datasets in Planner.js kunnen verbeteren
hypermedia controls de semantische beschrijving van
Een routeplanner op basis van Open Data: hoe
Academiejaar 2019-2020
Master of Science in de industriële wetenschappen: informatica Masterproef ingediend tot het behalen van de academische graad van
Delva
Begeleiders: Brecht Van de Vyvere, Julian Andres Rojas Melendez, Harm
Promotoren: prof. dr. ir. Ruben Verborgh, dr. Pieter Colpaert
Studentennummer: 01400033
Thomas Neuser
A routeplanner based on Open Data: how
hypermedia controls can be used to improve the
semantic description of datasets used by Planner.js
Thomas Neuser
Supervisor(s): Ruben Verborgh, Pieter Colpaert, Harm Delva, Juli´an Andr´es Rojas Mel´endez, Brecht Van de Vyvere
Abstract— Hypermedia controls are used to structure and describe data and are needed in the Routable Tiles specification, a Linked Data specifi-cation that partitions geographical Open Data from OpenStreetMap into square areas in a custom grid coordinate system. Planner.js, a Javascript library for route planning, makes use of datasets containing routable tiles and transit tiles (a data-reduced version of routable tiles) as an in-between alternative to full data dumps and RPC APIs. A new set of hypermedia con-trols was introduced that allows to describe the relation between routable and transit tiles while avoiding the need for clients to dynamically compute their access URL. A data catalog was introduced to describe the relations between the different datasets, while 2 tree-based structures were created to structure the routable and transit tiles. Planner.js got extended to perform tile discovery through tree-based traversing approaches, leading to higher route planning execution times (on average 1.57-1.61 times higher depend-ing on the tree traversdepend-ing method) and an increased number of requests (on average 1.78 times more requests) compared to the original tile discovery approach. In conclusion, by making relations among tiles explicit, reusing road network data for route planning purposes is facilitated for developers, but execution times went up because of the increasing number of requests and increasing amount of data to process. Future work will study alter-natives to optimize data fetching requirements for tree traversing on route planning scenarios in order to make this new approach less time consuming. Keywords—hypermedia controls, Planner.js, routable tiles, transit tiles
I. INTRODUCTION
H
YPERMEDIA controls are used in many ways. They can describe and structure data and give indications on how data can be used. Planner.js is a Javascript library for route planning developed by the Open Planner Team. The goal of Planner.js is to enable developers to set up a route planning client application in a efficient way. To be able to perform route planning, one has to provide geographical data. The routable tiles [1] dataset that is used by Planner.js contains geographi-cal data from OpenStreetMap (OSM). This geographigeographi-cal data includes the street network and is structured into square areas (hence the name routable tiles).II. RELATED WORK
A. Reduced data requirements by introducing transit tiles By fetching routable tiles one at a time during the route plan-ning process, one is able to gradually fetch and process pieces of data. Therefore this approach is a trade-off between full data dumps and RPC-APIs. Still, routable tiles can contain a lot of data. That’s why transit tiles were introduced. Those transit tiles are a reduced version of the routable tiles by omitting all ways that should not be used to traverse the tile itself (e.g. lo-cal districts, dead-end streets). Next to that, certain profiles can
be applied while reducing the routable tiles into transit tiles so that only ways are kept that are accessible for the used profile (e.g. when applying a car profile, all bike-only or pedestrian-only ways are omitted).
When performing the route planning, the client can now choose which type of tile it will fetch to get more data. When the tile to fetch contains the start- or endpoint of the route, a routable tile will be fetched. If not, a transit tile will be fetched because the necessary route doesn’t start or stop in that tile and so data requirements can be reduced.
III. INTRODUCED WORK
A. Omitting the need for conversion into tile numbers
The Routable Tiles specification partitions all of the street network geographical data from OpenStreetMap into a grid of tiles. To be able to retrieve the correct tile, each tile is as-signed coordinates depending on their position in the grid and the chosen zoom level. Before the start of this master’s the-sis, clients that were performing route planning queries based on datasets containing routable or transit tiles, had to know how WGS84-coordinates can be converted into tile coordinates (or tile numbers) to be able to fetch the necessary tile. In this mas-ter’s thesis, a new approach of structuring datasets containing routable and transit tiles is introduced. By establishing relations between the tiles themselves using the TREE-specification1, a
tree structure can be formed. This tree structure starts in a root tile (note that routable tiles and transit tiles are kept sepa-rated into different tree structures) and goes all the way down by using tree:GeospatiallyContainsRelation re-lations. This relation indicates a certain area, described by a WKT-string, that the tile associated with this relation cov-ers. Every tile now contains 4 tree:Geospatially-ContainsRelationrelations pointing to it’s 4 children. The tile’s children are 4 tiles on a higher zoom level that together cover the area of the tile itself. By using this new tree-kind structured datasets, instead of having to count on implemented conversion functions to get the correct tile numbers, a client can traverse the tree structure by following the correct relations un-til it arrives at the necessary un-tile. Because of the relations de-scribing areas pure (WGS84-)coordinate-based, clients do not have to know anything about the specific grid-based tile coordi-nates system. Next to the introduction of the new structuring of
route planning using these datasets.
B. Source description and selection through a catalog
Next to establishing relations between tiles in one dataset, there was also a need to explain to clients how transit tiles are related to routable tiles. An autonomous client should be able to select the data sources it needs based on hypermedia controls telling it what kind of data can be found into cer-tain datasets. This was done by making use of a catalog. A catalog that contains all of the possible datasets (in this case datasets containing routable or transit tiles) was introduced. By using the PROV Ontology [2] and the DCAT-2 [3] vocabu-lary and introducing the new subproperties ex:algorithm, ex:onDataand ex:usingProfile, the relation between transit and routable tiles could be described to make clear for clients such as Planner.js which dataset to use in certain cases.
IV. EVALUATION
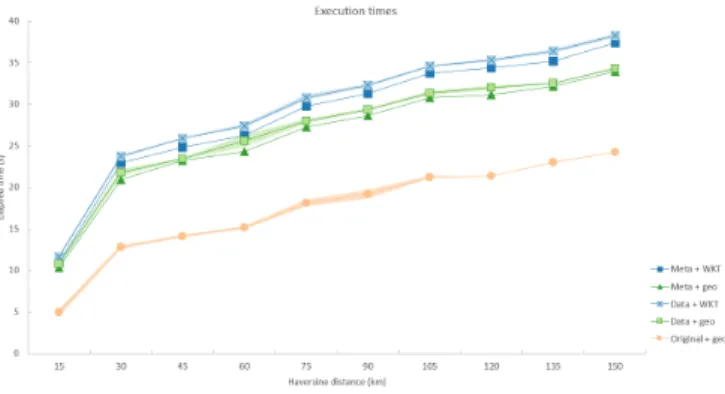
For each tile discovery approach, 50 route planning queries were executed using Node.js between points having a Haversine distance starting from 15 km to 150 km with intervals of 15 km (5 executions per query distance). A Nginx webserver was set up at the Virtual Wall of IDLab to provide the routable and tran-sit tile tree data. The client executing the route planning queries is a HP Spectre x360 Convertible, with 16GB RAM memory and a dual-core Intel i7 processor. The queries were executed following 5 different approaches, based on 2 differences. On the one hand, transit tile tree traversing was done by parsing all the data that is fetched when traversing the tree. On the other hand, as an optimisation, transit tile tree traversing was done by only parsing the metadata of the tiles, until arrived in the necessary tile. A second difference lies in the representation of osm:Node locations. One approach represents those loca-tions using a WKT-string, the other approach represents those locations using the geo:long and geo:lat2fields. The last
approach follows the way of solving the route planning query that was used before this master’s thesis.
V. RESULTS
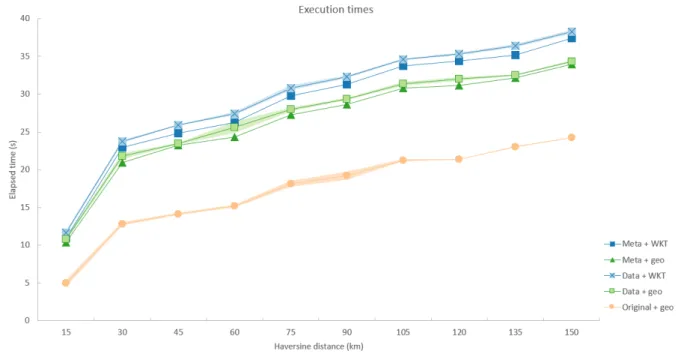
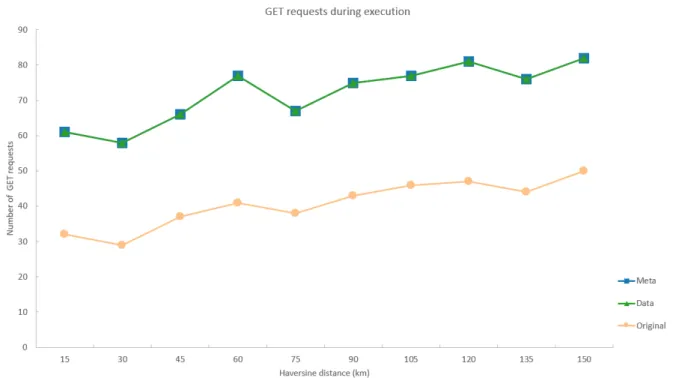
Fig. 1 shows the total route planning query execution times for the different approaches. The fact that metadata travers-ing approaches seem to require nearly as much execution time as regular data traversing approaches doesn’t square with the idea of introducing this kind of approach to lower the execu-tion times. This behaviour is due to the network latency times coming from retrieving the necessary tiles and is mainly in-fluenced by the fetch API from Node.js that doesn’t support HTTP/2 yet, leading to sequential execution of tile requests. Although planning algorithms have to process less data when using metadata traversing approaches, they still have to wait for the same amount of time to get the needed data fragments as regular data traversing approaches, because of the two different approaches using the same transit tile tree datasets. Next to that,
2see namespace http://www.w3.org/2003/01/geo/wgs84 pos
proaches using the geo:long and geo:lat fields to repre-sent these locations. This is because of the extra parsing needed when using WKT-strings as location representations.
Fig. 1. Comparison of total route planning query execution times for differ-ent tile discovery approaches. Metadata tree traversing approaches nearly need as much execution time as regular data tree traversing approaches, the original approach has the lowest execution times. Approaches using WKT-string location representations take more execution time than approaches using geo:long and geo:lat.
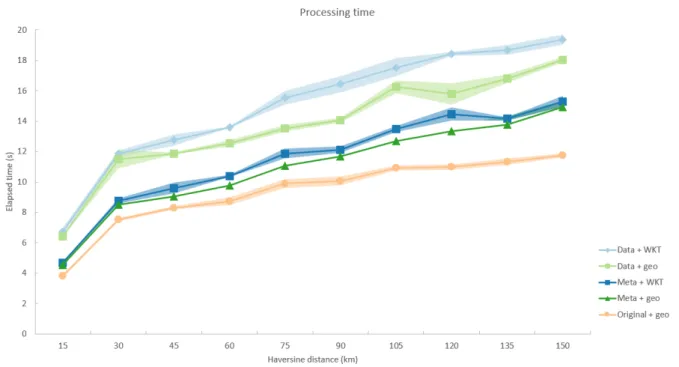
Still, to show the use of using metadata traversing approaches, pure processing times were measured and displayed in Fig. 2. These results are closer to the route planning query execution times when performed in modern browsers.
Fig. 2. Comparison of pure processing times for different tile discovery ap-proaches. Here, metadata tree traversing approaches clearly need less pro-cessing time than regular data tree traversing approaches. The original ap-proach still has the lowest processing times.
As can be seen in Fig. 2, metadata traversing approaches clearly do require less processing time compared to regular data traversing approaches. However, the original way of query exe-cution still remains the fastest approach. This is because of the tree traversing approach taking more time than the calculations for the conversion from WGS84-coordinates to tile numbers.
VI. CONCLUSION
Using the routable and transit tile tree structures avoids the need for implementing conversion functions from WGS84-coordinates to tile numbers. However, as seen in section V, this
approach increases execution time, even when using a metadata tree traversing approach. A possible solution to lower execu-tion times for the metadata tree traversing approach could be by introducing a metadata transit tile tree next to the current tran-sit tile tree for traversing purposes. When arrived in the needed metadata transit tile, an additional relation that leads to the cor-responding transit tile could be followed. The introduction of the catalog for source selection and source description makes sure that clients as Planner.js can comprehend which kind of data can be found at a certain access URL. After making the necessary adaptations to Planner.js, now checks to classify data based on hardcoded access URLs are replaced by checks on cer-tain derivation algorithms and profile types.
REFERENCES
[1] J. A. R. M. H. D. R. V. Pieter Colpaert, Ben Abelshausen, “Republishing openstreetmap’s roads as linked routable tiles,” Lecture Notes in Computer Science, vol. 11762, 2019.
[2] T. Lebo, S. Sahoo, D. McGuinness, K. Belhajjame, J. Cheney, D. Corsar, D. Garijo, S. Soiland-Reyes, S. Zednik, and J. Zhao, “Prov-o: The prov ontology,” W3C recommendation, vol. 30, 2013.
[3] F. Maali, J. Erickson, and P. Archer, “Data catalog vocabulary (dcat),” W3c recommendation, vol. 16, 2014.
Dankwoord
Allereerst zou ik graag mijn promotoren, prof. dr. ir. Ruben Verborgh en dr. Pieter Colpaert, bedanken om het mogelijk te maken voor mij om deze leerrijke en interessante masterproef te realiseren.
Het voorbije semester is niet altijd evident geweest. Sinds het virus COVID-19 roet in het eten kwam gooien, was het niet meer mogelijk om op locatie te gaan werken aan je masterproef en werden discussies, vragen of opmerkingen genoodzaakt gesteld of gevoerd te worden via de voorziene digitale kanalen. Het vele thuis zitten en jezelf telkens opnieuw moeten stimuleren om toch op een regelmatig tijdstip verder te werken aan de masterproef bleek een grotere opgave dan verwacht.
Toch zijn er heel wat mensen geweest die deze periode een stuk aangenamer gemaakt hebben en bijgedragen hebben aan mijn productiviteit. In het bijzonder zou ik graag mijn vriendin, Letitia, bedanken om via de regelmaat van haar thuiswerksituatie ook regelmaat en structuur te steken in mijn semester “in m’n kot” en er te zijn op momenten wanneer eens iets wat tegenstak.
Daarnaast zou ik graag ook mijn begeleider Harm bedanken voor de vele hulp en begeleiding. Bij vragen of voor feedback kon ik altijd bij hem terecht voor een duidelijk en uitgebreid antwoord. Door zijn manier van begeleiden zag ik hem meer als een oudere, wijzere vriend dan puur als begeleider en konden de meetings of het gechat ook wel eens plaatsmaken voor een grap of gesprekken over onderwerpen buiten het gebied van de masterproef.
Last but not least zou ik nog graag mijn ouders bedanken om het mogelijk te maken voor mij om deze studies te vervolmaken en zo met een mooie basis in het leven te kunnen stappen. Thomas Neuser
Inhoudsopgave
Lijst van figuren 12
Lijst van listings 13
1 Inleiding 15 1.1 Inleiding . . . 15 1.2 Probleemstelling en onderzoeksvraag . . . 16 2 Literatuurstudie 18 2.1 Inleidende begrippen . . . 18 2.1.1 Semantic Web . . . 18 2.1.2 Linked Data . . . 19 2.1.3 RDF . . . 19 2.1.4 JSON-LD . . . 22
2.2 Data voor routeplanning . . . 23
2.2.1 Linked Connections specificatie . . . 23
2.2.2 Routable Tiles specificatie . . . 26
2.3 Clients . . . 28
2.3.1 Planner.js . . . 28
2.3.2 Comunica . . . 28
2.4 Hypermedia . . . 29
2.4.1 Hypermedia zonder Linked Data . . . 29
2.4.2 Hypermedia met Linked Data . . . 32
3 Hydra:search 35 3.1 Nadelen en oplossing bij hydra:search . . . 36
3.1.1 Conversiefuncties via de Function Ontology en de Function Hub . . . 37
3.1.2 TREE-specificatie . . . 37
3.2 Wegwerken van hydra:search via de TREE-specificatie . . . 38
4 Preprocessed routable tiles 42 4.1 Data vereisten . . . 42
4.2 Mogelijke vormen van preprocessing . . . 43
5 Transit tiles 44 5.1 Preprocessing in deze masterproef . . . 44
5.2 Definiëren van de relaties tussen verschillende datasets . . . 45
5.3 Structureren van de transit tiles binnen de dataset zelf . . . 48
5.4 De transit tile tree . . . 49
6 Planner.js 52 6.1 Architectuur . . . 52
6.2 Routeplanning binnen Planner.js . . . 53
6.3 Gemaakte aanpassingen . . . 55
INHOUDSOPGAVE 11
6.5 Aanpassingen bij routable tiles . . . 58
6.6 Uiteindelijke fetchTile algoritme . . . 59
6.7 Catalogus in Planner.js . . . 61 7 Evaluatie 65 7.1 Opzetten testomgeving . . . 65 7.2 Uitvoeringen . . . 66 7.3 Resultaten . . . 67 7.3.1 Totale uitvoeringstijd . . . 67 7.3.2 Pure verwerkingstijd . . . 69
7.3.3 Aantal tile requests . . . 71
8 Conclusie 73 8.1 Conclusies m.b.t. de tree structuur . . . 73
8.2 Conclusies m.b.t. de data catalogus . . . 74
8.3 Conclusies m.b.t. Planner.js . . . 74
8.4 Conclusies bij meetresultaten . . . 75
9 Future work 76
10 Overzicht repositories 78
2.1 Verschillende serialisaties van dezelfde informatie . . . 20
2.2 Schematische voorstelling van een triple . . . 21
2.3 Vergelijking van data dumps met RPC API’s . . . 23
2.4 Schematische voorstelling van de Linked Connections specificatie . . . 24
5.1 De oranje wegen zijn overbodig en worden weggelaten bij de transformatie van een routable tile naar een transit tile . . . 45
7.1 Resultaten van de totale uitvoeringstijden bij benchmarking tussen de verschil-lende aanpakken. Uitvoeringstijden kunnen grofweg worden opgedeeld in drie gro-te lijnen. Uitvoeringen waarbij de locaties van nodes werden voorgesgro-teld d.m.v. WKT-strings hebben de hoogste uitvoeringstijden, gevolgd door uitvoeringen die deze locaties voorstelden aan de hand van de velden geo:long en geo:lat en de originele uitvoeringsaanpak met de laagste uitvoeringstijden. . . 68
7.2 Resultaten van de pure verwerkingstijden bij benchmarking tussen de verschil-lende aanpakken. Hier liggen de tijden van metadata tree traversing uitvoeringen duidelijker lager dan van uitvoeringen die gebruik maken van gewone data tree traversing. De originele tile discovery aanpak blijkt ook hier de laagste verwer-kingstijd te hebben. . . 70
7.3 Resultaten van het aantal tile requests bij benchmarking tussen de verschillende aanpakken. Uitvoeringen via metadata tree traversing hebben exact evenveel re-quests nodig als uitvoeringen via gewone data tree traversing, uitvoeringen via de originele aanpak hebben duidelijk een kleiner aantal requests. . . 72
Lijst van listings
2.1 Gebruik van triples . . . 20
2.2 Triple die gebruik maakt van URI’s . . . 21
2.3 Voorbeeld JSON-LD . . . 22
2.4 Inhoud van @context . . . 25
2.5 Codefragment van een Connection . . . 26
2.6 Codevoorbeeld HAL . . . 30
2.7 Codevoorbeeld JSON:API . . . 31
2.8 Codevoorbeeld van een activity stream . . . 34
3.1 hydra:search . . . 36
3.2 Tree structuur op basis van relaties m.b.t. de longitude en latitude van nodes . . 39
3.3 Tree structuur met WKT-strings . . . 40
3.4 Specifieke conversiefuncties voor het converteren van tilenummers naar WGS84-coördinaten . . . 41
5.1 De data catalogus . . . 47
5.2 tree:GeospatiallyContainsRelation relaties naar de vier kinderen van een tile . . . 51
6.1 Methode pickTile . . . 54
6.2 Methode traverseTransitTree . . . 56
6.3 Methode traverseTransitTree na de optimalisatie . . . 58
6.4 fetchTile methode . . . 61
6.5 classifyDataSource . . . 62
6.6 classifyDataSet als alternatief voor classifyDataSource . . . 63
1
Inleiding
1.1
Inleiding
Data spelen een grote rol in alle facetten van het dagelijks leven. Eén van die facetten is wanneer we ons moeten verplaatsen van punt A naar punt B. De meest gekende tools hiervoor zijn routeplanners zoals Google Maps of Waze, die we gebruiken om ons te verplaatsen met de wagen, fiets, trein, enzovoort. Naast deze typische voorbeelden kunnen routeplanners nog in andere vormen voorkomen, zo zijn er routeplanners voor wandelpaden, mountainbikeroutes en voor openbaar vervoer alternatieven zoals bijvoorbeeld deelsteps.
Het World Wide Web (WWW) kan gezien worden als grootste verschaffer van data. Het werd uitgevonden door Tim Berners-Lee in 1989. Door het gebruik van HTML (HyperText Mark-up Language), HTTP (HyperText Transfer Protocol) en URI’s (Uniform Resource Identifiers) blijft na ongeveer 30 jaar het hoofddoel van het WWW nog intact: informatie uitwisselen en communiceren op een eenvoudige manier.
Een nieuwe richting die werd ingeslaan enkele jaren geleden was die van de Open Data. Om te spreken van Open Data moet er rekening gehouden worden met drie verschillende eigenschap-pen: de data moet in een open formaat beschikbaar zijn, mag hergebruikt en met andere data geïntegreerd worden en mag gebruikt worden door iedereen. Verschillende redenen leidden tot
het beschikbaar stellen van data die niet toebehoren aan één organisatie of bedrijf. Redenen hiervoor waren o.a. het tegengaan van de groter wordende macht van tech giganten zoals Google die heel veel data bezitten en ter beschikking stellen waardoor andere bedrijven die deze data gebruiken er afhankelijk van worden, het vermijden van copywrite issues of het vergroten van de openbaarheid van bestuur en transparantie (bv. in de vorm van bestuursdocumenten). Deze Open Data kan ook linked zijn, we spreken dan van Open Linked Data.
De overstap naar Open Data gebeurde ook bij de NMBS. In 2008 startten Yeri Tiete en Pieter Colpaert het iRail project op. De NMBS had een routeplanner ontwikkeld, maar de data die hiervoor gebruikt werd was niet vrij toegankelijk. Als gevolg daarvan konden externe ontwik-kelaars geen gebruik maken van deze data. Nadat de Open Data gemeenschap de NMBS kon overtuigen van de voordelen die Open Data met zich meebrengt, zetten ze de stap in 2015 naar Open Data.
Een minder gekend gegeven onder het grote publiek is Planner.js. Planner.js [1] is een Javascript library ontwikkeld door het Open Planner Team met als doel iedereen die het wenst toe te laten om op een snelle en efficiënte manier een eigen specifieke routeplanner op te zetten. Het is via Planner.js mogelijk om aan routeplanning te doen voor zowel wagenverkeer als openbaar vervoer, waarbij er voor de achterliggende data gebruik wordt gemaakt van Open Linked Data.
Om deze data bruikbaar te maken voor meerdere clients moeten ze op een goede semantische manier beschreven worden. Het moet duidelijk zijn voor een client wat te vinden is een dataset, waar de client bepaalde andere data nog kan vinden en hoe hij zich een weg kan banen door de verschillende datasets. Dit is waar hypermedia controls in het verhaal komen. Hypermedia controls maken het mogelijk om datasets te beschrijven en mogelijke acties op de data aan te geven.
1.2
Probleemstelling en onderzoeksvraag
Binnen het Open Planner Team werden al verschillende datasets samengesteld die gebruik maken van hypermedia controls. Toch schieten deze nog soms te kort in hun beschrijvingen. Zo zijn bijvoorbeeld hypermedia controls in de vorm van hydra:next en hydra:previous1 in feite niet
meer dan controls om de verschillende pagina’s sequentieel af te lopen en geven ze aan een query agent geen specifieke info van wat op een bepaalde pagina te vinden is.
In deze masterproef wordt er onderzocht hoe verschillende datasets die gebruikt worden bij clients zoals Planner.js op een betere manier beschreven kunnen worden. Een mogelijkheid hier-voor is bijhier-voorbeeld de datasets opnieuw designen en hierbij andere hypermedia controls te
1.2. PROBLEEMSTELLING EN ONDERZOEKSVRAAG 17
gebruiken of nieuwe hypermedia controls in het leven te roepen. Dit met als doel om query agents zowel te kunnen laten begrijpen wat er in een bepaald document of bepaalde dataset te vinden is als om het mogelijk te maken om zich op een autonome manier een weg te laten banen doorheen datasets op zoek naar de benodigde data. Verschillende use cases zullen worden bekeken en aangepast of geïmplementeerd worden.
De onderzoeksvraag voor deze masterproef luidt als volgt:
Hoe kunnen hypermedia controls aangewend of aangepast worden om reeds bestaande datasets die gebruikt worden door Planner.js beter en op een meer generische manier semantisch te beschrijven?
2
Literatuurstudie
2.1
Inleidende begrippen
2.1.1 Semantic Web
Het Semantic Web [2] of anders genoemd “The Web of Data” is een uitbreiding op het World Wide Web (WWW) met als doel om de data op het internet door machines interpreteerbaar te maken. Hierbij worden pagina’s op het internet semantisch beschreven, wat wil zeggen dat ze op een manier beschreven worden waardoor ze een betekenis krijgen en machines deze beteke-nis kunnen begrijpen. Dit is mogelijk door het gebruik van Semantic Web technologieën zoals bijvoorbeeld RDF en SPARQL [3] die een omgeving aanbieden waar applicaties data kunnen opvragen en links kunnen leggen tussen verschillende datasets door gebruik te maken van be-paalde vocabularies. Het leggen van de links tussen de data zorgt voor de creatie van een web van relaties, vandaar de naam ”The Web of Data”. Naar het geheel van aan elkaar gelinkte datasets kan ook gerefereerd worden als Linked Data.
2.1. INLEIDENDE BEGRIPPEN 19
2.1.2 Linked Data
Data staan op het web verspreid over verschillende machines en pagina’s, in verschillende do-cumenten en datasets. Een manier om deze data te publiceren en onderling geconnecteerd te krijgen is via de Linked Data principes [4]. Linked Data is één van de hoekstenen van het Seman-tic Web. Het maakt het mogelijk om links te leggen tussen verschillende datasets die niet alleen door mensen interpreteerbaar zijn maar ook door machines. In tegenstelling tot het WWW zijn deze links geen relationele ankerpunten geschreven in HTML, maar zijn het links tussen wille-keurige zaken beschreven in RDF. Er zijn vier regels/ best practices die gevolgd kunnen worden om goede Linked Data te publiceren.
• Gebruik URI’s (Uniform Resource Identifier) als namen voor objecten
• Gebruik HTTP URI’s zodat de namen gemakkelijk opgezocht kunnen worden
• Als een URI opgezocht wordt, zorg er dan voor dat er nuttige informatie wordt aangeboden, gebruik makend van de standaarden (RDF, SPARQL, ...)
• Zorg voor links naar andere URI’s, zodat nog meer zaken kunnen worden ontdekt
Deze regels zijn niet bindend maar door ze niet te volgen gaan er kansen verloren om de data op een goede manier te connecteren.
Nu is de vraag of Linked Data in het kader van deze masterproef een betekenis of nut heeft en of het dus interessant is om tijdens het structureren van de datasets deze regels indachtig te houden. De voornaamste reden waarvoor het gebruik van Linked Data noodzakelijk lijkt is het wegwerken van mogelijke ambiguïteit. Een voorbeeld ter verduidelijking:
Stel dat er twee verschillende datasets zijn die beide spreken over het “Sint-Pietersplein”. Hoe weten we zeker dat ze het beiden over het Sint-Pietersplein in Gent hebben en daarbij beiden spreken over het plein zelf of over de parking eronder? Wanneer er in beide datasets gebruik gemaakt wordt van Linked Data door als naam niet Sint-Pietersplein maar een URI naar het document met informatie over het Sint-Pietersplein te gebruiken, kan enige twijfel over of het over hetzelfde plein gaat uitgesloten worden. Dit voorbeeld alleen al toont aan dat Linked Data wel degelijk nut heeft in deze masterproef en het dan ook interessant is om de principes ervan toe te passen in de datasets.
2.1.3 RDF
Het Resource Description Framework (RDF) [5] is een framework gecreëerd door het W3C. Het is bedoeld als standaard voor het beschrijven van resources of informatie op het web. Er bestaan
veel verschillende serialisaties om data voor te stellen die exact dezelfde informatie bevatten maar op een andere manier gestructureerd worden. Zo kan zoals te zien is in Figuur 2.1 [6] informatie over een bepaalde parking voorgesteld worden in zowel XML als JSON. RDF probeert de informatie uit verschillende serialisaties te halen en zo een standaardisatie voor de voorstelling van bepaalde informatie te bekomen. Dit wordt door RDF gerealiseerd via het gebruik van triples, de kern van dit framework. RDF maakt het eenvoudig om verschillende datasets te mergen, ook al zijn hun onderliggende schema’s verschillend.
Figuur 2.1: Verschillende serialisaties van dezelfde informatie
De informatie uit Figuur 2.1 kan in triples gegoten worden, het resultaat hiervan is dan:
1 <stP-Plein> <type> <Parking> .
2 <stP-Plein> <city> <Gent> .
3 <Gent> <population> "275k" .
Listing 2.1: Gebruik van triples
Een semantic triple of kortweg triple [7] is de kleinste entiteit binnen het RDF framework. Triples kunnen gezien worden als de kleinste zinnen die terug te vinden zijn in data. Zoals de naam triple al aangeeft bestaan ze telkens uit drie delen die er als volgt uit zien:
• iets of iemand • heeft een relatie met • een ander iets of iemand
Deze drie delen zijn respectievelijk een subject, een predicaat en een object en kunnen visueel voorgesteld worden zoals in Figuur 2.2. Het subject kan een IRI (Internationalized Resource Identifier)1 of een lege knoop zijn, het predicaat is een IRI en het object kan een IRI, een
2.1. INLEIDENDE BEGRIPPEN 21
literal (string, getal, datum, ...) of een lege knoop zijn. Het einde van een triple wordt aangeduid met een punt.
Figuur 2.2: Schematische voorstelling van een triple
Triples maken het mogelijk om informatie weer te geven op een door machines leesbare manier. Een simpel voorbeeld van triples was al terug te vinden in Listing 2.1. In de eerste triple heeft het subject stP-Plein een relatie is van het type met het object Parking. Een voorbeeld die binnen Linked Data en het Semantic Web echter interessanter is, is te vinden in Listing 2.2.
1 http://example.name#BobSmith12 http://xmlns.com/foaf/0.1/knows http://example.name#JohnDoe34 .
,→
Listing 2.2: Triple die gebruik maakt van URI’s
In het voorbeeld in Listing 2.2 wordt er voor alle drie delen van de triple gebruik gemaakt van URI’s. Deze aanpak volgt de vooropgestelde regels van Linked Data: zowel het subject, predicaat als object zijn eenduidig gedefinieerd en kunnen verder opgezocht worden. De verzameling van de gebruikte hypermedia controls/ URI’s binnen een dataset wordt de vocabulary van die dataset genoemd. Veelal wordt er gebruik gemaakt van hypermedia controls uit vocabularies die al gedefinieerd zijn, zoals bijvoorbeeld de Hydra Core Vocabulary. Deze bevinden zich dan in een namespace (in dit voorbeeld http://www.w3.org/ns/hydra/core#), die aangegeven wordt door een prefix (hydra:).
Een verzameling van triples wordt een RDF graaf [5] genoemd. Deze kan gevisualiseerd worden als een gerichte graaf, waarbij iedere triple voorgesteld wordt als een knoop-verbinding-knoop stuk. Een RDF dataset is een verzameling van RDF grafen en bestaat uit een default RDF graaf die geen naam heeft en leeg mag zijn en nul of meerdere RDF grafen met naam die uniek zijn binnen de RDF dataset.
Er bestaan verschillende serialisaties voor het RDF formaat. Zo is er de Notation3 (N3) [9] familie, met serialisaties zoals Turtle, trig, N-triples, N-quads en N3. Deze serialisaties zien er uit zoals de triples die in de voorbeelden hierboven werden voorgesteld. Daarnaast bestaan er ook RDF serialisaties die al bestaande serialisaties gebruiken om de triples in weer te geven. Voorbeelden hiervan zijn RDF/XML en JSON-LD. JSON-LD wordt vaak gebruikt in de datasets waarvan Planner.js gebruik maakt en wordt in de volgende paragraaf besproken.
2.1.4 JSON-LD
JSON-LD [10] is een op JSON gebaseerde RDF serialisatie die het mogelijk maakt om Linked Data te serialiseren. De bedoeling ervan is het mogelijk maken om Linked Data in web-based programmeeromgevingen te gebruiken, om interoperabele web services te bouwen en om Lin-ked Data in JSON-gebaseerde opslagruimtes op te kunnen slaan. Aangezien JSON-LD 100% compatibel is met JSON, kunnen de vele JSON parsers en libraries die al bestaan hergebruikt worden.
JSON-LD introduceert naast de al bestaande features van JSON enkele nieuwigheden:
• een uniek identificatiemechanisme door gebruik te maken van IRI’s
• een mechanisme waarbij een waarde in een JSON object kan refereren naar informatie op een andere site op het internet
Wanneer een RDF graaf of dataset moet geserialiseerd worden in JSON-gebaseerde syntax is JSON-LD de oplossing.
Een simpel voorbeeld is te vinden in Listing 2.3 [11]. Hier wordt een persoon voorgesteld met de naam John Lennon, die geboren is op 9 oktober 1940. In het voorbeeld zijn verschillende IRI’s terug te vinden die wijzen naar informatiebronnen die zich op een andere pagina bevinden, verschillende datastukken worden aan elkaar gelinkt en zo wordt Linked Data bekomen.
1 {
2 "@context": "https://json-ld.org/contexts/person.jsonld",
3 "@id": "http://dbpedia.org/resource/John_Lennon",
4 "name": "John Lennon",
5 "born": "1940-10-09",
6 "spouse": "http://dbpedia.org/resource/Cynthia_Lennon"
7 }
2.2. DATA VOOR ROUTEPLANNING 23
2.2
Data voor routeplanning
In deze masterproef wordt er gewerkt rond datasets die gebruikt worden voor routeplanning. Deze datasets bevatten zowel data in verband met wegen en paden als data voor het openbaar vervoer. Bij het opvragen en verwerken van data voor routeplanning kan grosso modo op twee manieren te werk gegaan worden. Aan de ene kant van het spectrum zijn er data dumps. Hierbij doet een client een aanvraag aan een server die data voor routeplanning bevat en deze in de vorm van data dumps beantwoordt. Aan de andere kant van het spectrum zijn er Remote Procedure Call (RPC) API’s. Hierbij stuurt de client een vraag naar de server waarop de server het rekenwerk uitvoert en de vraag specifiek beantwoordt met de benodigde info.
Beide manieren hebben hun voor- en nadelen. Bij data dumps is het mogelijk om via één data dump en dus één request naar de server meerdere vragen te beantwoorden en te berekenen client-side, terwijl bij RPC API’s per vraag één request naar de server nodig is. Aan de andere kant zal in normale omstandigheden het rekenwerk server-side wel sneller uitgevoerd kunnen worden. Het probleem bij het rekenwerk uitvoeren server-side is de schaalbaarheid, aangezien de server infrastructuur moet aangepast worden naargelang het aantal clients die requests uitsturen. Figuur 2.3 [12] maakt de vergelijking tussen beide manieren.
Figuur 2.3: Vergelijking van data dumps met RPC API’s
Zoals te zien is op Figuur 2.3 bestaan er alternatieven die proberen een afweging te maken tussen beide uitersten, de Linked Connections specificatie is hier een voorbeeld van.
2.2.1 Linked Connections specificatie
In de Linked Connections specificatie [13] worden de data gestructureerd volgens de principes van Linked Data. Deze specificatie zorgt voor een compromis tussen data dumps en RPC API’s. De Linked Connections specificatie schuift een publicatiemechanisme naar voor waarbij de data
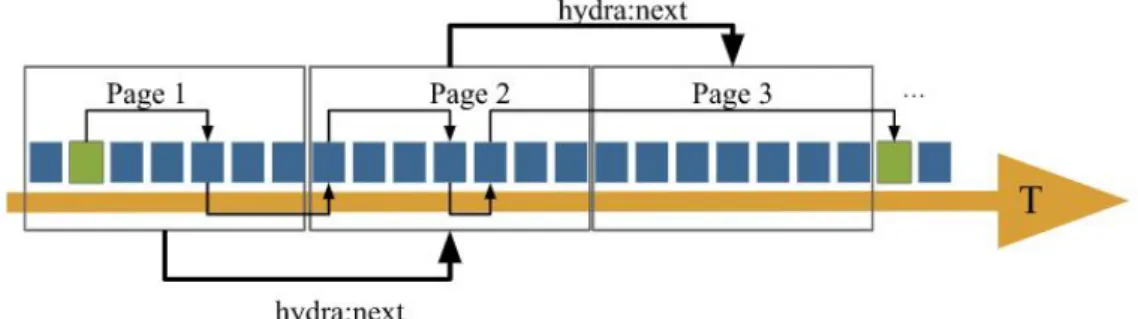
met betrekking tot het openbaar vervoer worden voorgesteld in vertrek-aankomst paren tussen 2 stations. Deze paren zijn de kleinste bouwstenen en worden Connections genoemd. Ze worden geordend volgens de vertrektijden. De dataset wordt dan opgedeeld in fragmenten (in de vorm van pagina’s) die over HTTP verstuurd kunnen worden. Doordat er bij het ophalen van een document ook hypermedia controls worden mee verstuurd, kan er verzekerd worden dat een client altijd meer informatie kan verkrijgen. De links om te navigeren tussen de verschillende pagina’s zijn hydra:next en hydra:previous, en verwijzen respectievelijk naar de volgende en vorige pagina met data. Een visualisatie hiervan is te vinden in Figuur 2.4.
Figuur 2.4: Schematische voorstelling van de Linked Connections specificatie
Een dataset die de Linked Connections specificatie volgt, is die van de NMBS, die gehosted wordt door iRail. De dataset wordt weergegeven in een JSON-LD serialisatie en is te vinden in de volgende listings.
In Listing 2.4 is de inhoud van @context te zien. Als twee personen in gesprek zijn, vindt het gesprek plaats in een gedeelde omgeving, die de context van het gesprek genoemd wordt. Een context zorgt ervoor dat personen afkortingen kunnen gebruiken zonder verlies te doen aan duidelijkheid. Bijvoorbeeld kan er in een bepaalde context een afkorting van een naam van een vriend gebruikt worden. @context in JSON-LD werkt net op dezelfde manier en zal korte woorden mappen op IRI’s zodat die gebruikt kunnen worden in plaats van telkens de volledige IRI. Daarnaast worden binnen @context de gebruikte namespaces en velden die later in het document gebruikt worden gedefinieerd.
1 { 2 "@context": { 3 "xsd": "http://www.w3.org/2001/XMLSchema#", 4 "lc": "http://semweb.mmlab.be/ns/linkedconnections#", 5 "hydra": "http://www.w3.org/ns/hydra/core#", 6 "gtfs": "http://vocab.gtfs.org/terms#", 7 "Connection": "lc:Connection",
2.2. DATA VOOR ROUTEPLANNING 25 8 "CancelledConnection": "lc:CancelledConnection", 9 "arrivalTime": { 10 "@id": "lc:arrivalTime", 11 "@type": "xsd:dateTime" 12 }, 13 "departureTime": { 14 "@id": "lc:departureTime", 15 "@type": "xsd:dateTime" 16 }, 17 ... 18 }, 19 ... 20 }
Listing 2.4: Inhoud van @context
Naast @context zijn er nog andere hypermedia controls belangrijk binnen een Linked Connec-tions document, deze worden hieronder opgelijst:
• @id: dit veld bevat de identifier van het document • @type: dit veld specificeert het type van het document
• hydra:next en hydra:previous: bevatten de URI naar respectievelijk het volgende en vorige document
• hydra:search: dit veld bevat informatie over hoe de huidige pagina kan bereikt worden • @graph: dit veld bevat de eigenlijke data (in dit geval dus de Connection’s), deze bevatten
op hun beurt alle of enkele van de volgende velden:
– @type: dit veld geeft aan dat het over een Connection gaat
– departureStop en arrivalStop: deze velden bevatten URI’s naar respectievelijk het
vertrekstation en het bestemmingsstation
– departureTime en arrivalTime: deze velden bevatten respectievelijk het tijdstip van
vertrek en van aankomst
– departureDelay en arrivalDelay: deze velden geven aan hoeveel de vertraging bij
vertrek en aankomst bedraagt
– gtfs:trip: dit veld geeft de huidige trip aan waartoe deze Connection behoort, een
trip is een opeenvolging van 2 of meerdere stops die gebeuren in een bepaald tijdsin-terval
– gtfs:route: dit veld geeft aan tot welke route de Connection behoort, een route is
een verzameling van trips die naar de reiziger toe weergegeven worden als een enkele service
– direction: dit veld geeft de richting aan van de Connection
De meeste waarden van de velden in deze listing bevatten een URI die op een eenduidige manier de vertrekstations, bestemmingsstations, routes enzovoort aangeeft. Hier is dus zeker weer sprake van Linked Data.
Listing 2.5 toont aan hoe een Connection er uit kan zien.
1 { 2 "@id": "http://irail.be/connections/8896925/20200324/IC835", 3 "@type": "Connection", 4 "departureStop": "http://irail.be/stations/NMBS/008896925", 5 "arrivalStop": "http://irail.be/stations/NMBS/008896909", 6 "departureTime": "2020-03-24T13:26:00.000Z", 7 "arrivalTime": "2020-03-24T13:29:00.000Z", 8 "gtfs:trip": "http://irail.be/vehicle/IC835/20200324", 9 "gtfs:route": "http://irail.be/vehicle/IC835", 10 "direction": "Bruges", 11 "gtfs:pickupType": "gtfs:Regular", 12 "gtfs:dropOffType": "gtfs:Regular" 13 }
Listing 2.5: Codefragment van een Connection
2.2.2 Routable Tiles specificatie
Een andere specificatie die voor een compromis zorgt tussen data dumps en RPC API’s is de Routable Tiles specificatie [14]. De Routable Tiles specificatie is ontwikkeld door het Open Planner Team en is een light-weight Linked Data specificatie voor het publiceren van een we-gennetwerk opgedeeld in tegels (later tiles genoemd). Als een server zijn wewe-gennetwerk op deze manier publiceert, is het mogelijk voor een client om at runtime tijdens het uitvoeren van de routeplanning aan tile discovery te doen om meer data te voorzien. De specificatie maakt gebruik van een JSON-LD serialisatie om de data voor te stellen.
De data die worden voorgesteld zijn afkomstig van OpenStreetMap (OSM) en de ontologie van deze specificatie probeert zo goed mogelijk het datamodel van OSM te volgen. De drie
2.2. DATA VOOR ROUTEPLANNING 27
hoofdklassen zijn osm:Way, osm:Relation en osm:Node. osm:Node beschrijft een bepaald punt op de kaart, osm:Way stelt een weg voor op de kaart die bestaat uit meerdere osm:Node’s en osm:Relation legt relaties tussen de verschillende entiteiten.
Naast een Linked Data specificatie introduceert de Routable Tiles specificatie ook een hyper-media specificatie die hergebruik maakt van Hydra Collections om de tile server te beschrijven, dit komt later nog aan bod. Voor de URI’s van osm:Node’s en osm:Way’s worden de pagina’s van OpenStreetMap gebruikt. Zo ziet de URI van een osm:Node er bijvoorbeeld als volgt uit: openstreetmap.org/node/366934331.
2.3
Clients
2.3.1 Planner.js
Planner.js [1] is een JavaScript library die gebruikt wordt voor routeplanning. De reden voor het ontwikkelen van Planner.js was de nood aan een framework dat het mogelijk maakt om op een relatief eenvoudige manier een routeplanner op te zetten. Het opzetten van een eigen routeplanner is immers een zware en tijdsintensieve taak waarbij eerst de correct data dumps gevonden moeten worden om die dan om te zetten naar het correcte formaat. Daarna moeten de data nog geconnecteerd worden aan een routeplanning systeem. Voor het beheren van real-time data (indien die bestaan) moet dan nog eens een ander systeem gebruikt worden.
De architectuur van Planner.js bestaat uit drie grote delen:
• Fetchers: dit zijn de klassen die zorgen voor het effectieve ophalen van de benodigde data. Elke fetcher is verbonden aan één databron en zal de data parsen en de nodige verwerking erop doen.
• Providers: deze klassen kunnen gezien worden als de data interfaces. Providers zullen de correcte fetcher aanroepen op basis van de data die nodig zijn. Providers zijn de component tussen fetchers en planners.
• Planners: deze klassen implementeren de routeplanning zelf en roepen methodes van de providers aan om hen te voorzien van de nodige data hiervoor.
2.3.2 Comunica
Comunica [15] is een framework dat het mogelijk maakt om queries op Linked Data op het web uit te voeren. Comunica kan geïnstantieerd worden als query engine die SPARQL queries kan verwerken. De queries kunnen data ophalen van verschillende bronnen, dit kunnen Triple Pattern Fragment interfaces, SPARQL endpoints of data dumps in verschillende RDF serialisaties zijn. Comunica is een modulair framework. Dit betekent dat Comunica een verzameling van modules is die kunnen gecombineerd worden om een bepaalde taak uit te voeren.
2.4. HYPERMEDIA 29
2.4
Hypermedia
Het doel in deze masterproef is onderzoeken op welke manier hypermedia controls kunnen worden aangewend om op een betere manier te kunnen beschrijven wat er zich in bepaalde datasets bevindt en hoe verder kan worden genavigeerd binnen de dataset of richting andere datasets om zo meer informatie terug te vinden.
Als startpunt is het interessant om een definitie van hypermedia te geven. Hypermedia kan gezien worden als een veralgemening van hypertext. Hypertext is tekst die niet beperkt is tot lineair zijn (bijvoorbeeld tekst zoals ze bestaat in een boek), maar links naar andere tekst kan bevatten. Hypermedia is een veralgemening hiervan in de zin dat hypermedia niet beperkt is tot tekst maar ook afbeeldingen, geluid, video enzovoort kan bevatten.
Hypermedia controls zijn een combinatie van protocol methodes en link relaties in een hyper-media formaat die aangeven aan een client welke state overgangen er mogelijk zijn en hoe ze uitgevoerd kunnen worden. Het basisidee is dat een representatie van een resource of een ob-ject de client zou moeten vertellen wat hij met dat obob-ject of die resource kan doen of welke gerelateerde acties ondernomen kunnen worden.
Nu is de vraag op welke manieren we hypermedia hiervoor kunnen gebruiken. Er bestaan al wat specificaties die gebruik maken van hypermedia, zowel gebruik makend van Linked Data als zonder. Deze worden in de volgende paragrafen uitgediept.
2.4.1 Hypermedia zonder Linked Data
HAL
Een eerste formaat is Hypertext Application Language (HAL). HAL [16] is een simpel formaat, dat zonder gebruik van Linked Data een eenvoudige en consistente manier aanbiedt om hyper-links te leggen tussen verschillende resources in een API. Het gebruiken van HAL in je API zorgt ervoor dat de API verkenbaar wordt en de documentatie dus kan verkend worden binnenin de API zelf. HAL biedt een verzameling conventies aan om de hyperlinks uit te drukken in JSON of XML.
Het HAL model bestaat uit twee concepten: resources en links. Resources bestaan uit links, ingebedde resources en een staat. Links bestaan uit een doel (de URI), een relatie met de resource en eventuele extra eigenschappen voor extra informatie.
De voorbeeldcode in Listing 2.6 toont de links en embedded resources, respectievelijk onder _links en _embedded.
1 {
2 "_links": {
3 "self": { "href": "/orders" },
4 "curies": [{ "name": "ea", "href":
"http://example.com/docs/rels/{rel}", "templated": true }],
,→
5 "next": { "href": "/orders?page=2" },
6 ... 7 }, 8 "currentlyProcessing": 14, 9 "shippedToday": 20, 10 "_embedded": { 11 "ea:order": [ 12 { 13 "_links": {
14 "self": { "href": "/orders/123" },
15 "ea:basket": { "href": "/baskets/98712" },
16 "ea:customer": { "href": "/customers/7809" }
17 }, 18 "total": 30.00, 19 "currency": "USD", 20 "status": "shipped" 21 }, 22 ... 23 ] 24 } 25 }
Listing 2.6: Codevoorbeeld HAL
JSON:API
Een ander voorbeeld die ook geen gebruik maakt van Linked Data is de JSON:API specificatie. JSON:API [17] is gedesigned met de bedoeling om het aantal requests en de getransfereerde data tussen clients en servers te minimaliseren. Het codevoorbeeld in Listing 2.7 is een mogelijk antwoord van een server die JSON:API implementeert. Hier is te zien dat het antwoord een attribuut links bevat met onder andere links naar volgende of vorige delen van de dataset, daarnaast bevat het ook het attribuut data die dan de effectieve data bevat samen met opnieuw nog andere links.
2.4. HYPERMEDIA 31 1 { 2 "links": { 3 "self": "http://example.com/articles", 4 "next": "http://example.com/articles?page[offset]=2", 5 "last": "http://example.com/articles?page[offset]=10" 6 }, 7 "data": [{ 8 "type": "articles", 9 "id": "1", 10 "attributes": {
11 "title": "JSON:API paints my bikeshed!"
12 }, 13 "relationships": { 14 "author": { 15 "links": { 16 "self": "http://example.com/articles/1/relationships/author", 17 "related": "http://example.com/articles/1/author" 18 },
19 "data": { "type": "people", "id": "9" }
20 },
21 ...
22 }],
23 }
2.4.2 Hypermedia met Linked Data
Hydra
Hydra is ontstaan vanuit een poging om de ontwikkeling van interoperabele, hypermedia-driven Web API’s te vereenvoudigen. De twee fundamentele pijlers van Hydra zijn JSON-LD en de Hydra Core Vocabulary.
Hydra Core
De Hydra Core Vocabulary [18], ontwikkeld door de W3C Hydra Community Group, voorziet een lightweight vocabulary voor het creëren van hypermedia-driven Web API’s. De combinatie van REST als architecturale stijl met de Linked Data principes biedt mogelijkheden aan om in het “Web of machines” vooruitgang te boeken net zoals dat gebeurde door hypertext bij het menselijke web. De meeste bouwblokken hiervoor bestaan al maar worden zelden samen gebruikt. Hydra probeert om via het verrijken van data met machine-interpreteerbare voorzieningen die interactie mogelijk maken dat gat op te vullen. Door het specificeren van bepaalde concepten die vaak gebruikt worden in Web API’s zorgt Hydra ervoor dat het mogelijk is om generieke clients te maken. Generieke clients zijn clients die meerdere specificaties of hypermedia bouwblokken begrijpen, waardoor ze in API’s met generieke stukken code zelf hun weg kunnen vinden. Deze bouwblokken moeten dan zo goed mogelijk beschreven worden, zodat ze door zoveel mogelijk generieke clients kunnen worden gebruikt.
Het gebruik van Hydra als aanvulling op LDP applicaties
In de paper “Describing Linked Data Platform Applications with the Hydra Core Vocabula-ry” [19] wordt een aanpak naar voren geschoven waarbij er in LDP (Linked Data Platform) applicaties aanvullend gebruik zou kunnen worden gemaakt van de Hydra Core Vocabulary. Via Hydra kan een LDP applicatie generieke clients mogelijk maken door het beschrijven van de betekenis van de verwachte en teruggegeven data.
Wat wordt er bedoeld met LDP applicaties? Zoals eerder vermeld beschrijven Linked Data principes een verzameling van best practices voor het publiceren en koppelen van gestructureerde data op het web. De LDP specificatie voorziet een standaard protocol en een verzameling van best practices voor het ontwikkelen van lees- en schrijfbare Linked Data gebaseerd op HTTP toegang tot web resources die hun staat beschrijven gebruik makend van het RDF data model. LDP applicaties maken gebruik van HTTP headers om informatie te verschaffen over wat ze opleveren, zo is er bijvoorbeeld de Allow header die oplijst welke HTTP operaties toegestaan zijn. Het
2.4. HYPERMEDIA 33
probleem hierbij is dat wanneer er generieke RDF types (bv. text/turtle, application/ld+json) gebruikt worden, een client geen informatie kan vinden over applicatie-specifieke structurele beperkingen of waardebeperkingen. Hier kan Hydra een oplossing zijn, door een woordenschat aan te bieden om informatie over de data te verschaffen die uitgebreider is dan wat mogelijk is met headers.
Activity Streams
De Activity Streams specificatie [20] is een specificatie voor activity stream protocols. Activity stream protocols worden gebruikt om activiteiten die ondernomen worden op bepaalde sites of applicaties samen te brengen (bv. activiteiten op de tijdlijn van Facebook). Een activiteit is een semantische beschrijving van een actie. De bedoeling van de specificatie is om een op JSON-gebaseerde syntax aan te bieden die voldoende is om metadata over activiteiten uit te drukken op een uitgebreide zowel menselijk leesbare als machine verwerkbare manier.
Activity streams kunnen worden geserialiseerd volgens JSON-LD en maken gebruik van de Acti-vity Vocabulary om de activiteiten te beschrijven. In Listing 2.8 is een voorbeeld van een simpele activity stream te vinden.
1 {
2 "@context": "https://www.w3.org/ns/activitystreams",
3 "summary": "Martin added an article to his blog",
4 "type": "Add",
5 "published": "2015-02-10T15:04:55Z",
6 "actor": {
7 "type": "Person",
8 "id": "http://www.test.example/Martin",
9 "name": "Martin Smith",
10 "url": "http://example.org/martin", 11 "image": { 12 "type": "Link", 13 "href": "http://example.org/martin/image.jpg", 14 "mediaType": "image/jpeg" 15 } 16 }, 17 "object": { 18 "id": "http://www.test.example/blog/abc123/xyz", 19 "type": "Article", 20 "url": "http://example.org/blog/2011/02/entry",
22 },
23 ...
24 }
Listing 2.8: Codevoorbeeld van een activity stream
Listing 2.8 beschrijft een activiteit waarbij Martin een artikel toevoegt aan zijn blog. De vo-cabulary binnen de namespace https://www.w3.org/TR/activitystreams wordt gebruikt. Zo wordt bijvoorbeeld aangegeven dat de actor een Person is met de name Martin Smith.
DCAT-AP
De Data Catalog Vocabulary (DCAT) [21] is een RDF vocabulary voor het beschrijven van data catagoli met als doel om interoperabiliteit tussen verschillende data catalogi die gepubliceerd staan op het web te vergemakkelijken. Een data catalogus is een verzameling van metadata gecombineerd met data management en zoektools die niet alleen helpt met het vinden van bepaalde data maar de data ook kan evalueren om de gepastheid van de data te bepalen voor het gewenste doel.
3
Hydra:search
Een belangrijk veld in de metadata van datasets met tiles die door Planner.js worden gebruikt is hydra:search. Dit veld bevat de search template voor de URI waarmee pagina’s in de dataset kunnen worden gevonden. In Listing 3.1 wordt de search template weergegeven.
1 { 2 "hydra:search": { 3 "@type": "hydra:IriTemplate", 4 "hydra:template": "https://tiles.openplanner.team/planet/14/{x}/{y}", 5 "hydra:variableRepresentation": "hydra:basicRepresentation", 6 "hydra:mapping": [ 7 { 8 "@type": "hydra:IriTemplateMapping", 9 "hydra:variable": "x", 10 "hydra:property": "tiles:longitudeTile", 11 "hydra:required": "true" 12 }, 13 { 14 "@type": "hydra:IriTemplateMapping", 15 "hydra:variable": "y", 16 "hydra:property": "tiles:latitudeTile", 35
17 "hydra:required": "true" 18 } 19 ] 20 } 21 } Listing 3.1: hydra:search
3.1 Nadelen en oplossing bij hydra:search
In deze search form wordt bijna uitsluitend gebruik gemaakt van de Hydra Vocabulary. Het veld hydra:template geeft de template van de toegangs-URL aan om een bepaalde tile op te halen. Drie variabelen zijn daarbij belangrijk, waarvan momenteel één hardgecodeerd staat. De 14 staat voor het zoom level. Dit zoom level kan een maximale waarde hebben van 14 waarbij de betref-fende tile dan het kleinste grondoppervlak overspant. Het laagste zoom level (0) omhelst de hele wereld. De variabelen x en y zijn van het type: tiles:longitudeTile en tiles:latitudeTile die gedefinieerd worden door de OSM (Open Streetmap) conventie van Slippy map tilena-mes en staan respectievelijk voor de horizontale en verticale positie van de tiles in de ras-terstructuur waarin ze worden geordend. Het zoom level en de velden tiles:longitudeTile en tiles:latitudeTile vormen samen de tilecoördinaten of tilenummers. Welke zoom levels er zijn en dus welke tiles er bestaan is afhankelijk van de gebruikte tile server of implementatie. Het is niet wenselijk dat iedereen die de search template wil kunnen invullen om data te verkrijgen voor bepaalde WGS84-coördinaten weet moet hebben van welke specifieke implementatie van de Slippy Tiles gebruik werd gemaakt in de benodigde datasets.
Er zijn twee mogelijke manieren om dit probleem aan te pakken:
• Conversiefuncties voorzien die WGS84-coördinaten omzetten naar de benodigde tilecoör-dinaten
• Een andere structurering van de dataset gebruik makend van de TREE-specificatie om zo de search template overbodig te maken
3.1. NADELEN EN OPLOSSING BIJ HYDRA:SEARCH 37
3.1.1 Conversiefuncties via de Function Ontology en de Function Hub
Om de routable tiles herbruikbaar te maken is het niet wenselijk dat wie deze data wil gebruiken telkens opnieuw een eigen implementatie van conversiefuncties moet uitvoeren om dit mogelijk te maken. Een eerste mogelijke oplossing om de herbruikbaarheid te verhogen is door gebruik te maken van de Function Ontology en de Function Hub. De Function ontology [22] is een manier om functies semantisch te beschrijven: wat doet een functie, welke parameters verwacht de functie en wat geeft hij terug. Het gaat hier over een pure beschrijving die los staat van een effectieve implementatie. De Function Hub kan gezien worden als een soort van pakketbeheerder voor functies in eender welke programmeertaal (zoals npm een pakketbeheerder is voor Javascript). De Function Hub kan dan voor de in de Function Ontology beschreven functies implementaties van conversiefuncties voor verschillende programmeertalen opnemen zodat developers die gebruik willen maken van routable tiles dan de correcte conversiefunctie kunnen gebruiken. Op die manier hoeft er geen eigen implementatie te gebeuren. Het gebruik van de Function Ontology en de Function Hub verhoogt de standaardisatie en dus ook de herbruikbaarheid. In deze masterproef wordt hier niet verder op ingegaan.
3.1.2 TREE-specificatie
Een tweede mogelijke manier om de search form weg te kunnen laten, is door het herstruc-tureren van de dataset. Om dit te verwezenlijken werd gekeken in de richting van de TREE-specificatie [23]. Gebruik makend van deze TREE-specificatie wordt de search form weggelaten, wat als voordeel heeft dat developers die een client willen ontwikkelen geen eigen implementatie van de Slippy Tiles [24] meer moeten maken aangezien hun client enkel het correcte pad in de datastruc-tuur moet volgen. In tegenstelling tot wat de naam van deze specificatie zou doen vermoeden, slaat de term tree niet noodzakelijk op een boomstructuur. Verder in deze scriptie wordt de term tree dan ook gebruikt om de geïmplementeerde gelinkte datastructuren te benoemen. Een eventueel nadeel van deze specificatie zou kunnen zijn dat clients vele links moeten volgen als de tile die ze nodig hebben diep in de tree ligt.
De TREE-specificatie is een hypermedia specificatie die de Linked Data principes volgt en als doel heeft om autonome query agents mogelijk te maken. Met autonome query agents worden clients bedoeld die op een autonome manier begrijpen wat er zich in een bepaalde knoop van de tree bevindt en zich op een autonome manier door de tree kunnen begeven tot ze de gewenste informatie bereiken. Dat clients op hun weg bepaalde paden kunnen schrappen (prunen) doordat uit de beschrijving duidelijk wordt dat de data langs dit pad onnodig zijn voor een bepaalde query is een extra voordeel van deze specificatie. In deze masterproef wordt het gebruik van de TREE-specificatie als oplossing verder uitgewerkt.
3.2
Wegwerken van hydra:search via de TREE-specificatie
In deze sectie wordt de tweede manier die eerder voorgesteld werd verder uitgewerkt. Twee verschillende aanpakken op basis van de TREE-specificatie werden geïmplementeerd.
Een tile (bereikbaar via een toegangs-URL, bv. https://tiles.openplanner.team/planet-/14/8361/5481) bestaat uit verschillende osm:Node’s. Een osm:Node is niet meer dan een punt op de kaart die beschreven is door zijn longitude en latitude (lengte- en breedtegraad), zijn ID en eventueel aanvullende tags die er extra informatie over geven. Nodes maken deel uit van wegen of pleinen en vormen dan samen het pad van de wegen of de vorm van de pleinen.
In wat hieronder volgt, wordt er veel gebruik gemaakt van de term knoop/ node die twee heel verschillende betekenissen kan hebben. Een tree knoop of tree:Node is een knoop binnen een tree structuur waarin de data worden voorgesteld. Een node (osm:Node) stelt een datum voor in deze dataset en is niet meer dan een bepaald punt op de kaart. Wanneer het over welke soort knoop/ node gaat zou normaal duidelijk moeten worden uit de context.
Aangezien de search form template niet interessant is om door verschillende agents gebruikt te worden zou het wenselijk zijn om deze uit de datastructuur weg te laten. Een mogelijke oplossing hiervoor is het overschakelen op een gelinkte datastructuur waarbij binnen een dataset die tiles bevat deze tiles aan elkaar gelinkt worden. Een eerste aanpak was het introduceren van nieuwe relaties die betrekking hebben op de longitude en latitude van de nodes in de tiles. Een codesnippet is terug te vinden in Listing 3.2.
1 <https://example.treeGeoRelations> a tree:Collection ; 2 tree:view <firsttile.txt> ; 3 tree:member <http://www.openstreetmap.org/node/145789>, <http://www.openstreetmap.org/node/145790>, <http://www.openstreetmap.org/node/145791>, <http://www.openstreetmap.org/node/145792> . ,→ ,→ ,→ 4 5 <firsttile.txt> a tree:Node ; 6 tree:remainingItems 8 ; 7 tree:relation <#LatitudeGreaterThanRelation> , <#LongitudeGreaterThanRelation> . ,→ 8 9 <#LatitudeGreaterThanRelation> a tree:GreaterThanRelation ; 10 tree:path geo:lat ; 11 tree:value "51.0539305"^^xsd:decimal ; 12 tree:node <secondtile.txt> . 13
3.2. WEGWERKEN VAN HYDRA:SEARCH VIA DE TREE-SPECIFICATIE 39
14 <#LongitudeGreaterThanRelation> a tree:GreaterThanRelation ;
15 tree:path geo:long ;
16 tree:value "3.7308872"^^xsd:decimal ;
17 tree:node <secondtile.txt> .
Listing 3.2: Tree structuur op basis van relaties m.b.t. de longitude en latitude van nodes
Het voorbeeld hierboven stelt een tile voor die in een gelinkte datastructuur zit. Aangezien een tile een verzameling van nodes is, wordt de tree gedefinieerd als een collectie van die nodes. Het veld tree:view geeft de toegangs-URL aan die het begin van de datastructuur aanduidt en heeft in dit geval <firsttile.txt> als waarde. Het veld tree:member geeft de objecten aan die in deze knoop (deze tile) zitten.
Eén of meerdere relaties met een volgende knoop in de datastructuur worden aangegeven door het predicaat tree:relation. In dit codevoorbeeld worden de relaties LatitudeGreaterThan-Relation en LongitudeGreaterThanLatitudeGreaterThan-Relation geïntroduceerd die aangeven dat de nodes in de volgende tile waarden hebben voor hun longitude en latitude die groter zijn dan een bepaalde waarde. Het veld tree:path geeft telkens aan voor welke attributen de relaties gelden en in tree:value staat dan de corresponderende waarde om mee te vergelijken. Op die manier kan een agent zich een weg banen door de datastructuur.
Deze aanpak heeft toch zijn nadelen. In de eerste plaats zouden te veel verschillende nieuwe relaties geïntroduceerd moeten worden, want wat met bijvoorbeeld tiles die nodes bevatten die wel een grotere latitude hebben maar niet noodzakelijk een grotere longitude? Voor de verschillende buurtiles zouden verschillende combinaties van relaties moeten gebruikt worden.
Een tweede nadeel is dat deze relaties niet beschrijven welk gebied een volgende tile overspant, enkel wat de minimum waardes zijn voor de longitude en latitude van zijn nodes. Een betere aanpak zou kunnen beschrijven welk gebied een volgende tile precies overspant.
Een tweede aanpak die beide nadelen oplost en deze beschrijving voorziet maakt gebruik van WKT-strings. Een voorbeeld hiervan is te vinden in Listing 3.3.
1 <https://example.treeWKTstring> a tree:Collection ; 2 tree:view <firsttile.txt> ; 3 tree:member <http://www.openstreetmap.org/node/145789>, <http://www.openstreetmap.org/node/145790>, <http://www.openstreetmap.org/node/145791>, <http://www.openstreetmap.org/node/145792> . ,→ ,→ ,→ 4 5 <firsttile.txt> a tree:Node ;
6 tree:remainingItems 8 ; 7 tree:relation [ 8 a tree:GeospatiallyContainsRelation ; 9 tree:node <second.ttl> ; 10 tree:path geosparql:asWKT ; 11 tree:value "<http://www.opengis.net/def/crs/OGC/1.3/CRS84> POLYGON (( 3.75732421875 51.04139389812637, 3.75732421875 51.05520733858495, 3.7353515625 51.05520733858495, 3.7353515625 51.04139389812637, 3.75732421875 51.04139389812637 ))"^^geosparql:wktLiteral ,→ ,→ ,→ ,→ 12 ].
Listing 3.3: Tree structuur met WKT-strings
Als we de tile zelf bekijken kan er gezien worden dat vanuit deze knoop er 8 members kunnen bereikt worden, dit zijn de 4 die in deze knoop zitten en 4 andere die in andere kno(o)p(en) zitten. In plaats van de relaties LongitudeGreaterThanRelation en LatitudeGreaterThanRelation gaat hier om een tree:GeospatiallyContainsRelation die aangeeft welk gebied de knoop en dus de bijhorende tile die aan deze relatie hangt overspant. Zo kan een query agent zien of het interessant is om naar die volgende knoop over te gaan of niet. Het veld tree:path geeft aan dat er in dit geval moet gekeken worden naar het attribuut geosparql:asWKT. In tree:value staat dan de overeenkomstige waarde voor het attribuut. Deze waarde is aangegeven door middel van een WKT-string. WKT is een text markup language die het mogelijk maakt om vormen of punten in een tekstvorm weer te geven en werd oorspronkelijk gedefinieerd door het Open Geospatial Consortium (OGC).
Om bij het creëren van de datasets en het leggen van de relaties tussen de tiles over te gaan van de tilenummers in de toegangs-URL (x en y) naar een lengte- en breedtegraad (in WGS84-coördinaten) werd er gebruik gemaakt van specifieke conversiefuncties, volgens de Slippy tile-names conventie, die terug te vinden zijn in Listing 3.4. De getallen die in de WKT-string de polygon beschrijven die het gebied van de tile bevat, worden bekomen door de tilenummers telkens met deze functies te converteren. De tilenummers die in de toegangs-URL staan kunnen gebruikt worden voor de lengte- en breedtegraad van de linkerbovenhoek van de tile. Om de vier hoekpunten van een tile te weten te komen moet er dus gekeken worden naar de tilenummers van de tile zelf en die van de tile die rechtsonder de huidige tile in de rasterstructuur ligt (want zijn linkerbovenhoek is de rechteronderhoek van de huidige tile), deze zijn voldoende aangezien het om vierkanten gaat.
1 function tile_to_lat(y_tile: number) {
3.2. WEGWERKEN VAN HYDRA:SEARCH VIA DE TREE-SPECIFICATIE 41
3 const n = Math.PI - 2 * Math.PI * y_tile / Math.pow(2, 14);
4 return (180 / Math.PI * Math.atan(0.5 * (Math.exp(n) - Math.exp(-n))));
5 }
6
7 function tile_to_long(x_tile: number) {
8 // from https://wiki.openstreetmap.org/wiki/Slippy_map_tilenames
9 return (x_tile / Math.pow(2, 14) * 360 - 180);
10 }
Listing 3.4: Specifieke conversiefuncties voor het converteren van tilenummers naar WGS84-coördinaten
Het gebruik van tree:GeospatiallyContainsRelation relaties om links te leggen tussen ver-schillende tiles wordt verder uitgewerkt in Hoofdstuk 5.
4
Preprocessed routable tiles
4.1
Data vereisten
Eerder in deze masterproef werd er al verwezen naar de Routable Tiles specificatie. Gebruik makend van deze specificatie werd de Routable Tiles dataset bekomen, die een hergestructureerde versie is van het OpenStreetMap wegennetwerk. De omzetting met de Routable Tiles specificatie leidt tot het opdelen van de OpenStreetMap data in kleinere fragmenten die ervoor zorgen dat routeplanning mogelijk wordt client-side op een manier die een trade-off is tussen data dumps en RPC-API’s (zie subsectie 2.2.2). Doordat de data Linked Data zijn kunnen ze ook gebruikt worden voor andere doeleinden, zoals bijvoorbeeld het linken van IoT (Internet Of Things) data aan deze data.
De Routable Tiles dataset kan door gelijk wie gebruikt worden om een routeplanning query op te lossen zonder dat het nodig is om gebruik te maken van een gecentraliseerde routeplanning service.
Toch blijkt er zich in de praktijk een probleem voor te doen. Door de omvang van het wegen-netwerk is het mogelijk dat wanneer er aan routeplanning gedaan wordt tussen punten die op bijvoorbeeld 100 km van elkaar liggen, de benodigde (niet gecomprimeerde) data al snel enke-le gigabytes groot zijn. Om dit probenke-leem op te lossen kunnen de routabenke-le tienke-les gepreprocessed
4.2. MOGELIJKE VORMEN VAN PREPROCESSING 43
worden zodat een client selectiever kan zijn in de beslissing welke data het zal verwerken.
4.2
Mogelijke vormen van preprocessing
Voor het preprocessen van routable tiles werden er enkele transformatiescripts geschreven. Op dit moment kunnen de soorten transformaties opgedeeld worden in drie categorieën:
• Profile-based: Bij deze vorm van preprocessing wordt een vervoersmiddel gekozen die gede-finieerd is in de Open Planner Team’s vocabulary voor vervoersmiddelprofielen. Op basis van dit vervoersmiddel worden dan alle nodes en wegen waar het vervoersmiddel geen toegang toe heeft, weggelaten uit de routable tiles. Een voorbeeld: bij het kiezen van een auto als vervoersmiddel zullen de wegen of paden waar een auto geen toegang toe heeft, weggelaten worden (bijvoorbeeld wegen of paden specifiek voor fietsers). Daarnaast wor-den ook alle tags die niet gebruikt worwor-den voor dat profiel weggelaten, zoals bijvoorbeeld osm:cycleway tags voor bovenstaand voorbeeld.
• Transit-based: Bij deze vorm van preprocessing worden enkel de nodes en wegen behou-den die het mogelijk maken om je door de tile heen te bewegen. Zo zullen bijvoorbeeld doodlopende straten of lokale wijken binnen de tile weggelaten worden.
• Contraction-based: Niet alle nodes op een weg zijn relevant voor routeplanning. Sommige dienen enkel voor visualisatie zoals bijvoorbeeld het beschrijven van de kromming van een weg. Bij deze laatste vorm van preprocessing worden zulke soort nodes dan ook weggelaten. Dit is mogelijk zolang de afstanden tussen de overblijvende nodes worden beschreven.
Het oppervlak die een preprocessed tile beschrijft, blijft identiek aan die van de originele routable tile. Enkel de data binnen dit oppervlak zullen gereduceerd zijn. Natuurlijk zijn ook samengestel-de transformaties mogelijk. Zo is het bijvoorbeeld mogelijk om car profile-based transit tiles (zie sectie 5.1) te maken, die enkel de nodes en wegen toegankelijk voor auto’s behouden waarmee het mogelijk is om doorheen een tile te gaan.
5
Transit tiles
5.1
Preprocessing in deze masterproef
Binnen het bestek van deze masterproef is de transit-based transformatie de belangrijkste en wordt daarom hier verder uitgewerkt. Tiles die bekomen worden door op routable tiles een transit-based transformatie uit te voeren worden transit tiles genoemd.
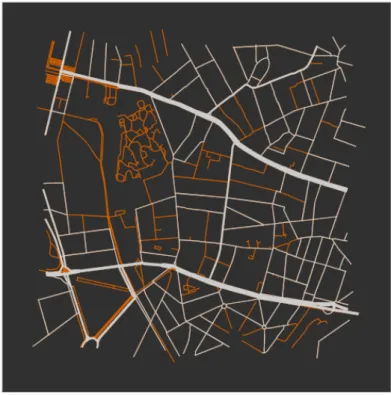
Zoals eerder aangegeven zijn transit tiles heel gelijkaardig aan de gewone routable tiles en be-vatten ze ook osm:Node’s die wegen (osm:Way’s) vormen. Figuur 5.1 illustreert hoe bepaalde nodes en wegen uit de data worden weggelaten. In deze figuur is er te zien dat de oranje wegen overbodig zijn wanneer er door de tile heen moet gegaan worden en worden bijgevolg enkel de witte wegen behouden na de transformatie. Zo wordt in deze figuur ook het wegennetwerk van ZOO Antwerpen weggelaten (linksboven het midden van de figuur).
Het effect van het weglaten van onnodige wegen wordt groter naarmate het zoom level lager en dus het bestreken oppervlak van de tile groter wordt.

![Figuur 2.3 [12] maakt de vergelijking tussen beide manieren.](https://thumb-eu.123doks.com/thumbv2/5doknet/3292153.22050/23.892.143.745.623.788/figuur-maakt-vergelijking-tussen-beide-manieren.webp)