DE ACCEPTATIE VAN INTELLIGENT
ASSISTANTS IN VLAANDEREN
Aantal woorden: 16.147
Laurens Ghyselen Stamnummer : 01600504
Promotor: Prof Dr. Els Clarysse
Masterproef voorgedragen tot het bekomen van de graad van: Master in de handelswetenschappen: management en informatica
i
Vertrouwelijkheidsclausule
Ondergetekende verklaart dat de inhoud van deze masterproef mag geraadpleegd en/of gereproduceerd worden, mits bronvermelding.
ii
Woord vooraf
Deze masterproef werd geschreven als laatste opdracht voor het behalen van de Master of Science in Handelswetenschappen met afstudeerrichting Management en Informatica.In dit werk wordt onderzoek gedaan naar de acceptatie van intelligent assistants in Vlaanderen. Het schrijven van deze thesis gebeurde in een uitzonderlijke periode: tijdens de uitbraak van COVID-19. Dit had een grote invloed op het sociaal leven gedurende enkele maanden. Voor dit werk vormde dit geen extra obstakels: alles verliep zoals gepland, er was zelfs meer tijd om te werken aan de masterproef. De zoektocht naar respondenten voor de enquête verliep extra vlot doordat veel mensen het huis nauwelijks uit mochten, en vervolgens manieren zochten om hun tijd te vullen.
Graag wil ik nog enkele mensen specifiek bedanken die hier (on)rechtstreeks bij geholpen hebben:
• Mijn promotor Prof. Dr. Els Clarysse • Mijn gezin
• Eline Dumortier • Robbe Woets
iii
Inhoudsopgave
Lijst van gebruikte afkortingen ... v
Lijst van tabellen ... vi
Lijst van figuren ... vii
1. Inleiding ...1
2. Literatuurstudie ...2
2.1. Verklarende definities ...2
2.2. Huidige marktpositie ...3
2.3. Korte geschiedenis Automatic Speech Recognition ...5
2.4. Implementaties intelligent assistants ...8
2.5. Use cases intelligent assistants ...9
2.6. Verschillende intelligent assistants ... 10
2.7. Vergelijking verschillende intelligent assistants ... 12
2.8. Veiligheid en privacy ... 13
2.9. Intelligent assistants in België ... 15
2.10. Intelligent assistants in Vlaanderen ... 15
2.11. Unified Theory of Acceptance and Use of Technology ... 16
3. Empirisch onderzoek ...30 3.1. Soort onderzoek ... 30 3.2. Onderzoeksvraag ... 30 3.3. Populatie ... 32 3.4. Steekproef ... 33 3.5. Datacollectie... 33 3.6. Vragenlijst ... 34 3.7. Factoranalyse ... 34 3.8. Betrouwbaarheid schalen ... 35 4. Resultaten ...37 4.1. Dataset ... 37
4.2. Indeling van de respondenten ... 37
4.3. Uitwerking deelvraag 1... 44
4.4. Uitwerking deelvraag 2... 47
4.5. Uitwerking deelvraag 3... 48
iv
4.7. Deelvraag 4... 62
4.8. Samenvatting alle hypotheses ... 64
5. Discussie ...66
6. Limitaties en aanbevelingen voor verder onderzoek ...68
7. Conclusie ...70
Lijst van geraadpleegde werken ... viii
Bijlagen ... xxi
Bijlage 1: Vragenlijst UTAUT2 ... xxi
Bijlage 2: Vragenlijst intelligent assistants ... xxi
Bijlage 3: Tabel factoranalyses ... xxxiv
Bijlage 4: Grafiek normale verdeling regressie deelvraag 1 ...xxxvii
v
Lijst van gebruikte afkortingen
Afkorting Betekenis
AI Artificiële intelligentie
ASR Automatic speech recognition Audrey Automatic digit recognizer C-TAM-TPB Combinatie van TAM en TPB
DARPA Defense Advanced Research Projects HMM Hidden Markov model
HTK Hidden Markov Model Toolkit IDT Innovation Diffusion Theory ML Machine learning
MM Motivation Model MPCU Model of PC Utilization NLP Natural language processing SCT Social Cognitive Theory
TAM Technology Acceptance Model TAM Technology Acceptance Model 2 TPB Theory of Planned Behavior TRA Theory of Reasoned Action
UTAUT Unified Theory of Acceptance and Use of Technology UTAUT2 Unified Theory of Acceptance and Use of Technology 2 VIF Variance Inflation Factor
VPA Virtual personal assistant
vi
Lijst van tabellen
TABEL 1:PRESTATIES INTELLIGENT ASSISTANTS (MUNSTER &THOMPSON,2019) ... 13
TABEL 2:CRONBACHS ALFA VOOR DE CONSTRUCTEN ... 36
TABEL 3:RESULTATEN REGRESSIE DEELVRAAG 1 INVLOED OP INTENTIE TOT GEBRUIK ... 45
TABEL 4:RESULTATEN REGRESSIE DEELVRAAG 2 INVLOED OP WERKELIJK GEBRUIK ... 48
TABEL 5:HYPOTHESE 3.1 MODERATOR LEEFTIJD OP RELATIE PRESTATIEVERWACHTING EN INTENTIE TOT GEBRUIK ... 49
TABEL 6:HYPOTHESE 3.1 MODERATOR GESLACHT OP RELATIE PRESTATIEVERWACHTING EN INTENTIE TOT GEBRUIK ... 49
TABEL 7:HYPOTHESE 3.3 MODERATOR LEEFTIJD OP RELATIE SOCIALE INVLOED EN INTENTIE TOT GEBRUIK ... 50
TABEL 8:HYPOTHESE 3.3 MODERATOR GESLACHT OP RELATIE SOCIALE INVLOED EN INTENTIE TOT GEBRUIK ... 51
TABEL 9:HYPOTHESE 3.3 MODERATOR ERVARING OP RELATIE SOCIALE INVLOED EN INTENTIE TOT GEBRUIK ... 51
TABEL 10:HYPOTHESE 3.4 MODERATOR LEEFTIJD OP RELATIE FACILITERENDE OMSTANDIGHEDEN EN INTENTIE TOT GEBRUIK ... 52
TABEL 11:HYPOTHESE 3.4 MODERATOR GESLACHT OP RELATIE FACILITERENDE OMSTANDIGHEDEN EN INTENTIE TOT GEBRUIK ... 52
TABEL 12:HYPOTHESE 3.4 MODERATOR ERVARING OP RELATIE FACILITERENDE OMSTANDIGHEDEN EN INTENTIE TOT GEBRUIK ... 53
TABEL 13:HYPOTHESE 3.5 MODERATOR LEEFTIJD OP RELATIE HEDONISCHE MOTIVATIE EN INTENTIE TOT GEBRUIK ... 54
TABEL 14:HYPOTHESE 3.5 MODERATOR GESLACHT OP RELATIE HEDONISCHE MOTIVATIE EN INTENTIE TOT GEBRUIK ... 54
TABEL 15:HYPOTHESE 3.5 MODERATOR ERVARING OP RELATIE HEDONISCHE MOTIVATIE EN INTENTIE TOT GEBRUIK ... 55
TABEL 16:HYPOTHESE 3.7 MODERATOR LEEFTIJD OP RELATIE GEWOONTE EN INTENTIE TOT GEBRUIK ... 56
TABEL 17:HYPOTHESE 3.7 MODERATOR GESLACHT OP RELATIE GEWOONTE EN INTENTIE TOT GEBRUIK ... 56
TABEL 18:HYPOTHESE 3.7 MODERATOR ERVARING OP RELATIE GEWOONTE EN INTENTIE TOT GEBRUIK ... 57
TABEL 19:HYPOTHESE 3.8 MODERATOR ERVARING OP RELATIE INTENTIE TOT GEBRUIK EN WERKELIJK GEBRUIK ... 57
TABEL 20:HYPOTHESE 3.9 MODERATOR LEEFTIJD OP RELATIE FACILITERENDE OMSTANDIGHEDEN EN WERKELIJK GEBRUIK ... 58
TABEL 21:HYPOTHESE 3.9 MODERATOR ERVARING OP FACILITERENDE OMSTANDIGHEDEN EN WERKELIJK GEBRUIK ... 58
TABEL 22:HYPOTHESE 3.10 MODERATOR LEEFTIJD OP RELATIE GEWOONTE EN WERKELIJK GEBRUIK ... 59
TABEL 23:HYPOTHESE 3.10 MODERATOR GESLACHT OP RELATIE GEWOONTE EN WERKELIJK GEBRUIK ... 60
TABEL 24:HYPOTHESE 3.10 MODERATOR ERVARING OP RELATIE GEWOONTE EN WERKELIJK GEBRUIK ... 60
TABEL 25:HYPOTHESE 4.1 BESCHRIJVENDE STATISTIEKEN GESLACHT EN WERKELIJK GEBRUIK ... 62
TABEL 26:HYPOTHESE 4.1 VARIANTIEANALYSE GESLACHT EN WERKELIJK GEBRUIK ... 62
TABEL 27:HYPOTHESE 4.2 BESCHRIJVENDE STATISTIEKEN LEEFTIJD EN WERKELIJK GEBRUIK ... 63
vii
Lijst van figuren
FIGUUR 1:GARTNER'S HYPE CYCLE IN HET GEBIED ARTIFICIËLE INTELLIGENTIE (GOASDUFF,2019) ... 3
FIGUUR 2:MEEST GEBRUIKTE VOICE ASSISTANTS (OLSON &KEMERY,2019) ... 10
FIGUUR 3:POPULAIRSTE APPARATEN MET SPRAAKASSISTENTEN IN VLAANDEREN (VANDENDRIESSCHE &DE MAREZ,2020) ... 16
FIGUUR 4:HET BASISCONCEPT ACHTER ACCEPTATIEMODELLEN VAN TECHNOLOGIE (VENKATESH ET AL.,2003) ... 17
FIGUUR 5:TRA(FISHBEIN &AJZEN,1975) ... 18
FIGUUR 6:TAM1(F.D.DAVIS ET AL.,1989) ... 19
FIGUUR 7:TAM2(VENKATESH &DAVIS,2000) ... 20
FIGUUR 8:TPB(AJZEN,1991) ... 21
FIGUUR 9:C-TAM-TPB(TAYLOR &TODD,1995) ... 22
FIGUUR 10:MPCU(THOMPSON ET AL.,1991) ... 23
FIGUUR 11:INITIEEL ONDERZOEKSMODEL SCT VOOR COMPUTERS (COMPEAU &HIGGINS,1995) ... 24
FIGUUR 12:UTAUT1(VENKATESH ET AL.,2003) ... 25
FIGUUR 13:UTAUT2(VENKATESH ET AL.,2012) ... 27
FIGUUR 14:SOORTEN EXTENSIES VAN UTAUT(VENKATESH ET AL.,2016) ... 29
FIGUUR 15:INDELING VOLGENS GESLACHT... 37
FIGUUR 16:INDELING VOLGENS LEEFTIJD ... 38
FIGUUR 17:INDELING VOLGENS DIPLOMA ... 39
FIGUUR 18:INDELING VOLGENS KENNIS INTELLIGENT ASSISTANTS ... 40
FIGUUR 19:INDELING VOLGENS PRIVACY ... 41
FIGUUR 20:INDELING VOLGENS GEBRUIK ... 41
FIGUUR 21:INDELING VOLGENS MERK ... 42
FIGUUR 22:INDELING VOLGENS APPARATEN ... 43
FIGUUR 23:INDELING VOLGENS FREQUENTIE ... 44
1
1. Inleiding
‘Af en toe is er een tektonische verschuiving binnen technologie en wij denken dat stem zo’n verschuiving is’, aldus Nick Fox, een vice-president van Google (Dumaine, 2018). Wie in 2020 zijn smartphone gebruikt, doet dit doorgaans met behulp van zijn touchscreen. Toch werd de voorbije jaren meermaals verkondigd dat de toekomst niet ligt in deze technologie. Volgens bepaalde bronnen zou in de komende jaren spraakbesturing de nieuwe manier worden om interactie te voeren met de smartphone (S. Agarwal, 2019; Harlalka, 2013; Hempel, 2016). De meest verspreide toepassing van spraakbesturing zijn de intelligent assistants, zoals Siri, Alexa en Google Assistant. Hiermee kunnen de gebruikers met hun stem instructies geven en zo multitasken en tijd besparen (Fagnoul et al., 2019). Vrijwel op elke moderne smartphone is zo’n intelligent assistant aanwezig. Ook op andere apparaten zoals smart speakers en smartwatches zijn deze behulpzame assistenten ondertussen standaard geïnstalleerd bij de nieuwere modellen.
De stelling luidt dat spraakbesturing de toekomst is, maar de vraag kan gesteld worden of dit wel effectief zo is. In deze masterproef wordt nagegaan in welke mate intelligent assistants reeds deel uitmaken van het dagelijks leven van de Vlaming. Daarnaast wordt ook gekeken naar de factoren die het al dan niet gebruiken van deze technologie beïnvloeden. Hieruit kwam de uiteindelijke onderzoeksvraag: ‘Welke factoren beïnvloeden de intentie tot en het werkelijk gebruik van intelligent assistants in Vlaanderen?’.
Dit onderzoek steunt op het meest gebruikte theoretisch kader voor onderzoek naar de acceptatie van technologieën. Voor consumenten is dit het UTAUT2-model of de tweede versie van de Unified Theory of Acceptance and Use of Information Technology. Hierin wordt gekeken welke constructen de intentie tot gebruik en het werkelijk gebruik beïnvloeden van een bepaalde technologie.
De literatuurstudie bespreekt de geschiedenis en de spelers op de markt van intelligent assistants. Ook wordt het UTAUT2-model hierin toegelicht. Het hoofdstuk empirisch onderzoek beschrijft hoe het onderzoek is verlopen. De antwoorden van de respondenten worden in het luik resultaten beschreven en geanalyseerd. Hierna volgen de discussie, de limitaties en aanbevelingen voor verder onderzoek en de conclusie. In deze onderdelen wordt de masterproef samengevat en wordt kritisch nagedacht over de bevindingen.
2
2. Literatuurstudie
2.1.
Verklarende definities
Een intelligent assistant is een softwareagent die gesproken taal als input krijgt, deze interpreteert en hierop antwoordt door een bepaalde software te activeren of een gesproken antwoord terug te geven (Hoy, 2018; Riccardi, 2014). Hij helpt de menselijke gebruiker bij het voltooien van professionele administratieve, technische of sociale taken (Saad et al., 2017). Voor deze technologie bestaan verschillende benamingen: intelligent personal assistant, voice (activated virtual) assistant, mobile assistant, virtual (personal) assistant (VPA), AI agent, enzovoort. (Jiang et al., 2015; Perez Garcia et al., 2018). Deze termen worden vaak door elkaar gebruikt. In deze thesis gaat het specifiek over de
intelligent assistants, die met de stem worden bestuurd en bepaalde taken van de gebruiker uitvoeren. De verschillende termen worden in deze masterproef door elkaar gebruikt maar duiden telkens op dit soort intelligent assistant.
De onderliggende technologie die gebruikt wordt in intelligent assistants is automatic speech recognition (ASR). Dat maakt communicatie mogelijk tussen mens en computer door middel van spreken (O’Shaughnessy, 2008). Naast deze essentiële technologie maken intelligent assistants ook gebruik van artificiële intelligentie (AI), natural language processing (NLP) en machine learning (ML) (Devi et al., 2019).
Artificiële intelligentie is hier de overkoepelende term: ASR, NLP en ML zijn hier onderdelen van. Voor de term artificiële intelligentie zijn verschillende definities. Het komt het erop neer dat artificiële intelligentie een technologie is die probeert de handelingen van een mens zo realistisch mogelijk na te bootsen. Een mogelijke definitie van AI is ‘een programma dat in een arbitraire wereld niet slechter zal presteren dan een mens’ (Dobrev, 2012, p. 2).
ML is een andere tak van artificiële intelligentie die zich bezighoudt met het aanleren van historische data aan de robot door middel van statistiek en patronen (Russell et al., 2010). Hierdoor kan de intelligent assistant constant bijleren over de noden en voorkeuren van de gebruiker om zo de beleving te personaliseren.
NLP is binnen AI de tak die zich bezighoudt met taal. NLP maakt het mogelijk om effectief te communiceren met een computer op een menselijke manier. Dat proces zorgt voor de
3 omzetting van een gesproken instructie naar een duidelijk te begrijpen instructie voor de assistant. Hiervoor worden vaak ook machine learning algoritmes gebruikt (Sathiyakugan, 2018). Een van de definities van NLP is ‘een theoretisch gemotiveerde reeks van
computertechnieken voor het analyseren en weergeven van natuurlijk voorkomende teksten op een of meerdere niveaus van taalkundige analyse met het oog op het bereiken van mensachtige taalverwerking voor een reeks taken of toepassingen’ (Liddy, 2001, p. 1).
2.2.
Huidige marktpositie
Figuur 1: Gartner's Hype Cycle in het gebied artificiële intelligentie (Goasduff, 2019)
Gartner’s Hype Cycle is een cyclus die de huidige positie van een technologie op de markt weergeeft. Het is een weergave van hoe ver verschillende technologieën staan in een
4 bepaald domein, afgebeeld op een pad die een nieuwe technologie doorgaans aflegt
(Dedehayir & Steinert, 2016). Het onderzoeks- en adviesbedrijf Gartner geeft dit rapport jaarlijks uit sinds 1995 (Gartner Hype Cycle, z.d.).
De y-as geeft aan hoe groot de verwachtingen zijn ten opzichte van de technologie. Op de x-as wordt aangegeven hoe lang de technologie al bestaat. Bedrijven kunnen hierop hun strategie baseren: hoe risicovol de technologie die ze overwegen is, hoe ver de technologie gevorderd is, wanneer het juiste moment voor investering is, enzovoort. Gartner deelt de levenscyclus van een nieuwe technologie op in vijf grote fases (Gartner Hype Cycle, z.d.). Een eerste fase is de innovatietrigger. Die geeft de start van een nieuwe technologie aan. De media zal artikels beginnen te publiceren hierover. De technologie is echter nog niet sterk ontwikkeld en vaak zijn er nog niet echt bruikbare producten gecreëerd die de technologie gebruiken (Gartner Hype Cycle, z.d.).
De tweede fase is de piek van hooggespannen verwachtingen. In deze fase komen de eerste succesverhalen boven, maar sommige bedrijven falen ook in deze fase. Veel bedrijven kijken echter nog even de kat uit de boom en wachten op verdere evolutie (Gartner Hype Cycle, z.d.).
Fase drie is de trog van ontgoocheling. Op dit moment zakt de interesse in de technologie naar een minimum. De hooggespannen verwachtingen in de vorige fase kunnen niet worden ingelost. Veel producenten haken af, degene die blijven passen zich aan aan wat de markt echt wil (Gartner Hype Cycle, z.d.).
De vierde fase is de helling van verlichting. De hoop in de technologie komt terug naar boven. Verschillende implementaties van de technologie zien in deze fase het licht. Van producten uit eerdere fases komt een tweede of derde versie uit. Conservatieve bedrijven blijven nog steeds weg (Gartner Hype Cycle, z.d.).
Uiteindelijk bereikt de technologie in fase vijf het productiviteitsplateau. Dat is de fase waarin de technologie door de mainstream massa wordt aanvaard. De technologie is algemeen aanvaard en is volwassen geworden. Brede mogelijkheden van toepassingen komen op de markt. Dit is de laatste fase in de hypecyclus (Gartner Hype Cycle, z.d.).
5 Figuur 1 geeft de hypecyclus weer voor het gebied artificiële intelligentie in 2019. Op deze cyclus staan verschillende technologieën die relevant zijn voor dit onderzoek.
Conversational user interfaces en chatbots bevinden zich op de piek van hooggespannen verwachtingen. Er is dus momenteel een hype rond deze technologieën. Een conversational user interface laat de gebruiker toe om met gesproken taal instructies uit te voeren op computerprogramma’s (McTear, 2002). Een chatbot beantwoordt dan weer hoofdzakelijk vragen die een gebruiker heeft over een bepaald onderwerp (Huang et al., 2007) en lijkt daardoor meer op een echt gesprek.
ML en NLP worden respectievelijk juist voor en juist na de grens tussen de piek van hooggespannen verwachtingen en het dal van ontgoocheling geplaatst. Zij hebben dus de piek achter zich en zijn volgens de cyclus momenteel de verwachtingen niet aan het inlossen. De virtual assistant of intelligent assistant zelf wordt geplaatst in de trog van ontgoocheling, op weg naar het diepste dal in de figuur. Ook de VPA-enabled Wireless Speakers of smart speakers, die gebruikmaken van intelligent assistants, zitten in deze fase. Uit deze
positionering kan worden afgeleid dat de interesse in de technologie zakt. Stilaan begint men te zien dat de verwachtingen in het begin te hoog waren en niet in te lossen zijn. Uiterst rechts op de figuur is spraakherkenning te vinden. Dit is de technologie waarop intelligent assistants gebouwd zijn. Deze bevindt zich in het productiviteitsplateau. Dat wil zeggen dat de technologie volwassen is en veel verschillende toepassingen heeft. Het feit dat intelligent assistants en VPA-enabled Wireless Speakers hiervan toepassingen zijn bevestigt dit.
2.3.
Korte geschiedenis Automatic Speech Recognition
2.3.1. Radio Rex
Het eerste gecommercialiseerde toestel ooit dat gebruikmaakte van een vorm van stemherkenning was de Radio Rex. Dit speelgoedje bestond uit een hond die uit zijn hok kwam door zijn naam, Rex, te zeggen (Pierce, 1969). Deze lichte plastieken hond reageerde hier niet zelf op, maar de korte e-klank in zijn naam zorgde voor een frequentie van om en bij de 500 Hz. Deze frequentie zorgde ervoor dat het mechanisme binnen het speelgoed zich
6 activeerde, wat resulteerde in het naar buiten komen van de plastieken hond (Markowitz, 2003).
2.3.2. Audrey
In 1952 ontwikkelde Bell Laboratories Audrey. De naam Audrey staat voor automatic digit recognizer. Dit toestel wordt gezien als het eerste toestel dat spraak kon herkennen. Audrey kon alle enkelvoudige cijfers (nul tot negen) onderscheiden met een nauwkeurigheid van tussen de 97 en 99 procent. Dit deed het door de ingesproken woorden te splitsen in twee frequentiebanden en te vergelijken met de mogelijkheden van cijfers. Hieruit nam Audrey dan de beste overeenkomst en selecteerde het dit cijfer (K. H. Davis et al., 1952).
Dit werd geen commercieel succes. Een eerste reden was de prijs: de aankoopprijs, het energieverbruik en de onderhoudskosten waren hoog. Een tweede reden was dat het gewoon niet efficiënt was. Audrey kon enkel cijfers onderscheiden. Callcenters zouden dit bijvoorbeeld kunnen gebruiken maar de werknemers konden de toetsen zelf sneller intikken en dit verliep met minder fouten (Lea, 1980).
2.3.3. Shoebox
Tien jaar later werd de Shoebox aan het grote publiek voorgesteld op de Seattle World’s Fair van 1962 (Devi et al., 2019), ontwikkeld door IBM. Dit bedrijf is nog steeds een zeer
belangrijke speler is op de markt van technologie. De Shoebox had zijn naam te danken aan zijn afmetingen: de grootte van een schoendoos. Dit product kon naast de enkelvoudige cijfers ook zes nieuwe woorden begrijpen: plus, minus, total, subtotal, false en off. Door de toevoeging van deze woorden kon de Shoebox eenvoudige wiskundige problemen oplossen (Hursley Museum, 2018). Zowel Audrey en Shoebox waren echter heel afhankelijk van de stem die de input gaf. Maar één stem kon tegelijk gebruikt worden als input (Niesler, 2013).
2.3.4. Harpy
In 1971 investeerde de Amerikaanse overheid via hun Defense Advanced Research Projects Agency (DARPA) in een vijfjarig programma voor onderzoek naar spraakherkenning. Ze stelden enkele doelen voorop waaraan een systeem zou moeten voldoen voor hun
7 sponsoring volledig te verkrijgen. Het enige product dat alle vooropgestelde doelen
uiteindelijk kon bereiken was Harpy. Onderzoekers ontwikkelden Harpy in 1976 in de Carnegie Mellon University te Pittsburgh. Het systeem kon 1.011 verschillende woorden identificeren. Door een nieuwe techniek genaamd beam search werkte dit apparaat een stuk efficiënter dan zijn voorgangers. Tegelijk werd in de jaren 70 ook bij Bell Laboratories voor het eerst een systeem ontwikkeld dat meerdere stemmen kon herkennen en dus minder afhankelijk was van de specifieke spreker die aan het woord was (Juang & Rabiner, 2004).
2.3.5. Tangora
De belangrijkste ontdekking in de jaren 80 was het Hidden Markov Model (HMM). Deze nieuwe techniek maakte gebruik van statistiek en waarschijnlijkheid om te schatten wat gezegd wordt (Juang & Rabiner, 2004). De hidden toont aan dat de interne werking van de spraakherkenning niet getoond wordt bij het gebruik (Lama & Namburu, 2010). Dit gebeurde door de invoer te vergelijken met een set van gekende woorden en door middel van
waarschijnlijkheid in te schatten met welk woord de input al dan niet overeenkwam (O’Shaughnessy, 2008).
IBM ontwikkelde met deze nieuwe technologie Tangora. Deze opvolger van de Shoebox kon 20.000 verschillende woorden onderscheiden. Deze technologie kon echter nog steeds niet gemakkelijk overschakelen tussen verschillende stemmen. Hij had hiervoor circa twintig minuten inwerktijd nodig (Bahl et al., 1988).
2.3.6. Dragon Dictate en Dragon NaturallySpeaking
In de jaren 90 boekten grote bedrijven over heel de wereld veel vooruitgang. IBM, Philips en Lernaut en Hauspie waren in deze periode de leiders op de markt (Devi et al., 2019). Het brede publiek leerde spraakherkenning kennen door de opkomst van de computer. Het Hidden Markov Model werd geïmplementeerd in de Hidden Markov Model Toolkit (HTK). Dit is nog steeds een van de meest gebruikte softwaretools die HMM toepassen (Elouahabi et al., 2016).
Dragon Dictate was in de vroege jaren 90 het softwarepakket dat algemeen het meest gebruikt werd (Komissarchik et al., 1998). Dit systeem, ontwikkeld door Dragon Systems, kon
8 30.000 woorden herkennen. Terwijl een gebruiker aan het inspreken was, kon deze zien welk woord de Dictate dacht dat hij zei, plus een lijst van tussen de 100 en 200 woorden. Hieruit moest de gebruiker dan het juiste woord kiezen indien de Dragon Dictate hem verkeerd had begrepen (Gillick & Roth, 1990).
In deze periode evolueerden de commerciële toepassingen van spraakherkenning ook naar continue spraakherkenning. Hiervoor was het de norm om tussen elk woord een pauze te doen om zo de software duidelijk te maken dat een nieuw woord begon (O’Shaughnessy, 2008). Het eerste programma dat continue spraakherkenning gebruikte was
NaturallySpeaking, net zoals de Dragon Dictate ontwikkeld door het bedrijf Dragon Systems. Je kon inspreken aan een normale spraaksnelheid, zo’n 160 woorden per minuut (Zumalt, 2005).
2.3.7. Watson
De volgende grote mijlpaal op het gebied van spraakherkenning- en besturing was Watson. Dit was een project gemaakt door IBM met als doel de twee beste deelnemers tot nu toe te verslaan in het televisieprogramma Jeopardy!, een populair quizprogramma op televisie in de Verenigde Staten. IBM slaagde in 2011 in zijn opzet: Watson won het spelprogramma na een wedstrijd van twee verschillende ronden (Ferrucci et al., 2013) en versloeg hierbij twee menselijke topkandidaten. Dit maakte het grote publiek duidelijk dat intelligente machines niet langer voorkwamen in de verre toekomst: ze waren hier en nu aanwezig (Markoff, 2011). In datzelfde jaar bracht Apple de eerste intelligent assistant uit die met
spraakbesturing werkte: Siri (Guzman, 2018). Vanaf dan kwamen ook andere intelligent assistants op de markt en leerde het brede publiek ze kennen. De grootste spelers op de markt van intelligent assistants worden in sectie 2.6. besproken.
2.4.
Implementaties intelligent assistants
De meest gekende toepassing van intelligent assistants is die ingebouwd in een smartphone. Via smartphones zijn ze meer en meer een deel van het dagelijks leven aan het worden (Kiseleva et al., 2016). Dankzij de toepassing moet de gebruiker niet langer alles ingeven via het toetsenbord maar kunnen ze een conversatie aangaan met hun intelligent assistants.
9 Door instructies te geven voert de intelligent assistant deze dan uit voor de gebruiker (Jiang et al., 2015). Voorbeelden hiervan zijn Siri op de iPhone en Bixby op Samsung smartphones. Daarnaast kunnen ze ook voorkomen op een smart speaker specifiek gemaakt voor de assistant. Hiermee kan de gebruiker ook communiceren via stem, zonder een toestel te moeten aanraken. Zo kunnen ze vragen muziek af te spelen, de koers van hun aandelen op te volgen, aankopen te doen op het internet en nog veel meer (Bentley et al., 2018). Een bekend voorbeeld van een smart speaker is Google Home.
Ook op een computer kan een intelligent assistant werken. Zo staat Cortona van Microsoft standaard geïnstalleerd op computers met Windows 10 (Hoy, 2018) en staat Siri ook op Mac computers (Apple, 2019). Ook op smartwatches kan een intelligent assistant zitten. Wie een Apple Watch koopt kan gebruikmaken van Apple’s Siri op dit horloge (Hoy, 2018). Alexa kan ook geïntegreerd worden in de auto. Met Echo Auto kan Alexa op de weg helpen en
entertainen (Amazon, z.d.-b).
Een ander alledaags voorwerp waarin tegenwoordig intelligent assistants kunnen verwerkt worden is de televisie. Bij die smart-tv’s kan je dan in plaats van de afstandsbediening de stem gebruiken. De kijker bedient dan zijn televisie met instructies als ‘volume omhoog’ of ‘demp geluid’ (Lazic et al., 2018). Ook kunnen streamingdiensten hiermee gebrowset worden (Westcott et al., 2019), zoals Netflix.
2.5.
Use cases intelligent assistants
Intelligent assistants kunnen tegenwoordig een enorm groot takenpakket aan. Ze worden echter nog steeds doorgaans gebruikt om basistaken uit te voeren. Dit gaat dan over bepaalde dingen opzoeken op het internet, het weer opvragen, muziek afspelen, een berichtje zenden of muziek afspelen (Consumer Intelligence Series - Prepare for the Voice Revolution, 2018). Ook een route opvragen, de agenda beheren en een andere applicatie openen wordt frequent gedaan (Fagnoul et al., 2019). Meer complexe instructies zijn
mogelijk maar worden nog minder gebruikt. Enkele voorbeelden van complexere instructies zijn aankopen doen via een intelligent assistant of andere smart devices besturen (Consumer Intelligence Series - Prepare for the Voice Revolution, 2018).
Niet enkel consumenten maken gebruik van intelligent assistants. Binnen bedrijven wordt deze technologie ook gebruikt. Zo zijn intelligent assistants een essentieel onderdeel van
10 klantenervaring geworden. Ze kunnen hiermee ook efficiënter werken door repetitieve taken en veelgestelde vragen sneller op te lossen (Connolly et al., 2018). In België was Colruyt de eerste Belgische supermarkt die boodschappenlijstjes via stemopname testte. Burger King won in 2017 de Cannes Lion voor hun Google Home campagne, een prijs die uitgereikt wordt voor creativiteit (Fagnoul et al., 2019).
2.6.
Verschillende intelligent assistants
Volgens het Voice Report van Microsoft in 2019 (Olson & Kemery, 2019) zijn er vier grote spelers op de markt van voice assistants. In figuur 2 is te zien welke deze zijn.
Figuur 2: Meest gebruikte voice assistants (Olson & Kemery, 2019)
Dit zijn cijfers over Amerikaanse consumenten. Uit dit onderzoek bleek dus dat Siri en Google Assistant de twee grootste waren met elk 36%. Alexa volgt met 25% en Cortana met 19%. Het verschil tussen Alexa en de twee grootste kan te wijten zijn aan het grote aantal smartphones, waarop Siri en Google Assistant standaard staan, in vergelijking met smart speakers (250 miljoen t.o.v. 50 miljoen). Slechts 1% van de gebruikers doet beroep op een intelligent assistant die niet een van deze vier is (Olson & Kemery, 2019). Deze vier
populairste intelligent assistants worden in de volgende secties besproken.
2.6.1. Apple Siri
In april 2010 werd bekendgemaakt dat Apple een kleine startup genaamd Siri had
overgekocht. Siri was de eerste intelligent assistant in de vorm zoals ze nu gekend zijn (Hoy, 2018). Voor de overname was Siri een van Apple onafhankelijke personal assistant voor de
11 iPhone. Het was dus een app op de iPhone. Na de overname kreeg Siri initieel gemengde reacties (Perez Garcia et al., 2018).
Een artikel van Leena Rao in Techcrunch (2010) zag in deze overname twee mogelijkheden voor Apple. De eerste optie was dat Siri een standaardapplicatie zou worden op Apple apparaten. De tweede optie was dat ze enkel geïnteresseerd waren in de technologie erachter en deze wilden gebruiken voor de ontwikkeling van andere applicaties. Rao dacht dat de tweede optie waarschijnlijker was maar dit was niet het geval. In 2011
implementeerde Apple Siri als standaardprogramma in de iPhone 4S (Guzman, 2018). Vanaf dan zou dit in de meeste nieuwe Apple apparaten het geval zijn.
De spraakinstructie om Siri te activeren is ‘Hey Siri’. Deze woorden zullen Siri activeren en hierna zal Apple’s intelligent assistant vragen hoe ze kan helpen. Momenteel zit Siri onder andere in Airpods, Apple Watch, iPhone en Apple TV (Apple, z.d.).
2.6.2. Microsoft Cortana
De eerste intelligent assistant die volgde op Siri was Cortana van de technologiegigant Microsoft. Dit gebeurde twee jaar na de implementatie van Siri in de iPhone 4S, in 2013 (Hoy, 2018). Net zoals bij Siri moet de gebruiker Cortana activeren met de woorden ‘Hey Cortana’. Cortana gebruikt Bing als zoekmachine (Reis et al., 2017) en gebruikt dus niet standaard Google om op te zoeken op het internet. In juli 2015 lanceerde Microsoft Windows 10. Op deze nieuwste versie van Windows staat Cortana bij aankoop standaard geïnstalleerd (Singh & Singh, 2017).
Ondertussen is de positie van Cortana in de markt veranderd. Doordat de achterstand op de andere grote spelers steeds groter werd, besliste Microsoft om het over een andere boeg te gooien. De nieuwe filosofe was om de andere intelligent assistants niet langer te zien als concurrenten, maar om ermee samen te werken. Ze wilden zich dus volledig herpositioneren in de markt. Microsoft kondigde aan dat het de bedoeling is dat Cortana vanaf nu
complementair werkt met de andere assistants (Warren, 2019). Zo is Cortana’s stem ondertussen geïntegreerd in zowel Alexa als Google Assistant (Olson & Kemery, 2019).
12 In 2014 lanceerde Amazon zijn eigen assistant genaamd Alexa, samen met de smart speaker Amazon Echo (Hoy, 2018). Deze lancering was op dat moment enkel voor Amazon Prime-abonnees, de betalende versie van Amazon die met voordelen gepaard gaat. In 2015 werd Alexa voor het brede publiek uitgebracht. Op dat moment was dit de eerste virtual assistant die echt op een speciaal daarvoor gemaakt apparaat werkte (Perez Garcia et al., 2018). Om met Alexa te communiceren moet de gebruiker zijn zin beginnen met een
ontwaakwoord om haar aan te spreken. Hier heeft de gebruiker de keuze uit ‘Alexa’, ‘Amazon’, ‘Computer’ of ‘Echo’ (Amazon, z.d.-a). Dit resulteert dan in bijvoorbeeld ‘Alexa, zoek een Italiaans restaurant in mijn buurt’ (López et al., 2017). Alexa zit vervat in
verschillende producten die Amazon de laatste jaren heeft uitgebracht. Voor Amazon is de optie om producten aan te kopen via Alexa belangrijk. Hiermee kan Amazon de klant verwijzen naar hun eigen webwinkel(Amazon, z.d.-c), wat extra inkomsten genereert voor het bedrijf. Dankzij deze strategische zet beschikken ze ook over gegevens van het
koopgedrag van de klanten en kunnen ze hierop inspelen.
2.6.4. Google Assistant
In 2012 kwam Google Now op de markt. Dat was een soort van virtual personal assistant die met behulp van spraakbesturing helpt bij het opzoeken op Google (Perez Garcia et al., 2018). Vier jaar later, in 2016, werd Google Assistant gelanceerd door Google, samen met de
Google Home smart speaker. Dat was eerst een extensie van Google Now en werd op termijn de vervanger ervan (Tillman & O’Boyle, 2019). Het verschil tussen de twee was dat Google Assistant wel in staat was om een conversatie te houden met de gebruiker, terwijl Google Now dit nog niet kon (Perez Garcia et al., 2018).
Op Androidapparaten gebruikt de Google app ook Google Assistant (Hoy, 2018). Om Google Assistant aan te spreken moet de gebruiker zijn zin beginnen met ‘Ok Google’ of ‘Hey Google’. Een interactie met Google Assistant zal er dan bijvoorbeeld zo uitzien: ‘Ok Google, boek een tafel voor twee in restaurant Firenze om 19 uur’ (López et al., 2017).
2.7.
Vergelijking verschillende intelligent assistants
De verschillende intelligent assistants doen over het algemeen allemaal hetzelfde maar hebben wel elk unieke eigenschappen (Hoy, 2018). Berdasco et al. (2019) onderzochten de
13 vier grootste intelligent assistants om te weten te komen welke het beste functioneert. 92 van hun studenten beoordeelden de intelligent assistants op twee vlakken: hoe natuurlijk de antwoorden overkwamen en hoe correct de antwoorden waren. Uit dit onderzoek bleek dat Alexa en Google Assistant het met voorsprong beter deden dan Siri en Cortana. Alexa en Google Assistant vertoonden geen verschil in prestaties: ze bleken even goed te
functioneren. De studenten plaatsten Cortana op de derde plaats en Siri op de laatste plaats. Het valt op dat Siri, een van de meest gebruikte voice assistants, hier dus het slechtst scoort (Berdasco et al., 2019).
Instructie begrepen Correct antwoord
Google Assistant 100% 92,9%
Siri 99,8% 83,1%
Alexa 99,9% 79,8%
Tabel 1: Prestaties intelligent assistants (Munster & Thompson, 2019)
Een ander bedrijf genaamd Loup Ventures publiceert jaarlijks een vergelijking van de
prestaties van de verschillende voice assistants. De resultaten hiervan zijn te zien in tabel 1. Omdat Cortana zichzelf niet langer profileert als concurrent (Olson & Kemery, 2019) wordt ze dus ook niet langer opgenomen in het onderzoek van Loup Ventures. In 2018 was dit wel nog zo en eindigde Cortana op een laatste plaats. Dit bevestigt dat Cortana de zwakste van de vier was. De drie overige intelligent assistants begrepen de vragen doorgaans goed. Google Assistant was wel de enige die alle 800 testvragen correct begreep. Op vlak van vragen beantwoorden haalde Google Assistant 92,9% correctheid, Siri 83,1% en Alexa 79,8%. Opvallend was dat Google Assistant beter scoorde dan Alexa op vlak van handel. Intuïtief zou men misschien aanvoelen dat Alexa hiervoor beter geschikt is door de verweving met
Amazon, maar Google haalde hier 92% correctheid en Alexa maar 71%. Google Assistant kwam dus als grote winnaar uit dit onderzoek (Munster & Thompson, 2019), terwijl het in het onderzoek van Berdasco et al. (2019) ook al bij de beste twee was.
2.8.
Veiligheid en privacy
Een zorg die mensen weerhoudt van het gebruik van intelligent assistants is of ze wel de privacy van de gebruiker waarborgen. De gebruiker maakt zich zorgen over mensen die meeluisteren (Fagnoul et al., 2019). Ook rond de verwerking van de audio bestaan twijfels
14 over de privacy: de gebruikers maken zich zorgen over de veiligheid van hun persoonlijke gegevens (Mihale-Wilson et al., 2017). Deze mensen bekommeren zich niet zomaar om dit probleem; in het verleden werd verschillende malen bericht dat grote bedrijven
meeluisterden met hun consumenten. Dit gebeurde via de microfoon die op hun apparaat staat, zonder de expliciete toestemming van de gebruikers.
In april 2019 kwam aan het licht dat medewerkers van Amazon meeluisterden naar de geluidsopnames die Alexa maakte van de consument. Ze schreven de opnames uit, voegden informatie toe over de opname en gaven feedback aan Alexa om te verwerken. Dit had als doel de AI die de basis vormt van Alexa te optimaliseren. In de privacyvoorkeuren van de smart speaker kregen gebruikers wel de optie om te weigeren dat Alexa gebruikmaakt van opnames om het programma te verbeteren (Day et al., 2019). Onderzoek heeft echter aangetoond dat gewone gebruikers het privacybeleid en de algemene voorwaarden van een aanbieder van een bepaalde dienst dikwijls blindelings aanvaarden (Obar & Oeldorf-Hirsch, 2020). Bedrijven kunnen hier misbruik van maken.
In juli 2019, drie maanden later, deed VRT NWS hier onderzoek naar in Vlaanderen. Zij concludeerden dat Google ook meeluistert, niet live maar met vertraging. Deze opnames worden losgekoppeld van de gebruiker om zo anoniem behandeld te worden. In de
reportage van VRT NWS lukte het echter wel om via de informatie die besproken werd door de anonieme gebruikers, te achterhalen wie ze zijn (Van Hee et al., 2019). Google zelf haalt het zelfde argument als Amazon aan: dit helpt om de werking van hun assistant te
verbeteren (Cuthbertson, 2019).
Ook Apple kwam in de zomer van 2019 in het nieuws met gelijkaardige feiten. Ze boden hun excuses aan omdat ze onderaannemers van het bedrijf toestemming hadden gegeven om opnames van Siri te gebruiken voor hun werk. Met deze opnames moesten de
onderaannemers de consumenten opdelen in verschillende klassen om zo nog meer
gepersonaliseerd te werk te kunnen gaan. In deze verontschuldiging beloofde Apple om niet langer standaard alle opnames op te slaan. Hiervoor moeten gebruikers nu expliciet
15 De drie grote intelligent assistants zijn dus elk al negatief in de media gekomen met een schandaal rond privacy. Dit kan invloed hebben op het vertrouwen van de gebruikers in deze technologie.
2.9.
Intelligent assistants in België
Deze masterproef peilt naar de acceptatie van intelligent assistants, specifiek in Vlaanderen. Cijfers over België zijn voor deze masterproef dus relevanter dan onderzoeken uit de
Verenigde Staten. België is traditioneel een land dat niet snel nieuwe technologie aanvaardt (Fagnoul et al., 2019). Deloitte vond in een onderzoek dat van de 84% van de Belgen die een smartphone bezit (dus niet enkel Vlamingen), slechts 7% aangeeft dat hij of zij de virtual assistant erop gebruikt. Dat is beduidend lager dan enkele van de buurlanden, zoals Frankrijk (12%) en Duitsland (16%). Binnen de Benelux zijn gelijkaardige cijfers te zien: 8% in
Nederland en 9% in Luxemburg. Hier is België dus opnieuw nipt het land met het laagste percentage (Deloitte, 2019).
Volgens een onderzoek van iProspect (2019) zijn de meest gekende intelligent assistants in België Siri (57%), Google Assistant (44%) en Alexa (23%). Opvallend: Alexa staat niet in de top drie meest gebruikte intelligent assistants. Alexa is dus wel gekend in België maar wordt in verhouding niet veel gebruikt. Amazon is dan ook veel minder actief in Vlaanderen dan in de Verenigde Staten. In 2020 heeft Amazon nog steeds geen Belgische webwinkel. Als Belgische consumenten willen bestellen via Amazon, moet dit dus voorlopig via een
Amazon-webwinkel uit een ander land gebeuren, zoals deze van Nederland of Frankrijk.
2.10. Intelligent assistants in Vlaanderen
Sinds 2009 voert het bedrijf imec jaarlijks een onderzoek naar het gebruik van nieuwe technologieën in Vlaanderen. Voor het onderzoek van 2019 ondervraagden ze 2.754
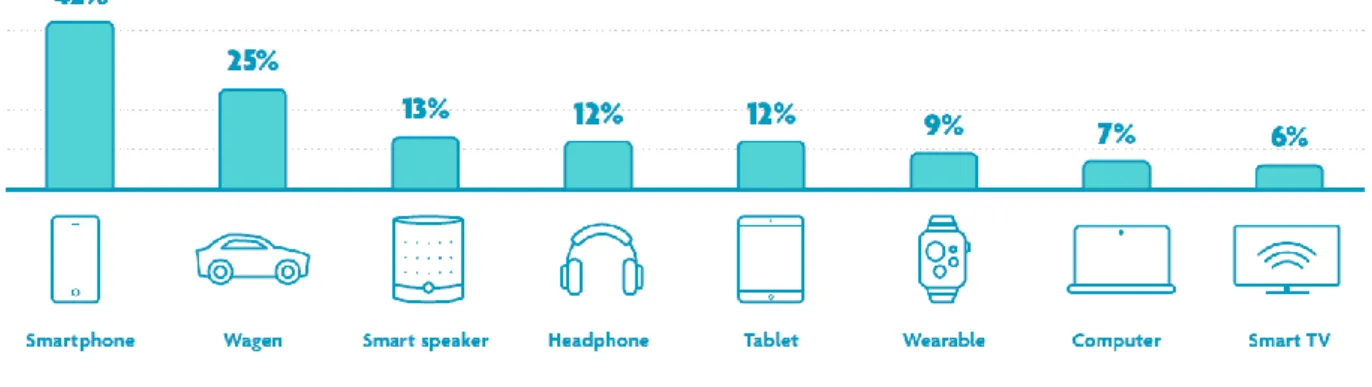
Vlamingen. In dat rapport staat dat, van de ondervraagde Vlamingen, slechts 36% reeds een voice assistant heeft gebruikt. De Vlaming moet volgens imec spraakassistent nog leren kennen. Maar 8% bezit een smart speaker. Op figuur 3 is te zien op welke apparaten de Vlaming die wel ervaring heeft met spraakassistenten, deze maandelijks gebruikt
16 (Vandendriessche & De Marez, 2020).
Figuur 3: Populairste apparaten met spraakassistenten in Vlaanderen (Vandendriessche & De Marez, 2020)
Op vlak van gebruikerservaring kan de assistant het volgens de inwoner van Vlaanderen nog veel beter doen. De natuurlijkheid van het gesprek kreeg een score van vier op tien: een score die zeer teleurstelt. Volgens imec ziet de Vlaming het nog als een technologie om eens mee te spelen of dingen mee uit te testen. Het is nog geen gewoonte geworden om iets te doen met de intelligent assistant. De technologie maakt dus nog niet echt een deel uit van het dagelijks leven in Vlaanderen. De term die in dit onderzoek gebruikt wordt is ‘spielerei met potentieel’ (Vandendriessche & De Marez, 2020). Volgens professor Jordan Peterson van de Universiteit van Toronto is het noodzakelijk om met een nieuwe technologie te spelen om deze volledig onder de knie te krijgen (Spears, 2017) en dit zou dus willen zeggen dat dit een stap in de juiste richting is.
2.11. Unified Theory of Acceptance and Use of Technology
2.11.1. Inleiding
Om na te gaan of technologieën al aanvaard of gebruikt worden, wordt doorgaans gebruikgemaakt van een acceptatiemodel. Hiervoor heeft de onderzoeker de keuze uit verschillende modellen. Veel van die modellen onderzoeken in grote lijn hetzelfde maar leggen de nadruk op een ander aspect. Doordat ze elk een andere insteek hebben, maken ze gebruik van verschillende perspectieven, technologieën, onderzoeksmethoden en theorieën (M. D. Williams et al., 2009).
17 In 2003 kwam een model uit genaamd de Unified Theory of Acceptance and Use of
Technology (UTAUT). Deze trachtte de acht meest gebruikte acceptatiemodellen samen te voegen in een nieuw model met een hoge betrouwbaarheid. Dit zorgde er uiteindelijk voor dat de keuze tussen deze acht modellen niet nodig was. Het UTAUT maakte onderzoek naar de acceptatie van technologieën makkelijker (Venkatesh et al., 2003). Sinds de publicatie van het UTAUT is dit model veel gebruikt in onderzoek naar de intentie en het gedrag bij de acceptatie van technologie (M. D. Williams et al., 2015). Het UTAUT-model werd de jaren die volgden beschouwd als het beste model om acceptatie van innovaties te voorspellen
(AlAwadhi & Morris, 2008).
In 2012 werd dit model uitgebreid naar het UTAUT2. Deze verbeterde versie voegde nieuwe constructen en relaties toe en focuste meer op de context van consumenten, terwijl UTAUT meer focuste op de bedrijfswereld (Venkatesh et al., 2012).
2.11.2. Basisconcept
Figuur 4: Het basisconcept achter acceptatiemodellen van technologie (Venkatesh et al., 2003)
Op figuur 4 is te zien wat de basisgedachte is bij modellen die de acceptatie meten van technologieën. Eerst heeft de potentiële gebruiker een bepaalde reactie op het gebruik van een nieuwe technologie. Hij heeft een bepaalde mening of een gevoel bij de technologie. Deze reactie heeft invloed op de intentie tot verder gebruik en het werkelijk gebruik. Hoe groot de intentie tot verder gebruik is heeft zelf ook een grote invloed op het werkelijk gebruik. Belangrijk hierbij is dat er dus een tussenstap mogelijk is tussen de reactie op een technologie en het werkelijk gebruik: de intentie tot gebruik (Venkatesh et al., 2003).
De pijl die terugkeert van het werkelijk gebruik toont aan dat de gebruiker zijn initiële reactie kan bijsturen. Bij een positieve ervaring zal deze positief bijgestuurd worden en bij een negatieve gebeurt het omgekeerde (Venkatesh et al., 2003). Hierop volgend worden de acht
18 gebruikte modellen in het UTAUT kort voorgesteld met de daarbij horende belangrijkste determinanten.
2.11.3. Theory of Reasoned Action (TRA)
Figuur 5: TRA (Fishbein & Ajzen, 1975)
Dit is het eerste van de acht modellen die verwerkt zijn in het UTAUT (Venkatesh et al., 2003). De Theory of Reasoned Action is oorspronkelijk afkomstig uit de sociale psychologie. Het raamwerk kan echter ook de acceptatie van technologie verklaren (F. D. Davis et al., 1989). De auteurs vonden dat er een belangrijke link is tussen de intentie om iets te doen en de effectieve uitvoering van de handeling. Deze intentie wordt beïnvloed door twee andere determinanten: de attitude tegenover het gedrag en de subjectieve norm. De subjectieve norm duidt op wat de potentiële gebruiker denk dat anderen van zijn gedrag vinden (Fishbein & Ajzen, 1975).
Belangrijkste determinanten: attitude tegenover gedrag, subjectieve norm
19
Figuur 6: TAM1 (F. D. Davis et al., 1989)
Het Technology Acceptance Model is een aanpassing van het TRA specifiek gemaakt voor de acceptatie van nieuwe technologieën. Het ging hier specifiek over voorspellingen naar het gebruik op de werkvloer (Venkatesh et al., 2003). Dit was het meest gebruikte raamwerk voordat UTAUT deze positie overnam (Dwivedi et al., 2008; Venkatesh et al., 2003; M. D. Williams et al., 2009). De subjectieve norm werd weggehaald uit het TRA omdat deze het moeilijkst te begrijpen was.
Twee constructen werden toegevoegd: gepercipieerde bruikbaarheid en gepercipieerd gebruiksgemak. Gepercipieerde bruikbaarheid duidt op hoe nuttig de gebruiker de technologie vindt. Gepercipieerd gebruiksgemak gaat over de moeilijkheidsgraad van het gebruik. Externe variabelen beïnvloeden deze nieuwe constructen (F. D. Davis et al., 1989).
20
Figuur 7: TAM2 (Venkatesh & Davis, 2000)
In 2000 stelden Venkatesh en Davis (2000) een tweede versie van het TAM voor: TAM2. Hierin werd de subjectieve norm opnieuw toegevoegd. Deze norm werd specifiek vermeld voor de gevallen waarin het gebruik van de technologie werd opgelegd en dit geen vrijwillige keuze was (Venkatesh et al., 2003). Er werden in totaal drie sociale determinanten
toegevoegd: subjectieve norm, bereidwilligheid en imago. Deze wijzen op de sociale invloed om de technologie te gebruiken. Drie cognitieve instrumentele determinanten werden toegevoegd: werkrelevantie, outputkwaliteit en aantoonbaarheid van resultaat. Deze determinanten geven weer wat de gebruiker denkt over de effectieve bruikbaarheid en het nut van de technologie (Venkatesh & Davis, 2000).
Belangrijkste determinanten: gepercipieerde bruikbaarheid, gepercipieerd gebruiksgemak, subjectieve norm
2.11.5. Motivation Model (MM)
Het Motivation Model is afkomstig uit de psychologie. Die werd in veel verschillende vormen en voor verschillende contexten ontwikkeld (Venkatesh et al., 2003). In 1992 pasten
21 is het verschil tussen intrinsieke en extrinsieke motivatie. Intrinsieke motivatie komt uit de persoon die de technologie zal gebruiken zelf. Hiervoor moeten geen andere invloeden zijn, de motivatie van de persoon zelf is essentieel. Extrinsieke motivatie daarentegen komt van buitenaf. Bij extrinsieke motivatie zorgt de technologie ervoor dat de gebruiker iets bekomt, zoals een beloning (F. D. Davis et al., 1992; Venkatesh et al., 2003).
Belangrijkste determinanten: intrinsieke motivatie, extrinsieke motivatie
2.11.6. Theory of Planned Behavior (TPB)
Figuur 8: TPB (Ajzen, 1991)
De Theory of Planned Behavior is wederom een extensie van het TRA. Hieraan werd de gepercipieerde beheersing van het gedrag toegevoegd (Venkatesh et al., 2003). Algemeen betekent dit hoe gemakkelijk of moeilijk de persoon denkt dat de uitvoering van een
handeling is (Ajzen, 1991). Specifiek voor nieuwe technologie is dit ‘de perceptie van interne en externe limieten op het gedrag’ (Taylor & Todd, 1995, p. 149). Buiten de gepercipieerde beheersing van het gedrag zijn de andere constructen gelijk aan die van het TRA (Venkatesh et al., 2003).
22 Belangrijkste determinanten: attitude tegenover gedrag, subjectieve norm, gepercipieerde beheersing van gedrag
2.11.7. Combinatie van TAM en TPB (C-TAM-TPB)
Figuur 9: C-TAM-TPB (Taylor & Todd, 1995)
Het C-TAM-TPB combineert de twee eerder vermelde modellen TAM en TPB. Het
combineert de determinanten van het TPB met de gepercipieerde bruikbaarheid om zo een nieuw hybridemodel te creëren (Taylor & Todd, 1995). In dit model zitten dus geen nieuwe determinanten vervat, die niet in het TAM of TPB zitten (Venkatesh et al., 2003).
Belangrijkste determinanten: attitude tegenover gedrag, subjectieve norm, gepercipieerde beheersing van gedrag, gepercipieerde bruikbaarheid
23
Figuur 10: MPCU (Thompson et al., 1991)
Het Model of PC Utilization (MPCU) is grotendeels gebaseerd op onderzoek van Triandis (1977) rond menselijk gedrag. Vooral de introductie van habits of gewoontes was hier belangrijk. Het onderzoek van Triandis behoorde tot een andere stroming dan TRA en TPB. Thompson et al. (1991) pasten zijn werk specifiek toe op computers. Ze onderzochten hoe vaak consumenten computers gebruikten, voor welke doeleinden, enzovoort. Het kon ook toegepast worden op andere technologieën. Hierin bepalen zes determinanten het
uiteindelijk gebruik van computers. Dit zijn de complexiteit, de job-fit, de
langetermijngevolgen, de affectie, sociale factoren en faciliterende omstandigheden. Faciliterende omstandigheden maken het gemakkelijker voor de gebruiker. Specifiek voor computers kan dit dan een persoon zijn die begeleidt en helpt bij het gebruik van de computer (Thompson et al., 1991; Venkatesh et al., 2003).
Belangrijkste determinanten: job-fit, langetermijngevolgen, affectie, sociale factoren, faciliterende omstandigheden
24
2.11.9. Innovation Diffusion Theory (IDT)
De Innovation Diffusion Theory (IDT) wordt al sinds de jaren 60 gebruikt om te kijken hoe nieuwe innovaties verspreid en geaccepteerd worden (Venkatesh et al., 2003). De adoptie van de innovatie wordt gezien als een proces van informatievergaring en risicovermindering (R. Agarwal et al., 1998). Moore en Benbasat (1991) pasten deze theorie specifiek toe op IT-innovatie. Ze vonden zo determinanten die de percepties van het gebruik van
informatiesystemen beïnvloeden. Op hun beurt beïnvloeden deze determinanten dan weer het gebruik van de informatiesystemen (Venkatesh et al., 2003).
Belangrijkste determinanten: relatief voordeel, gebruiksgemak, beeld, zichtbaarheid, comptabiliteit, resultaataantoonbaarheid, vrijwilligheid van het gebruik
2.11.10. Social Cognitive Theory (SCT)
Figuur 11: Initieel onderzoeksmodel SCT voor computers (Compeau & Higgins, 1995)
De Social Cognitive Theory (SCT) steunt op een agentperspectief voor verandering en
adoptie. Een agent kiest zijn eigen daden bewust en denkt hierover na. Hij laat dus niet alles afhangen van externe factoren (Bandura, 2005). Dit kan op vele velden toegepast worden. Compeau en Higgins (1995) pasten SCT specifiek toe op het gebruik van computers. Het kan echter ook toegepast worden op andere nieuwe technologieën. Self-efficacy of
zelfeffectiviteit in deze context is het vertrouwen in zichzelf m.b.t. het correct gebruik van computers. Van het initiële onderzoeksmodel werden vijf hoofddeterminanten gevormd (Venkatesh et al., 2003).
25 Belangrijkste determinanten: verwachtingen van resultaat: persoonlijk en prestatie,
zelfeffectiviteit, affectie en angst
2.11.11. Unified Theory of Acceptance and Use of Technology (UTAUT)
De bedoeling van Venkatesh et al. (2003) was om de acht voorgaande modellen te
combineren in één allesomvattend model. Het gaat hier dus om de TRA, TAM(2), MM, TPB, C-TAM-TPB, MPCU, IDT en SCT. Hiervoor selecteerden ze uit deze theorieën telkens de determinanten die de grootste invloed hadden. Dit kwam neer op 32 determinanten. Door een longitudinaal onderzoek te voeren, onderzochten ze welke determinanten nu echt invloed hadden om zo te weten welke uiteindelijk in het UTAUT moesten verwerkt worden (Venkatesh et al., 2003).
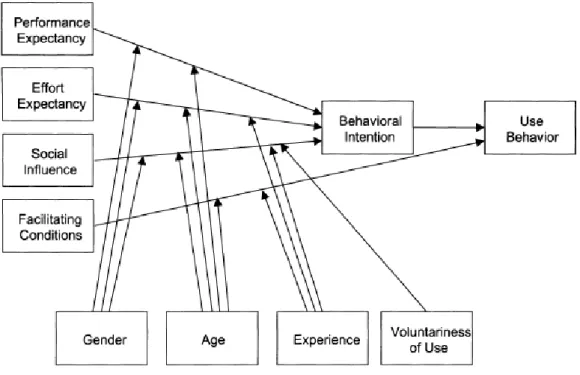
Van de zeven determinanten die een significante directe invloed hadden, selecteerden ze de vier die het meest effect hadden: prestatieverwachting, inspanningsverwachting, sociale invloed en faciliterende omstandigheden. Hiernaast vonden ze ook vier moderatoren die een onrechtstreekse invloed hebben in het model: geslacht, leeftijd, ervaring en vrijwilligheid van gebruik. Ze hebben namelijk een effect op de verbanden tussen de verschillende constructen (Venkatesh et al., 2003).
26 Performance expectancy of prestatieverwachting is in hoeverre de persoon die de
technologie gebruikt, gelooft dat het hem zal helpen bij het uitvoeren van zijn werk. Het is dus de mate waarin de technologie zijn prestaties zal verhogen of verbeteren. Dit is de determinant met de grootste invloed op het gebruik (Chang, 2012). De prestatieverwachting is gelijkaardig aan determinanten uit vijf van de acht modellen: gepercipieerde
bruikbaarheid uit TAM(2) en C-TAM-TPB, extrinsieke motivatie uit MM, job-fit uit MPCU, relatief voordeel uit IDT en uitkomstverwachtingen uit SCT (Venkatesh et al., 2003). Effort expectancy of inspanningsverwachting duidt op hoeveel moeite het kost om de technologie te gebruiken. Dit komt dus neer op hoe makkelijk de technologie is. Drie
determinanten van de vorige modellen komen hiermee overeen: gebruiksgemak uit TAM(2), complexiteit uit MPCU en gebruiksgemak uit IDT (Venkatesh et al., 2003).
Social influence of sociale invloed is de graad waarin de potentiële gebruiker denkt dat belangrijke mensen in diens leven vinden dat hij de technologie moet gebruiken. Deze sociale invloed komt overeen met enkele andere determinanten uit de acht modellen: sociale factoren in MPCU en beeld in IDT. Ook de subjectieve norm in TRA, TAM2, TPB/DTPB en C-TAM-TPB ligt in dezelfde lijn met sociale invloed (Venkatesh et al., 2003).
De drie constructen die hiervoor besproken werden, hebben allemaal een effect op de intentie tot gebruik. Deze intentie heeft dan uiteindelijk invloed op het werkelijk gebruik van de technologie.
Facilitating conditions of faciliterende omstandigheden duiden op de mate waarin de gebruiker kan steunen op organisatorische of technische infrastructuur bij het gebruik van de technologie. Dit kan bijvoorbeeld een helpdesk zijn. In tegenstelling tot de vorige drie besproken determinanten heeft deze factor geen invloed op de intentie tot gedrag. Faciliterende omstandigheden hebben wel rechtstreeks invloed op het werkelijke gebruik. Drie determinanten uit de oudere modellen lijken hier op: faciliterende omstandigheden in MPCU, comptabiliteit in IDT en gepercipieerde beheersing van het gedrag uit TPB en C-TAM-TPB (Venkatesh et al., 2003).
Hiernaast bestaan er ook vier moderatoren die de relaties tussen de verschillende
27 van gebruik. In Figuur 12 is te zien op welke verbanden in het model ze precies invloed hebben (Venkatesh et al., 2003).
Geslacht heeft in dit model invloed op drie relaties (Venkatesh et al., 2012). In voorgaande literatuur zijn gemengde resultaten gevonden met betrekking tot geslacht en de adoptie van nieuwe zaken. In bepaalde contexten was dit een belangrijke determinant, in andere totaal niet. In een context van gebruik van informatietechnologie vonden Goswami en Dutta (2016) dat mannen op vlak van technologie deskundiger zijn.
Leeftijd heeft in dit model invloed op vier relaties (Venkatesh et al., 2003). In het onderzoek door imec (2020) werd gevonden dat jongere leeftijdsgroepen positiever staan tegenover intelligent assistants dan oudere leeftijdsgroepen. De literatuur bevestigt dit: in het algemeen hebben oudere mensen meer moeite met het gebruiken van een nieuwe technologie (Morris & Venkatesh, 2006).
2.11.12. Unified Theory of Acceptance and Use of Technology 2 (UTAUT2)
Figuur 13: UTAUT2 (Venkatesh et al., 2012)
In 2012 publiceerde Venkatesh samen met nog twee andere onderzoekers een extensie van het originele UTAUT-model. Deze uitbreiding heet UTAUT2. In dit raamwerk gingen ze specifiek peilen naar de acceptatie bij consumenten, terwijl UTAUT focuste op werknemers
28 van bedrijven. UTAUT2 toonde een grotere betrouwbaarheid aan dan UTAUT. Er werden enkele aanpassingen aangebracht aan het originele model. Drie nieuwe constructen werden toegevoegd aan deze versie: hedonische motivatie, prijswaarde en gewoonte (Venkatesh et al., 2012).
Hedonic motivation of hedonische motivatie duidt op het aangenaam gebruik van een technologie. Dit komt neer op de vreugde die men ervaart bij het gebruik: hoe aangenamer het gebruik hoe groter de hedonische motivatie (Venkatesh et al., 2012).
Price value of prijswaarde is bij UTAUT2 relevanter dan bij UTAUT omdat het onderzoek draait rond consumenten. In tegenstelling tot UTAUT, waarbij het specifiek over een bedrijfscontext gaat, staat de gebruiker nu dus volledig zelf in voor de kosten. Een hoge of lage prijs zal bij de consument dus een groter effect hebben dan bij een werknemer die de technologie gebruikt die de werkgever aangekocht heeft (Venkatesh et al., 2012).
Habit of gewoonte is de mate waarin een bepaald gedrag een automatisme is geworden. Als het gebruik van technologie een gewoonte is, zal het gebruik hoger liggen. Dit beïnvloedt zowel de intentie tot gebruik als het echte gebruik rechtstreeks (Venkatesh et al., 2012). UTAUT2 bevat ook slechts drie moderatoren in plaats van vier. Vrijwilligheid van gebruik is de moderator die wegvalt. Dit heeft te maken met het feit dat consumenten deze keer de focus zijn van het model. Het bedrijf van de gebruiker legt in een bedrijfscontext vaak het gebruik op. Dan kan het voorkomen dat de gebruiker helemaal niet wil werken met de technologie. Bij UTAUT2 ligt de focus echter op consumenten en hier wordt aangenomen dat een consument telkens vrijwillig de aankoop doet. De mate van vrijwilligheid is dus telkens dezelfde: vrijwillig. De invloeden van de drie moderatoren zijn te zien op figuur 13
(Venkatesh et al., 2012).
Deze aanpassingen zorgden voor een verbetering van het model. De variantie in intentie tot gebruik (56% naar 74%) en werkelijk gebruik (40% naar 52%) is in beide gevallen groter dan in het eerste UTAUT-model (Venkatesh et al., 2012).
29 Sinds de introductie van het UTAUT-model is het een zeer wijd gebruikt raamwerk voor onderzoek naar de acceptatie van technologie geworden. Momenteel (mei 2020) is de originele paper over UTAUT (Venkatesh et al., 2003) al meer dan 9.000 keer geciteerd op Web of Science. De paper die de extensie voorstelde van UTAUT naar UTAUT2 (Venkatesh et al., 2012) heeft momenteel meer dan 1.800 citaten.
Enkele voorbeelden van toegepaste onderwerpen zijn informatiesystemen voor ziekenhuizen (Kijsanayotin et al., 2009), het online aankopen van tickets bij
lagekostenmaatschappijen (Escobar-Rodriguez & Carvajal-Trujillo, 2014) en de rol van sociale media bij contact tussen studenten (Gruzd et al., 2012). Verschillende soorten gebruikers zijn al in UTAUT-toepassingen bestudeerd, zoals studenten, werknemers of algemene gebruikers (M. D. Williams et al., 2015).
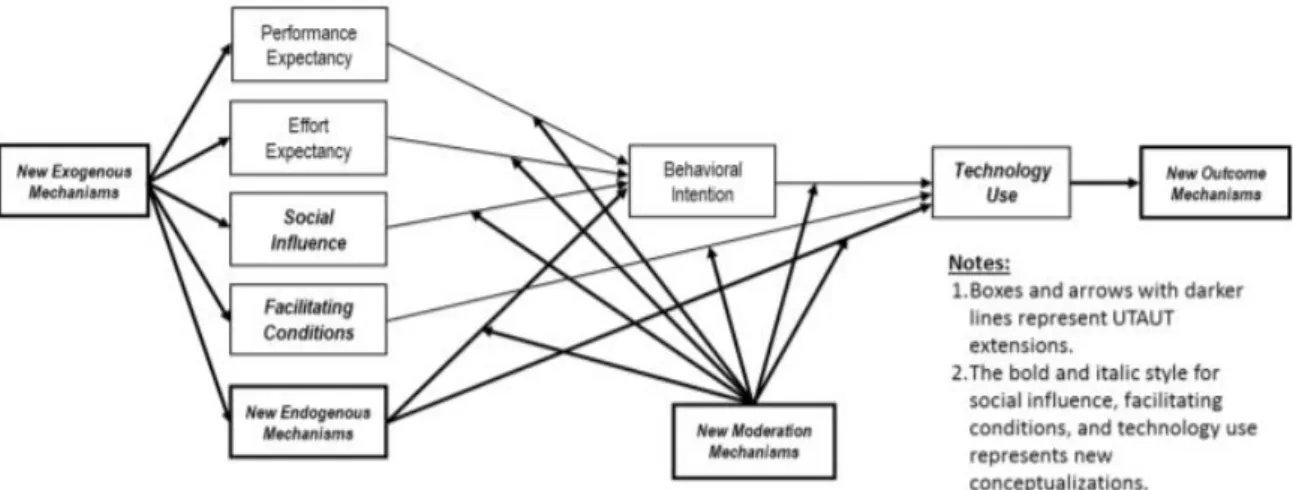
Figuur 14: Soorten extensies van UTAUT (Venkatesh et al., 2016)
Naast toepassingen van UTAUT(2) voor onderzoek zelf zijn ook verdere extensies van het model gemaakt. In deze extensies wordt dan bijvoorbeeld een construct of moderator toegevoegd. Deze constructen worden opgedeeld in vier hoofdtypes: nieuwe exogene mechanismes, nieuwe endogene mechanismes, nieuwe moderatoren en nieuwe uitkomsten (Venkatesh et al., 2016). Een voorbeeld hiervan is de toevoeging van de determinanten ‘vertrouwen’ en ‘persoonlijke webinnovatie’ bij het gebruik van technologie om online familieruzies op te lossen (Casey & Wilson-Evered, 2012).
30
3. Empirisch onderzoek
3.1.
Soort onderzoek
Door de wijde verspreiding en de algemene aanvaarding van het UTAUT2-model leek dit het beste raamwerk om te gebruiken voor dit onderzoek naar de acceptatie van intelligent assistants in Vlaanderen. Met UTAUT2 kan de acceptatie van een technologie bij
consumenten onderzocht en gemeten worden. Net als in het originele onderzoek gebeurde dit aan de hand van een enquête. Dit is een vorm van kwantitatief onderzoek bij een deel van de populatie. De enquête kan dan worden veralgemeend tot de gehele populatie (Recker, 2013).
3.2.
Onderzoeksvraag
Welke factoren beïnvloeden de intentie tot en het werkelijk gebruik van intelligent
assistants in Vlaanderen?
Hieruit volgden vier deelvragen met telkens bijhorende hypotheses.
• Deelvraag 1: Welke constructen beïnvloeden de intentie tot gebruik van intelligent assistants?
• Deelvraag 2: Welke constructen beïnvloeden het werkelijk gebruik van intelligent assistants?
• Deelvraag 3: Welke moderatoren beïnvloeden de relaties tussen de constructen, de intentie tot gebruik en het werkelijk gebruik van intelligent assistants?
• Deelvraag 4: Maken bepaalde groepen in Vlaanderen meer gebruik van intelligent assistants dan andere?
3.2.1. Hypothesen deelvraag 1
Deelvraag 1: Welke constructen beïnvloeden de intentie tot gebruik van intelligent assistants?
▪ Hypothese 1.1: Prestatieverwachting heeft een significante invloed op de intentie tot gebruik van intelligent assistants.
31 ▪ Hypothese 1.2: Inspanningsverwachting heeft een significante invloed op de intentie
tot gebruik van intelligent assistants.
▪ Hypothese 1.3: Sociale invloed heeft een significante invloed op de intentie tot gebruik van intelligent assistants.
▪ Hypothese 1.4: Faciliterende omstandigheden hebben een significante invloed op de intentie tot gebruik van intelligent assistants.
▪ Hypothese 1.5: Hedonische motivatie heeft een significante invloed op de intentie tot gebruik van intelligent assistants.
▪ Hypothese 1.6: Prijswaarde heeft een significante invloed op de intentie tot gebruik van intelligent assistants.
▪ Hypothese 1.7: Gewoonte heeft een significante invloed op de intentie tot gebruik van intelligent assistants.
3.2.2. Hypothesen deelvraag 2
Deelvraag 2: Welke constructen beïnvloeden het werkelijk gebruik van intelligent assistants?
▪ Hypothese 2.1: Intentie tot gebruik heeft een significante invloed op het werkelijk gebruik van intelligent assistants.
▪ Hypothese 2.2: Faciliterende omstandigheden hebben een significante invloed op het werkelijk gebruik van intelligent assistants.
▪ Hypothese 2.3: Gewoonte heeft een significante invloed op het werkelijk gebruik van intelligent assistants.
3.2.3. Hypothesen deelvraag 3
Deelvraag 3: Welke moderatoren beïnvloeden het verband tussen de constructen, de intentie en het werkelijk gebruik van intelligent assistants?
▪ Hypothese 3.1: Leeftijd en geslacht hebben een significante invloed op het verband tussen prestatieverwachting en intentie tot gebruik.
32 ▪ Hypothese 3.2: Leeftijd, geslacht en ervaring hebben een significante invloed op het
verband tussen inspanningsverwachting en intentie tot gebruik.
▪ Hypothese 3.3: Leeftijd, geslacht en ervaring hebben een significante invloed op het verband tussen sociale invloed en intentie tot gebruik.
▪ Hypothese 3.4: Leeftijd, geslacht en ervaring hebben een significante invloed op het verband tussen faciliterende omstandigheden en intentie tot gebruik.
▪ Hypothese 3.5: Leeftijd, geslacht en ervaring hebben een significante invloed op het verband tussen hedonische motivatie en intentie tot gebruik.
▪ Hypothese 3.6: Leeftijd en geslacht hebben een significante invloed op het verband tussen prijswaarde en intentie tot gebruik.
▪ Hypothese 3.7: Leeftijd, geslacht en ervaring hebben een significante invloed op het verband tussen gewoonte en intentie tot gebruik.
▪ Hypothese 3.8: Ervaring heeft een significante invloed op het verband tussen intentie tot gebruik en werkelijk gebruik.
▪ Hypothese 3.9: Leeftijd en ervaring hebben een significante invloed op het verband tussen faciliterende omstandigheden en werkelijk gebruik.
▪ Hypothese 3.10: Leeftijd, geslacht en ervaring hebben een significante invloed op het verband tussen gewoonte en werkelijk gebruik.
3.2.4. Hypothesen deelvraag 4
Deelvraag 4: Maken bepaalde groepen in Vlaanderen meer gebruik van intelligent assistants dan andere?
▪ Hypothese 4.1: Mannen gebruiken intelligent assistants meer dan vrouwen. ▪ Hypothese 4.2: Jongere mensen gebruiken intelligent assistants meer dan oudere
mensen.
3.3.
Populatie
De populatie in dit onderzoek zijn de inwoners van Vlaanderen. Volgens de recentste cijfers ligt dit aantal momenteel op 6.589.069 (Departement Kanselarij en Bestuur, 2019). Het
33 criterium voor deelname aan deze enquête is dus dat de respondent woonachtig is te
Vlaanderen.
3.4.
Steekproef
Om een populatie te onderzoeken wordt gebruik gemaakt van een steekproef. De omvang van de steekproef wordt bepaald met een specifieke formule. Voor populaties die zeer groot of oneindig zijn, wordt volgende formule toegepast:
𝑛 ≥ z
2 ∗ 𝑝(1 − 𝑝)
𝐹2
Hierbij geldt:
• n = de grootte van de steekproef
• z = de standaardafwijking bij het betrouwbaarheidspercentage • p = de kans op respons
• F = de foutmarge
Ingevuld volgens de gangbare cijfers voor een betrouwbaarheidspercentage van 95% wordt dit:
𝑛 ≥ 1,96
2∗ 0,5(1 − 0,5)
0,052
Deze berekening geeft een uitkomst van afgerond 384,16. De enquête voor dit onderzoek moet dus minimaal door 385 verschillende Vlamingen worden ingevuld.
3.5.
Datacollectie
De enquête voor de bevraging werd gemaakt in het online programma Qualtrics. Dit is het programma dat de Faculteit Economie en Bedrijfskunde van Universiteit Gent aanbiedt en aanraadt om te gebruiken.
Wegens de uitbraak van het COVID-19 virus werd deze enquête uitsluitend online verdeeld. Dit gebeurde hoofdzakelijk via sociale media. Familie en vrienden werden aangesproken via Facebook en Whatsapp. Daarnaast werd ook in verschillende lokale Facebookgroepen uit verschillende provincies in Vlaanderen een oproep gedaan om de enquête in te vullen. De
34 bedoeling hiervan was om antwoorden van over heel Vlaanderen te krijgen van mensen met uiteenlopende kenmerken.
3.6.
Vragenlijst
De vragenlijst was gebaseerd op de vragenlijst gebruikt in de originele UTAUT2-paper (Venkatesh et al., 2012), te vinden in bijlage 1. Na een algemene inleiding werden enkele vragen gesteld die kenmerken van de respondent bevraagden zoals geslacht, leeftijdsklasse en hoogst behaalde diploma.
Na een kleine voorstelling van intelligent assistants werden hierover enkele algemene vragen gesteld. Hierna volgden de blokken stellingen, afgeleid van het UTAUT2. Over deze stellingen moest de respondent aangeven in welke mate ze ermee akkoord gingen, op een Likertschaal met vijf opties van helemaal niet akkoord tot helemaal akkoord.
Op het einde van de enquête hadden de respondenten de keuze om al dan niet hun e-mailadres in te geven. Hiermee konden ze een waardebon voor een webshop winnen. Dit werd gedaan omdat dit de responsgraad kan verhogen (Laguilles et al., 2011). Ook had dit als doel de aandacht te trekken van mensen op sociale media. De volledige vragenlijst is te vinden in bijlage 2.
3.7.
Factoranalyse
Bij een factoranalyse is het de bedoeling om na te gaan of de verschillende vragen per construct ook effectief één construct meten. De factoranalyse geeft zo weer of bepaalde items al dan niet gebruikt mogen worden (Bauwens, 2018) en meet dus de
constructvaliditeit. Fout zou in dit onderzoek bijvoorbeeld zijn als twee van de drie vragen die prestatieverwachting meten, samen een ander construct meten. Hier is gekozen voor een confirmerende factoranalyse. Het doel van een confirmerende analyse is om de constructen te bevestigen en dus niet om nieuwe te zoeken, zoals bij exploratieve
factoranalyse. λ meet hierbij of de vragen eenzelfde construct meten. In dit onderzoek werd voor λ een ondergrens gebruikt van 0,5 (Bauwens, 2018).
In de literatuur wordt aangeraden om minimum drie stellingen per factoranalyse te gebruiken (Raubenheimer, 2004). In dit onderzoek was dit niet voor alle constructen het geval: faciliterende omstandigheden, prijswaarde, gewoonte en intentie tot gebruik hadden