opslag van herkomstinformatie
Analyse van op blockchain gebaseerde software ter
Academiejaar 2019-2020
Master of Science in de industriële wetenschappen: informatica Masterproef ingediend tot het behalen van de academische graad van
Begeleider: Sven Lieber
Promotoren: Ben De Meester, prof. dr. ir. Ruben Verborgh
Studentennummer: 01807490
In 2018 had ik de keuze gemaakt om van de opleiding toegepaste informatica te schakelen naar de Master of Science in de industri¨ele wetenschappen: informatica. Met trots kan ik zeggen dat deze masterproef het sluitstuk vormt op mijn vijfjarig traject. Al reeds enkele jaren bezit ik een grote interesse voor de blockchain wereld. Echter ben ik hier tijdens mijn opleiding weinig mee in aanraking geweest. Om die reden was de keuze snel gemaakt toen dit interessante onderwerp mij werd voorgesteld. De combinatie van twee boeiende technologie¨en vormde voor mij een perfect domein om mij verder in te verdiepen.
Hiervoor wil ik mijn promotor Ben De Meester en begeleider Sven Lieber beiden enorm bedanken. Zij hebben tijdens het verloop van mijn masterproef mij steeds in elk aspect ondersteund. Wekelijks hebben zij mij van constructieve feedback voorzien. Daarbij hielpen zij mij deze masterproef vormen tot wat het is geworden.
Daarnaast wil ik ook graag mijn vrienden, mede-studenten en ouders bedanken voor hun steun en aangename momenten die zij mij de voorbije jaren bezorgden.
Deze masterproef werd geschreven tijdens de coronapandemie van 2020. Hierbij wil ik graag de Universiteit Gent bedanken voor hun correcte maatregelen die zij troffen tijdens deze periode. De invloed van deze crisis op mijn masterproef bleef daardoor vrij beperkt.
Michiel Glibert Gent 15 juni 2020
provenance
Michiel Glibert
Supervisor(s): prof. dr. ir. Ruben Verborgh, Ben De Meester, Sven Lieber
Abstract—This article proposes an implementation of a system to store provenance information on a blockchain for which an extensive analysis of blockchain-based software was performed. Provenance is metadata which can be used to form assessments about the quality, reliability or trustwor-thiness of data [1]. Storing this provenance data in a blockchain can serve as an immutable storage which can secure the provenance against forgery. If non-provenance or malformed provenance data is also allowed on the blockchain, this doesn’t only hurt the trustworthiness of such a blockchain but also causes it to be less scalable. To address this issue, a validation mech-anism was made that validates all incoming data and, if required, blocks it from being added to the blockchain. For this validation mechanism to have a positive effect, all nodes that are part of the network and validate the data, the validators, should use the exact same validation rules. This requires an incentive for the validators to use the correct implementation as specified by the majority of the blockchain network. By using Tendermint [2], a Byzan-tine Fault Tolerant [3] consensus engine, a proof of concept was created that not only stores validated provenance data in a blockchain but also creates an incentive that is based on a credibility score for good behaviour and pun-ishment for bad behaviour. Although this article already shows a possible implementation, flaws are still present and further research can shed light upon these shortcomings.
Keywords—Blockchain, Provenance Data, RDF data, Tendermint
I. INTRODUCTION
Blockchain is a recent technology that was introduced by Satoshi Nakamoto with Bitcoin, a peer-to-peer electronic cash system [4] (also called a cryptocurrency). This technology pro-posed a peer-to-peer network using proof-of-work to record a public history of transactions that quickly becomes com-putationally impractical for an attacker to change if honest nodes control a majority of CPU power [4]. Because of this, blockchain serves as an immutable ledger which allows transac-tions take place in a decentralized manner [5]. This technology is not limited to electronic cash systems, but can be expanded further towards other uses like immutable data storage [6].
Provenance on the other hand is information about entities, activities, and people involved in producing a piece of data or thing, which can be used to form assessments about its quality, reliability or trustworthiness [1]. This provenance is part of the semantic web framework. The idea behind the Semantic Web is “to weave a Web that not only links documents to each other but also recognizes the meaning of the information in those docu-ments” [7]. We are living in a data-driven world where this data can undergo multiple transformations, causing it to only resem-ble a fraction of the original data. These transformations cause the data to lose it’s original quality and trustworthiness, eventu-ally leading to data that is less reliable for a data scientist. By using provenance, this effect is mitigated and the data still keeps most of it’s original properties.
But like many things, provenance can be forged by a mali-cious person. By forging the provenance in a way that it gives false qualities to the data, it can cause false data to look
trust-Fig. 1
THE PROVENANCE DATA BLOCKCHAIN STORES PROVENANCE INFORMATION.
worthy. Besides forgery, a central authority that stores this data and it’s provenance also has a large impact on the quality and trustworthiness of the data. As N. Prat and S. Madnick. [8] mention it: From the definition of believability, it is clear that the believability of a data value depends on its origin (sources) and subsequent processing history. The central authority that stores the data and provenance can be seen as a part of the pro-cessing history. Creating a blockchain that stores provenance data instead of electronic cash transactions could solve this is-sue and provide a decentralized manner of storing provenance data while being immutable. This concept is vissualy shown on figure 1.
This decentralization and immutability is not hard to achieve as the electronic cash transactions can simply be replaced with transactions that contain provenance data. The question is rather can such a blockchain be trusted and does it still provide the quality that provenance should give to data in the first place? By validating any incoming data before it is added to the im-mutable blockchain it is possible to block any transactions that contain malformed data. Validation is clearly a step in the right direction, but who should execute this validation? As a client can not be trusted, it is important that the nodes that form the blockchain network, the so-called validators, validate all incom-ing transactions. But the question remains; how can an incentive be created to enforce such a validation system for the validators? As this provenance data blockchain does not contain any finan-cial transactions or rewards, it is hard to obligate validators to use a correct validation system. An incentive is needed to not only reward good behaviour but also punish bad behaviour and therefore discourage the use of false validation systems.
Fig. 2
THE ARCHITECTURE OF A PROVENANCE DATA BLOCKCHAIN CONSISTS OF FOUR LAYERS WHICH CAN ONLY INTERACT WITH THE LAYER BENEATH OR
ABOVE THEM.
The architecture of the provenance data blockchain consists out of multiple layers as seen on figure 2. When taking a bottom-up approach, the first layer is the blockchain layer. This contains all the data of the actual blockchain.
The second layer is the blockchain consensus layer. This layer handles all the communication between nodes that are part of the blockchain network and makes sure that after each transaction all the nodes come to an agreement. This is also the layer where all transaction are handled and added to the blockchain.
The third layer is the blockchain interface layer. The purpose of this layer is to allow communication with the blockchain. Be-cause of this it is possible to execute actions on the blockchains to send and read transactions.
Finally the fourth and last layer is the application layer. This layer can be split up in two sub-layers. One sub-layer is used for front-end interaction for the users of the blockchain network, while the other sub-layer is used to process transactions on a node of the network. To make this more clear, the front-end application is only usable for users that want to send and read transaction. The blockchain application is only usable by nodes that listen or contribute to the blockchain network.
Each of these layers communicate with the layer beneath or above them. This means that the application layer does not di-rectly communicate with the blockchain layer.
III. IMPLEMENTATION
Based on this architecture, two implementations were made. The first one served as an initial implementation that had some expected flaws, but served very well to point out the need for a validation system even more. The second implementation cor-rected the flaws of the first implementation and therefore pos-sesses the validation system as discussed in the introduction. A. Initial implementation
The first implementation used the BigchainDB [6] technol-ogy combined with PROV Python [9], a technoltechnol-ogy provided by Open Provenance [10]. This implementation had minimal vali-dation as everything was situated on the front-end. As expected,
built on top of Tendermint, it works with so-called assets and is not well suited for file storage. Testing on this implementation also proved that our provenance data blockchain grew a lot faster than a cryptocurrency blockchain. Therefore it was even more important to implement a validation mechanism as this could stop so-called bad data from being added to the blockchain. This bad data can be viewed as data that does not follow the validation rules known in the blockchain network, for example bad formatted provenance data or duplicate data. This bad data does not serve any purpose and causes the size of the blockchain to be larger than it should be.
B. Improved implementation
The second and improved implementation solved the flaws the first one had. This implementation was based on Tendermint [2] as it gave more freedom for development than BigchainDB did. A validation system was implemented that blocked bad data from coming onto the network, but to promote using this system and it’s associated validation rules, it was important to create an incentive for this which was based on the way that Ethereum Casper [11] works. This is done by rewarding good behaviour, which means using the correct validation system, and punish-ing bad behaviour, which means uspunish-ing a false or no validation system.
The so-called good validators get rewarded with a credibil-ity score. By having a higher credibilcredibil-ity score, these validators are allowed to add blocks to the network more frequently. This score is limited in a way that these good validators don’t have too much power in the network and because of that also give the chance for new validators to become a good and trusted valida-tor. If a trusted validator chooses to send bad data, it will lose all it’s score but still be allowed to be a part of the network. If the validator is not fully trusted, in other words, did not have the maximum amount of credibility score, it will be removed and banned from the network.
It is important to note that a correctly implemented and prop-erly configured validator can reject bad data. Therefore, cor-rectly implemented validators who send bad data to a blockchain do so on purpose.
IV. EVALUATION
To evaluate the developed provenance data blockchain, it was important to do this in a realistic environment. This was done by executing ten experiments in a Docker [12] environment that for each experiment had a network with ten to twenty valida-tors. Each of these experiments had a different scenario that ranged from having twenty good validators to having fifteen of the twenty validators be malicious. Both good and bad data was sent to the network to test the effect it would have. The results were always very positive, meaning that the network reacts as it should have. Sending good data got rewarded by giving these good validators a positive credibility score. Meanwhile, bad val-idators that sent data that did not comply to the validation rules that the majority of the network follows were punished and/or removed from the network.
validators got added to the network that is not able to withstand this attack and the network can get taken over by these bad val-idators. This switch from good to bad would not be noticed by the users and could cause data scientists to view forged prove-nance information as good proveprove-nance information because the blockchain was always known to be a trustworthy one.
V. CONCLUSION
With this system it can be concluded that a provenance data blockchain needs validation mechanisms that can stop bad data from being added to the blockchain. It seemed that simply us-ing a blockchain that can store data was not sufficient enough to store provenance data. Data can be formed in many possible ways and it is therefore important to exclude all the bad data from the blockchain. If not, the data blockchain will grow very fast and will contain a lot of data that is not useful. This un-dermines the principles that provenance tries to achieve: qual-ity, reliability and trustworthiness. It is important that users can also trust the blockchain itself. By showing the users that bad data is not allowed and validators are only kept in the network if their behaviour is good, the blockchain can keep the properties that the provenance intended in the first place. This gives the possibility to use such a system in practice.
VI. FUTURE WORK
As mentioned earlier, weaknesses of this system were also tested in the evaluation. It are these weaknesses that evoke the requirement of more research to be conducted on this topic. One of the biggest weaknesses that this system still has is the fact that validators can be added freely to the system. This means that a malicious person can simply add multiple validators, even if some of his validators were banned before. Possible ways to solve this is could be by using a Proof-of-Authority approach. In such an approach, a validator could only be added if personal information is provided to the network. This gives an extra in-centive to not have bad behaviour and can also detect if a person would have multiple validators. But then again it could be ar-gued that this is not an optimal solution as this data would have to be stored on the blockchain, meaning that someones personal information is stored permanently on a public medium.
In it’s current state, the system could be a good use in private environments. In a private environment it is expected that every validator uses the correct implementation with the correct val-idation rules as no unknown validators are allowed to join the network. The system will be used primarily to avoid human er-rors (bad data that gets send accidentally) and to automatically remove failing validators.
REFERENCES
[1] Yolanda Gil and Simon Miles. PROV Model Primer. W3C Note. W3C, Apr. 2013.URL:
http://www.w3.org/TR/2013/NOTE-prov-primer-20130430/.
[2] Tendermint Inc. Tendermint.URL: https://www.tendermint. com.
microsoft . com / en - us / research / publication / byzantine-generals-problem/.
[4] Nakamoto Satoshi. “Bitcoin: A Peer-to-Peer Electronic Cash System”. In: Cryptography Mailing list at https://metzdowd.com (Mar. 2009).
URL: https://bitcoin.org/bitcoin.pdf.
[5] Zibin Zheng et al. “An Overview of Blockchain Technology: Architecture, Consensus, and Future Trends”. In: June 2017.
DOI: 10 . 1109 / BigDataCongress . 2017 . 85. URL: https : / / www . researchgate . net / profile / Hong - Ning _ Dai / publication / 318131748 _ An _ Overview _ of _ Blockchain _ Technology _ Architecture _ Consensus _ and _ Future _ Trends / links/59d71faa458515db19c915a1/An- Overview- ofBlockchain Technology Architecture Consensus -and-Future-Trends.pdf.
[6] BigchainDB. “BigchainDB 2.0”. In: 2018. URL: https : / / www . bigchaindb . com / whitepaper / bigchaindb -whitepaper.pdf.
[7] G. Kuck. “Tim Berners-Lee’s Semantic Web”. In: South African Jour-nal of Information Management 6 (Dec. 2004). DOI: 10 . 4102 / sajim . v6i1 . 297.URL: https : / / www . researchgate . net / publication / 307845029 _ Tim _ Berners - Lee ’ s _ Semantic_Web.
[8] N. Prat and S. Madnick. “Measuring Data Believability: A Provenance Approach”. In: Proceedings of the 41st Annual Hawaii International Conference on System Sciences (HICSS 2008). 2008, pp. 393–393. [9] Trung Dong Huynh. PROV Python. URL: https : / / prov .
readthedocs.io/en/latest/.
[10] King’s College London. Provenance Web Services.URL: https:// openprovenance.org/.
[11] Vitalik Buterin and Virgil Griffith. “Casper the Friendly Finality Gad-get”. In: Accessed:2017-11-06. 2017.URL: https://arxiv.org/ pdf/1710.09437.pdf.
1 Inleiding 6
1.1 Situering . . . 6
1.1.1 Het semantisch web en gelinkte data . . . 6
1.1.2 Herkomstinformatie . . . 7
1.2 Probleemstelling . . . 8
1.3 Onderzoeksvraag . . . 10
1.4 Aanpak . . . 11
2 State of the art 12 2.1 Het Semantisch Web . . . 12
2.1.1 URI . . . 13 2.1.2 RDF . . . 13 2.1.3 Schema en ontologie¨en . . . 17 2.1.4 SPARQL . . . 20 2.1.5 SHACL . . . 20 2.2 Herkomstinformatie . . . 22 2.2.1 PROV-Ontology . . . 23 2.3 Blockchain . . . 25 2.3.1 Waarom blockchain? . . . 26 2.3.2 Hashfunctie . . . 26
2.3.3 Werking achter blockchain . . . 27
2.3.4 Transactie verloop doorheen het netwerk . . . 31
2.3.5 Base64 codering . . . 32
2.4 Herkomstinformatie in een blockchain . . . 33
2.4.1 Opslag van herkomstinformatie . . . 34
2.4.2 Compressie van herkomstinformatie . . . 36
2.4.3 Geschikte blockchain technologie¨en . . . 37
3 Vooronderzoek 43 3.1 Architectuur . . . 43 3.2 Gekozen technologie¨en . . . 44 3.2.1 BigchainDB . . . 45 3.2.2 Tendermint . . . 47 3.3 Implementatie . . . 50
3.3.1 Verloop van transacties . . . 50
3.3.2 Verdere opbouw . . . 51 3.4 Evaluatie . . . 51 3.4.1 Opzet . . . 52 3.4.2 Uitvoering . . . 53 3.4.3 Resultaten . . . 54 3.5 Discussie . . . 56 4 Onderzoek 58 4.1 Voorgestelde oplossing . . . 58 4.1.1 Validatie en geloofwaardigheid . . . 59
4.1.2 Verkrijgen en verliezen van geloofwaardigheidsscore . . . 60
4.1.3 Mogelijke scenario’s . . . 62 4.2 Verbeterde implementatie . . . 64 4.2.1 Architectuur . . . 64 4.2.2 Validatie . . . 65 4.2.3 Geloofwaardigheidsscore . . . 67 4.2.4 Functionaliteiten . . . 69
4.2.5 Beperkingen van Tendermint . . . 76
4.3 Evaluatie . . . 77 4.3.1 Opzet . . . 78 4.3.2 Uitvoering . . . 79 4.3.3 Resultaten . . . 80 5 Conclusie 86 5.1 Besluiten . . . 86 5.2 Toekomstig onderzoek . . . 89 Appendices 94 A SHACL regels 95 B Repositories 97 Bibliografie 98
1.1 Data met zijn bijhorende herkomstinformatie . . . 8
1.2 Een visuele voorstelling van de herkomstinformatie blockchain . . . 10
2.1 De technologie stack van het semantisch web [12] . . . 13
2.2 Een RDF triplet voorgesteld in een graaf . . . 14
2.3 Een voorbeeld van hoe een blanke knoop kan gebruikt worden . . . 15
2.4 Het PROV model gespecificeerd volgens W3C [8] . . . 22
2.5 Het PROV-O model gespecificeerd volgens W3C [18] . . . 24
2.6 Een grafiek met valse data over het blockchain gebruik . . . 24
2.7 De SHA-256 hashfunctie toegepast op twee licht verschillende invoeren. . . . 27
2.8 Een blockchain met in elke blok transacties . . . 30
2.9 Het verloop van een transactie bij Bitcoin . . . 32
2.10 De Base64 tabel [27] . . . 34
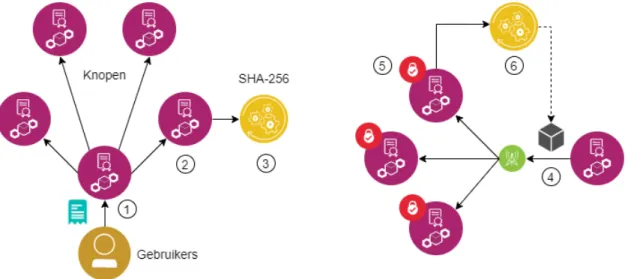
2.11 Een blockchain met semantische metadata [29] . . . 35
2.12 Een blockchain met RDF data [29] . . . 35
2.13 Een blockchain met een virtual RDF service [29] . . . 36
2.14 Een semantische blockchain [29] . . . 36
3.1 De architectuur van de herkomstinformatie blockchain die data opslaat. . . . 44
3.2 Een BigchainDB netwerk met vier knopen [21] . . . 46
3.3 Het aanmaken van een transactie met Tendermint. . . 48
3.4 Het proces van hoe Tendermint tot een consensus komt. . . 49
3.5 Een visuele voorstelling van de implementatie met de bijhorende technologie¨en 52 3.6 Het verloop van het experiment . . . 53
4.1 Meerdere blokketens met andere validatieregels . . . 60
4.2 De mogelijke scenario’s bij de voorgestelde oplossing . . . 63
4.3 Het model van de verbeterde implementatie met Tendermint . . . 65
4.4 Visuele voorstelling van experiment ´e´en . . . 80
4.5 Visuele voorstelling van experiment twee . . . 81
4.6 Visuele voorstelling van experiment drie . . . 82
4.7 Visuele voorstelling van experiment vier . . . 82
4.8 Visuele voorstelling van experiment vijf . . . 82
4.9 Visuele voorstelling van experiment zes . . . 83
4.10 Visuele voorstelling van experiment zeven . . . 84
4.11 Visuele voorstelling van experiment acht . . . 84
4.12 Visuele voorstelling van experiment negen . . . 85
2.1 Een voorbeeld van hoe Turtle eruit ziet waarbij het Game of Thrones universum
werd gebruikt . . . 15
2.2 Een voorbeeld van RDF Schema waarbij er gebruik wordt gemaakt van Vlaamse scholen . . . 18
2.3 Enkele planeten met hun ontdekkingsjaar volgens het Turtle formaat RDF . . 20
2.4 Een SPARQL query die de planeten toont die v`o`or 1930 gevonden zijn . . . . 20
2.5 RDF data . . . 21
2.6 SHACL regels . . . 21
2.7 Herkomstinformatie horend bij figuur 2.6 . . . 24
4.1 Transactie JSON object . . . 69
4.2 Herkomstinformatie . . . 70
4.3 Aangevuld JSON object die een transactie voorstelt . . . 70
4.4 De volledige URI die gebruikt kan worden om de transactie te verzenden . . . 70
4.5 De volledige URI om een query uit te voeren op het netwerk . . . 72
4.6 Een antwoord van Tendermint voor een goed verstuurde transactie . . . 72
4.7 Een antwoord van Tendermint voor een gevonden sleutel . . . 73
A.1 De gebruikte SHACL regels in de implementatie van hoofdstuk 4 . . . 95
De dag van vandaag zijn er grote hoeveelheden data in omloop. Deze data wordt voor vele doeleinden gebruikt gaande van medische tot commerci¨ele toepassingen. Een belangrijk onderdeel van deze data, dat zeker niet vergeten mag worden, is de kwaliteit en interpretatie ervan. De data moet een duidelijke betekenis hebben en zijn oorsprong moet ook geweten zijn [1]. Daarnaast moet ervoor gezorgd worden dat deze oorsprong niet zomaar vervalst kan worden. Dit blijkt echter een grotere uitdaging dan het lijkt.
1.1
Situering
1.1.1 Het semantisch web en gelinkte data
Het wereldwijde web wordt gebruikt om continu informatie uit te wisselen. Deze informatie wordt door mensen ge¨ınterpreteerd en heeft voor hen een duidelijke betekenis. Echter heeft die data zelf, voor computers, geen betekenis aangezien deze voor menselijke consumptie bedoeld is [2]. Een goed voorbeeld hiervan is als er een opzoeking wordt gedaan met een zoekmachine. Stel er wordt een zoekopdracht uitgevoerd met de zoekterm “apple”. Hierbij kunnen minstens twee resultaten voorkomen waarvan hun uiteindelijke betekenis verschilt. Het bedrijf Apple en het Engelstalige woord voor appel. Er wordt geen extra betekenis toegevoegd aan het woord apple en de zoekmachine zal op zoek gaan naar alles wat een apple zou kunnen voorstellen. Zou er extra informatie worden gespecificeerd bij de zoekterm, bijvoorbeeld dat apple een stuk fruit moet voorstellen, dan weet de computer beter hoe dit moet worden ge¨ınterpreteerd. Zo zullen de zoekresultaten bestaan uit het fruit, niet het bedrijf of andere termen die een “apple” voorstellen. Betekenis geven aan deze data wil ook wel zeggen: semantiek (semantics) toevoegen aan informatie. Op deze manier wordt het wereldwijde web (WWW) uitgebreid tot het semantisch web [3].
Naast het feit dat er aan de data een betekenis wordt gegeven, is het ook belangrijk om de data met elkaar te verbinden, te linken. Dit principe wordt gelinkte data [4] genoemd. Bij gelinkte data wordt er aan data verwijzingen toegevoegd die naar andere data refereert
om zo meer informatie te verschaffen over specifieke eigenschappen van deze data. Stel dat er een data object van Belgi¨e is waaruit kan worden afgeleid dat de hoofdstad van Belgi¨e, Brussel is. Zou de dataset gebruik maken van de principes van gelinkte data, dan zou er een link kunnen zijn naar het data object van Brussel in dat van Belgi¨e waardoor er meer informatie kan worden teruggevonden over de stad Brussel. Gelinkte data komt neer op een verzameling van best practices om structuur aan data te geven waardoor de data meer kan hergebruikt worden [4]. Daarnaast geeft dit ook de mogelijkheid aan machines om deze structuren te gaan interpreteren en verwerken. Dit in tegenstelling tot het scrapen van web pagina’s dat veel tijd in beslag neemt en het aanvragen van data via specifiek ontwikkelde web API’s die veranderen naargelang de tijd. Deze gelinkte data wordt beschreven door het Resource Description Framework [5]. Dat is een belangrijk framework binnen het semantisch web gebruikt om de eigenschappen, de betekenis van data te beschrijven.
1.1.2 Herkomstinformatie
Data kan niet alleen achter gesloten deuren worden gehouden maar kan ook vrij beschikbaar zijn. Dit wordt open data [6] genoemd. Een groot voordeel aan een open data ecosysteem is dat deze data door iedereen bruikbaar en deelbaar is [6]. Dit zorgt ervoor dat gebruikers snel data kunnen vinden en consumeren naar eigen noden. Beschikbare data kan gebruikt worden als invoer data voor een functie, een transformatie. Deze invoer data wordt dan getransformeerd naar uitvoer data die bruikbaar is voor verdere use cases. Zo een functie kan gaan van een zeer eenvoudige functie zoals het berekenen van de minima of maxima, tot meer complexe zoals een regressie analyse.
Door het gebruik van complexe functies op de data kan er soms niet meer de link worden gelegd met de originele data waardoor het vertrouwen in de resulterende data verminderd. Denk maar aan het belang dat wordt gehecht bij het naleven van de privacy wetgeving indien gevoelige data openbaar wordt gesteld [7]. Zo is het mogelijk dat voor een bepaalde use case de data moet getransformeerd worden naar geanonimiseerde data waardoor de oorspronkelijke data er niet meer uit af te leiden is. Het uiteindelijke resultaat van analyses op de data blijft uiteraard wel behouden. Dit transformeren van invoer naar uitvoer is een proces dat zich kan blijven herhalen waardoor vertrouwen in data kan verloren gaan en de kwaliteit ervan niet meer kan worden gemeten.
Dit geeft aanleiding tot een duidelijk nadeel van deze gelinkte data filosofie. Immers, van waar is onze data afkomstig? Wat was de initi¨ele data die verzamelt werd? Door wie? Hoe? Hoe kunnen we dan zeker zijn over de correctheid van de gegevens? Hoe meten we uiteindelijk de kwaliteit? Het kan daarom nuttig zijn om gegevens bij te houden die vorige vragen beantwoorden. Er is baat bij om een historiek bij te houden van de data zelf, een soort logboek van alles wat met de data gebeurt. Wie of wat heeft het gebruikt, wat werd ermee
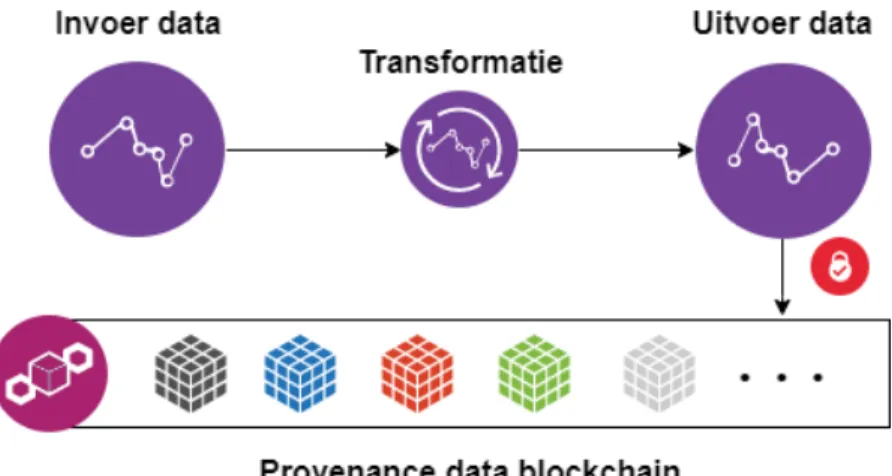
gedaan, wat was het resultaat, ... Dit is meta informatie, gegevens die de karakteristieken van bepaalde gegevens beschrijven, die naast de data zelf moet worden opgeslagen. Dit principe is te zien op figuur 1.1. Dit concept noemt herkomstinformatie, provenance data [8] genoemd in het Engels. Dit is een goede maatstaf voor de oorsprong van de data, de data origin, te weten te komen. Met het concept van het semantisch web en gelinkte data kunnen we deze herkomstinformatie op een zeer interessante manier gaan voorstellen. Daardoor is de informatie niet enkel nuttig voor mensen maar ook voor machines.
Figuur 1.1: Data met zijn bijhorende herkomstinformatie
1.2
Probleemstelling
Herkomstinformatie vermeldt van waar de data afkomstig is en wat er allemaal mee gebeurd is [8]. Het is een beschrijving van het gehele proces hoe er tot de resulterende data gekomen is [1]. Een data wetenschapper kan zo assumpties maken over de kwaliteit en de geloofwaar-digheid van de data [8]. Hij/zij kan zo zien hoe betrouwbaar de data is. Daarom is het handig als deze herkomstinformatie permanent en niet meer aan te passen is. Zo niet, zou de geloofwaardigheid van data kunnen vervalst worden voor mogelijke malafide doeleinden. Daarnaast heeft een centrale autoriteit hier ook een grote invloed op. Wat als een bedrijf her-komstinformatie opslaat voor klanten maar deze een data lek blijkt te hebben? Dit schaadt het imago van dat bedrijf en zorgt ervoor dat alle herkomstinformatie afkomstig van dat be-drijf, plots minder geloofwaardig lijkt. Zoals het in [1] wordt vermeld: Uit de definitie van geloofwaardigheid is het duidelijk dat de geloofwaardigheid van een gegevenswaarde afhangt van de oorsprong (bronnen) en de daaropvolgende verwerkingsgeschiedenis. De centrale au-toriteit die de data (en herkomstinformatie) opslaat maakt immers ook deel uit van de ver-werkingsgeschiedenis. Daarom mag er geen (of weinig) afhankelijkheid zijn van een centrale autoriteit doordat deze een te grote invloed heeft op het vertrouwen en de kwaliteit van de herkomstinformatie. Het is nodig om de opslag van herkomstinformatie te decentraliseren.
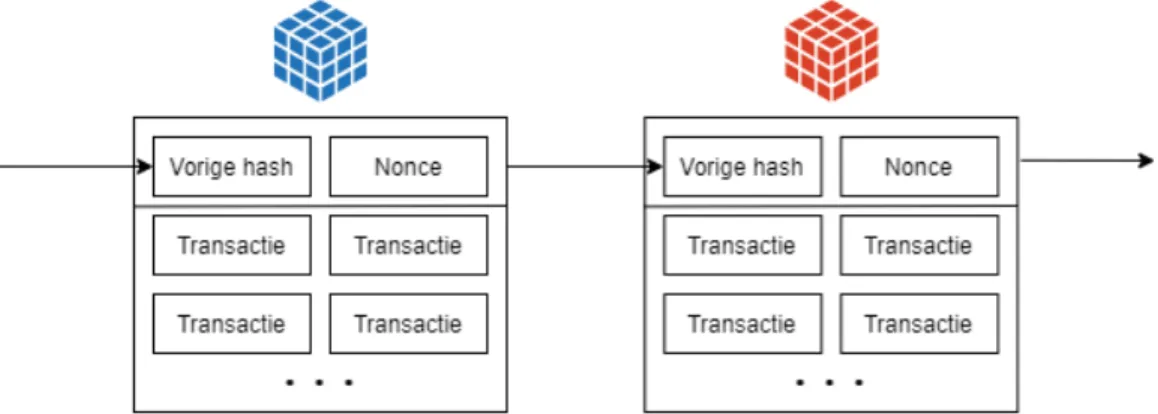
Een geschikte technologie hiervoor, is blockchain [9]. Dit is een gedecentraliseerd netwerk van systemen die samenwerken om op die manier een onveranderlijk en publiek grootboek (public ledger) van transacties te verschaffen. Deze transacties bevatten meestal een valuta, maar kunnen evengoed data bevatten. Een blockchain bestaat uit een ketting van blokken met transacties en meta informatie waarbij elke blok naar de vorige blok verwijst door middel van een unieke hash. Dit concept is vergelijkbaar met hoe een gelinkte lijst steeds verwijst naar de volgende knoop in de lijst. In het geval van de blockchain zou het dan een omgekeerde gelinkte lijst zijn waarbij steeds naar de vorige knoop wordt verwezen. Het opmerkelijke aan deze gelinkte lijst van blokken, deze blockchain, is dat de blokken niet zomaar kunnen aangepast worden eens ze aan de ketting (chain) van blokken zijn toegevoegd. De blokken zijn namelijk op mekaar gebaseerd doordat de unieke hashwaarde van een nieuwe blok steeds wordt berekend op basis van de data die zich in die nieuwe blok zal bevinden en die bevat ook een verwijzing naar de vorige blok. Zou er slechts ´e´en bit worden aangepast in een blok, dan wijzigt de hash van de blok waardoor de gehele blockchain niet meer consistent is. Immers, de verwijzingen naar de vorige blokken klopt bij ´e´en blok niet meer. Die fout kan uiteraard worden opgelost, maar schuift zich ook steeds door naar de volgende blok. Aangezien de hash van de voorgaande blok is aangepast, moet de blok erna zich ook aanpassen. Dit zal zich blijven herhalen tot alle blokken van de blockchain zijn afgegaan.
Daarnaast is de hash niet zomaar een hash, maar wordt hier een bepaalde complexiteit aan toegevoegd waardoor deze niet zomaar kan (of mag) worden berekend. Dit kan gaan van een hash vinden die grote hoeveelheid rekenkracht vereist of het inzetten van een hoeveelheid geld om zo een hash te mogen berekenen. Door dit extra werk zou een herberekening van alle blokken een enorm lange tijd in beslag nemen of een hoog kostenplaatje hebben indien een aanpassing zou uitgevoerd zijn aan ´e´en van de blokken. In het blockchain netwerk, de verzameling van alle computers die meewerken aan de blockchain, zal altijd de langste blockchain als de echte blockchain worden gezien. Daardoor is een kortere (en mogelijk malafide) blokketen (een alternatieve chain van blokken) volgen niet mogelijk in normale omstandigheden. Door dit concept wordt er gezorgd voor een gedecentraliseerd systeem waarbij er kan gegarandeerd worden dat de data die zich erin bevindt niet zomaar kan worden aangepast en dus onveranderlijk is.
Blockchain blijkt een geschikte technologie voor een onveranderlijk en gedecentraliseerd me-dium. Op figuur 1.2 wordt een visuele voorstelling gegeven van een herkomstinformatie block-chain. Daarop is te zien hoe de data wordt getransformeerd en aanpassingen kunnen opge-nomen worden in de herkomstinformatie blockchain. Hierbij zijn de geld transacties in het grootboek, de ledger, vervangen door transacties van data. Een probleem dat dan ontstaat, is dat er gemakkelijk slechte data in de blockchain kan terechtkomen die niet overeenstemt met het type data dat de blockchain zou moeten bevatten. In tegenstelling tot transacties met va-luta waarbij enkel geld kan worden rondgestuurd. Dit zorgt ervoor dat de blockchain vervuild
Figuur 1.2: Een visuele voorstelling van de herkomstinformatie blockchain
wordt (bevat nutteloze data) en onnodig in grootte toeneemt (niet schaalbaar). Hierdoor ver-dwijnt het vertrouwen dat herkomstinformatie net wel aan data zou moeten geven. De data op voorhand valideren en tegenhouden indien het niet voldoet aan de regels kan hiervoor een geschikte oplossing zijn. Het is nodig dat het netwerk van computers die meewerken aan de herkomstinformatie blockchain vertrouwd kan worden. Er wordt dan ook verwacht dat elke computer de juiste validatieregels toepast. Er is nood aan een stimulans die ervoor zorgt dat een computer in het netwerk niet zomaar slechte data verstuurt waardoor de blockchain niet vervuild kan worden. Dan blijft de vraag, wat zou zo een stimulans kunnen zijn als er geen alternatieven zoals geld in omloop zijn? Geld geeft namelijk een goede stimulans om niet vals te spelen. Zo wordt er bij een Proof-of-Stake [10] blockchain geld ingezet en als een computer vals zou spelen, verliest de computer dit ingezette geld. Hoe kan er een gelijkaardig concept worden gebruikt zonder financi¨ele middelen? En als er zoiets wordt gevonden, zou het ook in de praktijk kunnen werken? Om op deze vragen een antwoord te vinden moest er een grondige analyse van op blockchain gebaseerde software ter opslag van herkomstinformatie worden uitgevoerd.
1.3
Onderzoeksvraag
Op basis van de omschreven probleemstelling, defini¨eren we volgende onderzoeksvraag: Met welke technologie¨en en technieken kan er een schaalbaar en betrouwbaar blockchain systeem worden opgezet ter opslag van herkomstinformatie?
Het was belangrijk dat een juiste technologie werd gekozen die, in tegenstelling tot een va-luta blockchain, de opslag van herkomstinformatie in een blockchain mogelijk maakt. Hierbij moet er een mogelijkheid zijn om de verwerking van de transacties bij zo een blockchain technologie te bekijken en aan te passen. Zo kan dit proces worden afgesteld specifiek voor
de verwerking van herkomstinformatie waarmee mogelijks meer schaalbaarheid en vertrouwen kan gerealiseerd worden. Met andere woorden, met die technologie kunnen er technieken wor-den gerealiseerd die een schaalbaar en betrouwbaar blockchain systeem mogelijk kan maken. Daaruit kan volgende hypothese worden afgeleid: Met een gepaste blockchain technologie kan er met de passende technieken een schaalbaar en betrouwbaar blockchain systeem worden opgezet ter opslag van herkomstinformatie.
1.4
Aanpak
Om een analyse van op blockchain gebaseerde software ter opslag van herkomstinformatie te kunnen uitvoeren moesten er meerdere activiteiten plaatsvinden tijdens het onderzoek. Eerst werd een uitgebreide literatuurstudie (2) gedaan over de concepten van het semantisch web (2.1), hoe herkomstinformatie kan worden voorgesteld (2.2) en de werking achter een blockchain (2.3). Uiteindelijk werd bekeken met welke methodieken en structuren herkomst-informatie en een blockchain kan worden samengebracht (2.4). Met deze kennis kon er worden overgaan naar het vooronderzoek (3) waarbij er een model voor de architectuur werd voor-gesteld (3.1). Verder werden de gekozen technologie¨en besproken (3.2) die verder gebruikt werden in het onderzoek en waarmee ook een eerste implementatie (3.3) werd gerealiseerd. Hiermee werd ook een eerste experiment uitgevoerd (3.4). Echter bleek, zoals verwacht, deze implementatie net een uitbreiding op de probleemstelling (3.5). Het gaf een duidelijk inzicht waarom er verder moest gekeken worden dan louter het concept van een blockchain die data kan opslaan (4). Om die reden werd een oplossing (4.1) voor de problematiek die de eer-ste implementatie aangaf, voorgeeer-steld. Deze voorgeeer-stelde oplossing werd ge¨ımplementeerd (4.2) en wordt verder in het onderzoek de verbeterde implementatie genoemd. Deze lost de problemen op die de initi¨ele implementatie had. Op deze implementatie werden er experimen-ten (4.3) uitgevoerd waarbij enkele use cases werden afgetoetst op een netwerk met tien tot twintig computers. Dit gaf een goede proof of concept voor een schaalbaar en betrouwbaar blockchain systeem ter opslag van herkomstinformatie. Daarmee konden er in de conclusie (5) enkele besluiten worden gevormd (5.1). Om het onderzoek af te sluiten worden er verder nog mogelijke pistes aangehaald voor toekomstig onderzoek (5.2).
Deze masterproef werd in het Nederlands geschreven maar bevat ook enkele Engelse termen omdat deze geen correcte of een onhandige vertaling hebben in het Nederlands. Daarnaast werd alle code steeds in het Engels uitgedrukt om een verwarrende samenstelling van Nederlandse en Engelse syntax te vermijden.
In dit hoofdstuk worden er enkele belangrijke onderwerpen besproken zodat het verdere on-derzoek beter begrepen kan worden. Eerst wordt in 2.1 het semantisch web besproken. Dit is een belangrijk onderdeel om de structuur van herkomstinformatie te kunnen begrijpen. Hoe herkomstinformatie wordt voorgesteld gebeurt dan in 2.2. Verder wordt de werking van de blockchain in 2.3 aangetoond en tot slot wordt in 2.4 bekeken hoe herkomstinformatie en blockchain gecombineerd kunnen worden.
2.1
Het Semantisch Web
In 1.1.1 werd al een inleiding gegeven tot het semantisch web. Het semantisch web is een uitbreiding tegenover het web dat vandaag de dag bestaat. Computers moeten net zoals mensen de informatie die in omloop is, kunnen verstaan en gebruiken. In [11] worden 2 interessante perspectieven vermeldt van hoe het semantisch web kan worden bekeken:
1. Het web gaan omvormen naar een universele bibliotheek van informatie die gelezen en gebruikt kan worden door gebruikers van het web.
2. Het web die een backbone aanbiedt voor computers zodat die op zelfstandige wijze activiteiten kunnen uitvoeren in opdracht van gebruikers. Het web wordt hier gezien als een navigator doorheen de kennis die het web aanbiedt.
Het is duidelijk dat het semantisch web voornamelijk een gestandaardiseerde structuur van kennis wil bereiken om op die manier data meer te kunnen hergebruiken. Bij mensen wordt deze informatie verschaft door het tonen van HTML pagina’s. Echter kan een computer hier zelf weinig informatie uit halen zonder dat die expliciet is gespecificeerd door een mens. Zoals bijvoorbeeld het scrapen van webpagina’s of het gebruiken van publieke API’s waarvoor steeds tussenkomst van een mens nodig is. Het semantisch web is een geschikte technologie om informatie aan computers te geven net zoals HTML pagina’s ons informatie verschaffen. Het semantisch web heeft dan ook een eigen technologie stack (stapel) zoals getoond in figuur
2.1. Deze stack wordt overlopen van onder naar boven en de belangrijkste aspecten ervan worden besproken.
Figuur 2.1: De technologie stack van het semantisch web [12]
2.1.1 URI
Een URI [11], Universal Resource Identifier (ook wel IRI, Internationalized Resource Identifier, genoemd), is het eerste belangrijke onderdeel van de semantische web stack. Dit is een manier hoe items op het internet kunnen worden ge¨ıdentificeerd net zoals wij objecten in het echte leven identificeren met een benaming. Een gekende vorm van deze URI’s is een URL. Dit wordt gebruikt als een web adres om een pagina die zich op een server resideert te kunnen bereiken. URI’s werken op dezelfde manier, maar worden niet gebruikt om een pagina te vinden op het web, wel als identificatie van een bron (resource). Op deze manier kunnen er verscheidende items gaan onderscheiden worden van elkaar. Zo kan er een URI zijn die wijst naar de planeet Pluto die er zo uit ziet: http://example.org/Pluto. Pluto heeft dan weer andere eigenschappen die op zich ook URI’s kunnen zijn. Zoals het jaar waarin het ontdekt werd of de persoon wie het ontdekt heeft. Hierdoor wordt er een heel netwerk van data ter beschikking gesteld.
2.1.2 RDF
Deze semantieken moeten op een duidelijke manier kunnen voorgesteld worden die zowel door mensen, als door computers gemakkelijk kunnen gelezen en opgesteld worden. Het Resource Description Framework [5] is hiervoor een geschikte technologie. De essentie bij RDF ligt aan het feit dat er steeds wordt gebruik maakt van triplets. Een triplet bestaat dan uit een:
Predikaat of predicate, het kenmerk of het aspect die wordt beschreven. Object, de waarde van het predikaat.
Figuur 2.2: Een RDF triplet voorgesteld in een graaf
Zo een triplet kan eenvoudig in een graaf worden voorgesteld zoals getoond op figuur 2.2. Deze onderdelen van de triplet kunnen verschillende waarden bevatten, afhankelijk van of ze een onderwerp, predikaat of object voorstellen.
Ten eerste kan dit een URI bevatten [5]. Dit is, zoals eerder besproken, een verwijzing naar de bron. Door gebruik te maken van URI’s in de plaats van vaste strings, kan de data met elkaar gelinkt worden. Een URI kan bijvoorbeeld de identificatie van de bron Pluto zijn waarbij het hier gaat over de planeet Pluto. De bron van de planeet Pluto bevat mogelijks zelf ook verwijzingen naar andere bronnen.
Een tweede manier is een vaste waarde of literal in het Engels [5]. Dit is simpelweg een statische waarde die een mogelijk datatype kan hebben. Zo is Pluto ontdekt in het jaar 1930 en wordt er daarom ook geen extra betekenis aan het nummer 1930 gehecht. Er kan wel een datatype bij zo een vaste waarde vermeldt worden en bij 1930 zou dat als datatype een decimal kunnen zijn.
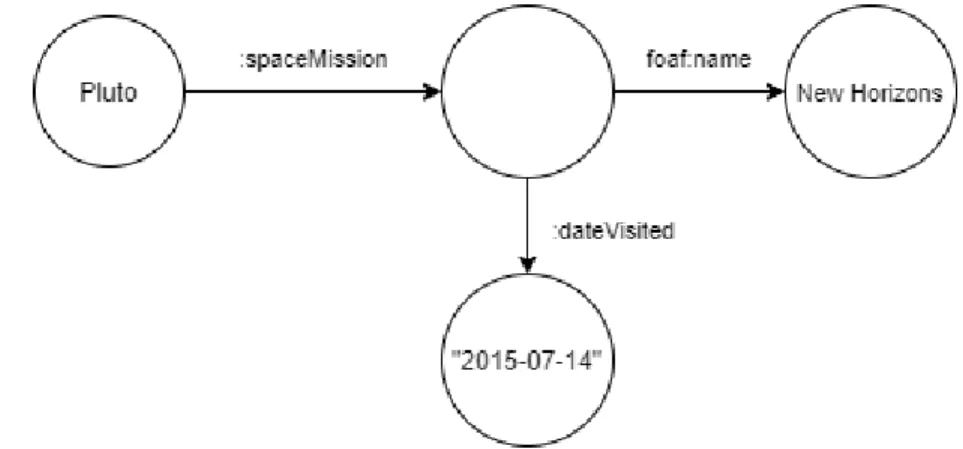
Een derde manier is een blanke knoop [5]. Een blanke knoop is iets dat geen URI of vaste waarde heeft. Een blanke knoop is een lege knoop, zonder data. Deze lege knoop kan voor-namelijk zorgen voor meer structuur in de data. Een goed voorbeeld hiervan is waarbij er een onderwerp Pluto aanwezig is, een predikaat spaceMission (een ruimtemissie) en een pre-dikaat dateVisited (datum dat Pluto bezocht werd), met hun bijhorende waarden. Stel dat er meerdere ruimtemissies zijn geweest met elk hun bijhorende datum waarop Pluto bezocht werd. Dit geeft dan een lijst van predikaten met zowel meerdere spaceMission predikaten als meerdere dateVisited predikaten. Hoe kan er dan worden geweten welke dateVisited bij welke spaceMission hoort? Het zou kunnen dat de dateVisited hoort bij de spaceMission die volgens de opgegeven volgorde erna komt, maar dat is niet noodzakelijk altijd waar. Er is namelijk geen logische volgorde in de triplets. Een manier om dit op te lossen is door een blanke knoop te gebruiken. Voor elke spaceMission met een dateVisited wordt er een blanke knoop gebruikt. Aan deze blanke knoop wordt dan de spaceMission en dateVisited
predikaat gekoppeld. Op die manier kan er achterhaalt worden, welke spaceMission bij welke dateVisited hoort. Figuur 2.3 toont dit principe visueel aan.
Figuur 2.3: Een voorbeeld van hoe een blanke knoop kan gebruikt worden
Een onderwerp kan een URI zijn of een lege knoop, een predikaat kan enkel een URI zijn en een object kan een URI of een vaste waarde zijn. Door deze regels te volgen, wordt er een gestandaardiseerde manier verkregen om semantieken te kunnen voorstellen. Daarnaast kun-nen deze ook eenvoudig door mensen en door computers begrepen worden. Er zijn meerdere manieren beschikbaar om RDF te gaan voorstellen. In dit onderzoek werd gekozen om voor de voorstelling van RDF steeds Turtle te gebruiken aangezien dit naar mijn mening de meest leesbare vorm is.
2.1.2.1 Turtle RDF
Terse RDF Triple Language [13] of korter, Turtle RDF, is een formaat om RDF weer te geven op het web. Om de syntax van Turtle duidelijk te maken, wordt er gebruik gemaakt van de code getoond in 2.1. Deze code is gebaseerd op enkele fictieve figuren uit de serie Game of Thrones.
1 @prefix foaf: <http://xmlns.com/foaf/0.1/> .
2 @prefix rel: <http://www.perceive.net/schemas/relationship/> .
3 @prefix xsd: <http://www.w3.org/2001/XMLSchema#> . 4 @base <http://example.org/#> . 5 6 <http://example.org/lyannastark> <http://www.perceive.net/schemas/relationship/parentof> <http:// example.org/jonsnow> . 7 8 <jonsnow> 9 rel:childOf <rhaegartargaryen> ; 10 a foaf:Person ;
11 foaf:name "Jon Snow", "Aegon Targaryen"@en ;
13
14 <rhaegartargaryen>
15 rel:parentOf <jonsnow> ;
16 a foaf:Person ;
17 foaf:name "Rhaegar Targaryen" .
Code voorbeeld 2.1: Een voorbeeld van hoe Turtle eruit ziet waarbij het Game of Thrones universum werd gebruikt
Triplets [13]
Een triplet wordt steeds gedefinieerd door drie onderdelen. Zo kan het volgende worden gezien op lijn 6: drie URI’s gesplitst door drie spaties en be¨eindigd met een punt. Dit duid op het volgende: Lyanna Stark is de ouder van Jon Snow. Op deze manier zullen alle triples worden gedefinieerd doorheen Turtle. Respectievelijk is dit Lyanna Stark als onderwerp, ouder van als predikaat en Jon Snow als object. Bij Jon Snow op lijn 10 staat een speciaal predikaat. Daar staat namelijk a foaf:Person. Dit duidt op het type van een onderwerp, in dit geval is Jon Snow een persoon.
Prefix en base [13]
Bepaalde delen van URI’s kunnen mogelijks meerdere malen voorkomen. Hierdoor kan er veel redundantie aanwezig zijn in een Turtle bestand. Het is daarom beter om een @prefix te gebruiken. Dit is een speciale syntax die aangeeft dat een bepaald woord zich eigenlijk vertaald naar een volledige URI. Zo vertaald foaf: zich in “<http://xmlns.com/foaf/0.1/>”. Op lijn 4 wordt ook een @base gedefinieerd. Dit heeft dezelfde functionaliteit als een @prefix, echter moet nu niet het opgegeven woord (zoals foaf:) ervoor worden geplaatst. Elk gebruikt woord die zich tussen <en >bevindt wordt automatisch aangevuld met de URI die zich bij de @base triplet bevindt.
Vaste waarden [13]
Jon Snow beschikt over een naam, dit is een vaste waarde. Ook zijn leeftijd op lijn 12 is een vaste waarde te zien door het foaf:age predikaat. Er kan nog extra informatie worden meegegeven aan deze waardes. Zo kan het datatype van een vaste waarde meegegeven worden zoals bijvoorbeeld bij foaf:age wordt gedaan. Hier is het datatype xsd:decimal. Opnieuw wordt er gebruik gemaakt van een URI om het datatype aan te geven. Een ander iets wat er bij deze vaste waarden kan worden gespecificeerd is welke taal het is. Zo is de naam “Aegon Targaryen” een Engelse naam aangegeven door @en. Er is daardoor de mogelijkheid om meerdere namen te specificeren in andere talen en dit aan te geven door het @ teken te gebruiken.
Predikaten lijst [13]
Bij Jon Snow zijn er meerdere predikaten aanwezig. Dit zou lijn per lijn kunnen gedefinieerd worden waarbij het onderwerp <jonsnow> steeds opnieuw wordt vernoemd. Dit is echter
opnieuw redundant en kan vereenvoudigd worden. Opnieuw wordt er begonnen met het on-derwerp aan te halen en vervolgens zijn predikaat met het bijhorende object te defini¨eren. Echter wordt in dit geval niet afgesloten met een punt, maar met een puntkomma. Hier-mee wordt bedoelt dat het onderwerp <jonsnow> Hier-meerdere predikaten bezit. In het code voorbeeld is dit duidelijk aanwezig. Bij de laatste predikaten wordt een punt na het object gezet om aan te geven dat er geen verdere predikaten meer aanwezig zijn voor de opgegeven onderwerp.
Object lijst [13]
Wat nog opvalt, is dat Jon Snow bij de laatste predikaat foaf:name op lijn 11 meerdere objecten bezit. In het Game of Thrones universum bezit Jon Snow namelijk meerdere namen. Het is ook mogelijk om meerdere objecten aan eenzelfde predikaat te geven in de plaats van elk predikaat opnieuw te gebruiken voor een andere object waarde. De verschillende objecten kunnen dan opgesplitst worden door gebruik te maken van een komma. Dit wordt dan be¨eindigd met een punt of puntkomma.
Tot slot is in de code op lijn 14 de naam Rhaegar Targaryen te zien. Dit is het object die vermeldt werd bij Jon Snow met het predikaat rel:childOf. Ook Rhaeger bezit enkele predikaten, die ook opnieuw mogelijks naar andere onderwerpen kunnen verwijzen. Op deze manier kunnen continu entiteiten aan mekaar gekoppeld worden, waardoor er een netwerk van linked data wordt verkregen [13].
Turtle heeft nog veel meer mogelijkheden. Daarover heeft de offici¨ele documentatie van W3C [13] meer informatie te bieden.
2.1.3 Schema en ontologie¨en
Net zoals bij veel datastructuren is er nood aan andere structuren die de structuren zelf beschrijven. Zo is een schema een definitie van een model. Zo een schema kan dan een vaste structuur aan data geven. Dit zorgt voor meer kennis over wat de data precies wil zeggen. Daarnaast zorgt zo een schema ook voor meer consistentie in grote hoeveelheden data. Ontologie is een bredere term die meerdere betekenissen kan hebben afhankelijk van de con-text. De hier besproken definitie is die op het terrein van het semantisch web. Volgens Thomas R. Gruber [14] is een ontologie een expliciete, formele specificatie van een gedeelde conceptualisatie. Concreter wil dit zeggen dat er een abstract model expliciet wordt uitge-drukt waardoor het ge¨ınterpreteerd kan worden door computers. Dit wil niet zeggen dat het slechts leesbaar moet zijn. Een computer kan immers al zonder problemen data inlezen, ech-ter weet deze niet wat de logische betekenis is achech-ter deze data. Door een ontologie kan een computer wel de logische betekenis achter de ingelezen data verstaan. Deze conceptualisatie moet ook gedeeld zijn, zodat elke computer elkaar kan verstaan. Net zoals een menselijke
taal door meerdere mensen wordt gesproken. Zouden computers immers voor een bepaald iets elk een andere betekenis hebben, dan begrijpen ze mekaar niet correct. Deze ontologie¨en kunnen worden voorgesteld door het gebruik van klassen, relaties en instanties waarover in de volgende sectie verder wordt op ingegaan hoe dit bij RDF gebeurt. Kort samengevat, is een ontologie niet meer dan een interpreteerbare beschrijving van de werkelijkheid voor een computer.
2.1.3.1 RDFS
RDF Schema [15] is een uitbreiding tegenover het in 2.1.2 besproken RDF. Het dient om de structuur van de ontologie¨en te kunnen beschrijven. Deze schema definitie taal kan verge-leken worden met hoe bij object geori¨enteerde talen gebruik wordt gemaakt van klassen en eigenschappen. Dit zijn ook definities die gebruikt worden om objecten aan te maken. Als er bijvoorbeeld een URI is die verwijst naar de bron “Universiteit Gent”, dan kunnen mensen hieruit gemakkelijk afleiden dat de URI waarschijnlijk wijst naar een universiteit gelegen in Gent. Echter kan een computer dit niet. Voor een computer is het net alsof er “ea07dae8dcc” (dit is louter een willekeurige gekozen string) zou staan in de plaats van Universiteit Gent. Voor een mens heeft “ea07dae8dcc” ook duidelijk geen betekenis. Om die reden is het be-langrijk dat er bepaalde definities worden gemaakt zodat een computer weet waar het mee te maken heeft.
In code voorbeeld 2.2 wordt een voorbeeld getoond van hoe RDFS er uit ziet. Deze wordt dan ook gebruikt om de werking van RDFS te bespreken in de volgende paragrafen. De syntax is hetzelfde als bij RDF, echter wordt er hier gebruik gemaakt van een nieuwe prefix: rdfs. Het eerste wat opvalt is dat er gebruik wordt gemaakt van rdf:type. Een alternatieve gekwalificeerde naam (= alternatieve syntax) hiervoor in Turtle is a waarvan de betekenis ook equivalent is. Deze werd ook al in de uitleg van RDF in 2.1.2 gebruikt.
1 @prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> . 2 @prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> . 3 @prefix : <http://example.org/> . 4 5 :Universiteit 6 rdf:type rdfs:Class ; 7 rdfs:subClassOf :School . 8 :Hogeschool 9 rdf:type rdfs:Class ; 10 rdfs:subClassOf :School . 11 :School 12 rdf:type rdfs:Class . 13 :Person 14 rdf:type rdfs:Class . 15 16 :goesTo 17 rdf:type rdf:Property ;
18 rdf:domain :Person ;
19 rdf:range :School .
20 21 :Ugent
22 a :Universiteit ;
23 rdfs:label "Universiteit Gent" ;
24 rdfs:comment "Een universiteit gelegen in Gent" .
25 :Michiel
26 a :Person ;
27 rdfs:label "Michiel" ;
28 rdfs:comment "Een persoon genaamd Michiel" ;
29 :goesTo :Ugent .
Code voorbeeld 2.2: Een voorbeeld van RDF Schema waarbij er gebruik wordt gemaakt van Vlaamse scholen
Klassen en eigenschappen [15]
Er kunnen zowel rdfs:Class (klassen) als rdfs:Property (eigenschappen) worden onderschei-den. Klassen kunnen dan gekoppeld worden aan mekaar door een eigenschap. Eigenschappen worden gebruikt voor predikaten, terwijl klassen worden gebruikt voor onderwerpen en ob-jecten. Net zoals bij object geori¨enteerde talen kan een klasse ook een subklasse zijn van een andere klasse. Op deze manier volstaat het om op lijn 16 bij :goesTo te specificeren dat het gekoppeld is aan een :School. Zo is op lijn 7 en 10 in de code te zien dat :Universiteit en :Hogeschool subklasses zijn van :School.
Domein en bereik [15]
De rdfs:domain (domein) en rdfs:range (bereik) van een rdf:property bepalen welke soort klassen een predikaat is. Het verschil tussen deze twee is dat rdfs:domain de nadruk legt op welke klasse het onderwerp is en rdfs:range welke klasse het object is. Het is belangrijk om hier bij op te merken dat het opgegeven object of onderwerp niet noodzakelijk bij die klasse moet toebehoren. Zo kan :goesTo gebruikt worden voor een persoon als onderwerp en een school als object. Echter kan ook het volgende worden opgegeven: Stel dat een persoon Michiel naar Sven gaat: :Michiel :goesTo :Sven. In die context geeft dat aan dat Michiel een persoon is en Sven een school. De domein en bereik geven dus aan van welk type het onderwerp of object is in die context en niet van welke type het zou moeten zijn.
Label en commentaar [15]
Verder wordt in het voorbeeld op lijn 23-24 en 27-28 ook nog gebruik gemaakt van rdfs:label en rdfs:comment (commentaar). Dit is voornamelijk bedoelt voor menselijke consumptie voor extra informatie. Zo zou bijvoorbeeld de eerder genoemde “ea07dae8dcc” wel een logische betekenis kunnen hebben als identificatiemiddel door commentaar hierbij te plaatsen van wat de string precies wil zeggen. Uiteraard geldt dit enkel voor een mens.
Dit deel dient slechts als introductie tot RDFS. Voor meer informatie hierover kan de docu-mentatie van W3C [15] worden geraadpleegd.
2.1.4 SPARQL
SPARQL [16], SPARQL Protocol and RDF Query Language, is een query taal die gebruikt kan worden in combinatie met RDF datastructuren. SPARQL lijkt grotendeels op het gekende SQL en wordt ook om soortgelijke doeleinden gebruikt. Namelijk om specifieke informatie over RDF data te bekomen. Stel dat er een lijst van planeten ter beschikking is zoals in code voorbeeld 2.3 getoond wordt. Als de planeten willen opgehaald worden die v`o`or 1930 gevonden zijn, dan kan dit worden gedaan met de query getoond op code voorbeeld 2.4. Dit zal dan als resultaat de planeten Jupiter, Uranus en Neptunus geven.
1 @prefix dbo: <http://dbpedia.org/page/> .
2 @prefix foaf: <http://xmlns.com/foaf/0.1/> .
3 4 dbo:Pluto 5 foaf:name "Pluto" ; 6 dbo:discovered 1930 . 7 8 dbo:Jupiter 9 foaf:name "Jupiter" ; 10 dbo:discovered 1610 . 11 12 dbo:Uranus 13 foaf:name "Uranus" ; 14 dbo:discovered 1781 . 15 16 dbo:Neptune 17 foaf:name "Neptune" ; 18 dbo:discovered 1846 .
Code voorbeeld 2.3: Enkele planeten met hun ontdekkingsjaar volgens het Turtle formaat RDF
1 PREFIX dbo: <http://dbpedia.org/page/>
2 SELECT ?name
3 WHERE {
4 ?name dbo:discovered ?year .
5 FILTER (?year < 1930)
6 }
Code voorbeeld 2.4: Een SPARQL query die de planeten toont die v`o`or 1930 gevonden zijn
De uitgebreidere werking van SPARQL is verder niet relevant voor dit onderzoek.
2.1.5 SHACL
SHACL wil voluit zeggen: Shapes Constraint Language [17]. Het is bedoelt om graaf geba-seerde data te kunnen valideren tegenover een verzameling regels. Deze verzameling wordt ook wel een vorm (shape) genoemd en wordt uitgedrukt in RDF. Het is de bedoeling dat andere RDF data kan gevalideerd worden tegenover deze vormen. Op die manier kan ervoor gezorgd worden dat RDF data steeds op de juiste manier gestructureerd is. In het volgende deel 2.2 zal een model worden voorgesteld om herkomstinformatie te kunnen voorstellen in
RDF data. Zo zou SHACL er voor kunnen zorgen dat dit model steeds wordt nageleefd bij bijvoorbeeld het opslaan van herkomstinformatie op een databank.
Op code voorbeeld 2.5 wordt er RDF data getoond. Zo is op de lijnen 4-6 en 8-10 is te zien dat ex:Alice en ex:Bob van het type ex:Person zijn en werken voor ex:Ugent. Een eenvoudig voorbeeld van SHACL die betrekking heeft op deze RDF data is te zien op code voorbeeld 2.6.
Op lijn 5 van code voorbeeld 2.6 is sh:NodeShape te zien. Dit is een RDF klasse van SHACL zelf die aangeeft dat het om een vorm gaat van een knoop. Vervolgens is er op lijn 6 de sh:targetClass met de bijhorende ex:Person te zien. Dit geeft aan dat de regels bedoelt zijn op een RDF klasse van het type ex:Person. Hierna volgt op lijn 7 een sh:property. Dit heeft betrekking tot de eigenschap van een RDF klasse. In dit geval gaat het om de sh:path voor ex:worksFor te zien op lijn 8. Daarmee wordt bedoelt dat deze regel invloed heeft op het ex:worksFor predikaat. Ten slotte geeft de regel op lijn 9 aan dat de sh:class voor dat predikaat een ex:Company moet zijn. De getoonde SHACL lijnen willen eenvoudigweg zeggen dat een persoon steeds moet werken voor een bedrijf. Zou het onderwerp ex:Alice een predikaat ex:worksFor hebben met als object ex:Bob, dan worden de SHACL regels overtreden en zal dit een fout geven.
1 @prefix sh: <http://www.w3.org/ns/shacl#> .
2 @prefix ex: <http://example.com/ns#> .
3 4 ex:Alice 5 a ex:Person ; 6 ex:worksFor ex:Ugent . 7 8 ex:Bob 9 a ex:Person ; 10 ex:worksFor ex:Ugent . 11 12 ex:Ugent 13 a ex:Company .
Code voorbeeld 2.5: RDF data
1 @prefix sh: <http://www.w3.org/ns/shacl#> .
2 @prefix ex: <http://example.com/ns#> .
3 4 ex:PersonShape 5 a sh:NodeShape ; 6 sh:targetClass ex:Person ; 7 sh:property [ 8 sh:path ex:worksFor ; 9 sh:class ex:Company ; 10 ] .
2.2
Herkomstinformatie
Herkomstinformatie of in het Engels provenance data [8] is kort gezegd een logboek van alles wat met de data is gebeurd. Deze vermeldt alle transformaties op de data, van wie of wat het afkomstig is en heeft als doel om een beoordeling op de kwaliteit en de geloofwaardigheid van de data mogelijk te maken. Dit is een vorm van metadata, maar niet alle metadata is automatisch ook herkomstinformatie. Zo zijn de dimensies van een afbeelding metadata maar dit is geen herkomstinformatie. Net zoals bij het semantisch web in 2.1 kan deze herkomstinformatie vanaf meerdere perspectieven worden bekeken [8]:
1. Een eerste perspectief focust zich op “agent-gecentreerde herkomstinformatie” dat wil zeggen, welke mensen zijn er betrokken bij deze data? Bijvoorbeeld een nieuwsartikel, wie heeft het geschreven?
2. Een tweede perspectief legt de nadruk op “object-gecentreerde herkomstinformatie”. Hierbij worden de documenten (entiteiten) die gebruikt werden bij de vorming van de data neergeschreven. Zo kan de oorsprong van data worden achterhaalt. Zo kan bijvoorbeeld de data afkomstig zijn van een webpagina of een publieke dataset.
3. Een derde en laatste perspectief bekijkt “proces-gecentreerde herkomstinformatie” waar-bij de processen (activiteiten) worden bekeken die nodig waren om de effectieve data te bekomen. Denk hierbij aan een algoritme dat is uitgevoerd op de data of een grafische tool die gebruikt werd om een grafiek voor te stellen.
Met deze 3 perspectieven kan een concreet herkomstinformatie model worden gemaakt te zien op figuur 2.4. Dit wordt volgens W3C het PROV model genoemd en specificeert enkele belangrijke definities en regels.
Entiteit of entity [8]: Dit is niet meer dan een digitaal, fysiek of conceptueel object. Dit kunnen documenten zijn met data, data sets, webpagina’s, ... Deze documenten kunnen afgeleid worden van andere documenten (wasDerivedFrom) of kunnen gegenereerd zijn door een activiteit (wasGeneratedBy). Deze entiteiten hoeven niet noodzakelijk aan het einde van een activiteit te worden gegenereerd maar kunnen ook doorheen de levenscyclus van een activiteit worden aangemaakt.
Activiteit of activity [8]: Hierbij worden de processen bedoelt die een bepaalde entiteit kan genereren. Deze activiteiten zelf kunnen andere entiteiten gaan gebruiken (used ) om op die manier een nieuwe entiteit te gaan genereren. Dit wil niet zeggen dat een entiteit enkel bij het begin van een activiteit kan gebruikt worden. Dit kan ook gebeuren naargelang de levenscyclus van een activiteit.
Agent [8]: Een agent kan een persoon, een stuk software, een organisatie, ... zijn. Een agent is voornamelijk bedoelt om een bepaalde verantwoordelijkheid toe te vertrouwen aan een activiteit. Immers zijn deze activiteiten meestal door een agent in werking gebracht (wasAs-sociatedWith). Daarnaast kan een entiteit ook aan een agent toebehoren (wasAttributedTo) wat dan ook indirect wil zeggen dat de agent verantwoordelijk is voor de activiteit die de entiteit heeft gegenereerd.
2.2.1 PROV-Ontology
Er zijn meerdere specificaties beschikbaar van het PROV model beschreven door W3C. Zo werd bij de herkomstinformatie in dit onderzoek voornamelijk gebruik gemaakt van het PROV-Ontology model [18] zoals getoond op figuur 2.5. Hierbij zijn nog enkele toevoe-gingen aanwezig tegenover het originele model. Zo heeft een activiteit een start en eindtijd (startedAtTime en endedAtTime). Er kan ook een activiteit gespecificeerd worden die geen start en eindtijd heeft door deze te laten informeren door een andere activiteit (wasInfor-medBy). De activiteit die ge¨ınformeerd werd gebruikt dan een entiteit die gegenereerd werd door de informerende activiteit. Tot slot kan er bij een agent nog een andere agent worden gespecificeerd die verantwoordelijk is voor de actie van de agent (actedOnBehalfOf ). Een goed voorbeeld hiervan is een persoon die in naam van een bedrijf een actie uitvoert.
Figuur 2.5: Het PROV-O model gespecificeerd volgens W3C [18]
Op figuur 2.6 is een grafiek te zien van het blockchain gebruik over de jaren heen. Let op dat deze figuur geen echte data weergeeft en de data louter verzonnen werd ter illustratie. De bijhorende herkomstinformatie voor deze grafiek is te zien op code voorbeeld 2.7.
Figuur 2.6: Een grafiek met valse data over het blockchain gebruik
1 @prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
2 @prefix foaf: <http://xmlns.com/foaf/0.1/> .
3 @prefix prov: <http://www.w3.org/ns/prov#> .
4 @base <http://example.org#> .
5
6 <bar_chart>
7 a prov:Entity ;
9 prov:wasDerivedFrom <paper> ;
10 prov:wasAttributedTo <michiel> .
11
12 <paper>
13 a foaf:Document, prov:Entity ;
14 foaf:name "Blockchain usage" .
15 16 <excelGraphing> 17 a prov:Activity ; 18 prov:used <paper> ; 19 prov:wasAssociatedWith <michiel> ; 20 prov:startedAtTime "2020-02-14T20:51:04Z"^^xsd:dateTime ; 21 prov:endedTime "2020-02-14T20:51:05Z"^^xsd:dateTime . 22 23 <michiel> 24 a foaf:Person, prov:Agent ; 25 foaf:givenName "Michiel" ; 26 foaf:mbox "mailto:michiel@example.org" ; 27 prov:actedOnBehalfOf <ugent> . 28 29 <ugent> 30 a foaf:Organization, prov:Agent ; 31 foaf:name "UGent" . 32
Code voorbeeld 2.7: Herkomstinformatie horend bij figuur 2.6
In het code voorbeeld wordt op lijn 6 verwezen naar de getoonde grafiek op figuur 2.6. Deze is een entiteit, gegenereerd door het Excel programma, afgeleid van een paper en gelinkt aan agent Michiel. Verder worden alle entiteiten, agenten en activiteiten beschreven die het mogelijk maken om tot de grafiek te komen. Het code voorbeeld is een eenvoudige voorstelling van hoe herkomstinformatie er kan uitzien. Het is deze data dat zal worden opgeslagen in een blockchain systeem om op die manier te garanderen dat deze niet meer kan worden aangepast. Het is eenvoudig om deze herkomstinformatie aan te maken en daardoor ook even eenvoudig om deze, met eventuele slechte bedoelingen, aan te passen.
2.3
Blockchain
Het principe achter een blockchain werd al reeds in 1992 beschreven door Stuart Haber en W. Scott Stornetta [19]. Zij stelden een systeem voor waar de timestamps (moment van aanmaken) van documenten niet meer konden aangepast worden. Toch duurde het tot 2008 voordat een blockchain zoals die vandaag gekend is werd beschreven. Zo werd de blockchain Bitcoin [20] beschreven door een onbekende persoon (of groep) genaamd Satoshi Nakamoto. Bitcoin was een digitaal geldsysteem die het probleem zou oplossen dat geld steeds moet verstuurd worden door middel van een financi¨ele instelling. Zo stelt Bitcoin een gedecentra-liseerde digitale valuta voor. Dit wordt ook wel een cryptografische valuta genoemd doordat hun werking voornamelijk gebaseerd is op de cryptografie. De dag van vandaag bestaan er
meerdere implementaties van blockchains en niet alleen voor geld transacties, maar ook voor andere use cases zoals data opslag [21].
2.3.1 Waarom blockchain?
Zoals vermeldt, is het doel van de Bitcoin om de tussenkomst van financi¨ele instellingen te vermijden. Dit wordt ook wel een gedecentraliseerd peer to peer elektronisch cash systeem genoemd [20]. Er is bij zo een systeem geen centrale eenheid nodig voor een betaling uit te voeren. Normaal is er een vertrouwde derde partij nodig om er zeker van te zijn dat het (digitaal) geld niet dubbel wordt gespendeerd. Deze derde partij is niet meer nodig als er gebruik wordt gemaakt van een blockchain. Zo zorgt dit ervoor dat er zeer snel en goedkoop transacties kunnen worden uitgevoerd. Daarnaast biedt dit systeem een vorm van anonimiteit aan en tegelijk ook transparantie. Alle transacties op het Bitcoin netwerk kunnen namelijk bekeken worden door elke persoon. Echter blijven de persoonlijke gegevens van de personen betrokken bij deze transactie onbekend indien er geen gegevens aan hun publieke sleutel gekoppeld zijn (zie 2.3.3 voor de betekenis van een publieke sleutel).
Zo een blockchain systeem is fraudebestendig en onveranderlijk in normale omstandigheden door de cryptografie en bewijs van rekenkracht [20] of bezit van geld [10]. De decentralisatie is afkomstig van het feit dat zo een blockchain peer to peer is. Knopen (computers, ook wel nodes genoemd in het Engels) die deelnemen aan het Bitcoin netwerk kunnen zich aanmelden en afmelden van het netwerk wanneer ze dat willen en communiceren met elkaar. Andere soorten blockchains vereisen dan weer dat de knopen continu online zijn. Transacties die gebeurt zijn terwijl een knoop niet naar het blockchain netwerk aan het luisteren was zullen alsnog worden opgenomen in het systeem als de knoop zich terug aanmeld. Doordat elke knoop steeds de langste blokketen volgt die uitgezonden wordt op het netwerk, zullen alle knopen ook dezelfde blockchain volgen.
2.3.2 Hashfunctie
Voordat er verder wordt ingegaan op de werking achter een blockchain, is het belangrijk te weten wat een hashfunctie [22] is en doet. Een hashfunctie is een cryptografische functie die door middel van gelijk welke invoer en onafhankelijk van de lengte een uitvoer geeft met een vaste lengte afhankelijk van de gebruikte soort hashfunctie. Een goede hashfunctie heeft meerdere belangrijke eigenschappen [22]:
´E´en richting: Een goede hash functie is eenvoudig te berekenen. Van invoer naar uitvoer gaan is niet moeilijk. Het is bij een goede hash functie echter praktisch onmo-gelijk om van uitvoer terug naar invoer te gaan. Zo een berekening zou veel tijd en rekenkracht in beslag nemen.
Geen verband tussen invoer en uitvoer: Zou ´e´en bit worden aangepast van de invoer, dan zal bij een goede hashfunctie de uitvoer er volledig anders uit zien. Er is geen verband te leggen met een invoer en een uitvoer. Dit is goed te zien in figuur 2.7 waarbij de enigste aanpassing van de invoer de letter “i” naar de letter “h” is. In ASCII (zie 2.3.5 voor meer informatie over ASCII) is enkel de laatste bit verschillend tussen de twee letters. Toch blijkt de tweede hash volledig anders dan de eerste hash.
Consistente uitvoer: Bij een goede hashfunctie zal eenzelfde invoer voor een hash-functie steeds een identieke uitvoer geven.
Botsingsweerstand of collision resistance: Een goede hashfunctie H zorgt ervoor dat het computationeel onmogelijk is om een x en y te vinden waarbij:
H(x) = H(y) Is dat wel zo, dan is H geen goede hashfunctie.
Figuur 2.7: De SHA-256 hashfunctie toegepast op twee licht verschillende invoeren.
Er wordt steeds gesproken over een “goede” hashfunctie. Een hashfunctie kan in zijn een-voudigste vorm de modulo van een getal berekenen zijn. Dit is echter geen goede hashfunctie omdat bijvoorbeeld de laatste eigenschap al snel wordt overtreden. Deze hashfuncties vormen een zeer belangrijk onderdeel bij blockchains en zijn de grootste reden waarom een blockchain werkt zoals hij hoort te werken.
2.3.3 Werking achter blockchain
Omdat blockchain een ingewikkeld onderwerp kan zijn, zullen de fundamentele principes steeds op basis van Bitcoin worden uitgelegd [20] [23]. Bitcoin is niet meer dan een openbaar grootboek van transacties, een public ledger in het Engels. Dit bevat transacties die zowel inkomend als uitgaand kunnen zijn. Een transactie is een aantal Bitcoins, de valuta van Bitcoin, die aan een adres wordt toegewezen. Dit adres is vergelijkbaar met een bankrekening en is steeds eigendom van ´e´en persoon of groep van personen. Deze transacties kunnen zowel inkomend zijn, een positief bedrag die aan een adres wordt toegewezen, als uitgaand zijn,
een negatief bedrag die aan een adres wordt toegewezen. Bitcoin is een publieke blockchain en volledig toegankelijk voor iedereen. Elke persoon kan elke transactie van de blockchain bekijken en zien van welk adres naar welk ander adres het verstuurd werd. Andere blockchains zijn dan weer privaat. Daar kunnen enkel de transacties worden gezien als de persoon toegang heeft tot de blockchain en niet iedereen heeft die toegang.
Het is niet nodig dat iemand het geld echt bezit zoals in het echte leven. Het is voldoende dat een persoon volgens het grootboek, meer inkomsten als uitgaven heeft om een transactie te kunnen uitvoeren. Stel dat Alice en Bob volgens de ledger elk ooit 100 BTC (Bitcoins) hebben ontvangen. Alice wil 10 BTC aan Bob betalen. Dan volstaat het om op de ledger een transactie toe te voegen met een waarde 10 BTC die van Alice naar Bob gaat. Die zal ook lukken omdat Alice nog genoeg balans heeft volgens haar vorige transacties. Als alle transacties steeds in hun geheel worden bekeken, dan zal Bob na de transactie over 110 BTC beschikken en Alice over 90 BTC. Door alle transacties in hun geheel te bekijken, wordt er vermeden dat er dubbel kan gespendeerd worden. In andere woorden, er wordt vermeden dat dezelfde Bitcoin meerdere keren kan worden uitgegeven. Zou Alice immers niet genoeg geld hebben, dan zou de transactie niet geldig zijn omdat op basis van de vorige transacties te zien zou zijn dat Alice niet genoeg saldo heeft. Echter blijken er nog meerdere technieken nodig om ervoor te zorgen dat dit alles veilig kan gebeuren.
Een eerste belangrijk onderdeel van een blockchain is authenticiteit. Zo mogen de Bitcoins enkel gespendeerd worden door de persoon zelf en niet door een andere persoon. Om dit te kunnen waarmaken, wordt er gebruik gemaakt van digitale handtekeningen [24]. Zo een digitale handtekening kan dezelfde vorm hebben als de hash die wordt getoond op de eerder getoonde figuur 2.7. Elke gebruiker van Bitcoin kan een private en een publieke sleutel combinatie genereren die bij elkaar horen. De private sleutel dient als extra invoer voor een hashfunctie zodat een unieke uitvoer kan worden gegenereerd. Samen met de private sleutel zou voor eenzelfde invoer steeds een andere uitvoer worden gegenereerd voor verschillende private sleutels met een identieke hashfunctie. Met de publieke sleutel kan dan geverifieerd worden dat de handtekening correct is en werd gegenereerd door de eigenaar van de private sleutel die bij de publieke sleutel hoort. De private sleutel moet steeds, zoals de naam aangeeft, privaat worden gehouden. Zou iemand toegang hebben tot deze private sleutel, dan zou deze sleutel kunnen worden gebruikt om transacties uit te voeren die niet werden geautoriseerd door de werkelijke eigenaar. Het veiligheidsmechanisme aan deze digitale handtekeningen is dat ze praktisch onmogelijk te vervalsen zijn. Een handtekening kan eenvoudig worden gemaakt met een private sleutel, maar een private sleutel kan niet binnen een realistische tijd worden afgeleid vanuit een digitale handtekening. Dit fenomeen wordt ook wel het discreet logaritme probleem genoemd [25]. Bij Bitcoin wordt de publieke sleutel van een gebruiker gebruikt om Bitcoins te associ¨eren aan een adres. De private sleutel dient dan om met de Bitcoins geassocieerd aan dit publiek adres transacties te kunnen uitvoeren.
![Figuur 2.1: De technologie stack van het semantisch web [12]](https://thumb-eu.123doks.com/thumbv2/5doknet/3274442.21396/18.918.235.670.219.488/figuur-technologie-stack-semantisch-web.webp)
![Figuur 2.4: Het PROV model gespecificeerd volgens W3C [8]](https://thumb-eu.123doks.com/thumbv2/5doknet/3274442.21396/27.918.268.652.795.1035/figuur-prov-model-gespecificeerd-volgens-w-c.webp)

![Figuur 2.11: Een blockchain met semantische metadata [29]](https://thumb-eu.123doks.com/thumbv2/5doknet/3274442.21396/40.918.202.700.274.424/figuur-een-blockchain-met-semantische-metadata.webp)
![Figuur 2.13: Een blockchain met een virtual RDF service [29]](https://thumb-eu.123doks.com/thumbv2/5doknet/3274442.21396/41.918.202.699.157.319/figuur-een-blockchain-met-een-virtual-rdf-service.webp)
