significant verschil gevonden werd op basis van leeftijd was bij het gebruik van sequentiële afbeeldingen. Vanuit de literatuur kan dus niet met zekerheid gesteld worden dat leeftijd een invloed op heeft op de effectiviteit van informatieoverdracht tijdens discourseproductie. Wat het effect van leeftijd op de efficiëntie van discourseproductie betreft, wees de literatuur op significant meer productie van off-topic spraak bij ouderen, wat leidt tot een minder efficiënte informatieoverdracht (Mackenzie, 2000; Juncos-Rabadan, Pereiro en Rodriguez, 2005; Kong en Yeh, 2015). Deze problemen zouden het resultaat zijn van de achteruitgang van non-linguïstische cognitieve functies, meer bepaald een aftakeling van werkgeheugen en executieve functies.
Ook educatieniveau blijkt informatieoverdracht tijdens discourseproductie te beïnvloeden. Mackenzie (2000), Mackenzie en Brady (2007) en Kong en Yeh (2015) stelden een verminderd aantal relevante uitingen geproduceerd bij een afbeelding (i.e.main concepts) vast bij laagopgeleiden in vergelijking met hoogopgeleide peers. Bovendien produceerden laagopgeleiden gemiddeld minder main concepts en waren hun uitingen algemeen korter en minder complex. Deze resultaten suggereren een verminderde effectiviteit van informatieoverdracht bij laagopgeleiden, die bovendien onafhankelijk van leeftijd werd
7
vastgesteld. Duong en Ska (2001) gaven echter aan dat de grootste invloed van educatieniveau op discourseproductie zich voordoet in een oudere populatie (60+ jaar). Hoogopgeleide ouderen zouden langere en meer cohesieve discourse produceren in vergelijking met laagopgeleide ouderen, waardoor ze tot meer effectieve communicatie komen. Leibovici, Ritchie, Ledesert en Touchon (1996), Christensen, Korten en Jorm (1997) en Duong en Ska (2001) stelden hieromtrent de hypothese dat een hoog opleidingsniveau ouderen in staat stelt strategieën te genereren om hun linguïstische en cognitieve achteruitgang te compenseren. Wat de efficiëntie van discourseproductie betreft, blijkt educatie hier geen invloed op uit te oefenen (Mackenzie, 2000), dit zowel bij het omschrijven van afbeeldingen als bij een conversatietaak.Om de discourseproductie te evalueren werden reeds verschillende Nederlandstalige testen ontwikkeld. Voorbeelden hiervan zijn de Amsterdam-Nijmegen Test voor Alledaagse Taalvaardigheden (ANTAT), ANTAT-CU4 en de Scenariotest. Deze testen zullen hieronder besproken worden. Tevens is een overzichtstabel te vinden in bijlage 1.
De ANTAT (Amsterdam-Nijmegen Test voor Alledaagse Taalvaardigheden; Blomert, Kean, Koster en Schokker, 1995) is een test waarbij verbale discourse van afasiepatiënten onderzocht wordt aan de hand van twee parallelle versies van telkens tien scenario’s van alledaagse situaties. Bij ieder scenario wordt de patiënt gevraagd wat hij of zij in een dergelijke situatie zou doen. De uitingen van de patiënt worden vervolgens beoordeeld aan de hand van twee beoordelingsschalen, met name (1) de A-schaal die de begrijpelijkheid van de boodschap weergeeft en (2) de B-schaal die de verstaanbaarheid van de uiting scoort. De twee schalen worden elk beoordeeld op een vijfpuntenschaal, van een score nul (geheel niet) tot en met een score vier (goed). De afname van deze test is weinig tijdrovend, maar heeft drie grote tekorten (Zwartjens, 2017). (1) De ANTAT gaat enkel de effectiviteit van discourseproductie na en niet de efficiëntie. (2) De ANTAT maakt gebruik een vijfpuntenschaal die een kwalitatieve beoordeling is en wordt bijgevolg als subjectief bevonden. (3) De normgegevens zijn verouderd. Bovendien voldoen de scenario’s niet meer aan de vereisten vastgelegd door Blomert et al. (1994), met name waarschijnlijkheid, voorstelbaarheid en verbale exclusiviteit. De eerste vereiste betekent dat het zeer waarschijnlijk moet zijn dat iemand een dergelijke situatie heeft meegemaakt. De tweede stelt dat personen zich de situatie goed moeten kunnen voorstellen. De laatste vereiste veronderstelt dat de scenario’s kort en eenduidig dienen te zijn. Volgens onderzoek van Filipinski (2014) bleken vijftien van de twintig scenario’s niet meer aan deze criteria te voldoen.
Omwille van bovengenoemde tekorten wordt de ANTAT momenteel herwerkt tot de ANTAT-CU4 (Ruiter et al. 2011; Filipinski, 2014; Aan de Stegge, 2015; Giessen, 2015; Dassek, 2016; Zwartjens, 2017), waarvoor een kwantitatieve beoordelingsmaat ontwikkeld werd door Ruiter et al. (2011). Hiervoor wordt een CU-schema gehanteerd, gebaseerd op de Content-analyse van Yorkston en Beukelman (1980). Een tweede aanpassing is dat naast de effectiviteit ook de efficiëntie van communicatie wordt nagaan in de herwerkte test, dit door het aantal Content Units per minuut te berekenen. Tot slot werden 15 van de 20 scenario’s aangepast opdat deze opnieuw voldoen aan de vereisten vastgelegd door Blomert et al. (1994) (Dassek, 2016). Ondanks alle aanpassingen zijn er nog steeds enkele werkpunten aan deze test. Zo blijkt de interne consistentie nog te laag, wat zorgt voor een lage betrouwbaarheid. Daarnaast
8
wordt een lage correlatie bekomen bij de interbeoordelaarsbetrouwbaarheid. Bijkomend is er nog steeds twijfel over welke nieuwe scenario’s opgenomen dienen te worden en welke testinstructies het meest begrijpelijk zijn (Zwartjens, 2017). Omwille van deze redenen is deze test nog niet verkrijgbaar op de markt.Tot slot wordt de Scenariotest (Van der Meulen, Van Gelder-Houthuizen, Wiegers, Wielaert en Van de Sandt-Koenderman, 2008) besproken. Deze test beoordeelt zowel de verbale als non-verbale discourse van afasiepatiënten. Tijdens testafname worden alle mogelijke communicatieve kanalen toegelaten, waaronder de mondelinge, schriftelijke, alternatieve communicatie en non-verbale vaardigheden. Tijdens testafname neemt de testleider bovendien de rol op van ondersteunende gesprekspartner. In totaal worden zes scenario’s voorgelegd, telkens met drie opeenvolgende items die bestaan uit een tekening en een auditief aangeboden tekst. Indien nodig wordt de tekst ook ondersteund door middel van gebaren. De patiënt dient duidelijk te maken hoe hij of zij zou reageren. De test neemt toe in moeilijkheidsgraad door te variëren in hoeveelheid en abstractie van de informatie die doorgegeven dient te worden. Scoring gebeurt aan de hand van een vierpuntenschaal (score nul tot en met score drie). Hoe lager de score, hoe meer hulp een persoon nodig heeft om informatie over te brengen. Een score van drie wijst op geen stoornis. Ook wordt onderzocht in welke mate de patiënt afhankelijk is van de gesprekspartner, alsook welke (alternatieve) communicatievormen beheerst zijn. De bekomen testresultaten kunnen de therapiekeuze ondersteunen. Net als de ANTAT maakt ook de Scenariotest gebruik van een kwalitatieve beoordelingsschaal en wordt enkel de effectiviteit van de informatieoverdracht beoordeeld. Ook deze test heeft dus enkele nadelen voor gebruik in de klinische praktijk.
De beschreven testen die voorhanden zijn om discourse te analyseren hebben elk hun tekortkomingen voor het gebruik in de klinische praktijk. Idealiter voldoet een test voor gebruik in de klinische praktijk aan volgende criteria: (1) In de praktijk wordt de voorkeur gegeven aan een kwantitatieve analyse. Deze vorm van beoordeling is, in tegenstelling tot een kwalitatieve analyse, tijdsefficiënt, weinig complex, eenvoudig normeerbaar en laat een goede inter- en intraindividuele vergelijking toe. (2) Daarnaast wordt geopteerd voor een evaluatie van zowel de effectiviteit als de efficiëntie van de informatieoverdracht. Meer specifiek dient te worden onderzocht hoe effectief en efficiënt afasiepatiënten erin slagen een boodschap over te brengen naar hun gesprekspartner, zonder rekening te houden met de vorm van de boodschap. Het is namelijk mogelijk dat afasiepatiënten, ondanks uitval van microlinguïstische taalaspecten, er toch in slagen hun boodschap effectief en efficiënt over te brengen naar hun communicatiepartner. Anderzijds kan het ook zijn dat ze hier net niet in slagen, ondanks goed behoud van microlinguïstisch functioneren. (3) Ten slotte is ook de keuze in uitlokkingsstimulus van discourse van belang. Verschillende stimuli stellen namelijk andere cognitieve en linguïstische eisen (Nicholas en Brookshire, 1993; Brady, Armstrong en Mackenzie., 2005; Bliss en McCabe, 2006; Fergadiotis, Wright en Capilouto, 2011). Zo zou het gebruik van sequentiële afbeeldingen een bredere woordenschat en grotere diversiteit in syntactische structuren uitlokken dan conversatie of spontane taal (Beeke, Wilkinson en Maxim, 2003; Mayer en Murray, 2003; Bliss en McCabe, 2006). Deze taak zorgt bovendien ook voor een meer geïsoleerd beeld van de effecten van afasie op discourse, los van andere cognitieve stoornissen. In de klinische praktijk wordt ook de voorkeur gegeven aan een stimulus die weinig ruimte
9
laat tot afdwaling. Voorbeelden van dergelijke stimuli zijn sequentiële afbeeldingsstimuli en het beschrijven van een procedure.Een test die over bovengenoemde eigenschappen beschikt, is de Main Concept Analysis (MCA; Kong, 2009). De MCA werd ontwikkeld met als doel de effectiviteit en efficiëntie van de informatieoverdracht tijdens verbale discourseproductie te kwantificeren bij afasiepatiënten. Kong (2009) besliste bij het ontwikkelen van de MCA, zich te baseren op de ‘main concepts’ van Nicholas en Brookshire (1995). Een main concept wordt door hen gedefinieerd als ‘a statement that provides an outline of the gist or essential information portrayed in the stimulus pictures or an outline of the essential steps in the procedure… and should contain one and only one main verb’. Bij het hanteren van deze werkwijze worden taalstalen beoordeeld op basis van de aanwezigheid, accuraatheid en volledigheid van main concepts. Vier beoordelingscategorieën werden hierbij vooropgesteld: accuraat en compleet (AC), accuraat en incompleet (AI), inaccuraat (IN) en afwezig (AB). Kong voegde hier bovendien nog twee parameters aan toe: de ‘main concept score (MCS)’ (3xAC+2xAI+IN), welke correleert met de effectiviteit van de informatieoverdracht, en het aantal AC/min, een parameter die correleert met de efficiëntie van de informatieoverdracht. De MCA werd oorspronkelijk ontwikkeld voor het Cantonees. Ondertussen zijn de vertaling en normering reeds voorhanden in het Amerikaans-Engels (Kong, Whiteside en Bargmann, 2016) en het Taiwanees-Mandarijns (Kong en Yeh, 2015). Voor de talen Iers-Engels, Spaans, Japans, Perzisch en Portugees is het proces van vertaling en normering nog aan de gang. Wegens de voordelen van de MCA ten opzichte van de huidig beschikbare Nederlandstalige testen, wordt de vertaling en normering van deze test voor gezonde, Nederlandstalige personen vooropgesteld als doel van dit onderzoek. Hierbij worden volgende onderzoeksvragen geformuleerd: ‘Welke main concepts van de originele Main Concept Analysis (Kong, 2009) worden behouden in de Nederlandstalige versie?’ en ‘Wat zijn de leeftijdsspecifieke normatieve data van de Main Concept Analysis voor gezonde, Nederlandstalige personen’. Uitgaande van bovenstaande bevindingen omtrent leeftijd en educatie kan verwacht worden dat deze invloeden zichtbaar zullen zijn in de normatieve data van de Main Concept Analysis (MCA; Kong, 2009). Deze worden dan ook bepaald binnen verschillende leeftijdscategorieën (jong: 20-39 jaar, middel: 40-59 jaar en oud: 60-79 jaar). Daarnaast wordt het effect nagegaan van de educatieniveaus (midden- en hooggeschoolden) op de bekomen normatieve data. Volgende subonderzoeksvragen kunnen gesteld worden: (1) ‘Zijn er significante verschillen in normatieve data voor de Nederlandstalige MCA tussen de drie leeftijdsgroepen (20-39 jaar, 40-59 jaar en 60-79 jaar)?’ (2) ‘Zijn er significante verschillen in MCA-scores tussen midden- en hooggeschoolden?’
3. Methode
3.1. Proefpersonen
Voor de vertaling en normering van de Main Concept Analysis werden 60 gezonde Nederlandse moedertaalsprekers gerekruteerd, waarvan twintig binnen elk van de volgende drie leeftijdscategorieën: 20-39 jaar (jong), 40-59 jaar (midden) en 60-79 jaar (oud). De gemiddelde leeftijd binnen deze
10
leeftijdscategorieën bedroeg respectievelijk 26,75 jaar (SD=5,495), 50,95 jaar (SD=4,513) en 68,10 jaar (SD=5,139). Binnen elke leeftijdscategorie werden telkens tien mannen en tien vrouwen geselecteerd. Daarenboven waren hiervan telkens vijf proefpersonen middengeschoold (hoogst behaalde diploma is een studiegetuigschrift 3e graad secundair onderwijs of een diploma hoger beroepsonderwijs) en vijf proefpersonen hooggeschoold (hoogst behaalde diploma is minstens een professionele of academische bachelor) volgens de definitie in Arvastat (bijlage 2). Het gemiddeld aantal jaren opleiding van de midden- en hooggeschoolde proefpersonen bedroeg respectievelijk 12,77 (SD=1,073) en 16,20 (SD=2,024) jaar. Uiteindelijk werden zo twaalf categorieën van telkens vijf proefpersonen bekomen op basis van geslacht, educatieniveau en leeftijd. Een visuele voorstelling hiervan werd bijgevoegd (bijlage 3). Voor de normering werden laaggeschoolden (hoogst behaalde diploma is lager dan een studiegetuigschrift 3e graad secundair onderwijs) geëxcludeerd. Deze ondergrens werd ingesteld met het oog op de toekomst. Onderzoek uitgevoerd door de Vlaamse overheid (StatBel, 2018) toonde aan dat 23% van de Vlaamse bevolking tussen 15 en 64 jaar laaggeschoold was in het jaar 2018. Het grootste deel van deze groep bevindt zich in de leeftijdscategorie tussen 55 tot 64 jaar oud. Dit valt te verklaren vanuit het feit dat kinderen sinds de jaren 70 leerplichtig waren tot de leeftijd van 16 jaar. In het jaar 1983 werd de leeftijd tot leerplicht opgetrokken tot 18 jaar. Deze gegevens impliceren dat het aantal personen dat geen diploma 3e graad secundair onderwijs behaalt, schaarser wordt.Geïncludeerde proefpersonen hadden een negatieve medische voorgeschiedenis van neurogene spraak- en taalstoornissen, neurodegeneratieve aandoeningen en psychiatrische aandoeningen. Bovendien werden ook personen met verworven of ontwikkelingsonvloeiendheden die de efficiëntie van informatieoverdracht tijdens spraak- en taalproductie kunnen verhinderen, uitgesloten. De aanwezigheid van bovenstaande aandoeningen werd bevraagd aan de hand van een anamnestische vragenlijst. Ook personen met cognitieve stoornissen, visusstoornissen en auditieve stoornissen met een inadequaat auditief begrip in een stille, afleidingsvrije omgeving als gevolg, werden geëxcludeerd uit het normeringsonderzoek. Het cognitief functioneren werd nagegaan aan de hand van de MoCA (Montreal Cognitive Assessment; Dautzenberg en De Jonghen, 2004), waarbij een cut-off score van 26/30 werd gehanteerd (Nasreddine et al., 2005). Proefpersonen dienden over een zelf gerapporteerd adequaat zicht te beschikken om de prenten te kunnen beschrijven. Gehoor werd beoordeeld aan de hand van de SSQ5 (Speech, Spatial and Qualities of hearing scale), een gehoorsscreeningsvragenlijst, waarbij een cut-off score van 7,4/10 gehanteerd werd (Mertens, Punte en Van de Heyning, 2013). Subjectgegevens met betrekking tot leeftijd, educatie, MoCA- en SSQ5-score zijn weergegeven voor elk van de twaalf subjectcategorieën op basis van leeftijd, geslacht en opleidingsniveau in tabel 1.
11
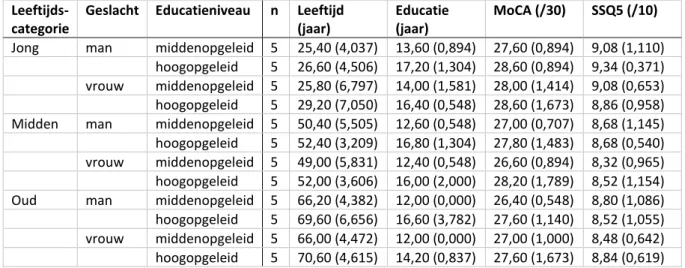
Tabel 1: Subjectgegevens per testgroep op basis van leeftijd, geslacht en educatieniveau.Leeftijds-categorie
Geslacht Educatieniveau n Leeftijd (jaar)
Educatie (jaar)
MoCA (/30) SSQ5 (/10) Jong man middenopgeleid 5 25,40 (4,037) 13,60 (0,894) 27,60 (0,894) 9,08 (1,110)
hoogopgeleid 5 26,60 (4,506) 17,20 (1,304) 28,60 (0,894) 9,34 (0,371) vrouw middenopgeleid 5 25,80 (6,797) 14,00 (1,581) 28,00 (1,414) 9,08 (0,653) hoogopgeleid 5 29,20 (7,050) 16,40 (0,548) 28,60 (1,673) 8,86 (0,958) Midden man middenopgeleid 5 50,40 (5,505) 12,60 (0,548) 27,00 (0,707) 8,68 (1,145) hoogopgeleid 5 52,40 (3,209) 16,80 (1,304) 27,80 (1,483) 8,68 (0,540) vrouw middenopgeleid 5 49,00 (5,831) 12,40 (0,548) 26,60 (0,894) 8,32 (0,965) hoogopgeleid 5 52,00 (3,606) 16,00 (2,000) 28,20 (1,789) 8,52 (1,154) Oud man middenopgeleid 5 66,20 (4,382) 12,00 (0,000) 26,40 (0,548) 8,80 (1,086) hoogopgeleid 5 69,60 (6,656) 16,60 (3,782) 27,60 (1,140) 8,52 (1,055) vrouw middenopgeleid 5 66,00 (4,472) 12,00 (0,000) 27,00 (1,000) 8,48 (0,642) hoogopgeleid 5 70,60 (4,615) 14,20 (0,837) 27,60 (1,673) 8,84 (0,619) Noot. MoCA = Montreal Cognitive Assessment; SSQ5 = Speech, Spatial, and Qualities of hearing Scale: 5-item versie; Weergegeven waarden voor leeftijd, educatie, MoCA- en SSQ5-score zijn gemiddelde (standaarddeviatie)
3.2. Data-collectie
Testafname bestond uit een screeningsfase en een eigenlijke testfase. Tijdens de screeningsfase werden respectievelijk de anamnestische vragenlijst, SSQ5 en MoCA afgenomen. De eigenlijke testfase omvatte de afname van de MCA zelf en vond plaats in een stille omgeving met minimale afleiding. Tijdens deze fase kreeg de proefpersoon vier sets van telkens vier opeenvolgende zwart-wit lijntekeningen (bijlage 4) met een afmeting van 15 cm op 21 cm aangeboden, welke men gevraagd werd te beschrijven. De vier afbeeldingen van elke set werden steeds simultaan aangeboden van links naar rechts. De deelnemers werden vooraf geïnformeerd dat deze afbeeldingen een sequentie vormen en met elkaar in verband staan. De vier afbeeldingssets werden steeds in dezelfde volgorde afgenomen. De afname van de MCA werd steeds gefilmd met een videorecorder (Sony HDR-CX305E).
Tijdens de testafname werden volgende standaardinstructies (Kong, 2009) gehanteerd:
- ‘U mag kijken naar deze vier afbeeldingen van links naar rechts’ (onderzoeker wijst de vier afbeeldingen aan). ‘Kan u mij vertellen wat er gebeurt op deze afbeeldingen? Wanneer u opmerkingen heeft op de afbeeldingen zelf, probeer er dan tijdens de testafname niet op in te gaan. Na de testafname krijgt u tijd om deze mede te delen.’
- De onderzoeker spoort de proefpersoon indien nodig aan om volzinnen te gebruiken.
- De onderzoeker onderbreekt de proefpersoon niet indien deze de beschrijving van een main concept overslaat.
- Wanneer onvoldoende informatie wordt gegeven door de proefpersoon, kan de onderzoeker enkel algemene hints geven zoals: ‘Wat gebeurt er hier?’, ‘Kan je mij hier iets meer over vertellen?’, terwijl men wijst naar het specifieke object of personage. Ook simpele non-verbale cues kunnen volstaan ter aanmoediging indien de proefpersoon stopt in het midden van een beschrijving.
12
- Tijdens het geven van hints geeft de onderzoeker geen informatie over de accuraatheid van de geproduceerde uitingen. Wanneer de proefpersoon een fout maakt, worden geen cues gegeven die ertoe kunnen leiden dat de proefpersoon zijn uiting aanpast.- Wanneer de testleider merkt dat de proefpersoon niet duidelijk ziet of begrijpt wat er gebeurt op de afbeelding (bv. het vallen van het bolletje ijs (set 3)/De man draagt twee verschillende sokken (set 2)), mag deze hiernaar wijzen ter verduidelijking.
- Tijdens de testafname worden geen pauzes ingelast. Wanneer de proefpersoon zelf duidelijk aangeeft klaar te zijn of niets meer te willen toevoegen aan de beschrijving, kan worden overgeschakeld naar de volgende set of wordt de testafname afgerond.
3.3. Data-analyse
Tijdens de fase van de data-analyse werd een tweeledig doel vooropgesteld. Enerzijds werd op basis van de taalstalen van de 60 proefpersonen een Nederlandstalig MCA-scoreformulier opgesteld. Anderzijds werd het originele scoringsprotocol (Kong, 2009) zo aangepast dat ook in de Nederlandstalige versie van de MCA een degelijke interbeoordelaarsbetrouwbaarheid gegarandeerd kan worden. Om deze doelen te bekomen werden verschillende stappen doorlopen. Deze worden verder uitgediept.
Fase 1: Vertaling Engelstalige scoreformulier naar het Nederlands
Het scoreformulier van de Engelstalige versie van de MCA, bestaande uit 26 main concepts, werd in eerste instantie vertaald naar het Nederlands aan de hand van een heen- en terugvertaling. Op dit moment werden de 26 originele main concepts zonder aanpassing behouden in het Nederlands.
Fase 2: Transcriptie en scoring aan de hand van het originele scoreformulier
De taalstalen bekomen bij afname van de MCA werden bij elk van de vier afbeeldingssets van iedere proefpersoon orthografisch getranscribeerd voor verdere analyse. Dit gebeurde door twee onderzoekers, die elk de taalstalen van de door zichzelf geteste proefpersonen transcribeerden. Elke onderzoeker transcribeerde zodoende de taalstalen van de helft van de proefpersonen. Vervolgens werden de taalstalen voor een eerste keer beoordeeld op basis van het originele, uit het Engels vertaalde scoreformulier. Dit gebeurde aan de hand van de vier vastgestelde categorieën (Kong, 2009) die de accuraatheid en volledigheid van de main concepts nagaan: AC, AI, IN en AB.
Fase 3: Opstelling van een finaal Nederlandstalig scoreformulier
De derde fase van de data-analyse bestond uit de opmaak van het finale Nederlandstalige scoreformulier. Uit de eerste scoring a.d.h.v. het originele scoreformulier (fase 2) bleek namelijk dat een groot aantal van de originele main concepts, verkregen uit de heen- en terugvertaling, door minder dan 75% van de proefpersonen AC werd geproduceerd. Naar analogie met Kong (2009) en Kong et al. (2016) werd dit percentage als criterium gesteld voor de inclusie van een main concept in de finale Nederlandstalige versie. Om deze main concepts te bekomen, werd een codeboek opgesteld voor elk van de vier afbeeldingssets waarin alle door de proefpersonen geproduceerde uitingen werden opgelijst. Bij deze oplijsting werden volgende regels gehanteerd:
13
- Samengestelde zinnen werden gesplitst. Bijvoorbeeld set 1: ‘De vrouw snijdt wortelen en snijdtin haar vinger.’ wordt: ‘De vrouw snijdt wortelen.’ en ‘De vrouw snijdt in haar vinger.’
- Wanneer een proefpersoon een zin uitte die reeds in het codeboek stond omdat deze ook door een andere proefpersoon geproduceerd werd, werd deze niet opnieuw opgenomen in de lijst. - Wanneer een proefpersoon een zin uitte die reeds geproduceerd werd door een andere
proefpersoon, maar een uitbreiding bevatte, werd deze uitbreiding wel opgenomen in de lijst. Bijvoorbeeld set 1: ‘de vrouw snijdt wortelen’ vs. ‘de vrouw snijdt wortelen met een mes’. - Wanneer een proefpersoon een referent gebruikte, maar het onderwerp vooraf reeds
gedefinieerd werd, werd deze referent in het codeboek vervangen door het vooraf gedefinieerde onderwerp. Bijvoorbeeld set 1: ‘De vrouw snijdt wortelen. Ze snijdt in haar vinger.’ wordt opgenomen als: ‘De vrouw snijdt wortelen.’ en ‘De vrouw snijdt in haar vinger.’
- Wanneer een proefpersoon een referent gebruikte zonder deze vooraf gedefinieerd te hebben, werd de refererende term opgenomen in het codeboek. Bijvoorbeeld set 1: Wanneer de proefpersoon de uiting ‘Ze snijdt wortelen.’ produceerde zonder ‘ze’ vooraf te definiëren, werd de uiting zo opgenomen in het codeboek.
Na het opstellen van de initiële lijst met uitingen, werd bepaald welke woorden golden als synoniemen (bijvoorbeeld set 1: de vrouw, mevrouw, de dame… werden als synoniem opgenomen). Deze woorden werden vervolgens in het codeboek vervangen door één term (‘de vrouw’). Bovendien werden ook alle duidelijke refererende termen vervangen door hun referent. Door het toepassen van deze regels werden verschillende identieke zinnen verkregen in het codeboek, die herleid konden worden tot één zin. Tot slot werden in alle zinnen in het codeboek de werkwoorden en zelfstandige naamwoorden onderlijnd die bijdroegen tot het main concept.
Na de opstelling van het codeboek voor een volledige afbeeldingsset, werd het taalstaal van elke proefpersoon opnieuw gescoord op basis van dit codeboek. Voor elke proefpersoon werd met andere woorden aangeduid welke van de uitingen in het codeboek werd geproduceerd. Als regel werd hierbij gehanteerd dat zowel de uiting die letterlijk geproduceerd werd, alsook algemenere uitingen, werden aangeduid. Wanneer een persoon bijvoorbeeld de zin ‘De oude vrouw snijdt wortelen’ produceerde, werden volgende uitingen aangeduid in het codeboek: ‘De vrouw’, ‘De oude vrouw’, ‘De vrouw snijdt’, ‘De oude vrouw snijdt’, ‘De vrouw snijdt wortelen’, ‘De oude vrouw snijdt wortelen’, ‘De vrouw snijdt groenten’, ‘De oude vrouw snijdt groenten’. Vervolgens werd voor elk van de uitingen in het codeboek nagegaan door hoeveel procent van de proefpersonen die werden geproduceerd. Uitingen die door 75% van de proefpersonen werden geproduceerd, werden opgenomen als main concepts in het finale Nederlandstalige scoreformulier. Hierbij werd de door Nicholas en Brookshire (1995) vooropgestelde definitie van een main concept aangehouden. Uitingen moesten met andere woorden één enkel hoofdwerkwoord (onderlijnd en vet) en twee of meer delen van essentiële informatie (onderlijnd) bevatten opdat ze als main concept werden opgenomen.
14
Fase 4: Evaluatie origineel scoringsprotocolNa het verkrijgen van het finale Nederlandstalige scoreformulier, werd het taalstaal van elke proefpersoon opnieuw gescoord naar accuraatheid en compleetheid aan de hand van de vier vooropgestelde beoordelingscategorieën: AC, AI, IN en AB. Tijdens deze scoring werd het scoreprotocol vooropgesteld door Kong (2009) gehanteerd. Om na te gaan of dit originele scoringsprotocol ook in het Nederlands voldeed om een eenduidige en betrouwbare scoringswijze te garanderen, werd de interbeoordelaarsbetrouwbaarheid van deze scoring nagegaan. Hiervoor werd de helft van de taalstalen van elke onderzoeker door de andere onderzoeker geherevalueerd. Meer specifiek evalueerde beoordelaar A 15 van de 30 subjecten van beoordelaar B en omgekeerd. Deze proefpersonen werden ad random geselecteerd door middel van SPSS Statistics 25. De interbeoordelaarsbetrouwbaarheid voor de beoordelingsparameters (AC, AI, IN, AB) werd nagegaan voor elk van de vier afbeeldingssets. Op basis van deze evaluatie bleek dat aan de hand van het originele scoringsprotocol geen degelijke interbeoordelaarsbetrouwbaarheid kon gegarandeerd worden voor de Nederlandstalige MCA. Vooral wat betreft het toekennen van de scores ‘accuraat maar incompleet’ en ‘inaccuraat’ werd voor enkele sets een slechte tot behoorlijke intraclass correlatiecoëfficient (ICC) weerhouden. Hierop werden enkele veranderingen doorgevoerd aan het originele scoringsprotocol (Kong, 2009). Volgende regels werden toegevoegd:
- Het gebruik van de termen ‘de persoon’ en ‘iemand’ als referentie naar het onderwerp worden als AI gescoord gezien dit het geslacht van het onderwerp niet aanduidt. Bijvoorbeeld set 2, MC 1: De uiting ‘De persoon wordt wakker.’ wordt als AI gescoord gezien dit niet definieert of het over een man of vrouw gaat.
- Het gebruik van eigennamen wordt steeds als AI gescoord, tenzij het onderwerp bij deze eigennaam ook verder gedefinieerd wordt. Bijvoorbeeld set 1, MC 1:
o ‘Mariëtte snijdt wortelen.’ wordt gescoord als accuraat maar incompleet. o ‘Mariëtte is een oude vrouw die wortelen snijdt.’ wordt gescoord als AC.
- Dialectinvloed is streekgebonden en wordt dan ook door de onderzoeker zelf geëvalueerd. Bijvoorbeeld set 1, MC 4: ‘De vrouw kleeft een sticker rond haar vinger.’ werd door beoordelaar A als AC gescoord, terwijl beoordelaar B dit als IN scoorde. Volgens beoordelaar A kon het woord ‘sticker’ als dialectisch synoniem van het woord ‘pleister’ geïnterpreteerd worden, terwijl beoordelaar B dit als een inaccurate benoeming interpreteerde.
- Bij bepaalde specifieke main concepts was onenigheid tussen de onderzoekers omtrent de scoring van bepaalde begrippen/uitingen. Hierop werd een uitgebreid scoringsmodel uitgewerkt dat per main concept voorbeelden van AC, AI en IN uitingen aanbiedt. Dit model is toegevoegd aan het scoringsprotocol in bijlage 5. Enkele voorbeelden van de hierin vastgelegde scoringsregels worden ook hier aangehaald:
o Set 1, MC 3: ‘De vrouw gaat naar de EHBO-kast’: Elke uiting met het begrip ‘verzorgen’ (bv. ‘De vrouw gaat zich verzorgen.’/‘De vrouw neemt iets om zich te verzorgen.’) wordt als AI gescoord.
15
o Set 1, MC 4: ‘De vrouw kleeft een pleister rond haar vinger.’: Het begrip ‘verband’ wordtals IN gescoord.
o Set 2, MC 2: ‘De man/hij kamt zijn haar.’: Gebruik van de begrippen ‘zijn toilet maken’ of ‘zich klaarmaken’, wordt als AI gescoord.
o Set 4, MC 6: ‘De oude man bedankt de jongen.’. Gebruik van de werkwoorden ‘blij zijn’/’tevreden zijn’ wordt als AI gescoord.
Fase 5: Scoring aan de hand van het finaal scoreformulier en scoringsprotocol
Met aandacht voor de doorgevoerde veranderingen aan het scoringsprotocol werden de taalstalen van de 60 proefpersonen een laatste maal gescoord op basis van het finale Nederlandstalige scoreformulier. De uitingen van de proefpersonen werden opnieuw beoordeeld naar accuraatheid en compleetheid van main concepts met behulp van de vier vooropgestelde beoordelingscategorieën. Het aantal AC, AI, IN en AB main concepts werd per afbeeldingsset nagegaan. Ook het totaal aantal geproduceerde AC, AI, IN en AB main concepts werd door optelling van de vier afbeeldingssets bepaald. Bovendien werd per afbeeldingsset de MCS en het aantal geproduceerde AC/min. berekend. Voor het bekomen van de MCS werd volgende formule gehanteerd: 3xAC + 2xAI + 1xIN. Het aantal AC/min werd bepaald door het aantal geproduceerde AC per set te delen door de uitingsduur (in minuten) van diezelfde set. Dezelfde berekeningen werden toegepast om de totale MCS het totaal aantal geproduceerde AC/min. na te gaan op basis van het totaal aantal AC, AI, IN en AB main concepts. Een voorbeeld van een taalstaal met bijhorende scoring wordt gevonden in bijlage 6.
Het doel van deze finale scoring was tweeledig. Enerzijds het opstellen van leeftijdsspecifieke normwaarden voor een gezonde Nederlandstalige populatie binnen de drie vooropgestelde leeftijdscategorieën (jong, middel en oud). Anderzijds het nagaan van de inter- en intrabeoordelaarsbetrouwbaarheid van de finale versie van de Nederlandstalige MCA.
Voor het nagaan van de interbeoordelaarsbetrouwbaarheid werden opnieuw 15 van de 30 subjecten van beoordelaar A geëvalueerd door beoordelaar B en omgekeerd. De interbeoordelaarsbetrouwbaarheid van de beoordelingsparameters AC, AI, IN, AB, MCS en AC/min. werd nagegaan voor elk van de vier afbeeldingssets en voor de totaalscores. Voor het nagaan van de intrabeoordelaarsbetrouwbaarheid, herevalueerde elke onderzoeker 50% van de door zichzelf gescoorde taalstalen. De intrabeoordelaarsbetrouwbaarheid werd op twee tijdstippen nagegaan: op 1 week na de finale scoring en op 4 weken na de finale scoring. Dit gebeurde om een eventuele ‘recall bias’ te minimaliseren (Grant, Miller, Jacobson, Morag, Bedi en Carpenter, 2013; Schlager et al., 2018) en zo een hoge intrabeoordelaarsbetrouwbaarheid ook op lange termijn te garanderen.
3.4. Statistische analyse
De data werden geanalyseerd met behulp van SPSS Statistics 25. Het hoofddoel van deze studie betrof het ontwikkelen van leeftijdsspecifieke normatieve data voor de Nederlandstalige MCA. Per afbeeldingsset werden normwaarden opgesteld voor de zeven MCA-parameters: het aantal AC, AI, IN en AB main concepts, MCS, uitingsduur en aantal AC/min. Ook voor het totaal van de vier sets werden
16
voor dezelfde parameters totaalnormwaarden opgesteld. Deze werden, naar analogie met Kong en Yeh (2015), uitgedrukt volgens gemiddelde (standaarddeviatie) en de minimum-maximumrange.In deze studie werd eveneens nagegaan of de scores op de MCA verschillen al naargelang leeftijd (jong, midden of oud), educatie (midden- of hoogopgeleid) en geslacht (man of vrouw). Ten eerste werd de normaalverdeling van scores per groep steeds nagegaan aan de hand van een Shapiro-Wilktest en QQ-plot. Een p-waarde van 0,05 werd gehanteerd als ondergrens voor normaal verdeelde data. Op basis van de resultaten hiervan werd bepaald of parametrische (p>0,05) of niet-parametrische (p<0,05) testen werden uitgevoerd. Voor het totaal van de vier afbeeldingssets werden de totale MCS, totale uitingsduur en totaal aantal AC/min. vergeleken tussen de vooropgestelde (1) leeftijds-, (2) educatie- en (3) geslachtscategorieën. (1) Voor de vergelijking van de totale MCS en totale uitingsduur tussen de drie vooropgestelde leeftijdscategorieën (jong, middel en oud) werd een niet-parametrische Kruskal-Wallistest uitgevoerd. Vergelijking van het totaal aantal geproduceerde AC/min. gebeurde aan de hand van een parametrische Brown-Forsythe ANOVA. Post-hoc werd geopteerd voor een Tamahane T2-test gezien de varianties op basis van de Levene’s test niet gelijk bleken binnen de drie leeftijdscategorieën (p=0,019). (2) De vergelijking tussen midden- en hoogopgeleiden gebeurde voor totale MCS door middel van de ongepaarde Student’s t-test. Voor de vergelijking van totale uitingsduur en totaal aantal AC/min. tussen de twee educatieniveaus werd een Mann-Whitney U-test uitgevoerd. (3) De totale MCS en totaal aantal AC/min. werd vergeleken tussen mannen en vrouwen aan de hand van een ongepaarde Student’s t-test. Voor de vergelijking van totale uitingsduur tussen de twee geslachtsgroepen werd een Mann-Whitney U-test uitgevoerd.
Indien significante verschillen werden vastgesteld tussen de verschillende leeftijdscategorieën wat de totale MCS, totale uitingsduur en het totaal aantal AC/min. betreft, werd bijkomstig nagegaan op welke afbeeldingssets deze significante verschillen konden worden weerhouden. Een niet-parametrische Kruskal-Wallistest werd hierop uitgevoerd voor de vergelijking van de MCS en het aantal geproduceerde AC/min. tussen de drie leeftijdscategorieën in elk van de vier afzonderlijke afbeeldingssets. Significante resultaten werden verder post-hoc geanalyseerd aan de hand van een Dunn-Bonferronitest om de specifieke aard van de vastgestelde verschillen te achterhalen.
Om de inter- als intrabeoordelaarsbetrouwbaarheid na te gaan voor alle MCA-parameters werd telkens een two-way mixed intraclass correlatiecoefficiënttest uitgevoerd. Deze test werd nagegaan voor elk van de scoringsparameters (AC, AI, IN, AB, MCS, uitingsduur, AC/min.) per afbeeldingsset en voor de totaalscores.
17
4. Resultaten
4.1. Nederlandstalig scoreformulier
Op basis van de taalstalen van de 60 proefpersonen, verkregen door de afname van de MCA, werd een Nederlandstalig scoreformulier (bijlage 7) opgesteld. De Nederlandstalige MCA bestaat uit 19 main concepts verdeeld over vier afbeeldingssets. Dit zijn er zeven minder dan de originele MCA (Kong, 2009). De opgenomen main concepts zijn opgebouwd uit uitingen die door 75% of meer van de proefpersonen als AC werden geproduceerd. Gezien de grote variabiliteit in de gebruikte woordenschat door de proefpersonen, werden meerdere synoniemen en gelijkaardige betekenissen als AC opgenomen in de main concepts. Een oplijsting van de verkregen main concepts per afbeeldingsset en hun accurate en complete alternatieven is weergegeven in bijgevoegd scoringsprotocol (bijlage 5). In wat volgt, worden de voornaamste verschillen besproken tussen het scoreformulier van de originele versie van de MCA en de Nederlandstalige versie.
Wat de eerste afbeeldingsset betreft, bevat de Nederlandstalige versie vier main concepts. Dit is er één minder dan de originele versie. Het main concept ‘De vinger van de oude vrouw bloedt.’ werd door minder dan 75% van de proefpersonen geproduceerd en werd dan ook niet opgenomen in de Nederlandstalige versie. Ook set 2 bevat met zijn vijf main concepts in de Nederlandstalige MCA één main concept minder dan de originele versie. Om te komen tot de vooropgestelde 75%, werden de twee main concepts uit de originele versie ‘De man wordt wakker.’ en ‘De man schrikt/is laat.’ samengevoegd tot ‘De man/hij staat op/ schrikt wakker/ wordt wakker/ overslaapt zich.’. Het grootste verschil tussen de originele en Nederlandstalige MCA werd gevonden in set 3: waar set 3 in de originele versie negen main concepts bevat, zijn dit er in de Nederlandstalige versie slechts vier. De vijf ontbrekende main concepts zijn: ‘Het meisje wil/vraagt een ijsje.’, ‘De man schept een ijs op een hoorntje.’, ‘Het meisje weent/is droevig.’, ‘De man kijkt naar het meisje.’ en ‘Het meisje lacht/is blij’. Set 4 bestaat zowel in de originele als in de Nederlandstalige versie uit zes main concepts. Toch zijn de twee versies ook voor deze set niet volledig identiek. In de Nederlandstalige versie werd het main concept ‘De boodschappentas scheurt/is stuk.’ toegevoegd maar bleek het main concept ‘De jongen ziet wat er gebeurt.’ niet door 75% van de proefpersonen geproduceerd te worden.
4.2. Normering
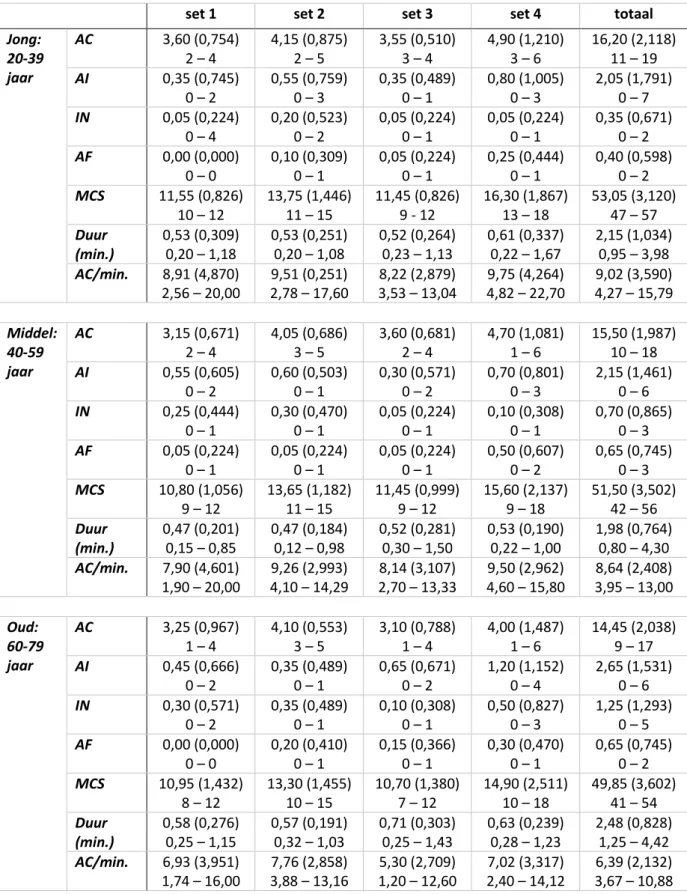
De taalstalen van de 60 proefpersonen werden vervolgens gescoord aan de hand van het verkregen Nederlandstalige scoreformulier en scoringsprotocol. De aanwezigheid, accuraatheid en compleetheid van de main concepts werd nagegaan. Op basis van deze scores werden normatieve data verkregen voor gezonde Nederlandstalige proefpersonen voor elk van de drie vooropgestelde leeftijdscategorieën. Normatieve data van het aantal AC, AI, IN en AB main concepts, MCS, uitingsduur en aantal AC/min. zijn voor elke afzonderlijke afbeeldingsset en voor totaalscores weergegeven in tabel 2.
18
Tabel 2: Leeftijdsspecifieke normatieve data voor MCA-parameters per leeftijdscategorie (jong - middel - oud) voor elke afbeeldingsset en totaalscore.set 1 set 2 set 3 set 4 totaal
Jong: 20-39 jaar AC 3,60 (0,754) 2 – 4 4,15 (0,875) 2 – 5 3,55 (0,510) 3 – 4 4,90 (1,210) 3 – 6 16,20 (2,118) 11 – 19 AI 0,35 (0,745) 0 – 2 0,55 (0,759) 0 – 3 0,35 (0,489) 0 – 1 0,80 (1,005) 0 – 3 2,05 (1,791) 0 – 7 IN 0,05 (0,224) 0 – 4 0,20 (0,523) 0 – 2 0,05 (0,224) 0 – 1 0,05 (0,224) 0 – 1 0,35 (0,671) 0 – 2 AF 0,00 (0,000) 0 – 0 0,10 (0,309) 0 – 1 0,05 (0,224) 0 – 1 0,25 (0,444) 0 – 1 0,40 (0,598) 0 – 2 MCS 11,55 (0,826) 10 – 12 13,75 (1,446) 11 – 15 11,45 (0,826) 9 - 12 16,30 (1,867) 13 – 18 53,05 (3,120) 47 – 57 Duur (min.) 0,53 (0,309) 0,20 – 1,18 0,53 (0,251) 0,20 – 1,08 0,52 (0,264) 0,23 – 1,13 0,61 (0,337) 0,22 – 1,67 2,15 (1,034) 0,95 – 3,98 AC/min. 8,91 (4,870) 2,56 – 20,00 9,51 (0,251) 2,78 – 17,60 8,22 (2,879) 3,53 – 13,04 9,75 (4,264) 4,82 – 22,70 9,02 (3,590) 4,27 – 15,79 Middel: 40-59 jaar AC 3,15 (0,671) 2 – 4 4,05 (0,686) 3 – 5 3,60 (0,681) 2 – 4 4,70 (1,081) 1 – 6 15,50 (1,987) 10 – 18 AI 0,55 (0,605) 0 – 2 0,60 (0,503) 0 – 1 0,30 (0,571) 0 – 2 0,70 (0,801) 0 – 3 2,15 (1,461) 0 – 6 IN 0,25 (0,444) 0 – 1 0,30 (0,470) 0 – 1 0,05 (0,224) 0 – 1 0,10 (0,308) 0 – 1 0,70 (0,865) 0 – 3 AF 0,05 (0,224) 0 – 1 0,05 (0,224) 0 – 1 0,05 (0,224) 0 – 1 0,50 (0,607) 0 – 2 0,65 (0,745) 0 – 3 MCS 10,80 (1,056) 9 – 12 13,65 (1,182) 11 – 15 11,45 (0,999) 9 – 12 15,60 (2,137) 9 – 18 51,50 (3,502) 42 – 56 Duur (min.) 0,47 (0,201) 0,15 – 0,85 0,47 (0,184) 0,12 – 0,98 0,52 (0,281) 0,30 – 1,50 0,53 (0,190) 0,22 – 1,00 1,98 (0,764) 0,80 – 4,30 AC/min. 7,90 (4,601) 1,90 – 20,00 9,26 (2,993) 4,10 – 14,29 8,14 (3,107) 2,70 – 13,33 9,50 (2,962) 4,60 – 15,80 8,64 (2,408) 3,95 – 13,00 Oud: 60-79 jaar AC 3,25 (0,967) 1 – 4 4,10 (0,553) 3 – 5 3,10 (0,788) 1 – 4 4,00 (1,487) 1 – 6 14,45 (2,038) 9 – 17 AI 0,45 (0,666) 0 – 2 0,35 (0,489) 0 – 1 0,65 (0,671) 0 – 2 1,20 (1,152) 0 – 4 2,65 (1,531) 0 – 6 IN 0,30 (0,571) 0 – 2 0,35 (0,489) 0 – 1 0,10 (0,308) 0 – 1 0,50 (0,827) 0 – 3 1,25 (1,293) 0 – 5 AF 0,00 (0,000) 0 – 0 0,20 (0,410) 0 – 1 0,15 (0,366) 0 – 1 0,30 (0,470) 0 – 1 0,65 (0,745) 0 – 2 MCS 10,95 (1,432) 8 – 12 13,30 (1,455) 10 – 15 10,70 (1,380) 7 – 12 14,90 (2,511) 10 – 18 49,85 (3,602) 41 – 54 Duur (min.) 0,58 (0,276) 0,25 – 1,15 0,57 (0,191) 0,32 – 1,03 0,71 (0,303) 0,25 – 1,43 0,63 (0,239) 0,28 – 1,23 2,48 (0,828) 1,25 – 4,42 AC/min. 6,93 (3,951) 1,74 – 16,00 7,76 (2,858) 3,88 – 13,16 5,30 (2,709) 1,20 – 12,60 7,02 (3,317) 2,40 – 14,12 6,39 (2,132) 3,67 – 10,88
Noot. AC= aantal accurate en complete main concepts, AI= aantal accurate en incomplete main concepts, IN = aantal inaccurate main concepts, AB = aantal afwezige main concepts, MCS = main concept score, AC/min. = aantal accurate en complete main concepts per minuut; MCS = 3xAC + 2xAI + 1xIN; Weergegeven waarden zijn gemiddelde (standaarddeviatie) en minimum-maximumrange.
19
4.3. Vergelijking van de MCA-scores tussen vooropgestelde leeftijds-, educatie-
en geslachtscategorieën
Effect van leeftijd op MCA-score
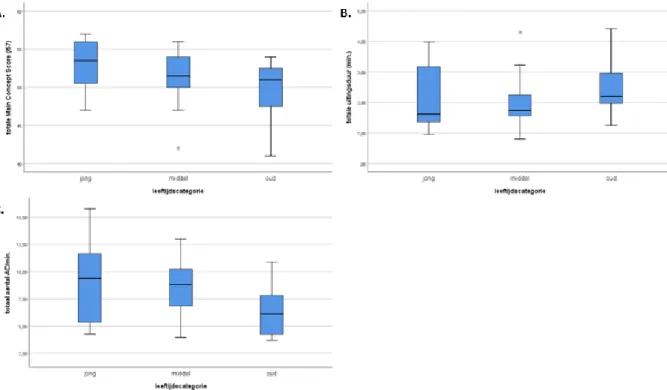
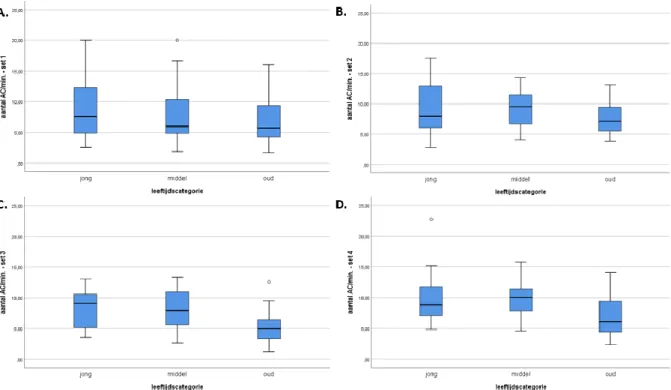
Bij de vergelijking van de totale MCS tussen de drie vastgestelde leeftijdscategorieën (jong: 20-39 jaar; middel: 40-59 jaar; oud: 60-79 jaar) wees de Kruskal-Wallistest op een significant effect van leeftijd op de totale MCS (H(2)=7,617; p=0,022). Post-hoc analyse aan de hand van de Dunn-Bonferronitest toonde een significant verschil aan tussen de jonge en oude leeftijdscategorie. De totale MCS van personen uit de jonge leeftijdscategorie (Mediaan(IQR)=53,5(50,25-56,00)) was significant hoger dan deze van personen in de oude leeftijdscategorie (Mediaan(IQR)=51,0(47,25-52,75); p=0,017) (figuur 1A). Met betrekking tot de totale uitingsduur werden geen significante verschillen vastgesteld tussen de drie leeftijdscategorieën (H(2)=4,898; p=0,086) (figuur 1B). Wat betreft het totaal aantal AC/min. wees de Brown-Forsythe ANOVA op een significant effect van leeftijd (F(2, 46,526)=5,221; p=0,009). Post-hoc vergelijking aan de hand van een Tamahane T2-test wees op een significant verschil tussen de jonge en oude leeftijdscategorie enerzijds en tussen de middelste en oude leeftijdscategorie anderzijds. Personen uit de jonge leeftijdscategorie produceren gemiddeld 2,63 AC/min. meer dan personen in de oudste leeftijdscategorie (p=0,025; 95%BI=0,274;4,987). Personen uit de middelste leeftijdscategorie produceren gemiddeld 2,25 AC/min. meer dan personen uit de oudste leeftijdscategorie (p=0,10; 95%BI=0,453;4,048) (figuur 1C).
Figuur 1: Grafische weergave aan de hand van een boxplot van (A) totale MCS, (B) totale uitingsduur en (C) totaal aantal AC/min. telkens per leeftijdscategorie (jong - middel - oud).
Bovenstaande resultaten duidden significante verschillen aan wat betreft de totale MCS en totaal aantal geproduceerde AC/min. tussen de drie leeftijdscategorieën. Gezien de normatieve gegevens opgesteld
20
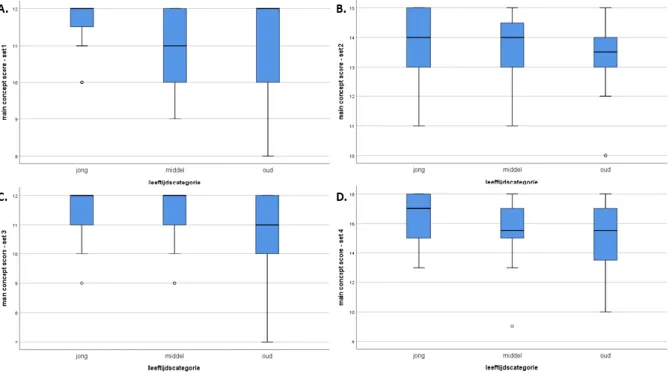
werden op basis van leeftijd, werd vervolgens nagegaan of deze verschillen specifiek terug te leiden zijn naar bepaalde afbeeldingssets. De multivariate Kruskal-Wallistest werd telkens uitgevoerd voor de vergelijking van MCS en aantal AC/min. tussen de verschillende leeftijdsgroepen binnen elk van de afbeeldingssets.Wat betreft de MCS, wees de Kruskal-Wallistest op een significant effect van leeftijd in set 1 (H(2)=6,051; p=0,049) en set 3 (H(2)=6,685; p=0,035). Een post-hoc Dunn-Bonferronitest toonde een significant verschil aan tussen de middelste (Mediaan(IQR)=11,0(10,00-12,00)) en oude leeftijdscategorie (Mediaan(IQR)=12,0(10,00-12,00); p=0,043) in set 1 (figuur 2A). Voor set 3 werden post-hoc geen specifieke verschillen weerhouden (figuur 2C). In set 2 (H(2)=1,656; p=0,437) en set 4 (H(2)=3,850; p=0,146) werden geen significante verschillen vastgesteld tussen de drie leeftijdscategorieën (respectievelijk figuur 2B en 2D). Met betrekking tot het aantal geproduceerde AC/min wees een Kruskal-Wallistest op een significant effect van leeftijd in set 3 (H(2)=10,388; p=0,006) en set 4 (H(2)=7,395; p=0,025). Het aantal AC/min in set 3 geproduceerd door personen uit de oude leeftijdsgroep (Mediaan(IQR)=4,94(3,150-6,488)) was significant lager dan deze van personen in de jonge leeftijdsgroep (Mediaan(IQR)= 9,09(5,075-10,590); p=0,015). Het aantal geproduceerde AC/min in set 3 van personen uit de oude leeftijdsgroep (Mediaan(IQR)=4,94(3,150-6,488)) was bovendien ook significant lager dan dit van personen in de middelste leeftijdsgroep (Mediaan(IQR)=7,95(5,415-11,028); p=0,017) (figuur 3C). Tot slot bleek ook het aantal AC/min in set 4 geproduceerd door personen uit de oude leeftijdsgroep (Mediaan(IQR)=10,07(7,768-11,445)) significant lager dan dit van personen in de middelste leeftijdsgroep (Mediaan(IQR)=6,14(4,305-9,515); p=0,039) (figuur 3D). In set 1 (H(2)=1,656; p=0,437) en set 2 (H(2)=2,414; p=0,229) worden geen significante verschillen tussen de drie leeftijdscategorieën weerhouden (respectievelijk figuur 3A en 3B).
Figuur 2: Grafische weergave aan de hand van een boxplot van de main concept score per leeftijdscategorie (jong - middel - oud) binnen (A) afbeeldingsset 1, (B) afbeeldingsset 2, (C) afbeeldingsset 3 en (D) afbeeldingsset 4
21
Figuur 3: Grafische weergave aan de hand van boxplot van het aantal geproduceerde AC/min. per leeftijdscategorie (jong - middel - oud) binnen (A) afbeeldingsset 1, (B) afbeeldingsset 2, (C) afbeeldingsset 3 en (D) afbeeldingsset 4De significante verschillen vastgesteld in totaalscores tussen de drie leeftijdscategorieën, bleken vooral terug te leiden naar de laatste twee afbeeldingssets. Bij deze sets, die meer dan 1 actor bevatten, is de efficiëntie van de informatieoverdracht (gemeten d.m.v. het aantal AC/min.) van personen uit de oude leeftijdsgroep significant lager dan deze van personen uit de jonge en middelste leeftijdsgroep.
Effect van educatieniveau op MCA-score
Om beoogde verschillen in opleiding tussen de twee vooropgestelde educatieniveaus te objectiveren werd het aantal gevolgde opleidingsjaren en MoCA-score vergeleken tussen midden- en hoogopgeleiden aan de hand van een Mann-Whitney U-test. Hieruit bleek het aantal gevolgde jaren educatie van hoogopgeleiden (Mediaan(IQR)=16,0(15,00-17,00)) significant hoger in vergelijking met middenopgeleiden (Mediaan(IQR)=12,0(12,00-13,00); U=855,500; p<0,001). Hoogopgeleiden (Mediaan(IQR)=28,0(27,00-29,25)) scoorden bovendien significant hoger op de MoCA dan middenopgeleide proefpersonen (Mediaan(IQR)=27,0(26,00-28,00); U=629,000; p=0,007).
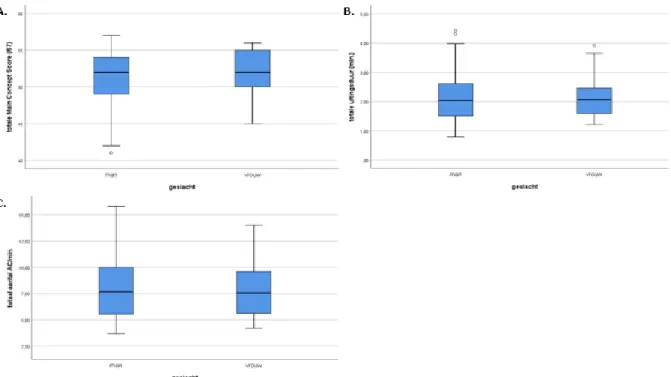
Wat betreft de totale MCS toonde vergelijking aan de hand van een ongepaarde Student’s t-test geen significante verschillen aan tussen midden- en hoogopgeleiden (t(58)=-1,596; p=0,116) (figuur 4A). Voor zowel totale uitingsduur als het totaal aantal geproduceerde AC/min. bleek door uitvoering van de Mann-Whitney U-test een significant verschil tussen de twee educatieniveaus. De totale uitingsduur van middenopgeleiden (Mediaan(IQR)=1,66(1,330-2,233) was significant lager dan deze van hoogopgeleiden (Mediaan(IQR)= 2,19(1,668-3,490); U=658,500; p=0,002) (figuur 4B). Hoogopgeleiden (Mediaan(IQR)=6,80(4,518-9,123)) produceren daarenboven significant minder AC/min. dan middenopgeleiden (Mediaan(IQR)= 8,69(6,600-11,345); U=271,000; p=0,008) (figuur 4C).
22
Middenopgeleiden zijn met andere woorden efficiënter maar niet effectiever in hun informatieoverdracht dan hoogopgeleiden.Figuur 4: Grafische weergave aan de hand van een boxplot van (A) totale MCS, (B) totale uitingsduur en (C) totaal aantal AC/min. per educatiecategorie (midden- en hoogopgeleid)
Effect van geslacht op MCA-score
Uit de vergelijking van de MCA-scores tussen mannen en vrouwen bleek op basis van een ongepaarde Student’s t-test geen significant verschil voor totale MCS (t(58)=-0,570; p=0,571) tussen mannen en vrouwen (figuur 5A). Ook op de totale uitingsduur (U=443,500; p=0,923) (figuur 5B) en het totaal aantal geproduceerde AC/min. (t(58)=0,145; p=0,885) (figuur 5C) bleek op basis van respectievelijk een Mann-Whitney U-test en ongepaarde Student’s t-test geen effect van geslacht.
23
Figuur 5: Grafische weergave aan de hand van een boxplot van (A) totale MCS, (B) totale uitingsduur en (C) totaal aantal AC/min. per geslacht (man - vrouw)Inter- en intrabeoordelaarsbetrouwbaarheid
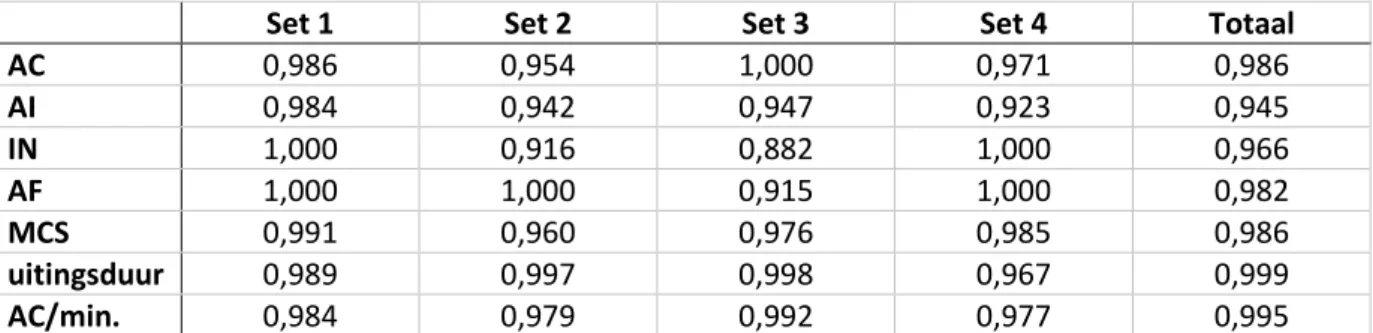
Resultaten van de two-way mixed intraclass correlation coëfficienttest voor het nagaan van de interbeoordelaarsbetrouwbaarheid zijn weergegeven in tabel 3. Een goede (ICC 0,75-0,90) tot excellente (ICC 0,90-1,00) betrouwbaarheid werd bekomen voor nagenoeg alle MCA-parameters over alle afbeeldingssets (Koo en Li, 2016). Enkel voor de beoordeling van AI en AF main concepts in set 3 wordt een moderate betrouwbaarheid (ICC 0,50-0,75) weerhouden.
Tabel 3: Interbeoordelaarsbetrouwbaarheid voor elk van de MCA-parameters per afbeeldingsset en voor totaalscores.
Set 1
Set 2
Set 3
Set 4
Totaal
AC
0,938
0,851
0,826
0,955
0,958
AI
0,963
0,843
0,658*
0,922
0,899
IN
0,838
0,887
0,794
0,882
0,844
AF
1.000
0,869
0,651*
1,000
0,943
MCS
0,900
0,896
0,833
0,980
0,971
uitingsduur
0,859
0,990
0,996
0,966
0,997
AC/min.
0,879
0,960
0,939
0,973
0,975
Noot. AC = accuraat en compleet, AI = accuraat en incompleet, IN = inaccuraat, AF = afwezig, MCS = main concept score en AC/min = aantal accurate en complete main concepts per minuut; *p=0,003, voor de andere waarden is p<0,001
Tabel 4 en 5 vormen een weergave van de intrabeoordelaarsbetrouwbaarheid op een tijdstip van respectievelijk 1 en 4 weken na initiële scoring. Voor nagenoeg alle beoordelingsparameters wordt voor alle sets een excellente betrouwbaarheid weerhouden tussen de initiële scoring en de herscoring op zowel het tijdstip van 1 week als 4 weken na initiële scoring.
24
Tabel 4: Intrabeoordelaarsbetrouwbaarheid tussen initiële scoring en herscoring 1 week na initiële scoring voor elk van de MCA-parameters per afbeeldingsset en voor totaalscores.Set 1
Set 2
Set 3
Set 4
Totaal
AC
0,986
0,954
1,000
0,971
0,986
AI
0,984
0,942
0,947
0,923
0,945
IN
1,000
0,916
0,882
1,000
0,966
AF
1,000
1,000
0,915
1,000
0,982
MCS
0,991
0,960
0,976
0,985
0,986
uitingsduur
0,989
0,997
0,998
0,967
0,999
AC/min.
0,984
0,979
0,992
0,977
0,995
Noot. AC = accuraat en compleet, AI = accuraat en incompleet, IN = inaccuraat, AF = afwezig, MCS = main concept score en
AC/min = aantal accurate en complete main concepts per minuut; p<0,001 in alle gevallen
Tabel 5: Intrabeoordelaarsbetrouwbaarheid tussen initiële scoring en herscoring 4 weken na initiële scoring voor elk van de MCA-parameters per afbeeldingsset en voor totaalscores.
Set 1
Set 2
Set 3
Set 4
Totaal
AC
0,970
0,925
0,957
0,946
0,957
AI
0,965
0,922
0,900
0,871
0,884
IN
1,000
0,916
1,000
0,838
0,951
AF
1,000
1,000
0,838
0,968
0,950
MCS
0,944
0,933
0,940
0,981
0,981
uitingsduur
0,988
0,995
0,998
0,973
0,999
AC/min.
0,980
0,974
0,973
0,945
0,987
Noot. AC = accuraat en compleet, AI = accuraat en incompleet, IN = inaccuraat, AF = afwezig, MCS = main concept score en
AC/min = aantal accurate en complete main concepts per minuut; p<0,001 in alle gevallen
5. Discussie
Dit onderzoek had tot doel de MCA (Kong, 2009), een test ontwikkeld voor het evalueren van de discoursevaardigheden van afasiepatiënten, te vertalen en normeren voor een gezonde Nederlandstalige populatie. Op basis van taalstalen van 60 gezonde proefpersonen werd in eerste instantie een Nederlandstalig scoreformulier opgesteld, waarna normatieve data op basis van dit scoreformulier werden bekomen.
Het scoreformulier van de Nederlandstalige MCA bestaat uit 19 main concepts. Dit zijn er zeven minder dan de originele, Cantonese MCA (Kong, 2009) en Engelstalige MCA (Kong et al., 2016). Het verschil met de Cantonese MCA kan mogelijks verklaard worden door de gehanteerde methode om de main concepts op te lijsten. Zo zijn de main concepts van de Cantonese MCA gebaseerd op taalstalen van acht logopedisten. Deze logopedisten kregen vooraf een training over de definitie en vorming van een main concept. Nadien werd hen gevraagd alle mogelijke main concepts per afbeelding neer te schrijven. Wanneer zes van de acht logopedisten (= 75%) een bepaalde uiting produceerden, werd deze opgenomen als main concept. Het feit dat in de Nederlandstalige versie uitgegaan wordt van 60 proefpersonen in plaats van getrainde logopedisten heeft twee implicaties: (a) Er werden geen logopedisten betrokken die een training kregen en gevraagd werden om alle mogelijke main concepts bij de afbeeldingen te produceren. Gezien de Nederlandstalige proefpersonen enkel gevraagd werden
25
te vertellen wat gebeurt op de afbeeldingen, keken zij met een andere intentie naar het stimulusmateriaal. Dit zorgde er mogelijks voor dat zij bepaalde uitingen niet noodzakelijk vonden om te vermelden. Zo werden de main concepts uit set 3 van de originele versie ‘Het meisje wil/vraagt een ijsje.’ en ‘De man kijkt naar het meisje’ slechts door respectievelijk 8% en 3% van de Nederlandstalige proefpersonen geproduceerd. (b) De acht logopedisten zijn allemaal hoogopgeleide personen. Binnen de groep van Nederlandstalige proefpersonen is er meer variatie wat educatieniveau betreft, waardoor een goede representatie van de populatie gevormd wordt. Gezien de aangetoonde effecten van educatieniveau op discourse, kan deze methodologische factor mogelijks een invloed uitoefenen op het geproduceerde aantal main concepts. Daarnaast dient vermeld te worden dat ook het type opleiding hier een rol in kan spelen: de acht logopedisten keken mogelijks met meer voorkennis van taal en van de doelpathologie afasie naar het stimulusmateriaal.Het verschil in main concepts tussen de Engelstalige en Nederlandstalige MCA, valt minder makkelijk te verklaren aangezien de gehanteerde methode van de Nederlandstalige versie gebaseerd is op de Engelstalige MCA. Twee methodologische verschillen kunnen worden weerhouden: (1) In de Engelstalige versie werd, in tegenstelling tot de Nederlandstalige MCA, geen onder- en bovengrens voor leeftijd vermeld. De verschillen in gemiddelde leeftijden over de drie groepen waren echter miniem waardoor dit gegeven mogelijks niet als verklaring kan dienen. (2) Een tweede verschil is dat de proefpersonen uit de Nederlandstalige MCA opgedeeld werden in een midden- of hoogopgeleide groep. Bij de Engelstalige versie werd dit onderscheid niet gemaakt: de proefpersonen werden enkel geëxcludeerd indien zij minder dan twaalf jaar educatie gevolgd hadden. Gezien educatieniveau een effect blijkt te hebben op discourseproductie, kan dit eventueel een gedeeltelijke verklaring vormen. Naast de gehanteerde methode, kan mogelijks het gebruikte stimulusmateriaal een alternatieve verklaring bieden voor het verschil in main concepts. Bij zowel de Engelstalige als de Nederlandstalige versie werd gebruik gemaakt van dezelfde vier sets bestaande uit telkens vier afbeeldingen. De studie van Kong et al. (2016) stelt dat de tekeningen geschikt zijn voor de Westerse cultuur. Nederlandstalige proefpersonen leken echter vaak moeite te vertonen om alle elementen, die de main concepts vormen in de Engelstalige versie, correct te herkennen en te benoemen. Zo gaf 6% van de proefpersonen aan dat de man in het begin en op het einde van set 2 niet dezelfde persoon lijkt: in de eerste twee afbeeldingen lijkt het een jonger persoon, in de laatste twee afbeeldingen lijkt het een ouder persoon. Eveneens sprak 6% van de proefpersonen in set 3 over het kind als een ‘jongen’ in plaats van een ‘meisje’. Door 8% werd dan weer aangegeven dat het in de laatste afbeelding van set 4 onvoldoende duidelijk was wie (vader of oude man) de jongen bedankt. Daarnaast lijkt niet alles duidelijk genoeg aangegeven te zijn op de tekeningen. Zo gaf 28% van de proefpersonen aan dat het moeilijk te zien is dat de man twee verschillende sokken draagt op de laatste afbeelding van set 2. 27% vermeldde dat de bol ijs die op de grond valt in set 3 eveneens onduidelijk en onvoldoende opvallend getekend is. Mogelijks zou een andere tekenstijl of tekeningen in kleur tot meer herkenning, en daardoor tot meer accurate en complete uitingen, kunnen leiden.
In tweede tijd werden, na het bekomen van een Nederlandstalig scoreformulier en scoring van de taalstalen van de proefpersonen volgens dit scoreformulier, normatieve data opgesteld. Uit vergelijking van deze normatieve data tussen de drie vooropgestelde leeftijdscategorieën (jong, middel, oud) bleken